How do large language models work?
Large language models function by utilizing deep learning techniques to process and generate human language.
- Data collection: The first step in training LLMs involves collecting a massive dataset of text and code from the internet. This dataset comprises a wide range of human-written content, providing the LLMs with a diverse language foundation.
- Pre-training data: During the pre-training phase, LLMs are exposed to this vast dataset. They learn to predict the next word in a sentence, which helps them understand the statistical relationships between words and phrases. This process enables them to grasp grammar, syntax, and even some contextual understanding.
- Fine-tuning data: Following pre-training, LLMs are fine-tuned for specific tasks. This involves exposing them to a narrower dataset related to the desired application, such as translation, sentiment analysis, or text generation. Fine-tuning refines their ability to perform these tasks effectively.
- Contextual understanding: LLMs consider the words before and after a given word in a sentence, allowing them to generate coherent and contextually relevant text. This contextual awareness is what sets LLMs apart from earlier language models.
- Task adaptation: Thanks to fine-tuning, LLMs can adapt to a broad array of tasks. They can answer questions, generate human-like text, translate languages, summarize documents, and more. This adaptability is one of the key strengths of LLMs.
- Deployment: Once trained, LLMs can be deployed in various applications and systems. They power chatbots, content generation engines, search engines, and other AI applications, enhancing user experiences.
In summary, LLMs work by first learning the intricacies of human language through pre-training on massive datasets. They then fine-tune their abilities for specific tasks, leveraging contextual understanding. This adaptability makes them versatile tools for a wide range of natural language processing applications.
Additionally, it's important to note that the selection of a specific LLM for your use case — as well as the processes of pre-training the model, fine-tuning, and other customizations — happen independently of Atlas (and thereby, outside of Atlas Vector Search).
What is the difference between a large language model (LLM) and natural language processing (NLP)?
Natural language processing (NLP) stands as a domain within computer science dedicated to facilitating interactions between computers and human languages, encompassing both spoken and written communication. Its scope encompasses empowering computers with the ability to understand, interpret, and manipulate human language, spanning applications such as machine translation, speech recognition, text summarization, and question answering.
On the other hand, large language models (LLMs) emerge as a specific category of NLP models. These models undergo rigorous training on vast repositories of text and code, enabling them to discern intricate statistical relationships between words and phrases. Consequently, LLMs exhibit the capacity to generate text that is both coherent and contextually relevant. LLMs can be used for a variety of tasks, including text generation, translation, and question-answering.
Large language model examples in real-world applications
Enhanced customer service
Imagine a company seeking to elevate its customer service experience. They harness the capabilities of a large language model to create a chatbot capable of addressing customer inquiries about their products and services. This chatbot undergoes a training process using extensive datasets consisting of customer questions, corresponding answers, and detailed product documentation. What sets this chatbot apart is its deep understanding of customer intent, enabling it to provide precise and informative responses.
Smarter search engines
Search engines are a part of our daily lives, and LLMs power these search engines, making them more intuitive. These models can understand what you're searching for, even if you don't phrase it perfectly, and retrieve the most relevant results from vast databases, enhancing your online search experience.
Personalized recommendations
When you shop online or watch videos on streaming platforms, you often see recommendations for products or content you might like. LLMs drive these smart recommendations, analyzing your past behavior to suggest things that match your tastes, making your online experiences more tailored and personalized to you.
Creative content generation
LLMs are not just data processors; they're also creative minds. They have deep learning algorithms that can generate content from blog posts to product descriptions and even poetry. This not only saves time but also aids businesses in crafting engaging content for their audiences.
By incorporating LLMs, businesses are improving their customer interactions, search functionality, product recommendations, and content creation, ultimately transforming the tech landscape.
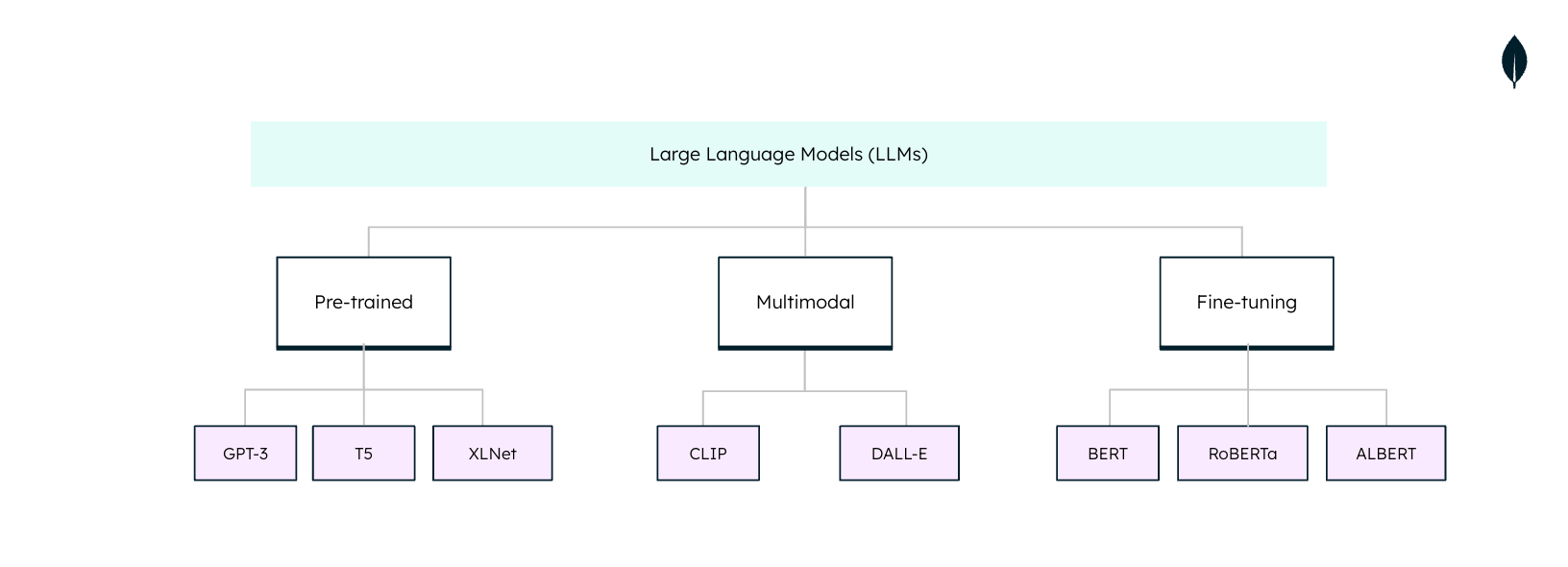
Types of large language models
Large language models (LLMs) are not one-size-fits-all when used in natural language processing (NLP) tasks. Each LLM is tailored to specific tasks and applications. Understanding these types is essential in harnessing the full potential of LLMs:
Pre-trained models:
Pre-training models like GPT-3 (Generative Pre-trained Transformers), T5 (Text-to-Text Transfer Transformer), and XLNet (Extra Large Neural Networks) undergo extensive training on massive amounts of text data. They can craft coherent and grammatically correct text on a variety of topics that serve as a foundation for other AI tasks, such as further training and fine-tuning.
Fine-tuned models:
Fine-tuning models, such as BERT (Bidirectional Encoder Representations from Transformers), RoBERTa, and ALBERT (both extensions of BERT) is another machine learning model for NLP. These machine learning models start as pre-trained models but are then fine-tuned on specific tasks or datasets. They are highly effective for particular tasks like sentiment analysis, question-answering, and text classification.
Multimodal models:
Multimodal models, including CLIP and DALL-E, combine text and visual information. CLIP stands for Contrastive Language-Image Pre-training. The name DALL-E is a play on words, combining "Dali" (referring to the artist Salvador Dalí) and "Wall-E" (the animated robot character from the Pixar movie). Both are known for their ability to perform tasks that involve connecting visual and textual information.
In summary, pre-trained models offer a broad foundation, fine-tuned models specialize in specific tasks, and a multimodal model bridges the gap between text and images. The choice depends on your specific use case and the complexity of the task at hand.
Atlas Vector Search: Accelerate your journey to building advanced search and generative AI applications
In today's fast-paced world, MongoDB Atlas Vector Search takes LLM technology to the next level by integrating with a wide variety of popular LLMs and frameworks and making it easy to get started with building an AI application. For example, you can use Atlas Vector Search to:
- Store and search vector embeddings generated by OpenAI, Hugging Face, and Cohere, right next to your source data and metadata. This allows you to build high-performance generative AI applications that can generate text, provide language translation, and answer questions in a more comprehensive and informative way, and it removes the overhead of managing disparate operational and vector databases.
- Provide long-term memory to LLMs with retrieval-augmented generation and integrations with application frameworks such as LangChain and LlamaIndex. Atlas Vector Search provides the relevant business context from proprietary data to an LLM and allows LLMs to learn from their interactions with users over time and provide more personalized and relevant responses, thereby reducing hallucinations.
- Visualize and explore vector embedding data easily in the web browser with Nomic.
- Build LLM applications in C# and Python with Microsoft Semantic Kernel.
If you are interested in building advanced search and generative AI applications, then Atlas Vector Search is a great place to start. Atlas Vector Search provides a powerful and flexible platform for developing and deploying AI applications.
Learn more about MongoDB Atlas Vector Search today!