Definição
$densifyNovidades na versão 5.1.
Cria novos documentos em uma sequência de documentos onde determinados valores em um campo estão faltando.
Você pode usar
$densifypara:Preencha lacunas nos dados de séries temporais.
Adicione valores ausentes entre grupos de dados.
Preencha seus dados com um intervalo de valores especificado.
Sintaxe
O estágio $densify tem esta sintaxe:
{ $densify: { field: <fieldName>, partitionByFields: [ <field 1>, <field 2> ... <field n> ], range: { step: <number>, unit: <time unit>, bounds: < "full" || "partition" > || [ < lower bound >, < upper bound > ] } } }
O estágio $densify toma um documento com estes campos:
Campo | necessidade | Descrição |
|---|---|---|
Obrigatório | O campo para densificar. Os valores do Os documentos que não contêm o Para especificar um Para restrições, consulte | |
Opcional | O conjunto de campos para agir como a chave composta para agrupar os documentos. No estágio, cada grupo de Se você omitir este campo, o utilizará uma partição para toda a Para obter um exemplo, consulte Densificação com partições. Para restrições, consulte | |
Obrigatório | Um objeto que especifica como os dados são densificados. | |
Obrigatório | Você pode especificar
Se
Se
Se
| |
Obrigatório | O valor para incrementar o valor do campo em cada documento. Se range.unit for especificado, o | |
Necessário se o campo for uma data. | A unidade a aplicar ao campo etapa ao incrementar valores de data no campo. Você pode especificar um dos seguintes valores para
Para ver um exemplo, consulte Densificar dados de séries temporais. |
Comportamento e restrições
field Restrições
Para documentos que contêm o campo especificado, $densify retornará um erro se:
Qualquer documento na coleção tem um valor de
fieldda data do tipo e o campo unidade não é especificado.Qualquer documento na coleção tem um valor de
fielddo tipo numérico e o campo unidade é especificado.O nome
fieldcomeça com$. Você deve renomear o campo se quiser densificá-lo. Para renomear campos, use$project.
partitionByFields Restrições
$densify retornará um erro se algum nome de campo na array partitionByFields:
Avalia para um valor não string.
Começa com
$.
range.bounds Comportamento
Se range.bounds for uma array:
Ordem de saída
$densify não garante a ordem de classificação dos documentos gerados.
Para garantir a ordem de classificação, utilize $sort no campo pelo qual você deseja classificar.
Exemplos
Densificar dados de série temporal
Crie uma coleção weather que contenha leituras de temperatura em intervalos de quatro horas.
db.weather.insertMany( [ { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T00:00:00.000Z"), "temp": 12 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T04:00:00.000Z"), "temp": 11 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T08:00:00.000Z"), "temp": 11 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T12:00:00.000Z"), "temp": 12 } ] )
Este exemplo utiliza o estágio $densify para preencher as lacunas entre os intervalos de quatro horas para obter a granularidade por hora para os pontos de dados:
db.weather.aggregate( [ { $densify: { field: "timestamp", range: { step: 1, unit: "hour", bounds:[ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ] } } } ] )
No exemplo:
O estágio
$densifypreenche as lacunas de tempo entre as temperaturas registradas.field: "timestamp"densifica o campotimestamp.
range:step: 1aumenta o campotimestamppor unidade 1.unit: hourdensifica o campotimestamppor hora.bounds: [ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ]Define o intervalo de tempo que é densificado.
Na saída seguinte, o estágio $densify preenche as lacunas de tempo entre as horas de 00:00:00 e 08:00:00.
[ { _id: ObjectId("618c207c63056cfad0ca4309"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T00:00:00.000Z"), temp: 12 }, { timestamp: ISODate("2021-05-18T01:00:00.000Z") }, { timestamp: ISODate("2021-05-18T02:00:00.000Z") }, { timestamp: ISODate("2021-05-18T03:00:00.000Z") }, { _id: ObjectId("618c207c63056cfad0ca430a"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T04:00:00.000Z"), temp: 11 }, { timestamp: ISODate("2021-05-18T05:00:00.000Z") }, { timestamp: ISODate("2021-05-18T06:00:00.000Z") }, { timestamp: ISODate("2021-05-18T07:00:00.000Z") }, { _id: ObjectId("618c207c63056cfad0ca430b"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T08:00:00.000Z"), temp: 11 } { _id: ObjectId("618c207c63056cfad0ca430c"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T12:00:00.000Z"), temp: 12 } ]
Densificação com divisórias
Crie uma coleção do coffee que contenha dados para duas variedades de grãos de café:
db.coffee.insertMany( [ { "altitude": 600, "variety": "Arabica Typica", "score": 68.3 }, { "altitude": 750, "variety": "Arabica Typica", "score": 69.5 }, { "altitude": 950, "variety": "Arabica Typica", "score": 70.5 }, { "altitude": 1250, "variety": "Gesha", "score": 88.15 }, { "altitude": 1700, "variety": "Gesha", "score": 95.5, "price": 1029 } ] )
Densifique toda a gama de valores
Este exemplo utiliza $densify para densificar o campo altitude para cada café variety:
db.coffee.aggregate( [ { $densify: { field: "altitude", partitionByFields: [ "variety" ], range: { bounds: "full", step: 200 } } } ] )
A agregação de exemplo:
Partições dos documentos por
varietypara criar um cluster paraArabica Typicae um paraGeshacafé.Especifica um intervalo do
full, significando que os dados são densificados ao longo do intervalo completo de documentos existentes para cada partição.Especifica um
stepde200, o que significa que novos documentos são criados em intervalos dealtitudede200.
A aggregation produz os seguintes documentos:
[ { _id: ObjectId("618c031814fbe03334480475"), altitude: 600, variety: 'Arabica Typica', score: 68.3 }, { _id: ObjectId("618c031814fbe03334480476"), altitude: 750, variety: 'Arabica Typica', score: 69.5 }, { variety: 'Arabica Typica', altitude: 800 }, { _id: ObjectId("618c031814fbe03334480477"), altitude: 950, variety: 'Arabica Typica', score: 70.5 }, { variety: 'Gesha', altitude: 600 }, { variety: 'Gesha', altitude: 800 }, { variety: 'Gesha', altitude: 1000 }, { variety: 'Gesha', altitude: 1200 }, { _id: ObjectId("618c031814fbe03334480478"), altitude: 1250, variety: 'Gesha', score: 88.15 }, { variety: 'Gesha', altitude: 1400 }, { variety: 'Gesha', altitude: 1600 }, { _id: ObjectId("618c031814fbe03334480479"), altitude: 1700, variety: 'Gesha', score: 95.5, price: 1029 }, { variety: 'Arabica Typica', altitude: 1000 }, { variety: 'Arabica Typica', altitude: 1200 }, { variety: 'Arabica Typica', altitude: 1400 }, { variety: 'Arabica Typica', altitude: 1600 } ]
Esta imagem exibe os documentos criados com $densify:

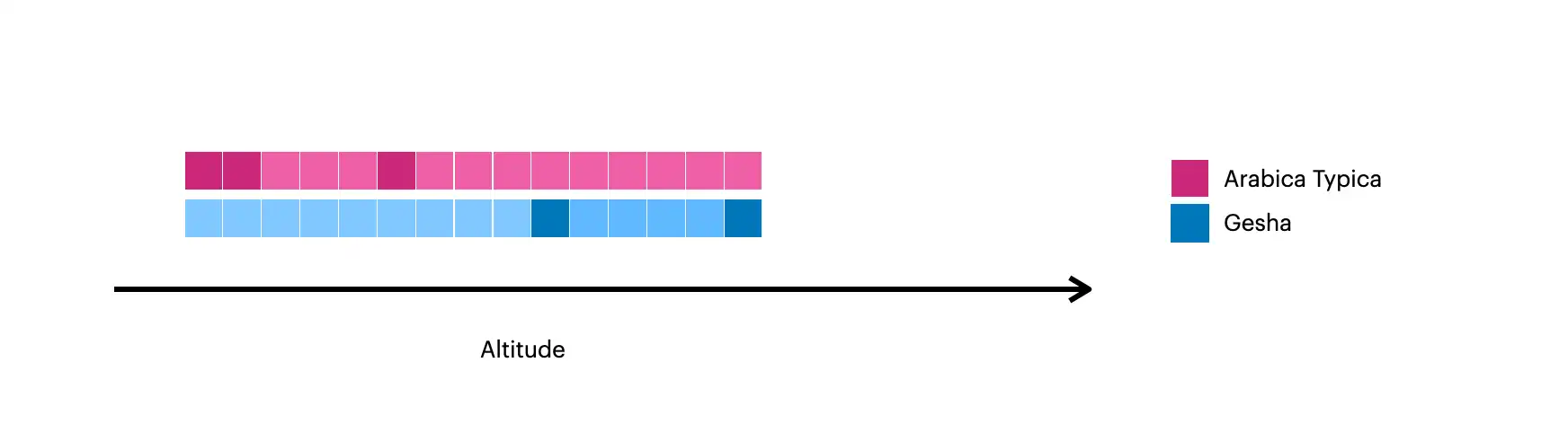
Os quadrados mais escuros representam os documentos originais na coleção.
Os quadrados mais claros representam os documentos criados com
$densify.
Densificar valores dentro de cada peça
Este exemplo utiliza $densify para somente densificar lacunas no campo altitude dentro de cada variety:
db.coffee.aggregate( [ { $densify: { field: "altitude", partitionByFields: [ "variety" ], range: { bounds: "partition", step: 200 } } } ] )
A agregação de exemplo:
Partições dos documentos por
varietypara criar um cluster paraArabica Typicae um paraGeshacafé.Especifica um intervalo
partition, significando que os dados são densificados dentro de cada partição.Para a partição
Arabica Typica, o intervalo é600-950.Para a partição
Gesha, o intervalo é1250-1700.
Especifica um
stepde200, o que significa que novos documentos são criados em intervalos dealtitudede200.
A aggregation produz os seguintes documentos:
[ { _id: ObjectId("618c031814fbe03334480475"), altitude: 600, variety: 'Arabica Typica', score: 68.3 }, { _id: ObjectId("618c031814fbe03334480476"), altitude: 750, variety: 'Arabica Typica', score: 69.5 }, { variety: 'Arabica Typica', altitude: 800 }, { _id: ObjectId("618c031814fbe03334480477"), altitude: 950, variety: 'Arabica Typica', score: 70.5 }, { _id: ObjectId("618c031814fbe03334480478"), altitude: 1250, variety: 'Gesha', score: 88.15 }, { variety: 'Gesha', altitude: 1450 }, { variety: 'Gesha', altitude: 1650 }, { _id: ObjectId("618c031814fbe03334480479"), altitude: 1700, variety: 'Gesha', score: 95.5, price: 1029 } ]
Esta imagem exibe os documentos criados com $densify:

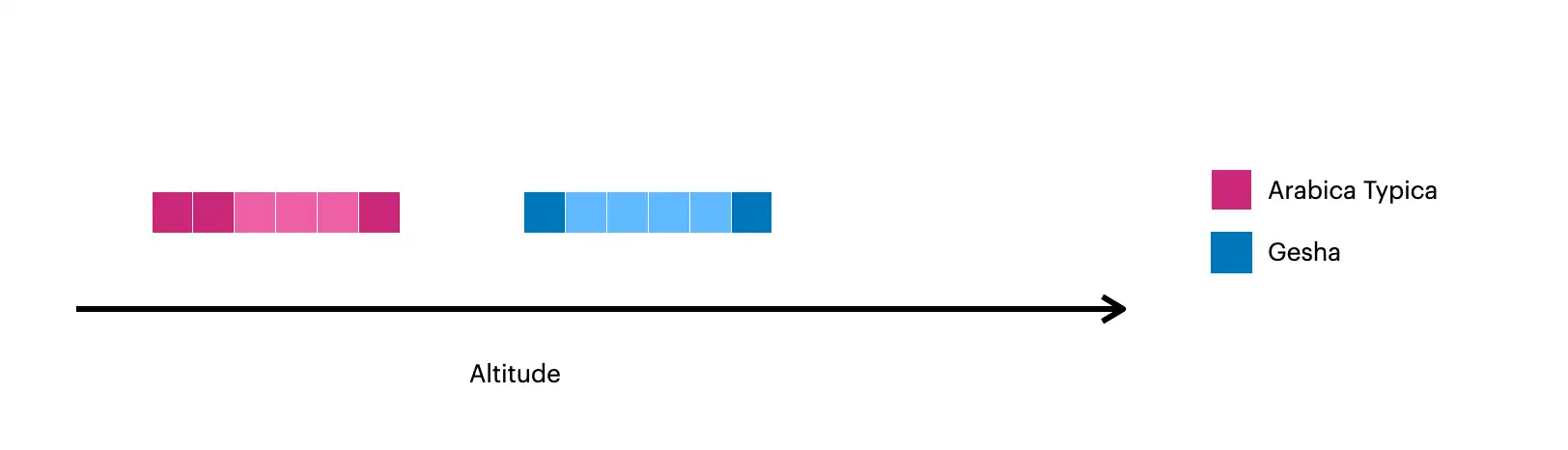
Os quadrados mais escuros representam os documentos originais na coleção.
Os quadrados mais claros representam os documentos criados com
$densify.
Os exemplos de C# nesta página usam a collection sample_weatherdata.data dos conjuntos de dados de amostra do Atlas. Para saber como criar um cluster MongoDB Atlas gratuito e carregar os conjuntos de dados de exemplo, consulte Introdução na documentação do driver MongoDB .NET/C#.
As seguintes classes Weather e Point modelam os documentos na collection sample_weatherdata.data:
public class Weather { public Guid Id { get; set; } public Point Position { get; set; } [] public DateTime Timestamp { get; set; } } public class Point { public float[] Coordinates { get; set; } }
A collection sample_weatherdata.data contém os seguintes documentos, que contêm medições para o mesmo campo de position, com uma hora de intervalo:
Document{{ _id=5553a..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:00:00 EST 1984, ... }} Document{{ _id=5553b..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 09:00:00 EST 1984, ... }}
Para usar o driver MongoDB .NET/C# para adicionar um estágio $densify a um pipeline de agregação, chame o método Densify() em um objeto PipelineDefinition.
O exemplo a seguir cria um estágio de pipeline que adiciona um documento a cada intervalo de 15minutos entre os dois documentos anteriores. O código então agrupa esses documentos pelos valores de seu campo Position.Coordinates.
var densifyTimeRange = new DensifyDateTimeRange( new DensifyLowerUpperDateTimeBounds( lowerBound: new DateTime(1984, 3, 5, 8, 0, 0), upperBound: new DateTime(1984, 3, 5, 9, 0, 0) ), step: 15, unit: DensifyDateTimeUnit.Minutes ); var pipeline = new EmptyPipelineDefinition<Weather>() .Densify( field: w => w.Timestamp, range: densifyTimeRange, partitionByFields: [w => w.Position.Coordinates]);
O estágio de agregação anterior gera os seguintes documentos destacados na coleção:
Document{{ _id=5553a..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:00:00 EST 1984, ... }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:15:00 EST 1984 }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:30:00 EST 1984 }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:45:00 EST 1984 }} Document{{ _id=5553b..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 09:00:00 EST 1984, ... }}
Os exemplos de Node.js nesta página usam a coleção sample_weatherdata.data dos conjuntos de dados de amostra do Atlas. Para aprender como criar um cluster gratuito do MongoDB Atlas e carregar os conjuntos de dados de amostra, consulte Introdução na documentação do driver MongoDB Node.js.
A collection sample_weatherdata.data contém os seguintes documentos, que contêm medições para o mesmo campo de position, com uma hora de intervalo:
{_id: new ObjectId(...), ts: 1984-03-05T13:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }, {_id: new ObjectId(...), ts: 1984-03-05T14:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }
Para usar o driver Node.js do MongoDB para adicionar um estágio $densify a um pipeline de agregação , use o operador $densify em um objeto de pipeline.
O exemplo a seguir cria um estágio de pipeline que adiciona um documento a cada intervalo de 15minutos entre os dois documentos anteriores. O código então agrupa esses documentos pelos valores de seu campo position.coordinates. Em seguida, o exemplo executa o agregação pipeline:
const pipeline = [ { $densify: { field: "ts", partitionByFields: ["position.coordinates"], range: { step: 15, unit: "minute", bounds: [new Date(1984, 3, 5, 8, 0, 0), new Date(1984, 3, 5, 9, 0, 0)] } } } ]; const cursor = collection.aggregate(pipeline); return cursor;
O estágio de agregação anterior gera os seguintes documentos destacados na coleção:
{ _id: new ObjectId(...), ts: 1984-03-05T13:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:15:00.000Z }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:30:00.000Z }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:45:00.000Z }, { _id: new ObjectId(...), ts: 1984-03-05T14:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }