- $cmd
- Una virtual colección que expone los comandos de base de datos de MongoDB. Para usar comandos de base de datos, ve Emitir comandos.
- _id
- Un campo obligatorio en todos los documentos de MongoDB. El campo _id debe tener un valor único. Puedes pensar en...
_idcampo como la clave primaria del documento. Si creas un nuevo documento sin un campo_id, MongoDB crea automáticamente el campo y le asigna un ObjectId BSON único. - utilización absoluta de la CPU del sistema
Uso de la CPU del sistema en relación con la cantidad total de CPU disponible para las instancias en la nube que comparten CPU.
Cuando un proveedor de nube limita la utilización de la CPU para una instancia de la nube, la utilización absoluta de la CPU del sistema de la instancia es igual a la utilización de la CPU base asignada a esta instancia.
Cuando un proveedor de nube agrega CPU por encima de la CPU base, como a través de un mecanismo de ráfagas, la suma de la utilización normalizada de la CPU del núcleo y la utilización de la CPU del usuario en una instancia puede exceder la CPU base de la instancia. En este caso, la suma de la utilización normalizada de la CPU del núcleo y la utilización de la CPU del usuario sigue siendo inferior a la cantidad total de CPU compartida por las instancias en la nube. Consulta también utilización relativa de la CPU del sistema, utilización de la CPU base e instancias de ráfaga.
- acumulador
- Una expresión en un pipeline de agregación que mantiene el estado entre documentos en el pipeline de agregación. Para obtener una lista de operaciones de acumuladores, consulta
$group. - acción
- Una operación que el usuario puede realizar en un recurso. Las acciones y los recursos se combinan para crear privilegios. Consultar acción.
- base de datos admin
- Una base de datos con privilegios. Los usuarios deben tener acceso a la base de datos
adminpara ejecutar ciertos comandos administrativos. Para obtener una lista de los comandos administrativos, consulta Administration Commands. - Amenaza Avanzada Persistente
- En seguridad, un atacante que obtiene y mantiene acceso a largo plazo a la red, el disco y/o la memoria y permanece sin ser detectado durante un período extendido.
- Agregación
- Una operación que reduce y resume grandes conjuntos de datos. Para obtener más información, consultar Operaciones de Agregación.
- Aggregation Pipeline
- Consta de una o más etapas que procesan documentos. Los pipelines de agregación ofrecen una sintaxis rica para expresar los query complejos. Para obtener una lista de las etapas, consulta Etapas de agregación.
- alerta
Notificación enviada por Atlas cuando las operaciones de la base de datos o el uso del servidor alcanzan umbrales que afectan el rendimiento del clúster. Para aprender qué condiciones se puede configurar para activar alertas, se debe consultar Revisión de condiciones de alerta.
- nodo de análisis
- Nodo especializado de solo lectura que puede aislar los query para que no afecten la carga de trabajo operativa. Los nodos de análisis son útiles para manejar datos analíticos, como los query de reporte ejecutados por herramientas de BI. Se puede alojar nodos de análisis en regiones geográficas dedicadas para optimizar el rendimiento de lectura y reducir la latencia.
- API
Protocolo de comunicación que facilita la interacción entre el cliente y MongoDB Atlas. Puede utilizarse la API de administración de Atlas para automatizar muchas de las tareas realizadas en la interfaz de usuario de Atlas.
- Búsqueda aproximada del vecino más cercano (ANN)
Técnica computacional utilizada para encontrar rápidamente puntos en un conjunto de datos cercanos a un punto de consulta determinado. La Búsqueda Vectorial de MongoDB utiliza la búsqueda ANN para encontrar incrustaciones vectoriales en los datos más cercanas a las incrustaciones vectoriales de la consulta, sin escanear cada vector.
- árbitro
- Un nodo de un set de réplicas que existe solo para votar en elecciones. Los árbitros no replican datos. Un árbitro participa en las elecciones para un primario, pero no puede convertirse en uno. Para más detalles, consultar Árbitro del set de réplicas.
- Atlas
- MongoDB Atlas es una base de datos como servicio en la nube.
- Atlas user
Cuenta utilizada para acceder a la aplicación MongoDB Atlas. Puedes otorgar a los usuarios de MongoDB Atlas acceso a organizaciones, proyectos o ambos de MongoDB Atlas, con ciertos permisos definidos por roles de usuario. Un usuario de MongoDB Atlas es diferente de un usuario de base de datos. Los usuarios de MongoDB Atlas no otorgan acceso a ninguna base de datos de MongoDB.
- Atlas user role
Conjunto de permisos otorgados a un Atlas user. Puedes conceder permisos a nivel de organización o de proyecto.
- operación atómica
- Una operación atómica es una operación de guardar que se finaliza por completo o no se completa en absoluto. Para las transacciones distribuidas, que implican escrituras en varios documentos, todas las escrituras en cada documento deben tener éxito para que la transacción tenga éxito. Las operaciones atómicas no pueden completarse de manera parcial. Consultar Atomicidad y transacciones.
- Autenticación
- Verificación de la identidad del usuario. Consulta Autenticación en implementaciones autogestionadas.
- Autorización
- Provisionamineto de acceso a bases de datos y operaciones. Consulta Control de acceso basado en roles en implementaciones autogestionadas.
- Escalado automático
Opción configurable para que el clúster aumente o disminuya automáticamente su nivel de clúster, su capacidad de almacenamiento o ambos en respuesta al uso del clúster.
- cifrado automático
- Al utilizar encriptación en uso, se realiza automáticamente el cifrado y descifrado según el esquema de cifrado preconfigurado. La Librería compartida de cifrado automático traduce el lenguaje de la query de MongoDB en la llamada correcta, lo que significa que no se necesita reescribir la aplicación para llamadas específicas de cifrado y descifrado.
- B-tree
- Una estructura de datos comúnmente utilizada por los sistemas de gestión de bases de datos para almacenar índices. MongoDB utiliza índices B-tree.
- Backup
Copia de los datos que encapsula el estado del clúster en un momento determinado. Las copias de seguridad ofrecen una medida de protección en caso de eventos de pérdida de datos.
MongoDB Atlas proporciona copias de seguridad en la nube totalmente gestionadas.
- cursor de copia de seguridad
- Un cursor con seguimiento que apunta a una lista de archivos de copia de seguridad. Los cursores de copia de seguridad son solo para uso interno.
- balanceador
- Un proceso interno de MongoDB que se ejecuta en el contexto de un clúster particionado y gestiona la migración de fragmentos. Los administradores deben desactivar el balanceador para todas las operaciones de mantenimiento en un clúster particionado. Consultar Balanceador de clúster particionado.
- utilización de la CPU base
- Fracción de la cantidad total de CPU disponible para las instancias en la nube que comparten CPU. Un proveedor de nube asigna una cierta cantidad de CPU base a cada instancia en la nube, según el nivel de clúster de la instancia. Normalmente, la utilización de la CPU base se sitúa entre 20% y 50% de la utilización absoluta de la CPU del sistema. Consulta también utilización relativa de la CPU del sistema e instancias ráfaga.
- big-endian
Un orden de bytes en el que el byte más significativo (big end) de un valor de datos multibyte se almacena en la dirección de memoria más baja.
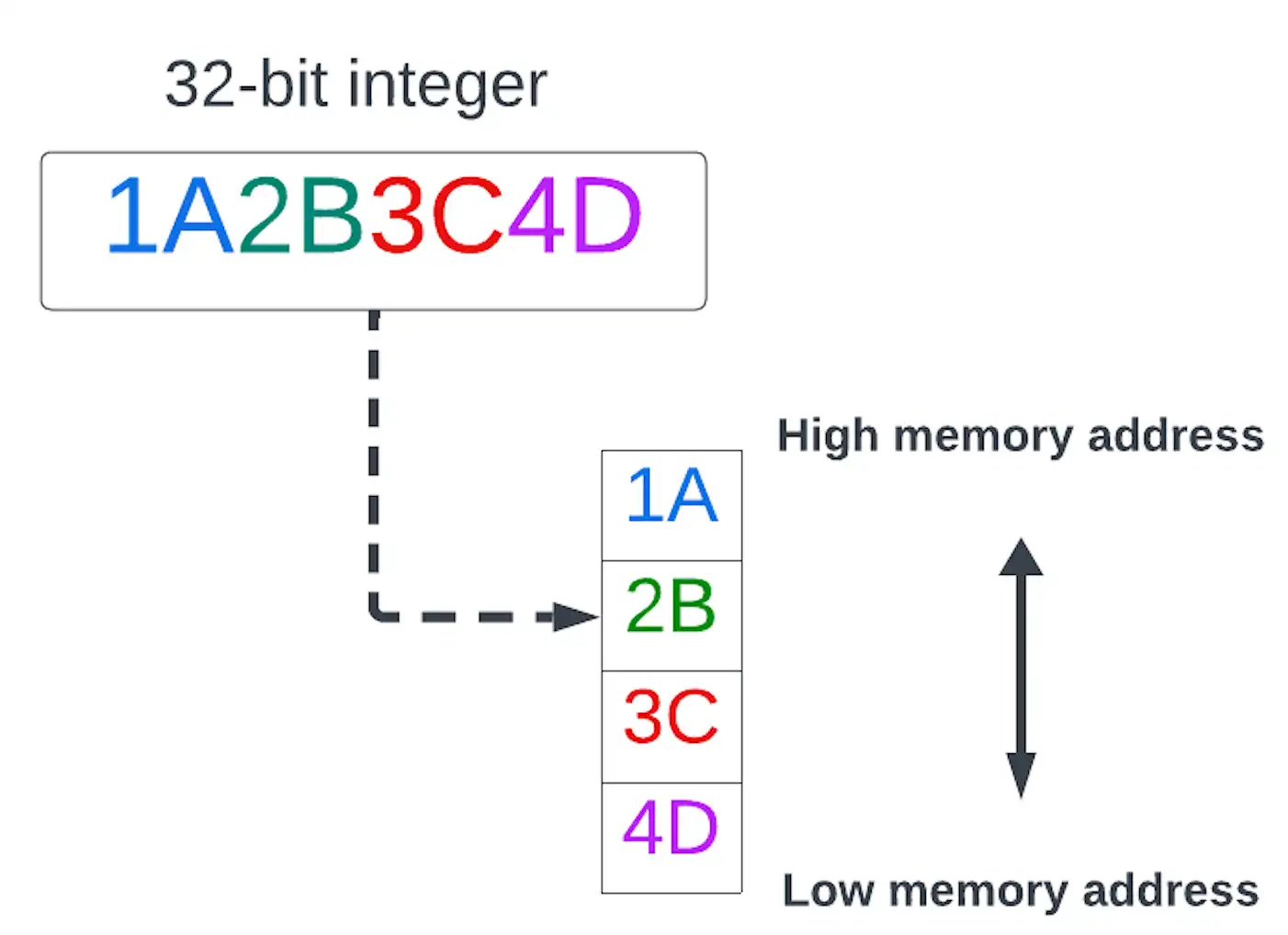 haga clic para ampliar
haga clic para ampliar- ordenamiento bloqueante
- Un ordenamiento que debe realizarse en memoria antes de que se devuelvan los resultados. Los ordenamientos en memoria pueden afectar el rendimiento para conjuntos de datos grandes. Utiliza una ordenación indexada para evitar una ordenación en memoria.
- escaneo acotado de colección
- Un plan utilizado por el optimizador del query que excluye documentos con rangos de valores específicos de campo. Por ejemplo, si un rango de valores de campo de fecha está fuera de un rango de fechas especificado, los documentos en ese rango se excluyen del plan del query. Consulta el escaneo de colección.
- BSON
- Un formato de serialización utilizado para almacenar documentos y realizar llamadas a procedimientos remotos en MongoDB. "BSON" es una combinación de las palabras "binary" y "JSON". Piensa en BSON como una representación binaria de documentos JSON (JavaScript Object Notation). Consulta BSON types y MongoDB Extended JSON (v2).
- BSON types
- El conjunto de tipos admitidos por el formato de serialización BSON. Para obtener una lista de BSON types, consultar BSON Types.
- instancias ráfaga
- Tipos de instancias en la nube que comparten una CPU física común y que, para algunos proveedores de nube, utilizan un modelo de "crédito de CPU". Al usar instancias con capacidad de expansión, partes de la CPU compartida pueden estar disponibles para cada instancia virtual o no estarlo, según la demanda de los recursos de la instancia. Para obtener más información, consulte Instancias con capacidad de expansión de AWS.Explosión de disco de Azure y Explosión de CPU de GCP. Consulte también utilización de CPU de referencia, utilización absoluta de CPU del sistema y utilización relativa de CPU del sistema.
- Teorema CAP
- Dadas tres propiedades de los sistemas de computación, coherencia, disponibilidad y tolerancia a particiones, un sistema de computación distribuido puede proporcionar dos de estas características, pero nunca las tres.
- colección con tamaño fijo
- Una colección de tamaño fijo que sobrescribe automáticamente sus entradas más antiguas cuando la colección alcanza su tamaño máximo. El oplog de MongoDB que se utiliza en la replicación es una colección con tamaño fijo. Consulta Colecciones con tamaño fijo.
- cardinalidad
- La medida del número de elementos dentro de un conjunto de valores. Por ejemplo, el conjunto
A = { 2, 4, 6 }contiene 3 elementos y tiene una cardinalidad de 3. Consulta Cardinalidad de la clave de partición. - producto cartesiano
- El resultado de combinar dos conjuntos de datos donde el conjunto combinado contiene todas las combinaciones posibles de valores.
- cfq (Planificador de I/O de Equidad Completa)
- Complete Fairness Queueing (CFQ (Planificador de I/O de Equidad Completa)) es un planificador de operaciones de E/S que asigna ancho de banda para los procesos de solicitudes entrantes.
- suma de verificación
- Un valor calculado utilizado para garantizar la integridad de los datos. El algoritmo md5 a veces se utiliza como suma de verificación.
- fragmento
- Un rango contiguo de valores de clave de partición dentro de una partición. Los rangos de fragmentos incluyen el límite inferior y no incluyen el límite superior. MongoDB divide los fragmentos cuando es necesario equilibrar los datos dentro del clúster. Aunque el tamaño establecido por defecto del fragmento es de 128 megabytes, es posible que los fragmentos crezcan y superen el tamaño establecido por defecto sin activar una división automática. La división de fragmentos ocurre como parte del proceso de balanceo para distribuir los datos uniformemente en todo el clúster. Para obtener más detalles, consultar Particionamiento de datos con fragmentos, Balanceador del clúster particionado y Gestionar el balanceador del clúster particionado.
- Cliente
La capa de aplicación que utiliza una base de datos para la persistencia y el almacenamiento de datos. Los controladores otorgan el nivel de interfaz entre la capa de aplicación y el servidor de bases de datos.
Un cliente también puede ser un único hilo o proceso.
- afinidad de cliente
- Una conexión de cliente coherente a una fuente de datos especificada.
- copias de seguridad en la nube
Almacenamiento de copia de seguridad localizado en el clúster utilizando la funcionalidad nativa de snapshot del proveedor de servicios en la nube del clúster.
MongoDB Atlas admite copias de seguridad en la nube para clústeres servidos en:
- clúster
Conjunto de nodos que componen una implementación de MongoDB. Los clústeres pueden ser sets de réplicas o implementaciones particionadas.
- clase de clúster
Configurable para clústeres M40+ alojados en AWS.
Clase de almacenamiento del clúster. La clase que se ha seleccionado afecta el rendimiento del almacenamiento del clúster y los costos del clúster. Se puede elegir una de las siguientes clases:
Low CPU
General
Local NVMe SSD
- nivel de clúster
Dicta la memoria, el almacenamiento, las vCPU y Especificación de IOPS para cada servidor portador de datos en el clúster. El tamaño del almacenamiento del clúster y el rendimiento general aumentan a medida que aumenta el nivel del clúster.
- cluster-to-cluster sync
- Sincroniza datos entre clústeres particionados. También se conoce como sincronización C2C.
- colección con índice clusterizado
- Una colección que almacena documentos ordenados por una clave de índice clusterizado. Consultar Colecciones con índice clusterizado.
- CMK
- Abreviatura de llave maestra de cliente, consulta Llave maestra de cliente.
- Colección
- Una agrupación de documentos de MongoDB. Una colección es el equivalente a una tabla de RDBMS. Una colección se encuentra en una única base de datos. Las colecciones no imponen un esquema. Los documentos en una colección pueden tener diferentes campos. Por lo general, los documentos en una colección tienen un propósito similar o relacionado. Consulta Restricciones de nombres.
- escaneo de colección
- Los escaneos de colección son una estrategia de ejecución de queries en la que MongoDB debe inspeccionar cada documento de una colección para verificar si cumple con los criterios de query. Estos query son muy ineficientes y no utilizan índices. Consulte Optimización de los query para obtener más información sobre las estrategias de ejecución de consultas.
- confirmación
- Guarda los cambios de datos realizados después del inicio del comando
startSession. Las operaciones dentro de una transacción no son permanentes hasta que se confirman con el comandocommitTransaction. - quórum de confirmación
- Durante una creación de índices, el quórum de confirmación especifica cuántos secundarios deben estar listos para confirmar su creación de índices local antes de que el nodo primario realice la confirmación.
- Índice compuesto
- Un índice que consiste de dos o más claves. Consultar Índices compuestos.
- control de concurrencia
- El control de concurrencia asegura que las operaciones de la base de datos puedan ejecutarse concurrentemente sin comprometer la precisión. El control de concurrencia pesimista, como el que se utiliza en sistemas con bloqueos, bloquea cualquier operación potencialmente conflictiva, incluso si no entran en conflicto. El control de concurrencia optimista, el enfoque utilizado por WiredTiger, retrasa la comprobación hasta después de que pueda haber ocurrido un conflicto, finalizando y reintentando una de las operaciones en cualquier conflicto de escritura.
- config database
- Una base de datos interna con metadatos para un clúster particionado. Normalmente, no modificas la base de datos
config. Para obtener más información sobre la base de datosconfig, consulta Base de datos de configuración. - config server
- Una instancia de
mongodque almacena todos los metadatos asociados con un clúster particionado. Consultar Servidores de configuración. - partición de configuración
- Una instancia de
mongodque almacena todos los metadatos asociados con un clúster fragmentado y también puede almacenar datos de aplicaciones. Consulta Particiones de configuración. - pool de conexiones
- Una caché de conexiones a bases de datos mantenida por el controlador. Las conexiones en caché se reutilizan cuando se requieren conexiones a la base de datos, en lugar de abrir nuevas conexiones.
- tormenta de difusión
- Un escenario en el que un controlador intenta abrir más conexiones a una implementación de las que esa implementación puede gestionar. Cuando las solicitudes de nuevas conexiones fallan, el controlador solicita establecer aún más conexiones en respuesta a que la implementación se ralentiza o no logra abrir nuevas conexiones. Estas solicitudes continuas pueden sobrecargar la implementación y provocar interrupciones del servicio.
- contenedor
- Un conjunto de software y sus librerías dependientes empaquetados juntos para facilitar la transferencia entre entornos informáticos. Los contenedores se ejecutan como procesos compartimentados en el sistema operativo y pueden tener sus propias restricciones de recursos. Las tecnologías comunes de contenedores son Docker y Kubernetes.
- factor de contención
- Varias operaciones que intentan modificar el mismo recurso, como un campo de documento, generan conflictos que retrasan las operaciones. El factor de contención es una configuración utilizada con Queryable Encryption para particionar internamente los pares de campo/valor cifrados y optimizar las operaciones. Ver contención.
- similitud coseno
- Métrica que utiliza el ángulo entre dos vectores para determinar la similitud entre esos vectores. La similitud del coseno es sensible a la orientación del vector. Puede utilizar la función de similitud del coseno al indexar sus incrustaciones de vectores para MongoDB Vector Search. Si los vectores están normalizados a longitud unitaria, usa la función similitud del producto escalar en su lugar.
- Robo de CPU
- El porcentaje en el que el uso de la CPU supera la tasa base garantizada de acumulación de créditos de CPU. El robo de CPU es relevante para los proveedores de nube que dependen del modelo de crédito en su estrategia de ráfagas. Los créditos de CPU son unidades de utilización de la CPU que acumulas. Los créditos se acumulan a un ritmo constante para proporcionar un nivel con garantías de rendimiento. Puedes usar estos créditos para obtener un rendimiento adicional de la CPU. Cuando se agota el saldo de crédito, MongoDB solo proporciona la línea de base garantizada del rendimiento de la CPU y muestra la cantidad de exceso como porcentaje de robo. Consulta también uso relativo de la CPU del sistema, uso de la CPU de línea de base e instancias con capacidad de ráfaga.
- CRUD
- Un acrónimo para las operaciones fundamentales de una base de datos: crear, leer, actualizar y borrar (CRUD, por sus siglas en inglés). Vea Operaciones CRUD de MongoDB.
- CSV
- Un formato de datos de texto con valores separados por comas. Los archivos CSV pueden utilizarse para intercambiar datos entre bases de datos relacionales porque contienen datos tabulares. Puedes importar archivos CSV usando
mongoimport. - cursor
- Un puntero al conjunto de resultados de un query. Los clientes pueden iterar a través de un cursor para recuperar resultados. Por defecto, los cursores que no se abren dentro de una sesión se cierran automáticamente después de 10 minutos de inactividad. Los cursores abiertos en una sesión se cierran al finalizar o al agotarse el tiempo de espera de la sesión. Consulta Cursores.
- rol personalizado
Conjunto personalizado de acciones de privilegio de MongoDB y roles de MongoDB que puede guardar y asignar a un usuario de base de datos. Crea roles personalizados cuando los roles integrados de MongoDB Atlas no describan el conjunto de privilegios que deseas.
- Llave maestra de cliente
- Una llave que cifra la llave de cifrado de datos. La llave maestra de cliente debe estar alojada en un proveedor de claves remoto.
- daemon
- Un proceso en segundo plano, no interactivo.
- directorio de datos
- La ubicación del sistema de archivos donde
mongodalmacena los archivos de datos.dbPathespecifica el directorio de datos. - Llave de cifrado de datos
- Una clave que se usa para cifrar los campos en los documentos de MongoDB. La llave de cifrado de datos cifrada se almacena en la colección de Bóvedas de Llaves. La llave maestra de cliente se encarga del cifrado de la llave de cifrado de datos.
- Data Explorer
Herramienta dentro de MongoDB Atlas para ver e interactuar con los datos del clúster. También puedes utilizar el Explorador de Datos para gestionar índices y ejecutar pipelines de agregación para procesar tus datos.
- Federación de Datos
Solución de MongoDB para consultar datos almacenados en depósitos S3 de bajo costo, clústeres de MongoDB Atlas y puntos finales HTTP utilizando el languaje del query de MongoDB. Las aplicaciones de análisis pueden utilizar Atlas Data Federation para aprovechar los datos archivados en sus necesidades de procesamiento de datos.
- archivos de datos
- Almacenar datos e índices de documentos. La opción
dbPathespecifica la ubicación del sistema de archivos para los archivos de datos. - pipeline de ingesta de datos
- Flujo de trabajo para organizar y transformar datos utilizando RAG y almacenarlos en una base de datos vectorial como MongoDB Atlas.
- partición de datos
- Una arquitectura de sistema distribuido que realiza la división de datos en rangos. Fragmentación utiliza particionamiento. Vea particionamiento de bloque de información.
- conciencia del centro de datos
- Una propiedad que permite a los clientes dirigirse a los nodos de un sistema en función de sus ubicaciones. Los sets de réplicas implementan la conciencia del centro de datos utilizando etiquetado. Consulta Conciencia del centro de datos.
- database
- Un contenedor para colecciones. Cada base de datos tiene un conjunto de archivos en el sistema de archivos. Un servidor MongoDB suele tener múltiples bases de datos.
- comando de base de datos
- Una operación de MongoDB, distinta de una inserción, actualización, eliminación o query. Para obtener una lista de comandos de base de datos, consulta Comandos de base de datos. Para usar comandos de base de datos, consulta Emitir comandos.
- exfiltración de base de datos
- La exfiltración de base de datos se refiere a que una parte autorizada toma datos de un sistema seguro y hace uso compartido de estos con una parte no autorizada o los almacena en un sistema no seguro. Esto puede deberse a un accionar malicioso o accidental.
- database profiler
- Una herramienta que, cuando se habilita, mantiene un registro de todas las operaciones de larga duración en la colección
system.profilede una base de datos. El perfilador se utiliza con mayor frecuencia para diagnosticar los query lentos. Ve Perfilador de base de datos. - usuario de base de datos
Credenciales utilizadas para autenticar a un cliente para acceder a un clúster de MongoDB. Puedes asignar privilegios a un usuario de base de datos para determinar el nivel de acceso de ese usuario a un clúster. Los usuarios de base de datos son diferentes de los usuarios de Atlas. Los usuarios de base de datos tienen acceso a las implementaciones de MongoDB, no a la aplicación MongoDB Atlas.
- dbpath
- La ubicación del almacenamiento de archivos de datos de MongoDB. Ve
dbPath. - DDL (Lenguaje de Definición de Datos)
- DDL incluye comandos que crean y modifican colecciones e índices.
- fila de letra muerta
- Una fila de letra muerta es una colección dentro de una base de datos de MongoDB Atlas que almacena documentos que generan errores durante la ingestión.
- clúster dedicado
Categoría de clúster que contiene clústeres de nivel
M10y superior.NivelEntornos recomendadosM10yM20Desarrollo
Producción de baja carga de tráfico
M30y superiorProducción
- servidor de configuración dedicado
- Una instancia de
mongodque almacena únicamente todos los metadatos asociados con un clúster fragmentado. - DEK
- Llave de cifrado de datos. Para obtener más detalles, consultar llave de cifrado de datos.
- miembro atrasado
- Un nodo del set de réplicas que no puede convertirse en primario y aplica operaciones con un retraso especificado. El retraso es útil para proteger los datos de errores humanos (como bases de datos borradas involuntariamente) o de actualizaciones que tienen efectos imprevistos en la base de datos de producción. Consultar Nodos del set de réplicas con retraso.
- vectores densos
- Representación numérica de datos donde la mayoría o la totalidad de las dimensiones contienen valores distintos de cero. MongoDB Vector Search se basa en vectores densos, que contienen más información, para capturar relaciones más complejas.
- implementación
- Un grupo de servidores de MongoDB que contienen tus datos. Los clústeres gestionados por MongoDB Atlas son clústeres (set de réplicas o clústeres particionados).
- dimensión
- Número de componentes o elementos que constituyen las funcionalidades o atributos de los datos en un espacio multidimensional. MongoDB Vector Search admite hasta
4096dimensiones en el momento de la indexación y la query. - Documento
- Un registro en una colección de MongoDB y la unidad básica de datos en MongoDB. Los documentos son análogos a objetos JSON, pero existen en la base de datos más en un formato del tipo texto enriquecido conocido como BSON. Consulta Documentos.
- Notación de puntos
- MongoDB utiliza la notación de puntos para acceder a los elementos de un arreglo y a los campos de un documento incrustado. Consultar notación de puntos.
- similitud de producto punto
- Mide la similitud entre dos vectores en un espacio multidimensional y devuelve un valor escalar. Este valor es positivo cuando los vectores apuntan aproximadamente en la misma dirección, negativo cuando apuntan en direcciones opuestas y cero cuando no tienen similitud. MongoDB Vector Search admite el uso de la función de similitud
dotproductal buscar vectores vecinos más cercanos. Recomendamos esta función de similitud en lugar de la similitud de coseno si los vectores están normalizados a longitud unitaria. - drenar
- El proceso de remover o "desprender" fragmentos de una partición a otra. Los administradores deben vaciar las particiones antes de removerlas del clúster. Consulta Remover particiones de un clúster fragmentado.
- controlador
- Una librería de clientes para interactuar con MongoDB en un lenguaje de programación específico. Consulta controlador.
- durable
- Una operación de escritura es duradera cuando persiste después de un apagado (o fallo) y se reinician uno o más procesos del servidor. Para un único servidor
mongod, una operación de escritura se considera durable cuando se ha escrito en el archivo de registro en la bitácora del servidor. Para un set de réplicas, una operación de escritura se considera duradera después de que la operación de escritura logre durabilidad en la mayoría de los nodos de votación y se escriba en la mayoría de los registros en la bitácora de los nodos de votación. - nodo elegible
- Nodo que es elegible para convertirse en el miembro primario del set de réplicas. MongoDB Atlas prioriza los nodos en la región de mayor prioridad para la elegibilidad como primario durante las elecciones. Para garantizar elecciones confiables, el número total de nodos elegibles en toda una región debe ser 3, 5 o 7.
- elección
- El proceso por el cual los nodos de un set de réplicas seleccionan un primario al iniciarse y en caso de fallo. Consulta Elecciones de sets de réplicas.
- integración
- Representación de datos como texto, imágenes, audio, vídeo, etc., como una matriz de números, que pueden interpretarse como coordenadas en un espacio multidimensional. MongoDB Atlas permite almacenar incrustaciones en un clúster de MongoDB Atlas, y MongoDB Vector Search permite indexar y consultar incrustaciones vectoriales de hasta
4096dimensiones. - llave de cifrado
String aleatoria de bits generada específicamente para cifrar y descifrar datos.
MongoDB Atlas
Project Ownerspuede configurar una capa adicional de cifrado en sus datos además del cifrado en reposo por defecto que MongoDB Atlas proporciona. Los propietarios de proyectos pueden utilizar su proveedor de gestión de claves de cliente compatible con MongoDB Atlas con el motor de almacenamiento cifrado de MongoDB.MongoDB Atlas admite los siguientes proveedores de gestión de claves de clientes al configurar el cifrado en reposo:
- esquema de cifrado
- En Queryable Encryption, el documento encryptedFields que define qué campos son consultables y qué tipos de query están permitidos en esos campos.
- endianness
- En informática, la endianidad se refiere al orden en que se disponen los bytes. Este orden puede referirse a la transmisión a través de un medio de comunicación o, más comúnmente, a cómo se ordenan los bytes en la memoria de la computadora, según su importancia y posición. Para obtener más detalles, consulta big-endian y little-endian.
- encriptación de sobre
- Un procedimiento de cifrado en el que los datos se cifran utilizando una llave de cifrado de datos y la llave de cifrado de datos se cifra con otra llave llamada Llave maestra de cliente. Las llaves cifradas se almacenan como documentos BSON en una colección de MongoDB llamada KeyVault.
- similitud euclidiana
- Fórmula para calcular la similitud utilizando la distancia entre dos vectores en un espacio multidimensional. La distancia euclidiana es sensible a la magnitud de los vectores. MongoDB Vector Search permite usar la función de similitud
euclideanpara indexar vectores y al buscar los vecinos más cercanos. - coherencia eventual
- Una propiedad de un sistema distribuido que permite que los cambios en el sistema se propaguen gradualmente. En un sistema de base de datos, esto significa que no se requiere que los nodos de lectura tengan las actualizaciones más recientes.
- cifrado explícito
- Al utilizar encriptación en uso, especificando explícitamente la operación de cifrado o descifrado, el ID de clave y el tipo de query (para Queryable Encryption) o el algoritmo (para cifrado a nivel de campo del lado del cliente) al trabajar con datos cifrados. Comparar con cifrado automático.
- expresión
Un componente de una query que se resuelve en un valor. Las expresiones no tienen estado, lo que significa que devuelven un valor sin modificar ninguno de los valores utilizados para crear la expresión.
En el lenguaje del query de MongoDB, puedes crear expresiones a partir de los siguientes componentes:
ComponenteEjemploConstantes
3Operadores
Expresiones de ruta de campo
"$<path.to.field>"Por ejemplo,
{ $add: [ 3, "$inventory.total" ] }es una expresión que consta del operador$addy dos operandos:La constante
3La expresión de ruta de campo
"$inventory.total"
La expresión devuelve el resultado de sumar 3 al valor en la ruta
inventory.totaldel documento de entrada.- conmutación por error
- El proceso que permite a un nodo secundario de un set de réplicas convertirse en primario en caso de fallo. Consultar conmutación por error automática.
- Campo
- Un par nombre-valor en un documento. Un documento tiene cero o más campos. Los campos son análogos a las columnas en las bases de datos relacionales. Consultar Estructura del documento.
- ruta de campo
- Ruta a un campo en un documento. Para especificar una ruta de campo, utiliza una string que anteponga el nombre del campo con un signo de dólar (
$). - cortafuegos
- Un filtro de red a nivel de sistema que restringe el acceso en función de las direcciones IP y otros parámetros. Los cortafuegos son parte de una red segura. Consultar Cortafuegos.
- clúster gratuito y flexible
Categoría de clúster que contiene clústeres de nivel
Free(nivel gratuito) de clústeres. Los clústeres Free y Flex se utilizan generalmente para cargas de trabajo de desarrollo y pequeñas producciones.- nivel gratuito
Nivel de clúster gratuito que ofrece un entorno de desarrollo a pequeña escala para host tus datos. Los clústeres gratuitos nunca caducan y proporcionan acceso a un subconjunto de las características y funcionalidades de Atlas. Los clústeres gratuitos también pueden denominarse por su tamaño de instancia,
M0.- fsync
Una llamada al sistema que vacía todas las páginas sucias en memoria a almacenamiento. A medida que las aplicaciones guardan datos, MongoDB registra los datos en la capa de almacenamiento.
Para proporcionar datos durables, WiredTiger emplea puntos de control. Para obtener más detalles, consultar Registro en la bitácora y el motor de almacenamiento WiredTiger.
- geohash
- Un valor de geohash es una representación binaria de la ubicación en una cuadrícula de coordenadas. Consultar Valores de Geohash.
- GeoJSON
- Un formato de intercambio de datos geoespacial basado en la notación de objetos de JavaScript (JSON). GeoJSON se utiliza en los query geoespaciales. Para los objetos GeoJSON compatibles, consulta Datos geoespaciales. Para la especificación del formato GeoJSON, ve https://tools.ietf.org/html/rfc7946#section-3.1.
- Geoespacial
- Relacionado con la ubicación geográfica. Consultar Los query geoespaciales.
- clúster global
Clústeres con zonas geográficas definidas para admitir operaciones de lectura y escritura conscientes de la ubicación para instancias de aplicaciones y clientes distribuidos globalmente. Puede habilitarse la fragmentación global en clústeres de nivel
M30y superiores.- zona de escritura global
Zona geográfica que representa un subconjunto de la distribución del clúster global. Cada clúster global admite hasta 9 zonas de escritura globales distintas. Cada zona consta de una región de mayor prioridad y una o más regiones elegibles, de solo lectura o de análisis.
Las regiones geográficas disponibles dependen del proveedor de servicios de nube seleccionado.
- GridFS
- Una convención para almacenar archivos grandes en una base de datos MongoDB. Todos los controladores oficiales de MongoDB brindan soporte a la convención GridFS, al igual que el programa
mongofiles. Consulta GridFS. - group
- Consulta proyecto.
- ID del grupo
- Consulta ID del proyecto.
- clave de partición con hash
- Un tipo de clave de partición que utiliza una encriptación del valor en el campo de clave de partición para distribuir documentos entre los nodos del clúster particionado. Consultar Índices encriptados.
- gestor de verificaciones de estado
- Un gestor de verificaciones de estado ejecuta verificaciones de estado en una faceta de gestión de verificaciónes de estado a un nivel de intensidad especificado. Las comprobaciones del gestor de verificaciones de estado se ejecutan a intervalos de tiempo especificados. Se puede configurar un gestor de verificaciones de estado para mover automáticamente un mongos con fallas fuera de un clúster.
- faceta de gestión de verificaciones de estado
- Un conjunto de características que se pueden configurar en un gestor de verificaciones de estado para ejecutar verificaciones de estado. Por ejemplo, puede configurar un gestor de verificaciones de estado para supervisar y gestionar automáticamente los problemas de estado del clúster DNS o LDAP. Consultar facetas de gestión de verificaciónes de estado para obtener más detalles.
- miembro oculto
- Un nodo del set de réplicas que no puede convertirse en primario y es invisible para las aplicaciones cliente. Consultar nodos ocultos del set de réplicas.
- grafos jerárquicos navegables de mundos pequeños
- Algoritmo para realizar una búsqueda eficiente de vecinos más cercanos en un espacio multidimensional. MongoDB Vector Search realiza búsquedas ANN con Mundos Pequeños Navegables Jerárquicos.
- Alta disponibilidad
La alta disponibilidad indica un sistema diseñado para durabilidad, redundancia y conmutación por error automática. Las aplicaciones que son compatibles con el sistema pueden operar sin interrupciones durante un período prolongado. Los sets de réplicas de MongoDB admiten alta disponibilidad cuando se implementan de acuerdo con las mejores prácticas.
Para obtener orientación sobre la arquitectura de implementación de sets de réplicas, consulta Arquitecturas de implementación de sets de réplicas.
- región de mayor prioridad
Región en un clúster multiregional que MongoDB Atlas prioriza para la elegibilidad de primario durante las elecciones.
- Búsqueda híbrida
- Método para combinar diferentes métodos de búsqueda, como la búsqueda de texto completo y la búsqueda semántica, para aprovechar sus respectivas fortalezas. Los resultados se combinan utilizando una técnica como la Fusión de Rangos Recíprocos (RRF).
- idempotent
- Una operación produce el mismo resultado con la misma entrada cuando se ejecuta varias veces.
- impacto
Mejora estimada del rendimiento de un índice que sugiere Performance Advisor.
- ordenación en memoria
Un ordenamiento que debe realizarse en memoria antes de que se devuelvan los resultados. Los ordenamientos en memoria pueden afectar el rendimiento para conjuntos de datos grandes. Utiliza una ordenación indexada para evitar una ordenación en memoria.
Consulta Uso de ordenación e índices para obtener más información sobre las operaciones de ordenación indexada.
- Encriptación en uso
- Cifrado que protege los datos cuando se transmiten, almacenan y procesan, y habilita los query compatibles sobre esos datos cifrados. MongoDB proporciona dos enfoques para la encriptación en uso: Queryable Encryption y Cifrado a nivel de campo del lado del cliente.
- index
- Una estructura de datos que optimiza los query. Consulte Índices.
- Límites del índice
- El rango de valores de índice que MongoDB busca al usar un índice para ejecutar un query. Para obtener más información, consultar Límites del índice multiclave.
- firma de índice
- La combinación de parámetros que identifican de manera única el índice.
- ordenación indexada
- Una ordenación en la que un índice ofrece el resultado ordenado. Las operaciones de ordenación que utilizan un índice a menudo tienen un mejor rendimiento que una ordenación en memoria. Consulta Usar índice para ordenar resultados de query para obtener más información.
- init script
- Un script de shell utilizado por el sistema de inicialización de una plataforma Linux para iniciar, reiniciar o detener un proceso demonio. Si se instaló MongoDB usando un administrador de paquetes, se otorga un script de inicio para el sistema como parte de la instalación. Consultar la Guía de instalación para cada sistema operativo.
- sistema de inicialización
- El sistema de inicialización es el primer proceso que se inicia en una plataforma Linux después de que se inicia el kernel y gestiona todos los demás procesos en el sistema. El sistema de inicialización utiliza un script de inicio para iniciar, reiniciar o detener un proceso demonio, como
mongodomongos. Las versiones recientes de Linux suelen utilizar el sistema de inicialización systemd y el comandosystemctl. Las versiones antiguas de Linux suelen utilizar el sistema de inicialización System V y el comandoservice. Se debe consultar la guía de instalación del sistema operativo. - Sincronización inicial
- La operación del set de réplicas que replica datos de un nodo existente del set de réplicas a uno nuevo. Consulta Sincronización inicial.
- bloqueo de intención
- Un bloqueo en un recurso que indica que el propietario del bloqueo leerá (intención compartida) o escribirá (intención exclusiva) en el recurso usando control de concurrencia a una granularidad más fina que la del recurso con el bloqueo de intención. Los bloqueos de intención permiten lectores y escritores concurrentes en un recurso. Consultar ¿Qué tipo de bloqueo utiliza MongoDB?.
- endpoint de la interfaz
AWS Punto de enlace VPC con una dirección IP privada que envía tráfico al servicio de nodo privado de MongoDB Atlas a través de AWS PrivateLink.
- punto de interrupción
- Un punto en una operación cuando puede finalizar de manera segura. MongoDB solo finaliza una operación en los puntos de interrupción designados. Ve Terminar operaciones en ejecución.
- lista de acceso IP
Lista de direcciones IP y bloques CIDR con acceso a clústeres dentro de un proyecto de MongoDB Atlas. Para las conexiones de clientes a través de Internet pública, MongoDB Atlas permite conexiones a un clúster solo desde las entradas en la lista de acceso IP del proyecto correspondiente. La lista de acceso puede tener hasta 200 entradas.
MongoDB Atlas también permite conexiones de clientes a través de redes no públicas, como conexiones peering de red o nodos privados. Estos tipos de conexiones funcionan independientemente de la lista de acceso IP. Para obtener más información, consulta Configurar una conexión peering de red y Aprenda sobre nodos privados en Atlas.
- IPv6
- Una revisión del estándar de IP (Protocolo de Internet) con un amplio espacio de direcciones para dar soporte a los hosts de Internet.
- ISODate
- El formato de fecha internacional utilizado por
mongoshpara mostrar fechas. El formato esYYYY-MM-DD HH:MM.SS.millis. - JavaScript
- Un lenguaje de creación de scripts. mongosh, el shell
mongoheredado, y ciertas funciones del servidor utilizan un intérprete de JavaScript. Consulta JavaScript del lado del servidor para obtener más información. - journal
- Un registro de transacciones secuencial y binario utilizado para llevar la base de datos a un estado válido en caso de un apagado forzoso. Al registrar en la bitácora, se guardan los datos primero en la bitácora y luego en los archivos de datos principales. Los archivos de registro en la bitácora están preasignados y existen como archivos en el directorio de datos. Consulta registrar en la bitácora.
- JSON
- Notación de objetos JavaScript. Un formato de texto plano para expresar datos estructurados con soporte en muchos lenguajes de programación. Para obtener más información, consulta http://www.json.org. Ciertas herramientas de MongoDB renderizan una aproximación de los documentos de BSON de MongoDB en formato JSON. Consulta MongoDB Extended JSON (v2).
- Documento JSON
- Un documento JSON es una colección de campos y valores en un formato estructurado. Para documentos JSON de muestra, consulta http://json.org/example.html.
- Puntero JSON
- Una string con un prefijo de un carácter
/que especifica un valor de campo particular en un documento JSON. - JSONP
- JSON con relleno. Se refiere a un método de inyectar JSON en aplicaciones. Presenta posibles problemas de seguridad.
- fragmento jumbo
- Un fragmento que crece más allá del tamaño de fragmento especificado y no puede dividirse en fragmentos más pequeños. Para obtener más detalles, consulta Fragmentos Jumbo/ indivisibles.
- Búsqueda de vecinos más cercanos K
- Dado un conjunto de puntos P con una función de similitud definida S, para un punto de consulta q, encuentra el conjunto de k puntos en P con los mejores valores de S*(p, q). La búsqueda de vectores de MongoDB ENN devuelve exactamente los k puntos principales y ANN devuelve k puntos que son similares a q, pero no necesariamente los k más similares a q.
- material clave
- La string aleatoria de bits utilizada por un algoritmo de cifrado para cifrar y descifrar datos.
- colección de bóvedas de llaves
- Una colección de MongoDB que almacena las llaves de cifrado de datos cifradas como documentos BSON.
- planificador kyber
- Un programador de E/S diseñado para mejorar el rendimiento en entornos con alta contención de recursos. Mejora la interpolación de E/S y reduce el impacto de latencia de vecinos ruidosos.
- LDAP
- Protocolo multiplataforma utilizado para autenticar a los usuarios y autorizarlos a acceder a datos en un clúster. Se puede usar MongoDB Atlas para gestionar la autenticación y autorización de usuarios desde todos los clientes de MongoDB usando el propio servidor LDAP sobre TLS. Una única configuración LDAPS se aplica a todos los clústeres en un proyecto de MongoDB Atlas.
- mínimo privilegio
- Una política de autorización que concede a un usuario únicamente el acceso que es esencial para su trabajo.
- legacy coordinate pairs
- El formato utilizado para los datos geoespaciales antes de MongoDB versión 2.4. Este formato almacena datos geoespaciales como puntos en un sistema de coordenadas planas (por ejemplo,
[ x, y ]). Consulta Query geoespacial. - LineString
- Un LineString es un arreglo de dos o más posiciones. Una LineString cerrada con cuatro o más posiciones se llama LinearRing, como se describe en la especificación de GeoJSON LineString: https://tools.ietf.org/html/rfc7946#section-3.1.4. Para usar una LineString en MongoDB, consulta Objetos GeoJSON.
- link-token
- String que contiene la información necesaria para conectarse desde Cloud Manager u Ops Manager a MongoDB Atlas durante una migración en vivo desde una implementación de Cloud Manager u Ops Manager a un clúster en MongoDB Atlas.
- little-endian
Un orden de bytes en el que el byte menos significativo (little end) de un valor de datos multibyte se almacena en la dirección de memoria más baja.
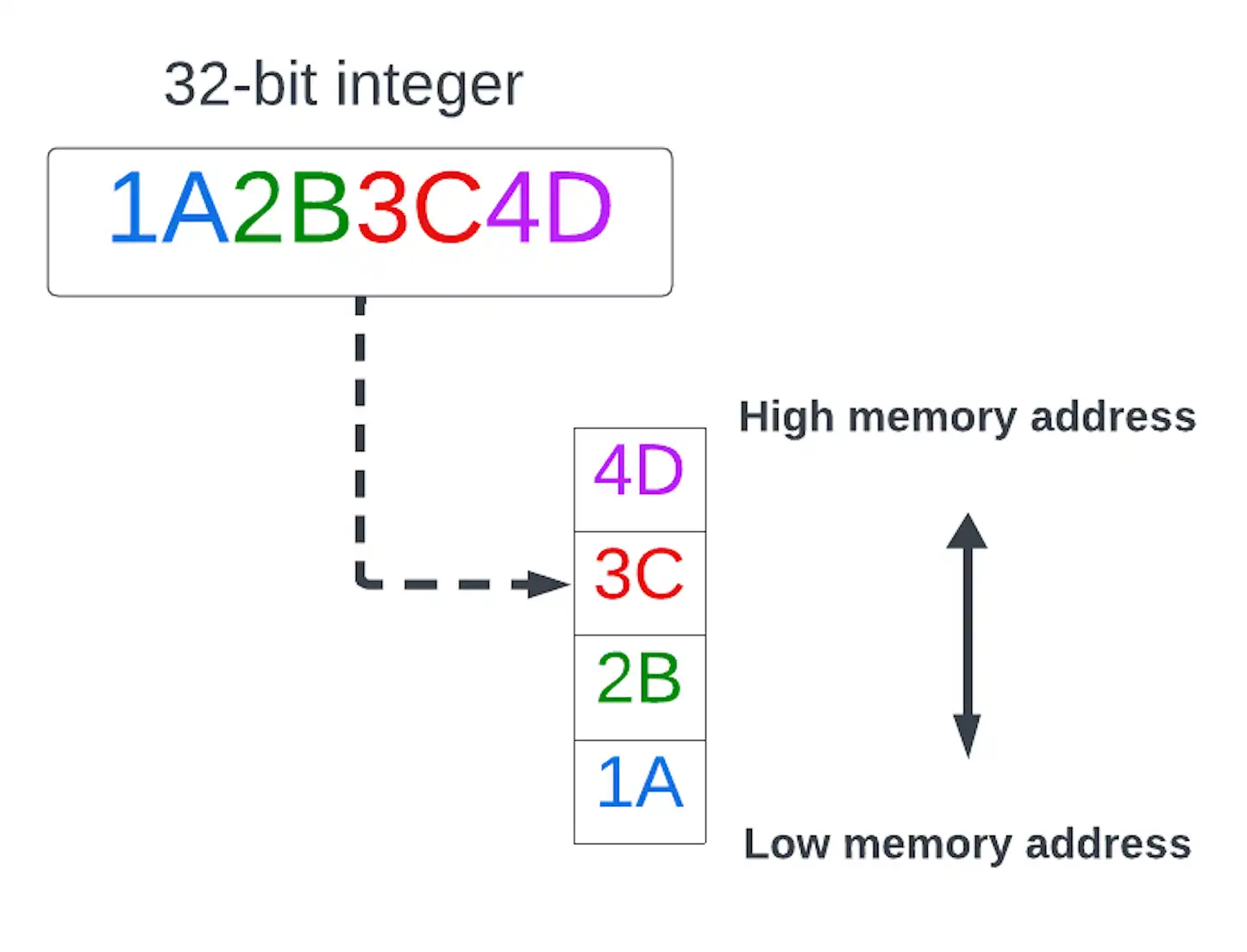 haga clic para ampliar
haga clic para ampliar- migración en vivo
Proceso para mover sin problemas un set de réplicas de origen existente o un clúster a MongoDB Atlas. Durante el proceso de migración en vivo, MongoDB Atlas mantiene el clúster de destino sincronizado con el origen remoto hasta que migras tus aplicaciones al clúster de MongoDB Atlas.
- bloqueo
- MongoDB utiliza bloqueos para garantizar que la concurrencia no afecte a la corrección. MongoDB utiliza bloqueos de lectura, bloqueos de escritura y bloqueos de intención. Para obtener más información, consultar ¿Qué tipo de bloqueo utiliza MongoDB?
- entradas de registro
- Contienen eventos del servidor, como conexiones entrantes, comandos ejecutados y problemas encontrados. Para más detalles, consulta Mensajes de registro.
- LVM
- Administrador de volúmenes lógicos. LVM es un programa que abstrae las imágenes de disco de los dispositivos físicos y ofrece varias capacidades de manipulación de discos en bruto y de snapshots útiles para la gestión del sistema. Para obtener información sobre LVM y MongoDB, consulta Copia de seguridad y restauración usando LVM en Linux.
- periodo de mantenimiento
Día y hora de la semana en que MongoDB Atlas debe iniciar el mantenimiento semanal en el clúster. Se puede establecer un periodo de mantenimiento en la Configuración del proyecto.
Importante
Consideraciones sobre el periodo de mantenimiento
Actividades de mantenimiento urgentes Las actividades de mantenimiento urgentes, como los parches de seguridad, no pueden esperar a la ventana que elijas. MongoDB Atlas iniciará esas actividades de mantenimiento cuando sea necesario.
Operaciones de mantenimiento en curso Una vez programado el mantenimiento para su clúster, no puede cambiar su periodo de mantenimiento hasta que finalicen las tareas de mantenimiento actuales.
El mantenimiento requiere elecciones del set de réplicas. MongoDB Atlas realiza el mantenimiento de la misma manera que el procedimiento de mantenimiento descrito en el Manual de MongoDB. Este procedimiento requiere al menos una elección de set de réplicas durante el periodo de mantenimiento por set de réplicas.
El mantenimiento comienza lo más cerca posible de la hora. El mantenimiento siempre comienza lo más cerca posible de la hora programada, pero las actualizaciones en curso del clúster o problemas inesperados del sistema podrían retrasar la hora de inicio.
- Map-Reduce
- Un proceso de agregación que tiene una fase de "map" que selecciona los datos y una fase de "reduce" que transforma los datos. En MongoDB, se pueden ejecutar agregaciones arbitrarias sobre los datos mediante map-reduce. Para la implementación de map-reduce, consultar Map-Reduce. Para todos los enfoques de agregación, consultar operaciones de agregación.
- tipo de mapeo
- Una estructura en lenguajes de programación que asocia claves con valores. Las claves pueden contener pares incrustados de claves y valores (por ejemplo, diccionarios, hashes, mapas y arreglos asociativos). Las propiedades de estas estructuras dependen de la especificación del lenguaje y de su implementación. Normalmente, el orden de las claves en los tipos de mapeo es arbitrario y no está garantizado.
- md5
- Un algoritmo de hash que calcula una suma de verificación para los datos suministrados. El algoritmo devuelve un valor único para identificar los datos. MongoDB utiliza md5 para identificar fragmentos de datos para GridFS. Consulta filemd5 (comando de base de datos).
- media
- Promedio de un conjunto de números.
- mediana
- En un conjunto de datos, la mediana es el valor percentil donde el 50 % de los datos se sitúan en ese valor o por debajo de él.
- nodo
- Un proceso mongod individual. Un set de réplicas tiene varios nodos. Un miembro también es conocido como nodo.
- metadata collection
- En Queryable Encryption, las colecciones internas que MongoDB utiliza para permitir los query de campos cifrados. Consulte Colecciones de metadatos.
- MIME
- Extensiones de correo de Internet multipropósito. Un conjunto estándar de definiciones de tipo y codificación utilizado para declarar la codificación y el tipo de datos en múltiples contextos de almacenamiento, transmisión y correo electrónico. La herramienta
mongofilesofrece una opción para especificar un tipo MIME para describir un archivo insertado en el almacenamiento de GridFS. - moda
- Número que ocurre con mayor frecuencia en un conjunto de números.
- mongo
El shell heredado de MongoDB. El proceso
mongoinicia el shell heredado como un demonio conectado a una instancia demongodomongos. El shell tiene una interfaz de JavaScript.A partir de MongoDB v5.0,
mongoestá obsoleto y mongosh reemplaza amongocomo el shell del cliente. Consulta mongosh.- mongod
- El servidor de base de datos MongoDB. El proceso
mongodinicia el servidor MongoDB como un demonio. El servidor MongoDB gestiona las solicitudes de datos y las operaciones en segundo plano. Consultarmongod. - MongoDB Charts
Herramienta de visualización para los datos de MongoDB Atlas. Se puede iniciar MongoDB Charts desde el clúster de MongoDB Atlas y ver los datos con la aplicación Charts para comenzar a visualizar los datos.
- MongoDB búsqueda
Indexación de texto de grano fino que permite la búsqueda avanzada de texto en sus datos sin necesidad de gestión adicional. La búsqueda de MongoDB ofrece opciones para varios tipos de analizadores de texto, clasificación de resultados basada en puntuaciones y un rico languaje del query.
- Búsqueda vectorial de MongoDB
- Característica que le permite realizar búsqueda semántica en incrustaciones vectoriales comparando vectores de query con vectores indexados para encontrar la coincidencia más cercana.
- mongos
- El enrutador de los query del clúster fragmentado de MongoDB. El proceso
mongosinicia el enrutador de MongoDB como un demonio. El enrutador de MongoDB actúa como una interfaz entre una aplicación y un clúster compartido de MongoDB y gestiona todo el enrutamiento y el equilibrio de carga en todo el clúster. Consulta las instanciasmongos. - mongosh
MongoDB Shell. mongosh ofrece una interfaz de shell para una instancia
mongodo o unamongos.A partir de MongoDB v5.0, mongosh reemplaza a
mongocomo el shell preferido.- clúster multiregional
MongoDB Atlas clúster que abarca varias regiones geográficas. Los clústeres multirregionales pueden aumentar la disponibilidad y mejorar el rendimiento al enrutar las queries de aplicaciones a las regiones geográficas más apropiadas.
Los clústeres multiregionales deben contener nodos elegibles.
Los clústeres multiregionales pueden contener nodos de solo lectura y nodos de análisis.
- namespace
- Un namespace es una combinación del nombre de la base de datos y el nombre de la colección o índice:
<database-name>.<collection-or-index-name>. Todos los documentos pertenecen a un namespace. Consulta Restricciones de nombres. - Namespace Insights
Una herramienta MongoDB Atlas que supervisa la latencia de query a nivel de colección. Puedes ver métricas y estadísticas de latencia de query para ciertos hosts y tipos de operaciones. Gestiona los namespaces fijados y elige hasta cinco namespaces para mostrar en las gráficas de latencia de query correspondientes.
- orden natural
El orden
recordIdsse crea y almacena en el índice WiredTiger. El orden de clasificación por defecto para un escaneo de colección ejecutado en una sola instancia es el orden natural.En los sets de réplicas, no se garantiza que el orden natural sea coherente y puede diferir entre los nodos.
En colecciones fragmentadas, el orden natural no está definido. Sin embargo, el uso del
$naturalobliga a cada partición a realizar un escaneo de la colección.Para obtener más información, consulta Devolución en orden natural.
- partición de red
Una falla de red que separa un sistema distribuido en particiones de tal manera que los nodos de una partición no pueden comunicarse con los nodos de la otra partición.
A veces, las particiones son parciales o asimétricas. Un ejemplo de partición parcial es la división de los nodos de una red en tres conjuntos, donde los miembros del primer conjunto no pueden comunicarse con los miembros del segundo conjunto, y viceversa, pero todos los nodos pueden comunicarse con los miembros del tercer conjunto.
En una partición asimétrica, la comunicación puede ser posible solo cuando se origina en ciertos nodos. Por ejemplo, los nodos de un lado de la partición pueden comunicarse con el otro lado solo si ellos inician el canal de comunicación.
- conexión peering de red
Proceso mediante el cual dos redes de Internet se conectan e intercambian tráfico. Se puede emparejar directamente la VPC con la VPC de MongoDB Atlas creada para los clústeres de MongoDB. Usando el emparejamiento de red, los servidores de aplicaciones pueden conectarse directamente a MongoDB Atlas mientras permanecen aislados de las redes públicas.
- node
- Un proceso mongod individual. Un set de réplicas tiene múltiples nodos. Un nodo también es conocido como miembro.
- ningún planificador
- La opción del programador
noneen el mecanismo de colas de la capa de bloque multicola (blk-mq) cumple la misma función que el programador "Sin operación" (noop). No realiza ninguna programación de solicitudes y envía las operaciones de E/S tal como se reciben al controlador del dispositivo de bloque. - noop
- El programador No operación (
noop) asigna ancho de banda de E/S para procesos entrantes según una cola FIFO (primero en entrar, primero en salir). A partir del kernel de Linux 5.3, este planificador se sustituye por el planificadornonefuncionalmente equivalente. - string normalizada
- La Forma normalizada unicode de un string aplica los puntos de código Unicode de manera estandarizada. Dos cadenas pueden parecerles idénticas a un usuario, pero pueden tener diferencias como el orden de los signos de combinación. Normalizar las cadenas garantiza que tengan la misma representación binaria.
- NVMe
- NVMe (Non-Volatile Memory Express) es un protocolo para acceder a medios de almacenamiento de alta velocidad.
- Almacenamiento NVMe
Disponible para clústeres M40+ alojados en AWS
Para las aplicaciones alojadas en AWS que requieren E/S de baja latencia y alto rendimiento, puedes utilizar la clase de clúster NVMe. La clase de clúster NVMe utiliza un protocolo de datos único para mejorar significativamente las velocidades de acceso a los datos.
Los clústeres NVMe utilizan un nodo secundario oculto que consta de un volumen aprovisionado con alto rendimiento e IOPS para facilitar la copia de seguridad.
- object identifier
- Consultar ObjectId.
- ObjectId
- Un tipo de BSON de 12 bytes que es único dentro de una colección. El ObjectId se genera utilizando la marca de tiempo, el ID de la computadora, el ID del proceso y un contador incremental de procesos locales. MongoDB utiliza valores ObjectId como valores por defecto para los campos _id.
- operation log
- Consultar oplog.
- metadatos de operación
- Información sobre la ejecución de procesos en lugar de su contenido, como la cantidad y el tiempo de las operaciones de inserción, actualización y borrado.
- filtro de rechazo de operación
- Una forma de la query rechazada. Para obtener más detalles, consulta Bloquear las query lentas con filtros de rechazo de operaciones.
- tiempo de operación
- Consultar optime.
- nodo operativo
- Cualquier nodo elegible o un nodo de solo lectura en el clúster de MongoDB Atlas.
- operador
- Una palabra clave que comienza con
$se utiliza para expresar componentes de MQL, como predicados de query, expresiones y etapas de agregación. Por ejemplo,$gtes el operador "mayor que" de MQL. Para conocer los operadores disponibles, consultar Referencia del languaje del query de MongoDB. - oplog
- Una colección con tamaño fijo que almacena un historial ordenado de escrituras lógicas en una base de datos MongoDB. El oplog es el mecanismo básico que habilita la replicación en MongoDB. Consultar Oplog del set de réplicas.
- colección de búfer de oplog
Una colección temporal creada durante las operaciones de resharding que almacena las entradas de oplog de una partición donante.
Las colecciones de búfer de oplog aseguran que las particiones receptoras puedan acceder a las entradas de oplog cuando se borran de la partición donante. Las colecciones de búfer de oplog se eliminan cuando se completa el reordenamiento.
- oplog hole
- Una brecha temporal en el oplog porque las operaciones de guardar del oplog no están en secuencia. Los primarios del set de réplicas aplican entradas del oplog en paralelo como una operación por lotes. Como resultado, pueden generarse brechas temporales en el oplog debido a entradas que aún no se han escrito desde un agrupamiento.
- oplog window
- Las entradas de oplog están selladas con una marca de tiempo. La oplog window es la diferencia de tiempo entre las marcas de tiempo más recientes y más antiguas en el
oplog. Si un nodo secundario pierde la conexión con el nodo primario, solo puede usar la replicación para sincronizarse nuevamente si la conexión se restaura dentro de la oplog window. - optime
Una referencia a una posición en el Oplog de replicación. El valor de optime es un documento que contiene:
ts, la marca de tiempo de la operación.t, latermen la cual la operación fue generada originalmente en el primario.
- plan del query ordenado
- Un plan del query que devuelve resultados en el orden coherente con el
sort(). Consulta planes del query. - organización
Agrupación lógica de proyectos de MongoDB Atlas. Puedes aprovechar una organización para gestionar la facturación, los usuarios y la configuración de seguridad de los proyectos que contiene.
La facturación se realiza a nivel de la organización mientras se mantiene la visibilidad del uso en cada proyecto.
Puedes ver todos los proyectos dentro de una organización.
Puedes utilizar equipos para asignar en bloque a los usuarios de la organización a proyectos dentro de esta.
- identificador de la organización
- String hexadecimal única de 24 dígitos utilizada para identificar la organización de MongoDB Atlas. El endpoint Devolver todas las organizaciones devuelve el ID de todas las organizaciones a las que el usuario autenticado que realiza la llamada a la API puede acceder.
- cursor huérfano
- Un cursor que no está correctamente cerrado ni iterado en el código de la aplicación. Los cursores huérfanos pueden causar problemas de rendimiento en la implementación de MongoDB.
- documento huérfano
En un clúster particionado, los documentos huérfanos son aquellos documentos en una partición que también existen en fragmentos en otras particiones. Esto se debe a una migración fallida o a una limpieza incompleta de la migración debido a un cierre atípico.
Los documentos huérfanos se eliminan automáticamente después de que se completa una migración de fragmentos. Ya no es necesario ejecutar
cleanupOrphanedpara borrar documentos huérfanos.- miembro pasivo
- Un nodo de un set de réplicas que no puede convertirse en primario porque su
members[n].priorityes0. Consulta Nodos de prioridad 0 del set de réplicas. - per-CPU cache
- Un tipo de caché que almacena memoria localmente para un núcleo específico de la CPU. La nueva versión de TCMalloc, que se introduce en MongoDB 8.0, utiliza las cachés por CPU.
- caché por hilo
- Un tipo de caché que almacena memoria localmente para cada hilo de aplicación. Las cachés por hilo son utilizadas por la versión heredada de TCMalloc, que se usa en MongoDB 7.0 y versiones anteriores.
- percentil
- En un conjunto de datos, un percentil es un valor donde ese porcentaje de los datos está en o por debajo del valor especificado. Para obtener más detalles, consulte Consideraciones de cálculo.
- Performance Advisor
Herramienta de MongoDB Atlas que supervisa los query lentos ejecutados en su clúster y sugiere índices para mejorar el rendimiento de los query. Cada índice que sugiere el Performance Advisor incluye una puntuación de impacto que indica la mejora potencial del rendimiento que ese índice podría aportar.
- PID
- Un identificador de proceso. Los sistemas tipo UNIX asignan un PID entero único a cada proceso en ejecución. Puedes utilizar un PID para inspeccionar un proceso en ejecución y enviarle señales. Consulta
/procsistema de archivos. - pipe
- Un canal de comunicación en sistemas tipo UNIX que permite a procesos independientes enviar y recibir datos. En el shell de UNIX, las operaciones de pipe permiten a los usuarios dirigir la salida de un comando a la entrada de otro.
- pipeline
- Una serie de operaciones en una agregación. Consulta pipeline de agregación.
- forma de la query de caché del plan
Una combinación de predicado de la query, orden, proyección e intercalación. La forma de la query de la caché del plan permite a MongoDB identificar las query equivalentes y analizar el rendimiento.
Para el predicado de query, solo se utilizan la estructura del predicado y los nombres de campo. Los valores en el predicado de query no se utilizan. Por ejemplo, un predicado de query
{ type: 'food' }es equivalente a{ type: 'drink' }.Para identificar las queries lentas con la misma forma de la query de caché de planes, cada forma de la query de caché de planes tiene un valor hexadecimal
planCacheShapeHash. Para obtener más información, consulta planCacheShapeHash y planCacheKey.A partir de MongoDB 8.0, el campo
queryHashexistente se duplica en un nuevo campo llamadoplanCacheShapeHash. Si estás utilizando una versión anterior de MongoDB, solo verás el campoqueryHash. Las versiones futuras de MongoDB removerán el campoqueryHashobsoleto y deberás utilizar el campoplanCacheShapeHashen su lugar.- punto
- Un único par de coordenadas como se describe en la especificación de punto GeoJSON: https://tools.ietf.org/html/rfc7946#section-3.1.2. Para usar un punto en MongoDB, consulta GeoJSON Objetos.
- polígono
Un arreglo de arreglos de coordenadas LinearRing, como se describe en la especificación del polígono GeoJSON: https://tools.ietf.org/html/rfc7946#section-3.1.6. Para polígonos con múltiples anillos, el primero debe ser el anillo exterior y los demás deben ser anillos interiores o huecos.
MongoDB no permite que el anillo exterior se autointersecte. Los anillos interiores deben estar completamente contenidos dentro del bucle exterior y no deben cruzarse ni superponerse entre sí. Consulta Objetos GeoJSON.
- documento post-imagen
- Un documento después de ser insertado, reemplazado o actualizado. Consultar Change Streams con imágenes de documentos antes y después.
- powerOf2Sizes
- Una configuración para cada colección que asigna espacio a cada documento para maximizar la reutilización del almacenamiento y reducir la fragmentación.
powerOf2Sizeses el valor por defecto para Colecciones TTL. Para cambiar la configuración de la colección, consultacollMod. - documento pre-imagen
- Un documento antes de ser sustituido, actualizado o borrado. Consultar Change Streams con imágenes de documentos antes y después.
- pre-división
- Una operación realizada antes de insertar datos que divide el rango de posibles valores de la clave de partición en fragmentos para facilitar la inserción y un alto rendimiento de escritura. En algunos casos, la pre-división acelera la distribución inicial de documentos en un clúster particionado al dividir manualmente la colección en lugar de esperar a que el balanceador de MongoDB lo haga. Consulta Crear rangos en un clúster particionado.
- reducción de prefijo
- Reduce el consumo de memoria y disco al almacenar cualquier prefijo de clave de índice idéntico solo una vez por página de memoria. Ver: Compresión para más información sobre el comportamiento de compresión de WiredTiger.
- primario
- En un set de réplicas, el primario es el nodo que recibe todas las operaciones de escritura. Consultar Primario.
- llave primaria
- Un identificador único e inmutable de un registro. En un software RDBMS, la llave primaria normalmente es un número entero almacenado en el campo
idde cada fila. En MongoDB, el campo _id almacena la llave primaria de un documento, que normalmente es un ObjectId de BSON. - partición primaria
- Cada base de datos en un clúster particionado tiene una partición primaria. Es el fragmento por defecto para todas las colecciones no particionadas en la base de datos. Consulta Partición primaria.
- prioridad
- Un valor configurable que ayuda a determinar qué nodos de un set de réplicas tienen más probabilidades de convertirse en primario. Consultar
members[n].priority. - privilegio
- Una combinación de recurso especificado y acciones permitidas sobre el recurso. Consultar privilegio.
- Proyecto
Agrupación lógica de clústeres. Puedes tener múltiples clústeres dentro de un solo proyecto y múltiples proyectos dentro de una sola organización.
Nota
El proyecto es sinónimo de grupo.
- ID del proyecto
Unique 24-digit string hexadecimal utilizada para identificar su proyecto de MongoDB Atlas. El endpoint Get All Projects de la API devuelve el ID de todos los proyectos a los que el usuario autenticado que ejecuta la llamada a la API puede acceder.
Nota
El Identificador del proyecto es sinónimo del ID del grupo.
- proyección
- Un documento proporcionado a un query que especifica los campos que MongoDB devuelve en el conjunto de resultados. Para obtener más información sobre las proyecciones, consulta Campos de proyecto a devolver del query.
- cuantización
- Método de compresión del valor de las dimensiones individuales en un vector a un rango más pequeño para reducir el consumo de recursos y mejorar la velocidad. MongoDB Vector Search admite la indexación y consulta de vectores cuantizados.
- Consulta
- Una solicitud de lectura. MongoDB utiliza una forma de lenguaje del query en JSON que incluye operadores del query con nombres que comienzan con un carácter
$. Enmongosh, puedes ejecutar los query usando los métodosdb.collection.find()ydb.collection.findOne(). Consulta Documentos de query. - estructura del query
- Una combinación del optimizador del query y el motor de ejecución de query que procesa una operación.
- operador del query
- Una palabra clave que empieza por
$en un query. Por ejemplo,$gtes el operador "mayor que". Para obtener una lista de los operadores del query, consultar operadores del query. - optimizador del query
- Un proceso que genera planes del query. Para cada query, el optimizador genera un plan que hace coincidir la query con el índice que devuelve los resultados de la manera más eficiente posible. El optimizador reutiliza el plan del query cada vez que se ejecuta el query. Si una colección cambia significativamente, el optimizador crea un nuevo plan del query. Consultar planes del query.
- plan del query
- El plan de ejecución más eficiente elegido por el planificador de query. Para obtener más detalles, consultar Planes del query.
- predicado de query
Una expresión que devuelve un valor booleano que indica si un documento coincide con la query especificada. Por ejemplo,
{ name: { $eq: "Alice" } }, que devuelve documentos que tienen un campo"name"cuyo valor es la string"Alice".Los predicados de query pueden contener expresiones secundarias y operadores para coincidencias más complejas. Para ver los operadores del query disponibles, consultar Predicados de query.
- Perfilador de la query
- Herramienta MongoDB Atlas que diagnostica y supervisa problemas de rendimiento en el clúster. El perfilador del query puede exponer los query de larga duración y sus estadísticas de rendimiento. Se pueden filtrar los datos devueltos por el perfilador del query para centrarse en namespaces y tipos de operación específicos.
- forma del query
- Una forma de la query es un conjunto de especificaciones que agrupan query similares. Para obtener más detalles, consulta Formas de la query.
- rango
- Un rango contiguo de valores de clave de partición dentro de un fragmento. Los rangos de datos incluyen el límite inferior y excluyen el límite superior. MongoDB migra datos cuando una partición contiene demasiados datos de una colección en comparación con otras particiones. Consultar Particionamiento de datos con fragmentos y Balanceador de clústeres particionados.
- RDBMS
- Sistema de gestión de bases de datos relacionales. Un sistema de gestión de bases de datos basado en el modelo relacional, que normalmente utiliza SQL como lenguaje del query.
- readConcern
- Especifica un nivel de aislamiento para las operaciones de lectura. Por ejemplo, puedes utilizar el nivel de consistencia de lectura para leer únicamente los datos que se hayan propagado a la mayoría de los nodos en un set de réplicas. Consulta Nivel de consistencia de lectura.
- bloqueo de lectura
- Un bloqueo compartido en un recurso como una colección o base de datos que, mientras se mantiene, permite lectores concurrentes pero no escritores. Consulte ¿Qué tipo de bloqueo utiliza MongoDB?.
- preferencia de lectura
- Una configuración que determina cómo los clientes dirigen las operaciones de lectura. La preferencia de lectura afecta a todos los sets de réplicas, incluidos los sets de réplicas de la partición. Por defecto, MongoDB dirige las lecturas a primarios. Sin embargo, también puede dirigir las lecturas a los secundarios para obtener lecturas eventualmente coherentes. Consultar Preferencia de lectura.
- nodo de solo lectura
- Set de réplicas en una región geográfica dedicada que complementa tus regiones de nodos elegibles. Puedes utilizar nodos de solo lectura para localizar los datos donde se leen con más frecuencia y mejorar el rendimiento.
- Panel de rendimiento en tiempo real
Servicio de supervisión de MongoDB Atlas que muestra el tráfico de red actual, las operaciones de base de datos en sus clústeres y estadísticas de hardware sobre sus máquinas host. Utilice el RTPP para evaluar visualmente los tiempos de ejecución de los query, supervisar la actividad de la red y descubrir un posible Atraso de la replicación en los miembros secundarios de los Sets de réplicas.
- recuperar
- Mide la fracción de verdaderos vecinos más cercanos que fueron devueltos por una búsqueda ANN. Esta medida refleja la precisión con la que el algoritmo aproxima los resultados de la búsqueda ENN. La notación Recall@k se refiere a la medición de cuántos de los verdaderos vecinos más cercanos estaban presentes en los k primeros resultados devueltos por MongoDB Vector Search.
- recuperando
- El estado de un nodo del set de réplicas que indica que un nodo no está listo para comenzar las actividades de un secundario o un primario. Los nodos de recuperación no están disponibles para lecturas.
- utilización relativa de la CPU del sistema
La utilización de la CPU en relación con la cantidad de CPU base asignada a una instancia en la nube. Puedes calcular la utilización relativa de la CPU del sistema dividiendo la utilización absoluta de la CPU del sistema por la cantidad de CPU base asignada a una instancia en la nube.
MongoDB limita la utilización relativa de la CPU del sistema al 100 %. Cuando un proveedor de nube limita la utilización de la CPU para una instancia en la nube, o aumenta la utilización de la CPU para una instancia por encima de la cantidad base de CPU disponible para esa instancia, el valor relativo de la CPU del sistema es del 100 %.
Consulte también utilización absoluta de la CPU del sistema e instancias de ráfaga.
- set de réplicas
- Grupo de servidores de MongoDB que mantienen el mismo conjunto de datos. Los sets de réplicas proporcionan redundancia, alta disponibilidad y son la base para todas las implementaciones de producción.
- Replicación
- Una característica que permite a varios servidores de bases de datos compartir los mismos datos. La replicación asegura la redundancia de datos y facilita el balanceo de carga. Consulte Replicación.
- atraso de la replicación
- El período de tiempo entre la última operación en el oplog del primario y la última operación aplicada a un secundario en particular. Normalmente, deseas que el atraso de la replicación sea lo más breve posible. Consulta Atraso de la replicación.
- memoria residente
- El subconjunto de la memoria de una aplicación que actualmente se almacena en la RAM física. La memoria residente es un subconjunto de memoria virtual, que incluye memoria asignada a la RAM física y al almacenamiento.
- resource
- Una base de datos, colección, conjunto de colecciones o clúster. Un privilegio permite acciones en un recurso especificado. Consultar recurso.
- rol
- Un conjunto de privilegios que permite acciones sobre recursos específicos. Los roles asignados a un usuario determinan el acceso del usuario a los recursos y operaciones. Consultar Seguridad.
- rollback
- Un proceso que revierte las operaciones de guardado para garantizar la coherencia de todos los miembros del set de réplicas. Ver Rollbacks durante la conmutación por error de un set de réplicas.
- reinicio en secuencia
- Proceso que reinicia todos los nodos del clúster en secuencia. Para mantener la disponibilidad del clúster, MongoDB Atlas reinicia un nodo a la vez, comenzando con un nodo secundario. MongoDB Atlas siempre mantiene un nodo primario hasta que se complete el reinicio en secuencia.
- Cuantificación escalar
- La cuantificación escalar consiste en seleccionar los valores mínimo y máximo en todos los vectores indexados dentro de un segmento para cada dimensión, y producir intervalos de igual tamaño entre ellos. Las asignaciones de cada una de estas dimensiones a las categorías producen los nuevos valores cuantificados. MongoDB Vector Search admite la cuantificación escalar automática para tus vectores flotantes32 y la ingestión e indexación de tus vectores cuantificados escalares de proveedores de embeddings.
- secundario
- Un nodo del set de réplicas que replica el contenido de la base de datos principal. Los miembros secundarios pueden ejecutar solicitudes de lectura, pero solo los nodos primarios pueden ejecutar operaciones de guardado. Consulta Secundarios.
- índice secundario
- Un índice de base de datos que mejora el rendimiento de los query al minimizar la cantidad de trabajo que el motor de los query debe realizar para ejecutar un query. Consultar Índices.
- miembro secundario
- Consultar secundario. También se conoce como nodo secundario.
- lista de nodos iniciales
- Los controladores y clientes utilizan una lista de nodos iniciales (como
mongosh) para el descubrimiento inicial de la configuración del set de réplicas. Las listas de nodos iniciales pueden proporcionarse como una lista de pareshost:port(consulta Formato de cadena de conexión estándar o a través de entradas DNS.) Para obtener más información, consulta Formato de conexión SRV. - autogestionamiento
- Cuando una persona u organización es la encargada de configurar y mantener una instancia de MongoDB, y no una gestión externa o servicios de terceros (como MongoDB Atlas).
- Semantic Search
- Busca valores que tengan un significado similar a la query. La búsqueda semántica captura la relación natural entre palabras o frases incluso cuando no hay solapamiento léxico. La búsqueda semántica y la búsqueda vectorial a menudo se utilizan indistintamente. MongoDB Vector Search admite la búsqueda semántica en datos vectoriales almacenados en clústeres de MongoDB Atlas.
- nombre del conjunto
- El nombre arbitrario dado a un set de réplicas. Todos los nodos de un set de réplicas deben tener el mismo nombre especificado con la configuración
replSetNameo la opción--replSet. - partición
- Una única instancia
mongodo set de réplicas que almacena parte del conjunto de datos total de un clúster particionado. Normalmente, en una implementación de producción, es necesario asegurarse de que todos las particiones formen parte de sets de réplicas. Consultar particiones. - clave de partición
- El campo que MongoDB utiliza para distribuir documentos entre los nodos de un clúster particionado. Consultar Claves de partición.
- clúster fragmentado
- El conjunto de nodos que componen una implementación particionada de MongoDB. Un clúster particionado consta de servidores de configuración, particiones y uno o más procesos de enrutamiento de
mongos. Consulta Componentes del clúster particionado. - fragmentación
- Una arquitectura de base de datos que particiona los datos por rangos de claves y distribuye los datos entre dos o más instancias de base de datos. El particionado permite el escalado horizontal. Consulta Particionado.
- asistente de shell
- Un método en
mongoshque tiene una sintaxis concisa para un comando de base de datos. Los asistentes de shell mejoran la experiencia interactiva. Consultemongoshmétodos. - función de similitud
- Mide la similitud entre dos vectores. MongoDB Vector Search admite
euclidean,cosine, ydotProductfunciones de similitud. - replicación monomaster
- Una topología de replicación en la que solo una instancia de base de datos acepta escrituras. La replicación monomaster garantiza la coherencia y es la topología de replicación que utiliza MongoDB. Consultar Set de réplicas primario.
- rápido
- Una biblioteca de compresión/descompresión para equilibrar los requisitos de cálculo eficientes con tasas de compresión razonables. Snappy es la biblioteca de compresión por defecto para el uso de MongoDB con WiredTiger. Consulta Snappy y la documentación de compresión de WiredTiger para obtener más información.
- snapshot
- Una snapshot es una copia de los datos en una instancia de
mongoden un momento específico. Puedes recuperar los metadatos de la snapshot para todo el clúster o set de réplicas, o para un solo servidor de configuración en un clúster. - softIRQ
- La métrica de utilización de la CPU que refleja la parte de la CPU que una instancia de nube está utilizando actualmente para procesar solicitudes de interrupciones de software. En algunos proveedores de nube, esta métrica es útil para realizar un seguimiento de la utilización de la CPU en instancias de ráfaga.
- clave de clasificación
- El valor con el que se compara al ordenar los campos. Para aprender cómo MongoDB determina la clave de ordenación para los campos no numéricos, consulta Orden de comparación/ordenación.
- división
- La división entre fragmentos en un clúster particionado. Consultar Particionamiento de datos con fragmentos.
- SQL
- El languaje del query estructurado (SQL) se utiliza para la interacción con bases de datos relacionales.
- SSD
- Disco de estado sólido. Almacenamiento de alto rendimiento que utiliza electrónica de estado sólido para la persistencia en lugar de platos giratorios y cabezales móviles de lectura/guardado utilizados por discos duros mecánicos.
- lectura desactualizada
- Una lectura obsoleta se refiere a cuando una transacción lee datos antiguos (obsoletos) que han sido modificados por otra transacción pero que aún no se han confirmado en la base de datos.
- autónomo
Una instancia de
mongodque se ejecuta como un servidor único y no como parte de un set de réplicas. Para convertir una instancia autónoma en un set de réplicas, consulta Convertir un mongod autogestionado autónomo en un set de réplicas.Nota
Una instancia autónoma no es un set de réplicas con solo un nodo.
- colección de reserva
Una colección temporal creada en la partición receptora para cada partición donante durante las operaciones de resharding.
Las colecciones de reserva retienen documentos que no pueden insertarse de inmediato debido a conflictos de operación. Por ejemplo, si la clave de fragmentación de un documento se ha actualizado, ahora pertenece a una partición diferente, y el orden de las operaciones aplicadas a este documento puede ser ambiguo. El destinatario almacena estos documentos en una colección de reserva hasta que pueda aplicar las operaciones en el orden correcto.
- retiro
El nodo primario del set de réplicas se desasigna como primario y se convierte en un nodo secundario.
Si un set de réplicas pierde contacto con el primario, los secundarios eligen un nuevo primario. Cuando el antiguo primario aprende de la elección, se retira y se reincorpora al set de réplicas como secundario.
Si el usuario ejecuta el comando
replSetStepDown, el primario se desactiva, obligando al set de réplicas a elegir un nuevo primario.
- motor de almacenamiento
- La parte de una base de datos que es responsable de gestionar cómo se almacenan y se accede a los datos, tanto en memoria como en disco. Los distintos motores de almacenamiento ofrecen un mejor rendimiento para cargas de trabajo específicas. Consulta Motores de almacenamiento para implementaciones autogestionadas para obtener detalles específicos sobre los motores de almacenamiento incorporados en MongoDB.
- orden de almacenamiento
- Consulte orden natural.
- coherencia estricta
- Una propiedad de un sistema distribuido que exige que todos los nodos incorporen los cambios más recientes al sistema. En un sistema de base de datos, esto significa que cualquier sistema que pueda proporcionar datos debe contener los últimos guardados.
- Nombre alternativo del sujeto
- El Nombre Alternativo del Sujeto (SAN) es una extensión del certificado X.509 que permite un arreglo de valores, como direcciones IP y nombres de dominio, que especifican los recursos que un único certificado de seguridad puede proteger.
- sincronizar
- La operación del set de réplicas donde los nodos replican datos del primario. La sincronización ocurre por primera vez cuando MongoDB crea o restaura un nodo, lo que se denomina sincronización inicial. La sincronización se produce entonces de forma continua para mantener al nodo actualizado con los cambios en los datos del set de réplicas. Consulta Sincronización de datos del set de réplicas.
- syslog
- En sistemas tipo UNIX, un proceso de registro que otorga un estándar uniforme para que los servidores y procesos envíen información de registro. MongoDB ofrece una opción para enviar la salida al sistema syslog del host. Consulta
syslogFacility. - tag
Una etiqueta aplicada a un miembro del set de réplicas y utilizada por los clientes para realizar operaciones con conocimiento del centro de datos. Para obtener más información sobre el uso de etiquetas con sets de réplicas, consultar Listas de conjuntos de etiquetas de preferencia de lectura.
Nota
Las zonas del clúster fragmentado reemplazan a las etiquetas.
- tag set
- Un documento que contiene cero o más etiquetas.
- cursor con seguimiento
- Para una colección con tamaño fijo, un cursor con seguimiento es un cursor que permanece abierto después de que el cliente agota los resultados en el cursor inicial. A medida que los clientes insertan nuevos documentos en la colección con tamaño fijo, el cursor con seguimiento sigue recuperando documentos.
- equipo
- Grupo de Atlas users en la misma organización. Puedes usar equipos para conceder acceso al mismo grupo de Atlas users en múltiples proyectos. Todos los usuarios del equipo comparten el mismo acceso al proyecto.
- término
- Para los miembros de un set de réplicas, un número que aumenta de manera monótona y que corresponde a un intento de elección.
- colección de series de tiempo
- Una colección que almacena eficientemente secuencias de mediciones a lo largo de un período de tiempo. Consultar Serie de tiempo.
- topología
El estado de una implementación de instancias de MongoDB. Incluye:
Tipo de implementación (autónomo, set de réplicas o clúster).
Disponibilidad de servidores.
Rol de cada servidor (primario, secundario, servidor de configuración o
mongos).
- transacción
- Grupo de operaciones de lectura o escritura. Para obtener más detalles, consultar Transacciones.
- coordinador de transacciones
- Un componente de MongoDB que gestiona transacciones en un set de réplicas o en un clúster particionado. Coordina la ejecución y finalización de transacciones multi-documento entre nodos y permite que una operación compleja se trate como una operación atómica.
- TSV
- Un formato de datos basado en texto que consiste en valores separados por pestañas. Este formato se utiliza comúnmente para intercambiar datos entre bases de datos relacionales porque es adecuado para datos tabulares. Puedes importar archivos TSV usando
mongoimport. - TTL
- El tiempo de vida (TTL) es un tiempo de expiración o período para que una pieza de información determinada permanezca en una caché u otro almacenamiento temporal antes de que el sistema la borre o la haga caducar. MongoDB tiene una característica de colección TTL. Consultar Expirar datos de colecciones configurando TTL.
- arreglo sin límites
- Un arreglo que aumenta constantemente con el tiempo. Si el valor de un campo de un documento es un arreglo sin límites, el arreglo puede tener un impacto negativo en el rendimiento. En general, se debe diseñar el esquema para evitar arreglos ilimitados.
- índice único
- Un índice que aplica la unicidad para un campo específico en una sola colección. Consultar Índices únicos.
- unix epoch
- 1 de enero de 1970 a las 00:00:00 UTC. Comúnmente se utiliza para expresar el tiempo, y se cuenta el número de segundos o milisegundos desde este punto.
- plan del query no ordenado
- Un plan del query que devuelve resultados en un orden inconsistente con el orden de
sort(). Consultar planes del query. - actualizar
- El proceso de actualizar un clúster de una versión de MongoDB a una versión más reciente.
- inserción
Una opción para las operaciones de actualización. Por ejemplo:
db.collection.updateOne(),db.collection.findAndModify(). Si la inserción estrue, la operación de actualización:actualiza los documentos que coinciden con el query.
o si ningún documento coincide, inserta un nuevo documento. El nuevo documento tiene los valores de campo especificados en la operación de actualización.
Para obtener más información sobre upserts, consultar Insertar un documento nuevo si no se encuentra ninguna coincidencia (
Upsert).- base de datos vectorial
- Sistema que almacena incrustaciones vectoriales y metadatos asociados, y permite la búsqueda de vecinos más cercanos en las incrustaciones vectoriales almacenadas. Puedes usar MongoDB Atlas como tu base de datos vectorial y MongoDB Vector Search para realizar búsqueda vectorial en los vectores almacenados. Puede utilizar una base de datos vectorial para implementar RAG.
- Índice vectorial
- Estructura de datos que procesa eficientemente las consultas de búsqueda del vecino más cercano. MongoDB Vector Search admite la creación de índices de tipo
vectorpara indexar campos para ejecutar$vectorSearchconsultas. - Búsqueda vectorial
- Método para realizar una búsqueda de los k vecinos más cercanos sobre un conjunto de vectores almacenados en un índice de vectores. MongoDB Vector Search admite búsqueda ANN y ENN de los k vecinos más cercanos.
- memoria virtual
- La memoria de trabajo de una aplicación, que normalmente reside tanto en el disco como en la RAM física.
- hora de reloj
- El tiempo que transcurre entre el inicio y la finalización de un programa de computadora o de un cálculo.
- WGS84
- El sistema de referencia por defecto y el datum geodésico que MongoDB utiliza para calcular la geometría sobre una esfera similar a la Tierra para los query geoespaciales en objetos GeoJSON. Consulta la especificación "EPSG:4326: WGS 84": http://spatialreference.org/ref/epsg/4326/.
- operador de ventana
- Devuelve valores de un rango de documentos de una colección. Consultar los operadores de ventana.
- conjunto de trabajo
- Los datos que MongoDB utiliza con mayor frecuencia.
- nivel de confirmación de escritura (write concern)
- Especifica si una operación de escritura ha tenido éxito. El nivel de confirmación de escritura permite que la aplicación detecte errores de inserción o instancias de
mongodno disponibles. Para el set de réplicas, se puede configurar el nivel de confirmación de escritura para confirmar la replicación a una cantidad especificada de nodos. Ver nivel de confirmación de escritura. - conflicto de escritura
- Una situación en la que dos operaciones concurrentes, siendo una, al menos, una escritura, intentan utilizar un recurso que viola las restricciones de un motor de almacenamiento que utiliza control de concurrencia optimista. MongoDB finaliza automáticamente y reintenta una de las operaciones de escritura en conflicto.
- bloqueo de escritura
- Un bloqueo exclusivo en un recurso como una colección o una base de datos. Cuando un proceso se guarda en un recurso, adquiere un bloqueo de escritura exclusivo para evitar que otros procesos escriban o lean ese recurso. Para obtener más información sobre los bloqueos, consultar Preguntas frecuentes: Concurrencia.
- zlib
- Una biblioteca de compresión de datos que ofrece mayores tasas de compresión a costo de un mayor uso de CPU, en comparación con el uso de snappy por parte de MongoDB. Puede configurar WiredTiger para usar zlib como su biblioteca de compresión. Consulte http://www.zlib.net y la documentación de compresión de WiredTiger para obtener más información.
- zona
- Una agrupación de documentos basada en rangos de valores de clave de partición para una colección particionada determinada. Cada partición en el clúster particionado puede estar en una o más zonas. En un clúster balanceado, MongoDB dirige las lecturas y escrituras para una zona solo a aquellas particiones dentro de esa zona. Consultar la página del manual Zonas para obtener más información.
- zstd
- Una librería de compresión de datos que ofrece tasas de compresión más altas y un menor uso de CPU en comparación con zlib.