Streaming Data from MongoDB to BigQuery Using Confluent Connectors


Venkatesh Shanbhag, Ozan Güzeldereli4 min read • Published Jan 24, 2023 • Updated Jul 11, 2023




Rate this tutorial


Many enterprise customers of MongoDB and Google Cloud have the core operation workload running on MongoDB and run their analytics on BigQuery. To make it seamless to move the data between MongoDB and BigQuery, MongoDB introduced Google Dataflow templates. Though these templates cater to most of the common use cases, there is still some effort required to set up the change stream (CDC) Dataflow template. Setting up the CDC requires users to create their own custom code to monitor the changes happening on their MongoDB Atlas collection. Developing custom codes is time-consuming and requires a lot of time for development, support, management, and operations.
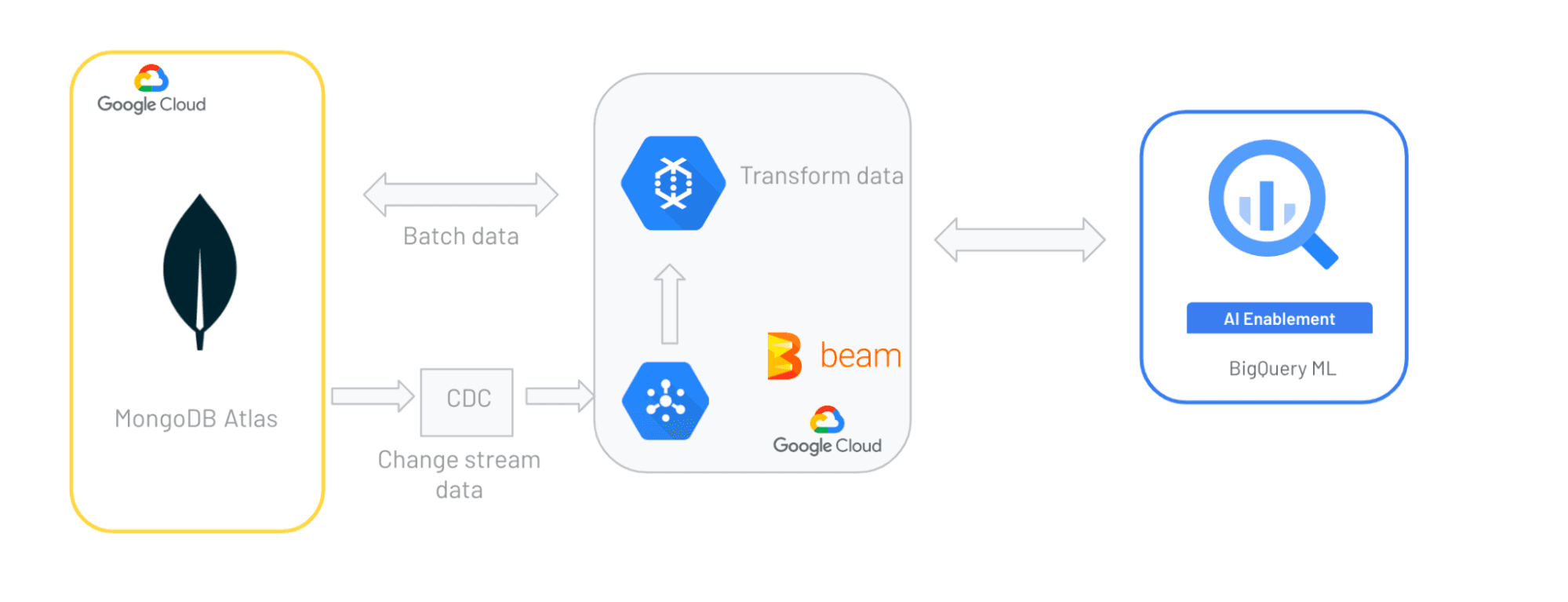
Overcoming the additional effort required to set up CDCs for MongoDB to BigQuery Dataflow templates can be achieved using Confluent Cloud. Confluent is a full-scale data platform capable of continuous, real-time processing, integration, and data streaming across any infrastructure. Confluent provides pluggable, declarative data integration through its connectors. With Confluent’s MongoDB source connectors, the process of creating and deploying a module for CDCs can be eliminated. Confluent Cloud provides a MongoDB Atlas source connector that can be easily configured from Confluent Cloud, which will read the changes from the MongoDB source and publish those changes to a topic. Reading from MongoDB as source is the part of the solution that is further enhanced with a Confluent BigQuery sink connector to read changes that are published to the topic and then writing to the BigQuery table.
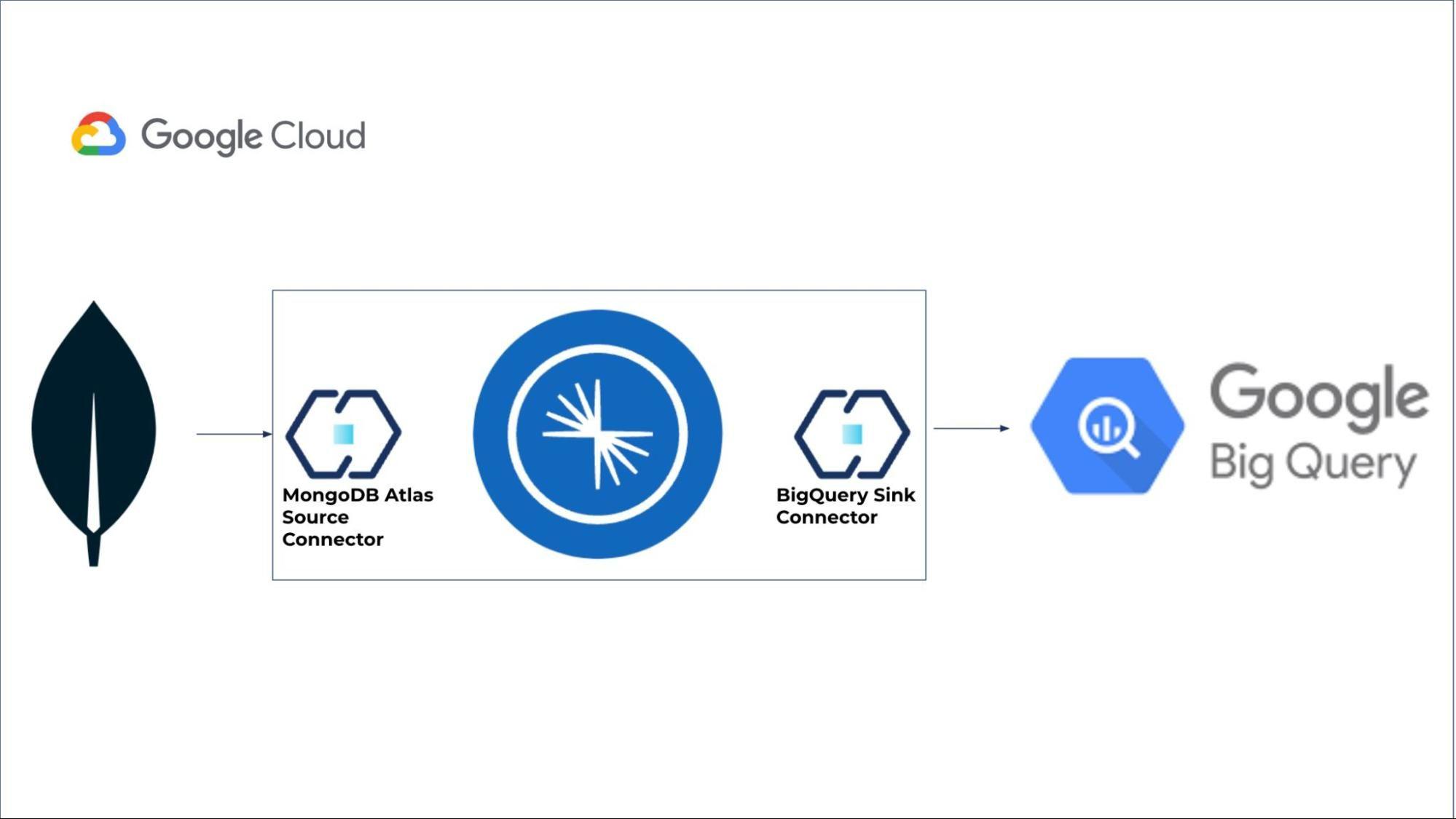
This article explains how to set up the MongoDB cluster, Confluent cluster, and Confluent MongoDB Atlas source connector for reading changes from your MongoDB cluster, BigQuery dataset, and Confluent BigQuery sink connector.
As a prerequisite, we need a MongoDB Atlas cluster, Confluent Cloud cluster, and Google Cloud account. If you don’t have the accounts, the next sections will help you understand how to set them up.
To set up your first MongoDB Atlas cluster, you can register for MongoDB either from Google Marketplace or from the registration page. Once registered for MongoDB Atlas, you can set up your first free tier Shared M0 cluster. Follow the steps in the MongoDB documentation to configure the database user and network settings for your cluster.
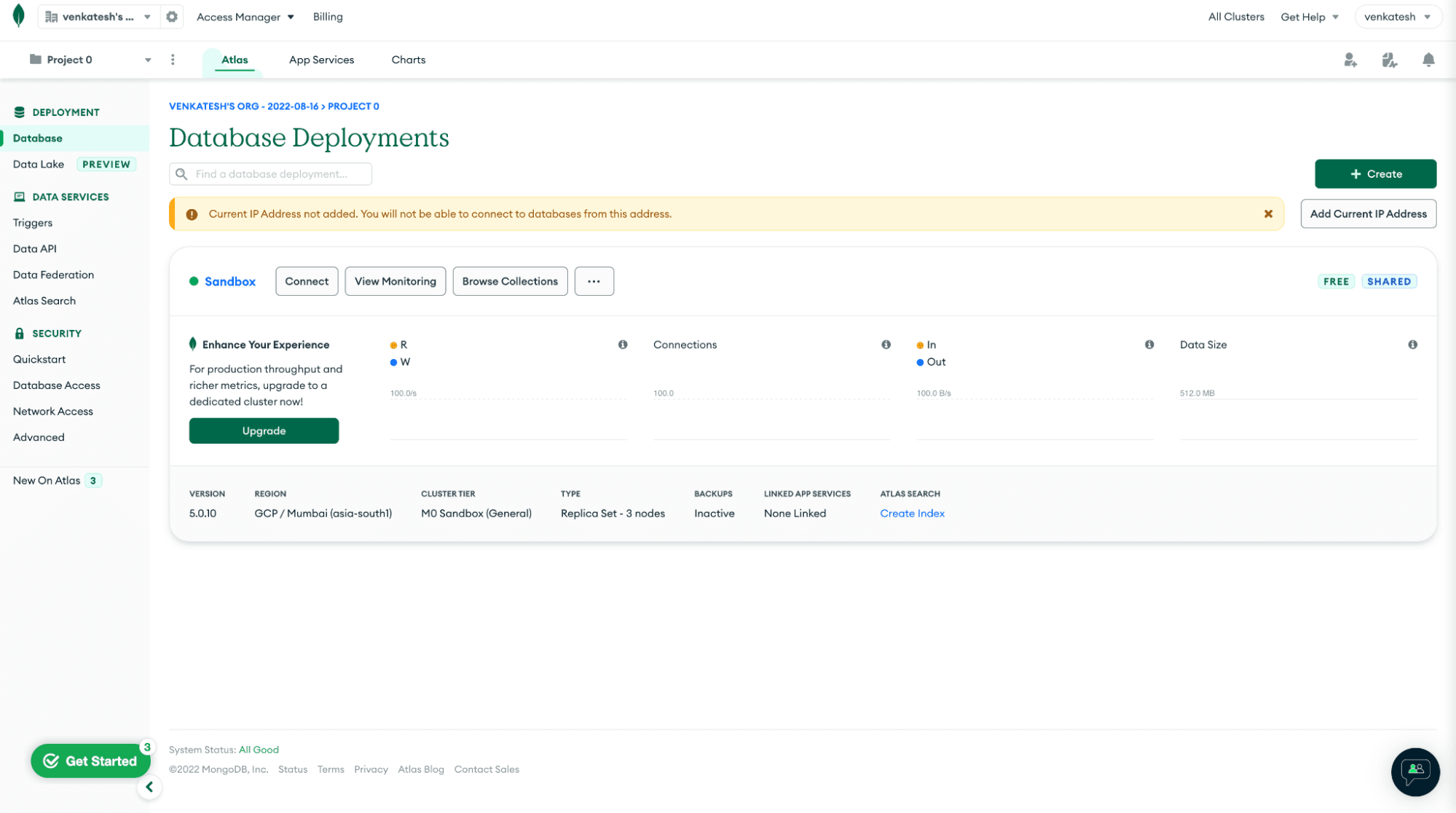
Once the cluster and access setup is complete, we can load some sample data to the cluster. Navigate to “browse collection” from the Atlas homepage and click on “Create Database.” Name your database “Sample_company” and collection “Sample_employee.”
Insert your first document into the database:

As a prerequisite for setting up the pipeline, we need to create a dataset in the same region as that of the Confluent cluster. Please go through the Google documentation to understand how to create a dataset for your project. Name your dataset “Sample_Dataset.”
After setting up the MongoDB and BigQuery datasets, Confluent will be the platform to build the data pipeline between these platforms.
To sign up using Confluent Cloud, you can either go to the Confluent website or register from Google Marketplace. New signups receive $400 to spend during their first 30 days and a credit card is not required. To create the cluster, you can follow the first step in the documentation. One important thing to consider is that the region of the cluster should be the same region of the GCP BigQuery cluster.
Depending on the settings, it may take a few minutes to provision your cluster, but once the cluster has provisioned, we can get the sample data from MongoDB cluster to the Confluent cluster.
Confluent’s MongoDB Atlas Source connector helps to read the change stream data from the MongoDB database and write it to the topic. This connector is fully managed by Confluent and you don’t need to operate it. To set up a connector, navigate to Confluent Cloud and search for the MongoDB Atlas source connector under “Connectors.” The connector documentation provides the steps to provision the connector.
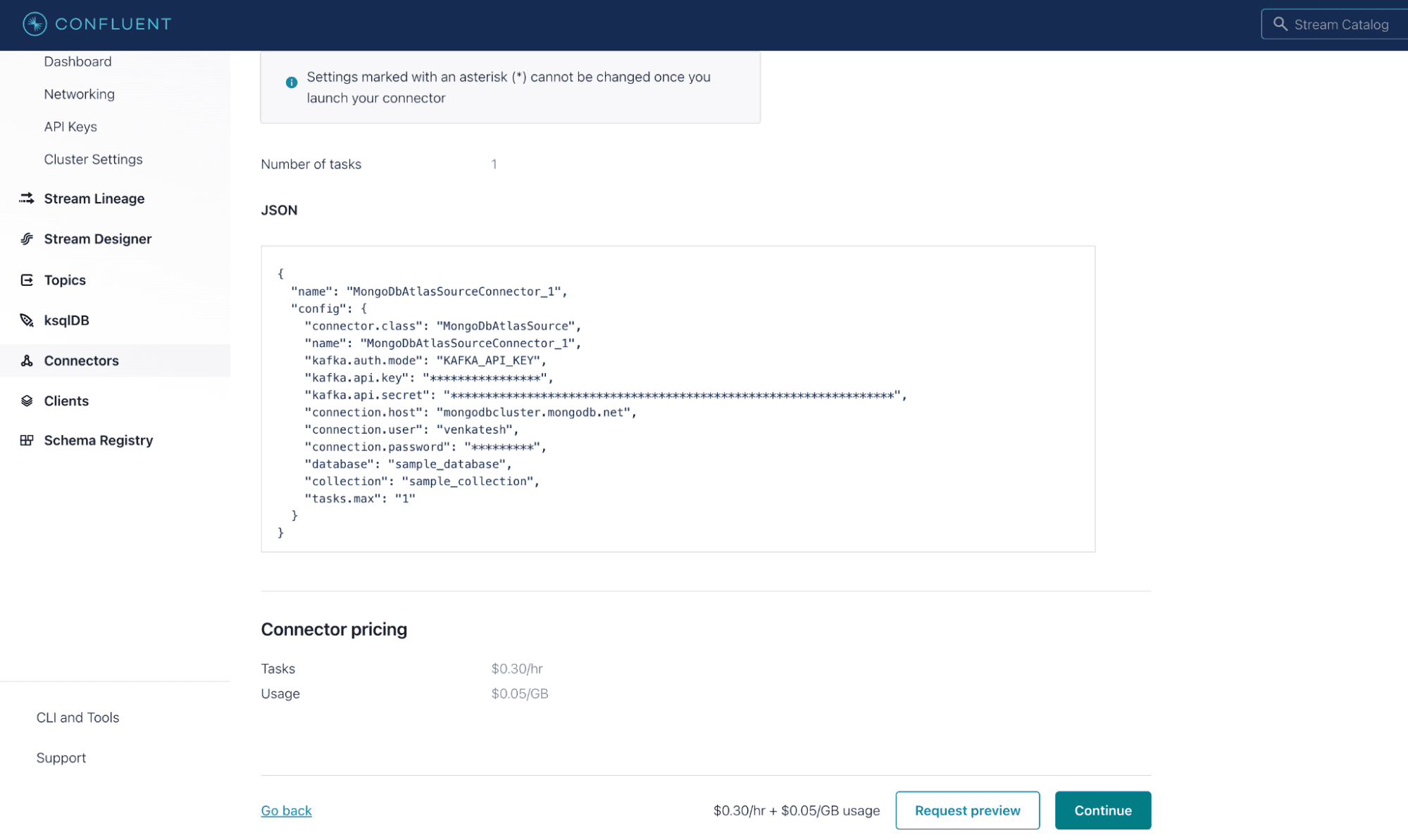
Below is the sample configuration for the MongoDB source connector setup.
- For Topic selection, leave the prefix empty.
- Generate Kafka credentials and click on “Continue.”
- Under Authentication, provide the details:
- Connection host: Only provide the MongoDB Hostname in format “mongodbcluster.mongodb.net.”
- Connection user: MongoDB connection user name.
- Connection password: Password of the user being authenticated.
- Database name: sample_database and collection name: sample_collection.
- Under configuration, select the output Kafka record format as JSON_SR and click on “Continue.”
- Leave sizing to default and click on “Continue.”
- Review and click on “Continue.”
After setting up our BigQuery, we need to provision a sink connector to sink the data from Confluent Cluster to Google BigQuery. The Confluent Cloud to BigQuery Sink connector can stream table records from Kafka topics to Google BigQuery. The table records are streamed at high throughput rates to facilitate analytical queries in real time.
To see the data being loaded to BigQuery, make some changes on the MongoDB collection. Any inserts and updates will be recorded from MongoDB and pushed to BigQuery.
Insert below document to your MongoDB collection using MongoDB Atlas UI. (Navigate to your collection and click on “INSERT DOCUMENT.”)
MongoDB and Confluent are positioned at the heart of many modern data architectures that help developers easily build robust and reactive data pipelines that stream events between applications and services in real time. In this example, we provided a template to build a pipeline from MongoDB to Bigquery on Confluent Cloud. Confluent Cloud provides more than 200 connectors to build such pipelines between many solutions. Although the solutions change, the general approach is using those connectors to build pipelines.
- To understand the features of Confluent Cloud managed MongoDB sink and source connectors, you can watch this webinar.
- Set up your first MongoDB cluster using Google Marketplace.