Speed. It's everything in today's complex data environments; a critical factor in ensuring seamless user experiences and efficient business operations, in-memory databases play a crucial role in your tech stack.
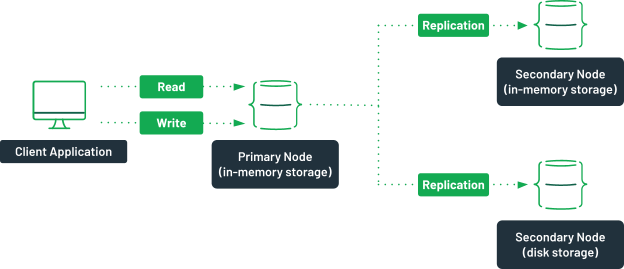
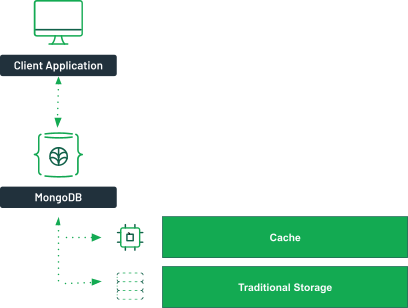
In-memory databases offer unparalleled speed by storing data entirely in random access memory (RAM) instead of traditional disk-based storage. With their ability to reduce latency and deliver real-time data access, in-memory databases have become indispensable in applications where rapid data retrieval is crucial.
But what exactly is an in-memory database, and how does it differ from traditional databases? Is speed alone enough to justify adopting this technology, or are there other factors to consider? These questions are essential for developers, system architects, and business leaders looking to optimize their data management strategies while balancing performance, cost, and reliability.
In-memory databases have become a pivotal technology in modern applications requiring real-time data processing and low latency responses. Unlike traditional databases, an in-memory database system stores data entirely in a computer’s main memory (RAM) instead of on disk-based databases. This architecture allows faster access to frequently accessed data and ensures low latency for applications where speed is critical.
Table of contents