To create performant apps, developers must write thread-safe and maintainable multithreaded code that avoids issues like deadlocking and race conditions. Realm provides tools specifically designed for performant multithreaded apps.
Three Rules to Follow
Before exploring Realm's tools for multithreaded apps, you need to understand and follow these three rules:
- Don't lock to read:
- Realm's Multiversion Concurrency Control (MVCC) architecture eliminates the need to lock for read operations. The values you read will never be corrupted or in a partially-modified state. You can freely read from the same Realm file on any thread without the need for locks or mutexes. Unnecessarily locking would be a performance bottleneck since each thread might need to wait its turn before reading.
- Avoid synchronous writes on the UI thread if you write on a background thread:
- You can write to a Realm file from any thread, but there can be only one writer at a time. Consequently, synchronous write transactions block each other. A synchronous write on the UI thread may result in your app appearing unresponsive while it waits for a write on a background thread to complete. Device Sync writes on a background thread, so you should avoid synchronous writes on the UI thread with synced realms.
- Don't pass live objects, collections, or realms to other threads:
- Live objects, collections, and realm instances are thread-confined: that is, they are only valid on the thread on which they were created. Practically speaking, this means you cannot pass live instances to other threads. However, Realm offers several mechanisms for sharing objects across threads.
Communication Across Threads
To access the same Realm file from different threads, you must instantiate a realm instance on every thread that needs access. As long as you specify the same configuration, all realm instances will map to the same file on disk.
One of the key rules when working with Realm in a multithreaded environment is that objects are thread-confined: you cannot access the instances of a realm, collection, or object that originated on other threads. Realm's Multiversion Concurrency Control (MVCC) architecture means that there could be many active versions of an object at any time. Thread-confinement ensures that all instances in that thread are of the same internal version.
When you need to communicate across threads, you have several options depending on your use case:
To modify an object on two threads, query for the object on both threads.
To react to changes made on any thread, use Realm's notifications.
To see changes that happened on another thread in the current thread's realm instance, refresh your realm instance.
To share an instance of a realm or specific object with another thread, share a thread_safe_reference to the realm instance or object.
To send a fast, read-only view of the object to other threads, "freeze" the object.
Pass Instances Across Threads
Instances of realm::realm, realm::results, and realm::object are
thread-confined. That means you may only use them on the thread where you
created them.
You can copy thread-confined instances to another thread as follows:
Initialize a thread_safe_reference with the thread-confined object.
Pass the reference to the target thread.
Resolve the reference on the target thread. If the referred object is a realm instance, resolve it by calling
.resolve(); otherwise, move the reference torealm.resolve(). The returned object is now thread-confined on the target thread, as if it had been created on the target thread instead of the original thread.
Important
You must resolve a thread_safe_reference exactly once. Otherwise,
the source realm will remain pinned until the reference gets
deallocated. For this reason, thread_safe_reference should be
short-lived.
// Put a managed object into a thread safe reference auto threadSafeItem = realm::thread_safe_reference<realm::Item>{managedItem}; // Move the thread safe reference to a background thread auto thread = std::thread([threadSafeItem = std::move(threadSafeItem), path]() mutable { // Open the database again on the background thread auto backgroundConfig = realm::db_config(); backgroundConfig.set_path(path); auto backgroundRealm = realm::db(std::move(backgroundConfig)); // Resolve the Item instance via the thread safe // reference auto item = backgroundRealm.resolve(std::move(threadSafeItem)); // ... use item ... }); // Wait for thread to complete thread.join();
Another way to work with an object on another thread is to query for it
again on that thread. But if the object does not have a primary
key, it is not trivial to query for it. You can use thread_safe_reference
on any object, regardless of whether it has a primary key.
Use the Same Realm Across Threads
You cannot share realm instances across threads.
To use the same Realm file across threads, open a different realm instance on each thread. As long as you use the same configuration, all Realm instances will map to the same file on disk.
Pass Immutable Copies Across Threads
Live, thread-confined objects work fine in most cases. However, some apps -- those based on reactive, event stream-based architectures, for example -- need to send immutable copies around to many threads for processing before ultimately ending up on the UI thread. Making a deep copy every time would be expensive, and Realm does not allow live instances to be shared across threads. In this case, you can freeze and thaw objects, collections, and realms.
Freezing creates an immutable view of a specific object, collection, or realm. The frozen object, collection, or realm still exists on disk, and does not need to be deeply copied when passed around to other threads. You can freely share the frozen object across threads without concern for thread issues. When you freeze a realm, its child objects also become frozen.
Frozen objects are not live and do not automatically update. They are effectively snapshots of the object state at the time of freezing. Thawing an object returns a live version of the frozen object.
To freeze a realm, collection, or object, call the .freeze() method:
auto realm = realm::db(std::move(config)); // Get an immutable copy of the database that can be passed across threads. auto frozenRealm = realm.freeze(); if (frozenRealm.is_frozen()) { // Do something with the frozen database. // You may pass a frozen realm, collection, or objects // across threads. Or you may need to `.thaw()` // to make it mutable again. } // You can freeze collections. auto managedItems = realm.objects<realm::Item>(); auto frozenItems = managedItems.freeze(); CHECK(frozenItems.is_frozen()); // You can read from frozen databases. auto itemsFromFrozenRealm = frozenRealm.objects<realm::Item>(); CHECK(itemsFromFrozenRealm.is_frozen()); // You can freeze objects. auto managedItem = managedItems[0]; auto frozenItem = managedItem.freeze(); CHECK(frozenItem.is_frozen()); // Frozen objects have a reference to a frozen realm. CHECK(frozenItem.get_realm().is_frozen());
When working with frozen objects, an attempt to do any of the following throws an exception:
Opening a write transaction on a frozen realm.
Modifying a frozen object.
Adding a change listener to a frozen realm, collection, or object.
You can use .is_frozen() to check if the object is frozen. This is always
thread-safe.
if (frozenRealm.is_frozen()) { // Do something with the frozen database. // You may pass a frozen realm, collection, or objects // across threads. Or you may need to `.thaw()` // to make it mutable again. }
Frozen objects remain valid as long as the live realm that spawned them stays open. Therefore, avoid closing the live realm until all threads are done with the frozen objects. You can close a frozen realm before the live realm is closed.
Important
On caching frozen objects
Caching too many frozen objects can have a negative impact on the realm file size. "Too many" depends on your specific target device and the size of your Realm objects. If you need to cache a large number of versions, consider copying what you need out of the realm instead.
Modify a Frozen Object
To modify a frozen object, you must thaw the object. Alternately, you can
query for it on an unfrozen realm, then modify it. Calling .thaw()
on a live object, collection, or realm returns itself.
Thawing an object or collection also thaws the realm it references.
// Read from a frozen database. auto frozenItems = frozenRealm.objects<realm::Item>(); // The collection that we pull from the frozen database is also frozen. CHECK(frozenItems.is_frozen()); // Get an individual item from the collection. auto frozenItem = frozenItems[0]; // To modify the item, you must first thaw it. // You can also thaw collections and realms. auto thawedItem = frozenItem.thaw(); // Check to make sure the item is valid. An object is // invalidated when it is deleted from its managing database, // or when its managing realm has invalidate() called on it. REQUIRE(thawedItem.is_invalidated() == false); // Thawing the item also thaws the frozen database it references. auto thawedRealm = thawedItem.get_realm(); REQUIRE(thawedRealm.is_frozen() == false); // With both the object and its managing database thawed, you // can safely modify the object. thawedRealm.write([&] { thawedItem.name = "Save the world"; });
Append to a Frozen Collection
When you append to a frozen collection, you must thaw both the object containing the collection and the object that you want to append.
The same rule applies when passing frozen objects across threads. A common case might be calling a function on a background thread to do some work instead of blocking the UI.
In this example, we query for two objects in a frozen Realm:
A
Projectobject that has a list property ofItemobjectsAn
Itemobject
We must thaw both objects before we can append the Item to
the items list collection on the Project. If we thaw only the
Project object but not the Item, Realm throws an error.
// Get frozen objects. // Here, we're getting them from a frozen database, // but you might also be passing them across threads. auto frozenItems = frozenRealm.objects<realm::Item>(); // The collection that we pull from the frozen database is also frozen. CHECK(frozenItems.is_frozen()); // Get the individual objects we want to work with. auto specificFrozenItems = frozenItems.where( [](auto const& item) { return item.name == "Save the cheerleader"; }); auto frozenProjects = frozenRealm.objects<realm::Project>().where( [](auto const& project) { return project.name == "Heroes: Genesis"; }); ; auto frozenItem = specificFrozenItems[0]; auto frozenProject = frozenProjects[0]; // Thaw the frozen objects. You must thaw both the object // you want to append and the object whose collection // property you want to append to. auto thawedItem = frozenItem.thaw(); auto thawedProject = frozenProject.thaw(); auto managingRealm = thawedProject.get_realm(); managingRealm.write([&] { thawedProject.items.push_back(thawedItem); });
struct Item { std::string name; }; REALM_SCHEMA(Item, name)
struct Project { std::string name; std::vector<realm::Item*> items; }; REALM_SCHEMA(Project, name, items)
Schedulers (Run Loops)
Some platforms or frameworks automatically set up a scheduler (or run loop), which continuously processes events during the lifetime of your app. The Realm C++ SDK detects and uses schedulers on the following platforms or frameworks:
macOS, iOS, tvOS, watchOS
Android
Qt
Realm uses the scheduler to schedule work such as Device Sync upload and download.
If your platform does not have a supported scheduler, or you otherwise want to use a custom scheduler, you can implement realm::scheduler and pass the instance to the realm::db_config you use to configure the realm. Realm will use the scheduler you pass to it.
struct MyScheduler : realm::scheduler { MyScheduler() { // ... Kick off task processor thread(s) and run until the scheduler // goes out of scope ... } ~MyScheduler() override { // ... Call in the processor thread(s) and block until return ... } void invoke(std::function<void()>&& task) override { // ... Add the task to the (lock-free) processor queue ... } [[nodiscard]] bool is_on_thread() const noexcept override { // ... Return true if the caller is on the same thread as a processor // thread ... } bool is_same_as(const realm::scheduler* other) const noexcept override { // ... Compare scheduler instances ... } [[nodiscard]] bool can_invoke() const noexcept override { // ... Return true if the scheduler can accept tasks ... } // ... }; int main() { // Set up a custom scheduler. auto scheduler = std::make_shared<MyScheduler>(); // Pass the scheduler instance to the realm configuration. auto config = realm::db_config{path, scheduler}; // Start the program main loop. auto done = false; while (!done) { // This assumes the scheduler is implemented so that it // continues processing tasks on background threads until // the scheduler goes out of scope. // Handle input here. // ... if (shouldQuitProgram) { done = true; } } }
Refreshing Realms
On any thread controlled by a scheduler or run loop, Realm automatically refreshes objects at the start of every run loop iteration. Between run loop iterations, you will be working on the snapshot, so individual methods always see a consistent view and never have to worry about what happens on other threads.
When you initially open a realm on a thread, its state will be the most recent successful write commit, and it will remain on that version until refreshed. If a thread is not controlled by a run loop, then the realm.refresh() method must be called manually in order to advance the transaction to the most recent state.
realm.refresh();
Note
Failing to refresh realms on a regular basis could lead to some transaction versions becoming "pinned", preventing Realm from reusing the disk space used by that version and leading to larger file sizes.
Realm's Threading Model in Depth
Realm provides safe, fast, lock-free, and concurrent access across threads with its Multiversion Concurrency Control (MVCC) architecture.
Compared and Contrasted with Git
If you are familiar with a distributed version control system like Git, you may already have an intuitive understanding of MVCC. Two fundamental elements of Git are:
Commits, which are atomic writes.
Branches, which are different versions of the commit history.
Similarly, Realm has atomically-committed writes in the form of transactions. Realm also has many different versions of the history at any given time, like branches.
Unlike Git, which actively supports distribution and divergence through forking, a realm only has one true latest version at any given time and always writes to the head of that latest version. Realm cannot write to a previous version. This means your data converges on one latest version of the truth.
Internal Structure
A realm is implemented using a B+ tree data structure. The top-level node represents a version of the realm; child nodes are objects in that version of the realm. The realm has a pointer to its latest version, much like how Git has a pointer to its HEAD commit.
Realm uses a copy-on-write technique to ensure isolation and durability. When you make changes, Realm copies the relevant part of the tree for writing. Realm then commits the changes in two phases:
Realm writes changes to disk and verifies success.
Realm then sets its latest version pointer to point to the newly-written version.
This two-step commit process guarantees that even if the write failed partway, the original version is not corrupted in any way because the changes were made to a copy of the relevant part of the tree. Likewise, the realm's root pointer will point to the original version until the new version is guaranteed to be valid.
Example
The following diagram illustrates the commit process:

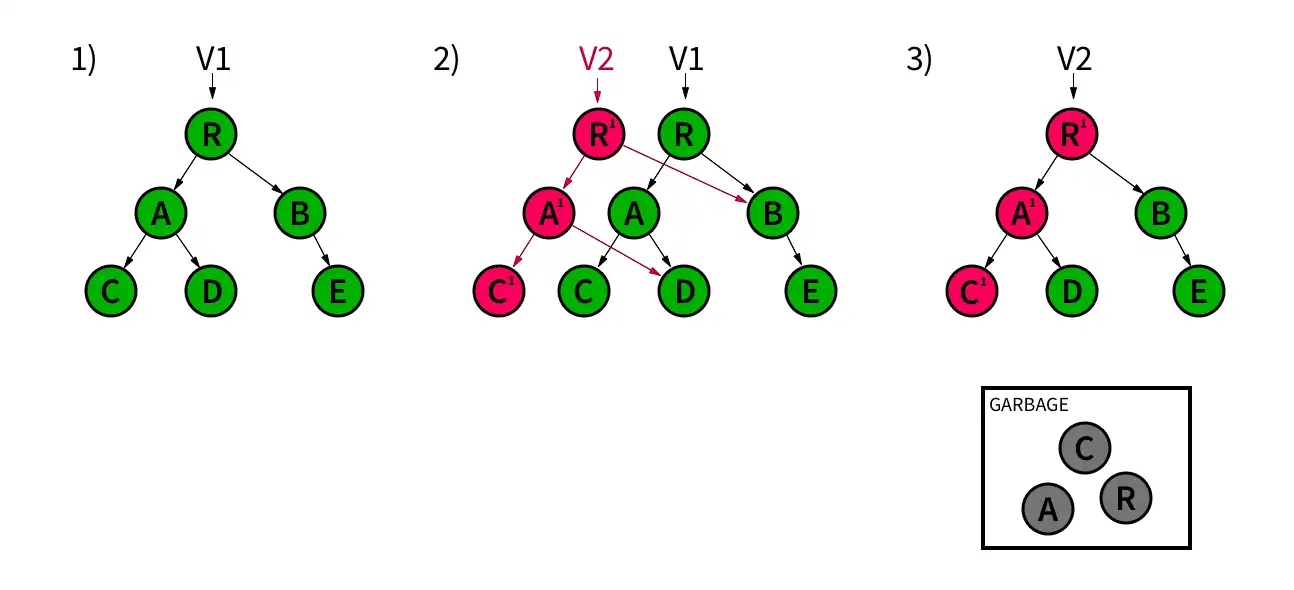
The realm is structured as a tree. The realm has a pointer to its latest version, V1.
When writing, Realm creates a new version V2 based on V1. Realm makes copies of objects for modification (A 1, C 1), while links to unmodified objects continue to point to the original versions (B, D).
After validating the commit, Realm updates the pointer to the new latest version, V2. Realm then discards old nodes no longer connected to the tree.
Realm uses zero-copy techniques like memory mapping to handle data. When you read a value from the realm, you are virtually looking at the value on the actual disk, not a copy of it. This is the basis for live objects. This is also why a realm head pointer can be set to point to the new version after the write to disk has been validated.