Word clouds visually represent text data, highlighting prevalent keywords and phrases. The frequency at which each word appears is reflected by the word's size.
Word Cloud Encoding Channels
Word clouds provide the following encoding channels:
Encoding Channel | Channel Type | Description |
|---|---|---|
Text | Category | The text values to add to the word cloud. Charts adds each unique value from the field applied to this channel to the word cloud. Word clouds can display a maximum of 100 values. If the field applied to this channel contains more than 100 unique values, the chart shows a random sample of 100 values. To ensure that the chart only shows the most common words, you should apply a limit and sort by Value. |
Size | Aggregation | Dictates the field to aggregate on and the type of aggregation to perform. The results of the aggregation define the size of each Text value, with larger aggregated values resulting in larger text sizes. For example, if you set the Text and Size channels to the If you set the Text channel to the |
Color | Category | (Optional) Colors each text value to indicate a corresponding data value from the applied field. For example, if you set the Text, Size, and Color channels to the If you set the Text and Size channels to the |
Use Cases
Use word clouds to show the frequency of specific words or phrases in text fields. Word clouds provide a high-level view of common words and themes across a series of text data. They can also highlight the most common phrases from a known set of strings, such as product categories or tags.
Consider using a word cloud to:
Show common words and phrases used in reviews of a product.
Identify common terms in existing content to improve SEO.
Highlight specific customer pain points from aggregated user surveys.
Examples
Word clouds are commonly used to show the frequency of words appearing within long text fields. By default, word clouds do not split text fields into words, and instead attempt to visualize the entire text field as a single value. You can use an aggregation pipeline to split a text field into individual words.
Note
The dataset used in this tutorial is included in the sample_airbnb.listingsAndReviews dataset provided by Atlas.
The following example creates a word cloud from a dataset containing information on AirBnB rental properties. Each property listing contains a description field; a text field describing the property.
First, we run an aggregation pipeline to pre-process the description field. The following aggregation pipeline:
Splitsthedescriptionfield into an array where each individual word is an array element.Unwindsthis array, creating a new document for each individual word from eachdescriptionfield.Adds a new fieldcalledwordsto the collection, where each unwound word from thedescriptionbecomes a value ofwords.Performs a
$matchquery such that only non-trivial words are added to the word cloud.
Procedure
Paste the following aggregation pipeline into the Query bar at the top of the Chart Builder:
[ { $addFields: { words: { $map: { input: { $split: ['$description', ' '] }, as: 'str', in: { $trim: { input: { $toLower: ['$$str'] }, chars: " ,|(){}-<>.;" } } } } } }, { $unwind: '$words' }, { $match: { words: { $nin: ["", "also", "i", "me", "my", "myself", "we", "us", "our", "ours", "ourselves", "you", "your", "yours", "yourself", "yourselves", "he", "him", "his", "himself", "she", "her", "hers", "herself", "it", "its", "itself", "they", "them", "their", "theirs", "themselves", "what", "which", "who", "whom", "whose", "this", "that", "these", "those", "am", "is", "are", "was", "were", "be", "been", "being", "have", "has", "had", "having", "do", "does", "did", "doing", "will", "would", "should", "can", "could", "ought", "i'm", "you're", "he's", "she's", "it's", "we're", "they're", "i've", "you've", "we've", "they've", "i'd", "you'd", "he'd", "she'd", "we'd", "they'd", "i'll", "you'll", "he'll", "she'll", "we'll", "they'll", "isn't", "aren't", "wasn't", "weren't", "hasn't", "haven't", "hadn't", "doesn't", "don't", "didn't", "won't", "wouldn't", "shan't", "shouldn't", "can't", "cannot", "couldn't", "mustn't", "let's", "that's", "who's", "what's", "here's", "there's", "when's", "where's", "why's", "how's", "a", "an", "the", "and", "but", "if", "or", "because", "as", "until", "while", "of", "at", "by", "for", "with", "about", "against", "between", "into", "through", "during", "before", "after", "above", "below", "to", "from", "up", "upon", "down", "in", "out", "on", "off", "over", "under", "again", "further", "then", "once", "here", "there", "when", "where", "why", "how", "all", "any", "both", "each", "few", "more", "most", "other", "some", "such", "no", "nor", "not", "only", "own", "same", "so", "than", "too", "very", "say", "says", "said", "shall"] } } } ] Click Apply to execute the pipeline.
Now that we have a new field containing the individual words from each review, we can visualize those words in a word cloud.
Apply the newly created
wordsfield to the Text encoding channel to add each individual word to the word cloud.Apply a limit of 80 to only show the 80 most common words from the reviews.
Apply the
wordsfield to the Size encoding channel and aggregate based on the count of each individual word.
Your word cloud should look something like this:
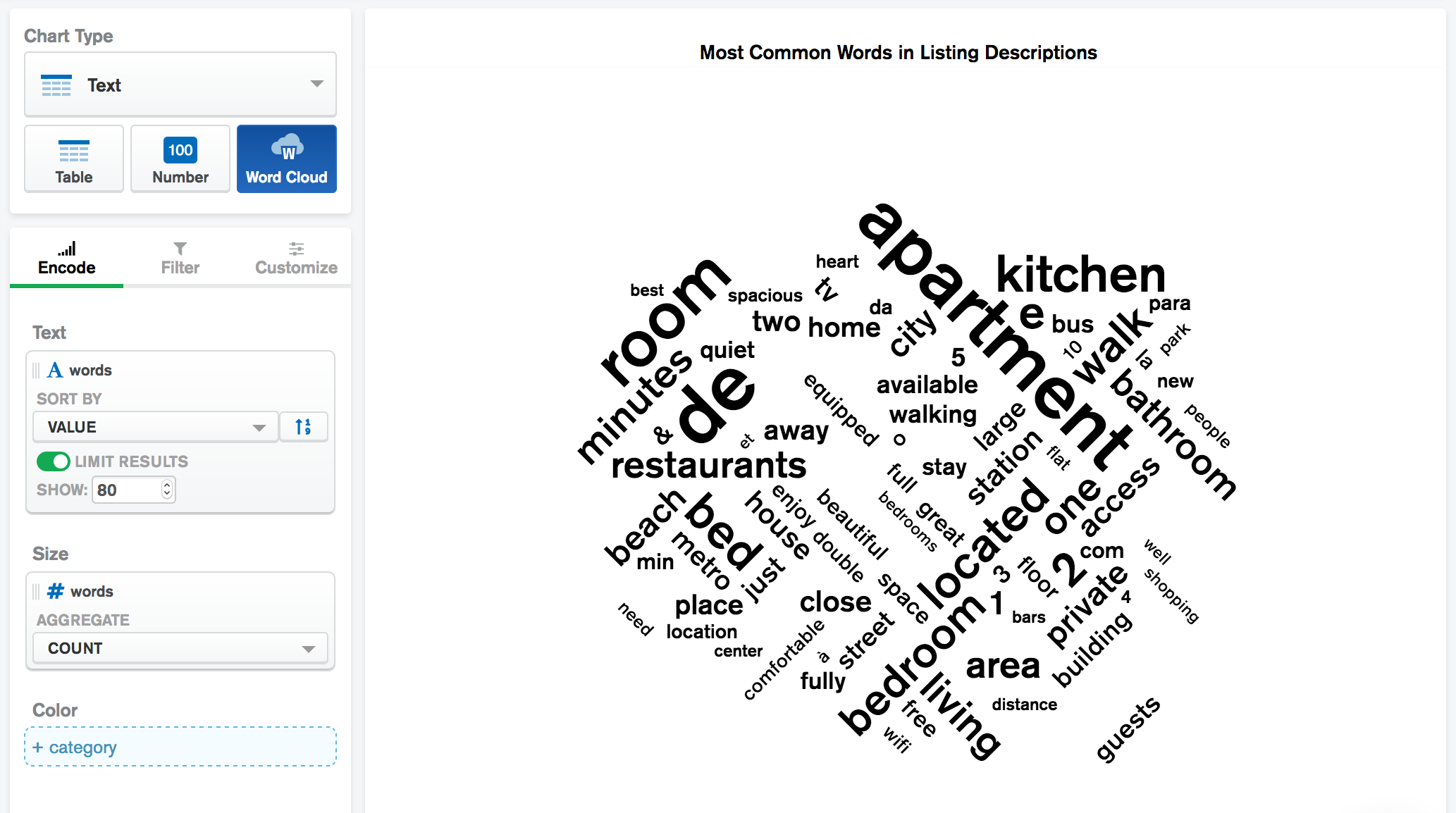
The size of the words in the cloud represent their relative frequency.
Limitations
The maximum query response size for a word cloud is 5000 documents.