Key takeaways
Data modeling is a process where businesses organize and store their data in the most efficient manner so that the data can be easily queried for operational and analytical purposes.
It is important to model data to maintain data integrity and security, and make data easily accessible and viewable.
There are three main types of data models: conceptual, logical, and physical.
Several modeling techniques exist to address different workloads and business requirements.
The data modeling process involves a series of steps, including gathering the requirements, understanding entities and their relationships, identifying the data structures, creating the schema, and applying design patterns.
MongoDB makes modeling data simple due to its flexible schema and support for various data modeling techniques and design patterns. Atlas UI and MongoDB Compass also provide an easy interface for its users to create and modify database schema.
Modern applications require data storage, but how that data is modeled will have a significant impact on the performance of the application, as well as the development speed. Proper data modeling management and database design are integral to setting up a successful application.
In this article, we will discuss what data modeling is, why data modeling is necessary, and important data modeling techniques that can be used in conjunction with MongoDB.
Table of contents
- What is data modeling?
- Why is data modeling important?
- What are the 3 different types of data models?
- Data modeling techniques
- Data modeling process with an example data model
- Next steps
- FAQs
What is data modeling?
Data modeling defines how organizations store, maintain, and visualize data. It is a process which identifies how businesses should capture relevant data, identify all data elements, determine complex data relationships, and find the best way to demonstrate those relationships.
Databases can store different types of unstructured data (raw data), semi-structured and structured data—like customer data, application data, logs, images, videos, and documents—and more.
The key concepts of a data model are:
An entity: This is defined as an independent object that is also a logical component in the system. Entities can be categorized as tangible and intangible. This means that tangible entities (such as books) exist in the real world, while intangible entities (such as book loans) don't have a physical form.
Entity instances: These describe the specific instance of an entity group. For example, the tangible book entity “Alice in Wonderland” belongs to the specific instance of “book.”
Attributes: Attributes describe the characteristics of an entity. For example, the entity “book” has the attributes International Standard Book Number or ISBN (String) and title (String).
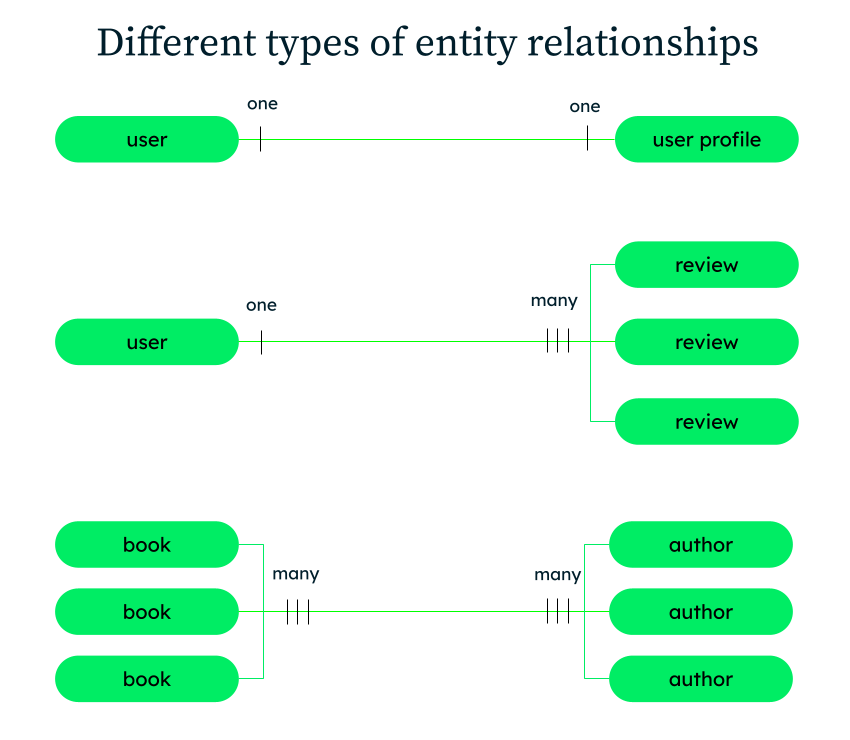
Relationships: These define the connections between the entities. For example, one user can borrow many books at a time. The relationship between the entities "users" and "books" is one to many.
Most databases, including MongoDB, support multiple ways to model relationships between entities:
One-to-one (1-1): One entity instance relates to exactly one instance of another entity. For example, a User has exactly one UserProfile.
One-to-many (1-N): One entity instance relates to multiple instances of another entity. For example, one User can borrow many books.
To learn more about the basics, please watch our data modeling introduction video.
Why is data modeling important?
Data modeling is a critical step in database design. It serves as a blueprint for building performant, scalable databases and provides a shared reference across teams. With a proper design, even non-technical experts like business analysts can understand the database structure along with developers and data architects, thus promoting better collaboration and efficient analysis.
Data modeling ensures that data consistency and data integrity requirements are met, and business rules and data relationships remain intact.
Different industries may use various types of data models (conceptual, logical, and physical) in different ways. Data architects, system analysts, and business intelligence analysts apply these models to meet their specific business needs.
Data modelers provide organizations with organized and accessible data. In addition to data management support, modeling also helps data analytics and business intelligence teams to uncover business opportunities that were hidden due to a previously non-existent entity relationship or a better way to support business stakeholders by augmenting data-driven business processes or management systems.
What are the 3 different types of data models?
There are three types of data models, based on the level of data abstraction:
Conceptual data model
The conceptual data model explains what data the system should contain and the relationships among data elements. Built with business stakeholders, it represents the application's business logic and often incorporates domain-driven design principles. This model typically serves as the foundation for subsequent models.
Logical data model
The logical data model describes how data will be structured. In this model, the relationship between entities is established at a high level, and a list of entity attributes will also be represented. This data model can be thought of as a “blueprint” for the data that will be incorporated.
Physical data model
The physical model represents how data will be stored in a specific database management system (DBMS). In this model, primary and foreign keys in a relational database are established, or the decision to embed or link data based on entity relationships in a document database such as MongoDB is made. This is also where data types for each of your fields will be established which, in turn, will provide the database schema.
Relational databases use the Entity-Relationship (ER) Diagram to visualize logical and physical data models. Document databases like MongoDB use a similar approach. However, they also give details regarding document embedding and/or referencing along with relationships and attribute types.

The diagram above shows three levels: the conceptual model (main entities), the logical model (entity relationships and attributes), and the physical model (actual database implementation including data types and embedding/referencing decisions).
Data modeling techniques
Databases use many techniques to model and represent data. While relational databases aim to reduce data redundancy and store data in normalized form, NoSQL databases allow some duplication to ensure better read performance. Below are some techniques used by different databases:
Hierarchical data modeling
This technique follows a tree structure with a single root node, where navigation flows top-to-bottom and each parent can have multiple children. It's suitable for simple, hierarchical data but struggles with many-to-many relationships.
Graph data modeling
This technique uses nodes and edges to represent entities and relationships, where any node can connect to many others. It enables fast traversal across complex relationship paths and is ideal for highly connected data like social networks or recommendation engines.
Relational data modeling
This technique is used by relational databases that use the Structured Query Language to query data. Each entity is represented by a table, and attributes are represented by columns. The primary keys, foreign keys of each entity, are mentioned in the visual representation itself.
Entity-relationship data modeling
This technique represents the database system at a very high level. It is used to build the physical model of a database, as it is very easy to visualize and gives details of each entity, attributes, and relationships in a single view that can be understood even by non-technical stakeholders. There are several ER modeling tools available like Hackolade and Open ModelSphere.
Object-oriented data modeling
The object-oriented data modeling technique uses an object-oriented programming paradigm, where entities are represented as objects with a set of associated attributes. The model presents the view as a collection of objects.
Dimensional data modeling
Dimensional models promote data redundancy for faster data retrieval and better read performance. These models are used in a data warehouse for analytics purposes.
MongoDB stores data as JSON-like (BSON) documents. The data that is used together is always stored together as nested fields, arrays, or subdocuments. Documents are held inside a collection, which is analogous to a database table in a relational database. MongoDB supports the above techniques through its design patterns, like the extended reference pattern, bucket pattern, polymorphic pattern, tree pattern, computed pattern, and so on. You can read all about the MongoDB design patterns on our blog series Building With Patterns.
Data modeling process with an example data model
The data modeling process is a series of steps taken to create a data model, and may vary for any database management system. As an example, we will show the modeling process for MongoDB for a basic library system with five entities:
Book: Collection of books, with details like ISBN and name, with ISBN being the unique identifier
Author: Collection of authors, with details about the author, where author_id will be the unique identifier
User Profile: Profiles of all the users that enrolled for a library subscription, i.e., borrowing books
User: All the active users who borrow books from the library with minimal details that are accessed regularly, like the books they borrowed, due date, and so on
Review: Collection of user reviews for various books
We follow through the data model types to arrive at the database schema for this requirement.
Gathering requirements
The first step is gathering application requirements. This uncovers the underlying data structures and, critically, the workload: what operations will be performed, how much data is involved, and how frequently operations occur.
Understand relationships among entities
The next step is to understand the relationships between data entities that make up the logical model. Try to think about how the objects are related (e.g., one to one, one to many, or many to many) and what data attributes will be used to describe these objects. In our library example, a book can be written by multiple authors (many:many). A user can be associated only with one user profile (1:1). Also, a user can write multiple reviews. However, one review can be associated with one user only (1:many).
The next step is to decide whether to reference or embed data in a document by using a set of questions based on the workload.
Questions and points for embedding:
Simplicity: Would keeping the pieces of information together lead to a simpler data model and code?
Yes – point for embedding
Go together: Do the pieces of information have a “has-a”, “contains”, or similar relationships?
Yes – point for embedding
Query atomicity: Does the application query the pieces of information together?
Yes – point for embedding
Update complexity: Are the pieces of information updated together?
Yes – point to embedding
Archival: Should the pieces of information be archived at the same time?
Yes – point for embedding
Questions and points for referencing:
Cardinality: Is there a high cardinality (current or growing) in a “many” side of the relationship?
Yes—point for reference
Data duplication: Would data duplication be too complicated to manage and undesired?
Yes—point for reference
Document size: Would the combined sizes of the pieces of information take too much memory or transfer bandwidth for the application?
Yes—point for reference
Document growth: Would the embedded piece grow without bound?
Yes—point for reference
Workload: Are the pieces of information written at different times in a write-heavy workload?
Yes—point for reference
Individuality: For the children's side of the relationship, can the pieces exist by themselves without a parent?
Yes—point for reference
Based on the above, in our library system, we can embed a subset of author documents (like their names and genres) inside the book collection. On the other hand, since a user will have many details that may not all be useful at all times, we can reference the details when required from the User Profile collection.
The completion of this step results in the logical data model.
Identify the data structure
This step considers the actual data stored in the database, and data modeling techniques will also depend on the type of DBMS used. For example, if using a relational database, identifying unique keys and field types, as well as normalizing data, will be necessary. However, with a document database, embedding related information may be warranted. For references, we use ObjectId (or ObjectId[] for arrays). For embedding, we use nested documents or embedded arrays—for example, embedding an array of author subdocuments within each book.
This step produces a physical data model representing the initial database design known as schema.
Apply design patterns
Patterns make data modeling more efficient and effective. With design patterns, it's easier to accommodate changes in application requirements and structure. In MongoDB, there are a number of patterns to choose from, including schema versioning, bucket, computed, and tree, to name just a few. For a more complete list, including details on each pattern type, check out MongoDB's Building With Patterns: A Summary
MongoDB provides a flexible schema for data, meaning that you can easily change data structures as your application progresses and requirements change without compromising data integrity. This flexibility enables you to restructure your schema and optimize your queries as many times as necessary.
In addition, as you model your data, think about how the data will be displayed and used in your application. The way you use the data will likely dictate the structure of your database, and not the other way around. This may be why MongoDB is so intuitive for software developers.
Using the MongoDB Atlas UI, you can design and create a visual representation of your schema.
Next steps
Data modeling is an essential step for a scalable, robust, and performant database. It enables data engineers, business users, and database administrators to view and query data easily and quickly. Selecting the right database and modeling technique is crucial, and you should decide that based on your use case.
Just as selecting the right pattern/modeling technique is an important step in data modeling, it's also critical to avoid schema design anti-patterns. To learn more, read MongoDB's Schema Design Anti-Patterns.
Interested in learning even more? Here are three ways to level up your data modeling skill set.
Review the MongoDB Data Modeling Intro course to catch up on the latest trends in data modeling.
Try out MongoDB Atlas, our fully managed developer data platform, and see how this data modeling tool can take your projects to the next level.
Take a course on data modeling on MongoDB University and build your knowledge even further.
Get a free MongoDB Skill Badge credential on a data modeling topic, each in 60 to 90 minutes.