Atlas Device Sync 有两种同步模式:灵活同步和较旧的 Partition-Based Sync。Partition-Based Sync 已弃用,而不允许在新的同步配置中使用。
此页面上的信息适用于仍在使用 Partition-Based Sync 的用户。
关键概念
在 Partition-Based Sync 中,同步集群中的文档通过具有与指定为“分区键”的字段相同的值来形成“分区”。对于给定用户,分区中的所有文档都具有相同的读取/写入权限。
您可以定义一个分区键,其值决定用户是否可以读取或写入文档。 App Services评估一设立规则,以确定用户是否可以读取或写入给定分区。 App Services直接将分区映射到各个已同步的 .realm文件。 同步域中的每个对象在分区中都有相应的文档。
例子
考虑一个使用基于分区的同步的库存管理应用程序。如果使用 store_number 作为分区键,则每个商店可以读取和写入与其库存相关的文档。
此类应用的权限示例可能为:
{ "%%partition": "Store 42" }
商店员工对商店号码为 Store 42 的文档可以具有读取和写入访问权限。
同时,客户可以对商店库存进行只读访问。
在客户端中,您在打开同步 Realm 时传递分区键的值。然后,App Services 会同步分区键值与从客户端应用程序传入的值匹配的对象。
例子
根据上面的商店库存示例,SDK 可能会传入 store42 作为同步配置中的 partitionValue。这将同步任何 partitionValue 为 store42 的 InventoryItem。
您可以使用自定义用户数据来指示登录用户是商店员工还是顾客。商店员工对 store42 数据集拥有读写权限,而顾客对该数据集仅拥有读取权限。
const config = { schema: [InventoryItem], // predefined schema sync: { user: app.currentUser, // already logged in user partitionValue: "store42", }, }; try { const realm = await Realm.open(config); realm.close(); } catch (err) { console.error("failed to open realm", err.message); }
Device Sync 要求 MongoDB Atlas 集群运行特定版本的 MongoDB。基于分区的同步需要 MongoDB 4.4.0 或更高版本。
关键词
分区(Partition)
分区是共享相同分区键值的对象的集合。
MongoDB Atlas 集群由多个远程服务器组成。这些服务器为同步数据提供存储空间。Atlas 集群存储集合中的文档。每个 MongoDB 集合映射到不同的 Realm 对象类型。集合中的每个文档代表一个特定的 Realm 对象。
同步 Realm 是设备上的本地文件。同步 Realm 可能包含与最终用户相关的部分或全部对象。客户端应用程序可以使用多个同步 Realm 来访问应用程序所需的所有对象。
分区将 Realm 数据库中的对象关联到 MongoDB 中的文档。当初始化同步 Realm 文件时,其参数之一是分区值。客户端应用在同步 Realm 中创建对象。当这些对象同步时,分区值成为 MongoDB 文档中的一个字段。该字段的值决定了客户端可以访问哪些 MongoDB 文档。
从宏观层面来看:
分区映射到同步集群中文档的子集。
对于给定用户,分区中的所有文档都具有相同的读取/写入权限。
Atlas App Services 将每个分区映射到单独的已同步
.realm文件。已同步 Realm 中的每个对象在分区中都有相应的文档。

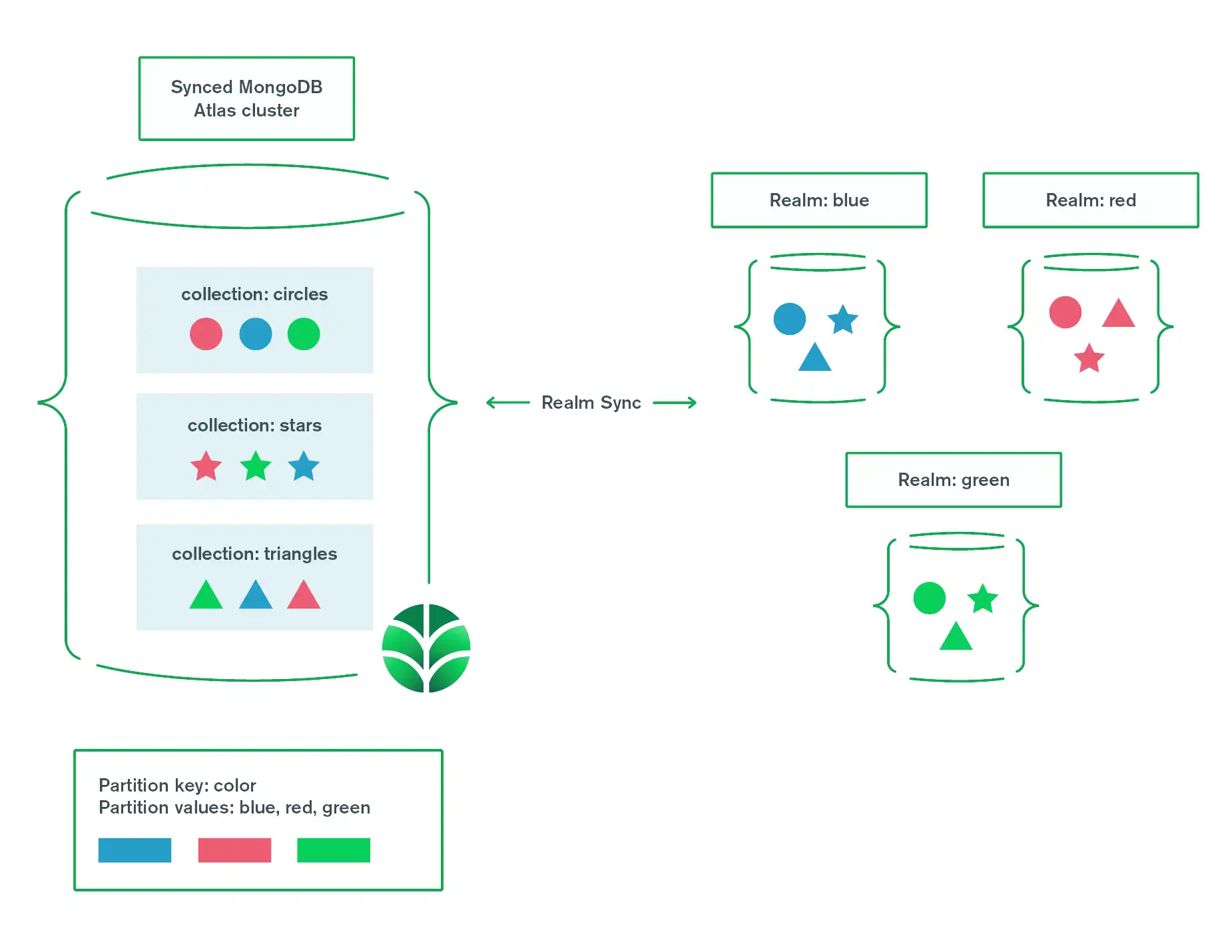
对 Atlas 集群中的形状数据进行分区。每个形状表示一个对象类型。分区由每个形状的 color 决定:红色、绿色或蓝色。
分区键
分区键是您在配置 Atlas Device Sync 时指定的命名字段。Device Sync 使用此键来确定哪个分区包含给定文档。
根据数据模型和应用的复杂性,您的分区键可以是:
每个文档中已存在的属性,用于在逻辑上对数据进行分区。例如,考虑这样一个应用,其中每个文档都是特定用户私有的。您可以将用户的 ID 值存储在
owner_id字段中,然后将其用作分区键。为分割数据而创建的合成属性(例如
_partition)。应用不包含自然分区键时可以使用此属性。
您可以将分区键设置为对象的必填字段或可选字段。App Services 将任何不包含分区键的对象映射到默认分区 — 空分区。
选择分区键时请考虑以下因素:
分区键必须是下列其中一个类型:
String、ObjectID、Long或UUID。App Services 客户端决不应直接修改分区值。不能使用客户端可以修改的任何字段作为分区键。
分区键在每个同步文档中使用相同的字段名。分区键不应与任何对象模型中的任何字段名称冲突。
例子
以下模式展示了自然和合成分区键:
owner_id字段是自然键,因为它已经是应用数据模型的一部分。_partition字段是一个合成键,其唯一用途是用作分区键。
应用只能指定单个分区键,但根据您的使用案例,任一字段都可以起作用:
{ "title": "note", "bsonType": "object", "required": [ "_id", "_partition", "owner_id", "text" ], "properties": { "_id": { "bsonType": "objectId" }, "_partition": { "bsonType": "string" }, "owner_id": { "bsonType": "string" }, "text": { "bsonType": "string" } } } { "title": "notebook", "bsonType": "object", "required": [ "_id", "_partition", "owner_id", "notes" ], "properties": { "_id": { "bsonType": "objectId" }, "_partition": { "bsonType": "string" }, "owner_id": { "bsonType": "string" }, "notes": { "bsonType": "array", "items": { "bsonType": "objectId" } } } }
更改分区键
应用的分区键是启用同步的应用的数据模型的核心部分。在同步配置中设置分区键时,不能稍后重新分配该键的字段。如果需要更改分区键,必须终止同步。然后,您可以使用新的分区键再次启用同步。不过,这要求所有客户端应用重置,并将数据同步到新的 Realm。
警告
终止同步后恢复同步
当您终止并重新启用 Atlas Device Sync 时,客户端将无法再同步。您的客户端必须执行客户端重置处理程序才能恢复同步。此处理程序可以放弃或尝试恢复未同步的更改。
分区值
分区值是给定文档的分区键字段的值。具有相同分区值的文档属于同一分区。它们同步到同一 Realm 文件,并共享用户级数据访问权限。
分区的值是其对应同步 Realm 的标识符。当您在客户端将分区作为同步 Realm 打开时,您可以指定分区的值。如果在 Atlas 中更改分区值,App Services 会将更改解释为两个操作:
从旧分区中删除。
插入到新分区中。
警告
如果更改文档的分区值,则会丢失客户端对对象的未同步更改。
启用基于分区的同步
开始之前
要启用基于分区的同步,您需要:
步骤

选择分区键
Device Sync 分区键是每个同步文档中的一个字段,它将每个文档映射到客户端域。Device Sync 规则适用于分区级别,因此考虑数据模型和访问模式尤为重要。有关分区键以及如何选择分区键的更多信息,请参阅分区。
注意
分区键可以是必需的或可选的。如果分区键字段是可选的,则不包含分区键或分区键为空值的所有 MongoDB 文档都将被送到空分区。如果分区键字段是必需的,则 Device Sync 会忽略缺少有效分区键值的任何 MongoDB 文档。建议分区键为必需字段,除非您想要通过 Device Sync 同步 MongoDB 集合中预先存在的数据,这些数据的分区值无效或缺少分区值。
定义读写权限
Define Permissions 部分允许您定义 JSON 表达式,App Services 动态计算这些表达式以确定用户对给定分区中的数据的读写权限。
Device Sync 规则表达式可以获取 %%user(即打开 Realm 的用户)和 %%partition(即 Realm 的分区键值)。您还可以使用操作符(包括 %function)来处理更复杂的情况。有关示例,请参阅基于角色的权限。
确定如何决定用户对给定分区的读取和写入权限后,请在 Read 和 Write 输入框中定义相应的 JSON 表达式。
拉取最新版本的应用程序
获取应用配置文件的本地副本。要获取最新版本的应用,请运行以下命令:
appservices pull --remote="<Your App ID>"
您也可以从用户界面或使用 Admin API 导出应用程序配置文件的副本。要了解如何操作,请参阅导出应用。
添加同步配置
您可以为应用程序中的单个关联集群启用同步。
App Services App 有一个 sync 目录,您可以在其中找到同步配置文件。如果尚未启用同步,则此目录为空。
添加类似于以下所示的 config.json:
{ "type": "partition", "state": <"enabled" | "disabled">, "development_mode_enabled": <Boolean>, "service_name": "<Data Source Name>", "database_name": "<Database Name>", "partition": { "key": "<Partition Key Field Name>", "type": "<Partition Key Type>", "permissions": { "read": { <Expression> }, "write": { <Expression> } } }, "client_max_offline_days": <Number>, "is_recovery_mode_disabled": <Boolean> }
选择分区键
同步分区键是每个已同步文档中的一个字段,用于将每个文档映射到客户端域。同步规则适用于分区级别,因此考虑数据模型和访问模式尤为重要。有关分区键以及如何选择分区键的更多信息,请参阅分区。
注意
分区键可以是必需的或可选的。 如果分区键字段为可选字段,则排除该分区键或分区分区键为 null 值的所有MongoDB文档都将被发送到空分区。 如果分区键字段为必填项,则Device Sync会忽略任何缺少分区键有效值的MongoDB文档。 我们建议使用必需的分区键,除非您要同步MongoDB集合中具有无效或缺失分区值的预先存在的数据。
决定使用哪个字段后,使用sync.partition key字段中的分区键字段名称和 字段字段的分区键类型更新type ,类似于:
{ ... "partition": { "key": "owner_id", "type": "string", "permissions": { "read": {}, "write": {} } } ... }
定义读写权限
App Services允许您定义JSON表达式,每当用户打开域时,它都会动态评估该表达式,以确定用户是否具有对该分区中的数据的读取或写入权限。
同步规则表达式可以访问权限%%user (可解析为打开域的用户)和%%partition (可解析为域的分区键)。 您还可以使用操作符(包括%function )来处理更复杂的情况。 有关示例,请参阅同步权限。
确定如何决定用户对给定分区的读取和写入权限后,请在 的read 和 字段中定义相应的JSON表达式,类似于:writepartition.permissions
{ ... "partition": { "key": "owner_id", "type": "string", "permissions": { "read": { "$or": [ { "%%user.id": "%%partition" }, { "%%user.custom_data.shared": "%%partition" } ] }, "write": { "%%user.id": "%%partition" } } } ... }
指定同步优化的值
Sync 提供的功能启用您能够优化 Sync 性能并改进客户端上的数据恢复进程。 这些功能由附加设置表示:
client_max_offline_daysis_recovery_mode_disabled
您可以为client_max_offline_days设立一个数值。 当您通过App Services用户界面启用同步时,默认值为30 ,表示30天。
有关更多信息,请参阅:客户端最长离线时间。
恢复模式使同步能够在客户端重置时尝试恢复尚未同步的数据。 当您通过App Services用户界面启用同步时,默认下会启用恢复模式。 我们建议启用恢复模式以进行自动客户端重置处理。 如果您已禁用恢复模式并想重新启用它,请将is_recovery_mode_disabled设立为false 。
有关更多信息,请参阅:恢复未同步的更改。
{ "type": "partition", "state": "enabled", "development_mode_enabled": true, "service_name": "mongodb-atlas", "database_name": "my-test-database", "partition": { ... }, "client_max_offline_days": 30, "is_recovery_mode_disabled": false }
选择要同步的集群
您可以为应用程序中的单个关联集群启用同步。
您需要集群的服务配置文件来配置同步。 您可以通过 Admin API 列出所有服务来查找配置文件:
curl https://services.cloud.mongodb.com/api/admin/v3.0/groups/{GROUP_ID}/apps/{APP_ID}/services \ -X GET \ -h 'Authorization: Bearer <Valid Access Token>'
确定需要更新其配置以启用同步的服务。如果您在配置应用时接受了默认名称,则这应该是一个name为mongodb-atlas且type为mongodb-atlas的服务。 您需要此服务的_id 。
curl https://services.cloud.mongodb.com/api/admin/v3.0/groups/{GROUP_ID}/apps/{APP_ID}/services/{MongoDB_Service_ID}/config \ -X GET \ -h 'Authorization: Bearer <Valid Access Token>'
获得配置后,添加具有以下模板配置的sync对象:
{ ... "sync": { "type": "partition", "state": "enabled", "development_mode_enabled": <Boolean>, "database_name": "<Database Name>", "partition": { "key": "<Partition Key Field Name>", "type": "<Partition Key Type>", "permissions": { "read": { <Expression> }, "write": { <Expression> } } }, "client_max_offline_days": <Number>, "is_recovery_mode_disabled": <Boolean> } ... }
选择分区键
同步分区键是每个已同步文档中的一个字段,用于将每个文档映射到客户端域。同步规则适用于分区级别,因此考虑数据模型和访问模式尤为重要。有关分区键以及如何选择分区键的更多信息,请参阅分区。
您可以通过 Admin API获取所有有效分区键及其相应类型的列表:
curl https://services.cloud.mongodb.com/api/admin/v3.0/groups/{GROUP_ID}/apps/{APP_ID}/sync/data?service_id=<MongoDB Service ID> \ -X GET \ -h 'Authorization: Bearer <Valid Access Token>'
注意
分区键可以是必需的或可选的。 如果分区键字段为可选字段,则排除该分区键或分区分区键为 null 值的所有MongoDB文档都将被发送到空分区。 如果分区键字段为必填项,则Device Sync会忽略任何缺少分区键有效值的MongoDB文档。 我们建议使用必需的分区键,除非您要同步MongoDB集合中具有无效或缺失分区值的预先存在的数据。
决定使用哪个字段后,使用key字段中的分区键字段名称和type字段字段的分区键类型更新sync.partition 。
{ ... "sync": { "type": "partition", "state": "enabled", "development_mode_enabled": <Boolean>, "database_name": "<Database Name>", "partition": { "key": "owner_id", "type": "string", "permissions": { "read": { <Expression> }, "write": { <Expression> } } }, "client_max_offline_days": <Number>, "is_recovery_mode_disabled": <Boolean> } ... }
定义读写权限
App Services允许您定义JSON表达式,每当用户打开域时,它都会动态评估该表达式,以确定用户是否具有对该分区中的数据的读取或写入权限。
同步规则表达式可以访问权限%%user (可解析为打开域的用户)和%%partition (可解析为域的分区键)。 您还可以使用操作符(包括%function )来处理更复杂的情况。 有关示例,请参阅同步权限。
确定如何决定用户对给定分区的读取和写入权限后,请在 的read 和 字段中定义相应的JSON表达式。writesync.partition.permissions
{ ... "sync": { "type": "partition", "state": "enabled", "development_mode_enabled": <Boolean>, "database_name": "<Database Name>", "partition": { "key": "owner_id", "type": "string", "permissions": { "read": { "$or": [ { "%%user.id": "%%partition" }, { "%%user.custom_data.shared": "%%partition" } ] }, "write": { "%%user.id": "%%partition" } } }, "client_max_offline_days": <Number>, "is_recovery_mode_disabled": <Boolean> } ... }
指定同步优化的值
Sync 提供的功能启用您能够优化 Sync 性能并改进客户端数据恢复进程。 这些功能由附加设置表示:
client_max_offline_daysis_recovery_mode_disabled
您可以为client_max_offline_days设立一个数值。 当您通过App Services用户界面启用同步时,默认值为30 ,表示30天。
有关更多信息,请参阅:客户端最长离线时间。
恢复模式使同步能够在客户端重置时尝试恢复未同步的数据。 当您通过App Services用户界面启用同步时,默认下会启用恢复模式。 我们建议启用恢复模式以进行自动客户端重置处理。 要启用恢复模式,请将is_recovery_mode_disabled设立为false 。
有关更多信息,请参阅:恢复未同步的更改。
{ ... "sync": { "type": "partition", "state": "enabled", "development_mode_enabled": true, "database_name": "my-test-database", "partition": { ... }, "client_max_offline_days": 30, "is_recovery_mode_disabled": false } ... }
部署同步配置
现在已经定义了同步配置(包括读取和写入权限),您可以部署更改以开始同步数据并执行同步规则。
要部署更改,请发送Admin API请求,使用同步配置更新集群配置:
curl https://services.cloud.mongodb.com/api/admin/v3.0/groups/{GROUP_ID}/apps/{APP_ID}/services/{MongoDB_Service_ID}/config \ -X PATCH \ -h 'Authorization: Bearer <Valid Access Token>' \ -d @/sync/config.json
基于分区的规则和权限
每当用户从客户端应用打开已同步域时,App Services 都会评估您应用的规则,并确定该用户是否拥有分区的读取和写入权限。用户必须具有读取权限才能同步和读取域中的数据,并且必须具有写入权限才能创建、修改或删除对象。写入权限意味着也有读取权限,因此如果用户拥有写入权限,则他们也拥有读取权限。
基于分区的同步规则行为
同步规则适用于特定分区,并通过分区键耦合到应用的数据模型。设计模式时请考虑以下行为,以确保您具有适当的数据访问粒度,并且不会意外泄漏敏感信息。
同步规则根据用户动态应用。一个用户可能对某个分区具有完全的读写访问权限,而另一用户仅具有读取权限或完全无法访问该分区。您可以通过定义 JSON 表达式来控制这些权限。
同步规则同等适用于分区中的所有对象。如果用户对给定分区具有读取或写入权限,则其可以读取或修改该分区中任何对象的所有同步字段。
写入权限需要读取权限,因此对分区具有写入权限的用户也具有读取权限,无论定义的读取权限规则如何。
基于分区的同步权限
App Services 实施特定于用户的动态读写权限,以保护每个分区中的数据。您可以使用 JSON 规则表达式定义权限,以控制给定用户对给定分区中的数据是否具有读取或写入权限。App Services 会在用户每次打开同步域时评估用户的权限。
提示
规则表达式可以使用 %%partition 和 %%user 等 JSON 扩展,以根据用户请求的上下文动态确定用户的权限。
关键概念
读取权限
对给定分区具有读取权限的用户可以查看相应同步 Realm 中任何对象的所有字段。读取权限不允许用户修改数据。
写入权限
对给定分区具有写入权限的用户可以修改相应同步 Realm 中任何对象的任何字段的值。写入权限需要读取权限,因此任何能够修改数据的用户也可以查看修改前后的数据。
权限策略
重要
关系不能跨分区
在使用 "Partition-Based Sync" 的应用程序中,一个对象只能与同一分区中的其他对象建立关系。只要分区键值匹配,这些对象就可以存在于不同的数据库和集合中(同一集群内)。
您可以将读取和写入权限表达式的结构设置为适用于您的分区策略的一组权限策略。以下策略概述了您可以用来定义应用的同步读取和写入权限的常见方法。
全局权限
您可以定义适用于所有分区的所有用户的全局权限。这本质上是一种不为特定用户设置权限,而是为所有用户提供统一的读取或写入权限的选择。
如需定义全局读取或写入权限,请指定一个布尔值,或一个总是求值为相同布尔值的 JSON 表达式。
例子 | 说明 | |
|---|---|---|
| 表达式 | |
| 表达式 | |
| 该表达式的计算结果始终为 |
特定分区的权限
您可以通过显式指定分区值来定义适用于特定分区或一组分区的的权限。
例子 | 说明 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 该表达式表示,所有用户对于分区值为 | |||||||||
| 该表达式表示,所有用户对于具有任何指定分区值的数据都有给定的访问权限。 |
特定用户的权限
您可以通过显式指定用户的 ID 值来定义适用于特定用户或一组用户的权限。
例子 | 说明 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 该表达式表示 id 为 | |||||||||
| 该表达式表示任何具有指定用户 ID 值之一的用户对任何分区中的数据都有给定的访问权限。 |
基于用户数据的权限
您可以根据用户的自定义用户数据文档、元数据字段或来自身份验证提供程序的其他数据中定义的特定数据来定义适用于用户的权限。
例子 | 说明 | |
|---|---|---|
| 该表达式表示,如果分区值在自定义用户数据的 | |
| 该表达式表示,如果分区值在用户对象的 |
函数规则
您可以计算返回布尔值的函数来定义复杂的动态权限。这种操作对于需要访问外部系统或其他自定义逻辑的权限方案非常有用,因为这些权限方案无法仅用 JSON 表达式来表达。
例子 | 说明 | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 该表达式调用 |
将基于分区的同步规则迁移到 App Services 规则
如果将基于分区的同步应用迁移到灵活同步,数据访问规则也需要迁移。
某些基于分区的同步规则策略无法直接转换为App Services 规则。您可能需要手动迁移包含以下内容的权限:
%function操作符。函数规则与Flexible Sync不兼容,无法迁移。
%%partition扩展。App Services 规则没有用于
%%partition的等效扩展,因此无法迁移。%or、%not、%nor、%and扩展包。这些权限可能有效,但存在很多细微差别,您应该进行测试以确保实现预期行为。测试新权限不适用于您正在迁移的应用。您需要一款新应用来测试手动迁移的权限。
有关所有支持的扩展,请参阅灵活同步兼容扩展列表。
您还应该查看《设备同步权限指南》,了解有关如何使用权限的更多信息。
分区策略
分区策略是一种将对象划分为多个分区的键/值模式。不同的用例需要不同的分区策略。您可以在同一个应用中编写多个分区策略来构成更大的策略。这样一来,您就可以处理任意复杂程度的用例。
使用哪种策略取决于应用的数据模型和访问模式。考虑一个同时包含公共和私有数据的应用。您可以将一些数据(如公告)放在公共分区中。您可以将其他数据(如个人信息)限制为只有特权用户才能访问。
在制定分区策略时,请考虑:
数据安全:用户对数据的不同子集可能需要不同的读取和写入访问权限。考虑用户对不同类型文档所需要的权限。用户对一个分区中的每个文档具有相同的权限。
存储容量:在某些设备和平台上,客户端应用的设备存储空间可能有限。分区策略应考虑存储限制。确保用户可以将其同步数据存储在设备上。
提示
组合策略
您可以使用类似 _partition 的分区键名称,并将查询字符串作为值。这样,您就可以在同一应用中使用多个策略。例如:
_partitionKey: "user_id=abcdefg" _partitionKey: "team_id=1234&city='New York, NY'"
您可以使用函数和规则表达式来解析字符串。同步可以根据组合策略来确定用户是否有权访问某个分区。
Firehose 策略
Firehose 分区策略将所有文档分组到一个分区中。通过这种结构,每个用户都将应用的所有数据同步到其设备。这种方法在功能上相当于不对数据进行分区。这适用于基础应用程序或小型公共数据集。
数据安全。对于其 Realm 使用该分区的客户端,所有数据都是公开的。如果用户对该分区具有读或写访问权限,则他们可以读或写任何 文档。
存储容量。每个用户都能同步分区中的每个文档。所有数据都必须符合最严格的存储限制。仅当数据集较小且增长速度不快时才使用此策略。
创建 firehose 的一种方法是将分区键设置为可选字段。不要在任何文档中包含此字段的值。App Services 将任何不包含分区值的文档映射到空分区。
您也可以设置静态分区值。在这种情况下,分区值不会根据用户或数据而变化。例如,所有客户端的 Realm 都可以使用分区值 "MyPartitionValue"。
例子
一个应用允许用户浏览当地高中棒球比赛的比分和统计数据。假设 games 和 teams 集合中包含以下文档:
collection games: [ { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } ] collection teams: [ { name: "Brook Ridge Miners" } { name: "Southside Rockets" } { name: "Uptown Bombers" } ]
比赛总数很少。少数当地球队每年只打几场比赛。大多数设备应能下载所有比赛数据,以便于离线访问。在这种情况下,firehose 策略是合适的。数据是公开的,文档不需要分区键。
该策略将集合映射到以下 Realm:
realm null: [ Game { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } Game { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } Game { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } Game { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } Game { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } Game { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } Team { name: "Brook Ridge Miners" } Team { name: "Southside Rockets" } Team { name: "Uptown Bombers" } ]
用户策略
用户分区策略对每个用户的私有文档进行分组。这些文档进入用户的专用分区。当每个文档都有一个所有者且没有其他人需要该数据时,此方法有效。标识所有者的用户名或 ID 是自然的分区键。
数据安全。用户分区中的数据是特定用户的专用数据。它可能包含该用户私有的信息。每个用户仅同步自己的分区。其他用户无法访问该分区中的文档。
存储容量。每个用户仅同步来自其自己分区的数据。数据必须适应设备的存储约束。仅当每个用户具有可管理的数据量时才使用此策略。
例子
音乐流媒体应用会存储每位用户的播放列表和歌曲评分数据。考虑 playlists 和 ratings 集合中的以下文档:
collection playlists: [ { name: "Work", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } { name: "Party", owner_id: "cat_enthusiast_92", song_ids: [ ... ] } { name: "Soup Tunes", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } { name: "Disco Anthems", owner_id: "PUBLIC", song_ids: [ ... ] } { name: "Deep Focus", owner_id: "PUBLIC", song_ids: [ ... ] } ] collection ratings: [ { owner_id: "dog_enthusiast_95", song_id: 3, rating: -1 } { owner_id: "cat_enthusiast_92", song_id: 1, rating: 1 } { owner_id: "dog_enthusiast_95", song_id: 1, rating: 1 } ]
每个文档都包含 owner_id 字段。对于用户分区策略而言,这是一个很好的分区键。它自然地将文档映射到各个用户。这会将每台设备上的数据限制为设备用户的播放列表和评分。
用户对其用户 Realm 具有读取和写入访问权限。这包含他们创建的播放列表以及他们对歌曲的评分。
每个用户都具有对分区值
PUBLIC的 Realm 的读取访问权限。这包含可供所有用户使用的播放列表。
该策略将集合映射到以下 Realm:
realm dog_enthusiast_95: [ Playlist { name: "Work", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } Playlist { name: "Soup Tunes", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } Rating { owner_id: "dog_enthusiast_95", song_id: 3, rating: -1 } Rating { owner_id: "dog_enthusiast_95", song_id: 1, rating: 1 } ] realm cat_enthusiast_92: [ Playlist { name: "Party", owner_id: "cat_enthusiast_92", song_ids: [ ... ] } Rating { owner_id: "cat_enthusiast_92", song_id: 1, rating: 1 } ] realm PUBLIC: [ Playlist { name: "Disco Anthems", owner_id: "PUBLIC", song_ids: [ ... ] } Playlist { name: "Deep Focus", owner_id: "PUBLIC", song_ids: [ ... ] } ]
团队战略
团队分区策略对用户团队共享的私有文档进行分组。一个团队可以包括一个商店的员工或一个乐队的成员。每个团队都有该群组专用的分区。团队中的所有用户共享团队文档的访问权和所有权。
数据安全。团队分区中的数据是特定团队的专用数据。它可能包含团队私有但非团队成员私有的数据。每个用户同步其所属团队的分区。团队以外的用户无法访问团队分区中的文档。
存储容量:每个用户仅同步来自自己团队的数据。来自用户团队的数据必须适应其设备的存储约束。当用户属于可管理数量的团队时,请使用此策略。如果用户属于许多团队,那么合并后的 Realm 可能包含大量数据。您可能需要限制一次同步的团队分区数量。
例子
应用允许用户创建项目以与其他用户协作。考虑 projects 和 tasks 集合中的以下文档:
collection projects: [ { name: "CLI", owner_id: "cli-team", task_ids: [ ... ] } { name: "API", owner_id: "api-team", task_ids: [ ... ] } ] collection tasks: [ { status: "complete", owner_id: "api-team", text: "Import dependencies" } { status: "inProgress", owner_id: "api-team", text: "Create app MVP" } { status: "inProgress", owner_id: "api-team", text: "Investigate off-by-one issue" } { status: "todo", owner_id: "api-team", text: "Write tests" } { status: "inProgress", owner_id: "cli-team", text: "Create command specifications" } { status: "todo", owner_id: "cli-team", text: "Choose a CLI framework" } ]
每个文档都包含 owner_id 字段。对于团队分区策略而言,这是一个很好的分区键。它自然地将文档映射到各个团队。这会限制每台设备上的数据。用户只有与他们相关的项目和任务。
用户对其所属团队拥有的分区具有读取和写入访问权限。
teams或users集合中存储的数据可以将用户映射到团队成员:collection teams: [ { name: "cli-team", member_ids: [ ... ] } { name: "api-team", member_ids: [ ... ] } ] collection users: [ { name: "Joe", team_ids: [ ... ] } { name: "Liz", team_ids: [ ... ] } { name: "Matt", team_ids: [ ... ] } { name: "Emmy", team_ids: [ ... ] } { name: "Scott", team_ids: [ ... ] } ]
该策略将集合映射到以下 Realm:
realm cli-team: [ Project { name: "CLI", owner_id: "cli-team", task_ids: [ ... ] } Task { status: "inProgress", owner_id: "cli-team", text: "Create command specifications" } Task { status: "todo", owner_id: "cli-team", text: "Choose a CLI framework" } ] realm api-team: [ Project { name: "API", owner_id: "api-team", task_ids: [ ... ] } Task { status: "complete", owner_id: "api-team", text: "Import dependencies" } Task { status: "inProgress", owner_id: "api-team", text: "Create app MVP" } Task { status: "inProgress", owner_id: "api-team", text: "Investigate off-by-one issue" } Task { status: "todo", owner_id: "api-team", text: "Write tests" } ]
渠道策略
频道分区策略按共同主题或领域对文档进行分组。每个主题或领域都有自己的分区。用户可以选择访问或订阅特定频道。名称或 ID 可以在公共列表中标识这些频道。
数据安全。频道分区中的数据是特定主题或领域的专用数据。用户可以选择访问这些频道。您可以限制用户对频道子集的访问。您可以完全阻止用户访问频道。当用户具有对某个频道的读取或写入权限时,他们可以访问该分区中的任何文档。
存储容量。用户可以选择从任何允许的渠道同步数据。来自用户渠道的所有数据都必须符合其设备的存储限制。使用此策略对公共或半私有数据集进行分区。此策略会拆分不符合存储限制的数据集。
例子
应用允许用户根据主题创建聊天室。用户可以搜索并加入他们感兴趣的任何主题的频道。考虑 chatrooms 和 messages 集合中的以下文档:
collection chatrooms: [ { topic: "cats", description: "A place to talk about cats" } { topic: "sports", description: "We like sports and we don't care who knows" } ] collection messages: [ { topic: "cats", text: "Check out this cute pic of my cat!", timestamp: 1625772933383 } { topic: "cats", text: "Can anybody recommend a good cat food brand?", timestamp: 1625772953383 } { topic: "sports", text: "Did you catch the game last night?", timestamp: 1625772965383 } { topic: "sports", text: "Yeah what a comeback! Incredible!", timestamp: 1625772970383 } { topic: "sports", text: "I can't believe how they scored that goal.", timestamp: 1625773000383 } ]
每个文档都包含 topic 字段。对于频道分区策略而言,这是一个很好的分区键。它自然地将文档映射到各个频道。这会减少每台设备上的数据。数据仅包含用户选定频道的消息和元数据。
用户对其订阅的聊天室具有读取和写入访问权限。用户可以更改或删除任何消息 — 甚至是其他用户发送的消息。若要限制写入权限,可以授予用户只读访问权限。然后使用无服务器函数处理消息发送。
将用户订阅的频道存储在
chatrooms或users集合中:collection chatrooms: [ { topic: "cats", subscriber_ids: [ ... ] } { topic: "sports", subscriber_ids: [ ... ] } ] collection users: [ { name: "Joe", chatroom_ids: [ ... ] } { name: "Liz", chatroom_ids: [ ... ] } { name: "Matt", chatroom_ids: [ ... ] } { name: "Emmy", chatroom_ids: [ ... ] } { name: "Scott", chatroom_ids: [ ... ] } ]
该策略将集合映射到以下 Realm:
realm cats: [ Chatroom { topic: "cats", description: "A place to talk about cats" } Message { topic: "cats", text: "Check out this cute pic of my cat!", timestamp: 1625772933383 } Message { topic: "cats", text: "Can anybody recommend a good cat food brand?", timestamp: 1625772953383 } ] realm sports: [ Chatroom { topic: "sports", description: "We like sports and we don't care who knows" } Message { topic: "sports", text: "Did you catch the game last night?", timestamp: 1625772965383 } Message { topic: "sports", text: "Yeah what a comeback! Incredible!", timestamp: 1625772970383 } Message { topic: "sports", text: "I can't believe how they scored that goal.", timestamp: 1625773000383 } ]
区域战略
地区分区策略对与位置或地区相关的文档进行分组。每个分区都包含特定于这些区域的文档。
数据安全。数据特定于给定地理区域。您可以将用户的访问权限限制在其当前地区。或者,逐个地区授予对数据的访问权限。
存储容量。存储需求因地区的大小和使用模式而异。用户可能只同步自己地区中的数据。任何地区的数据都应适应设备的存储约束。如果用户同步多个地区,则应分成更小的子地区。这有助于避免同步不需要的数据。
例子
一个应用允许用户搜索附近的餐厅并通过其菜单订餐。以 restaurants 集合中的以下文档为例:
collection restaurants: [ { city: "New York, NY", name: "Joe's Pizza", menu: [ ... ] } { city: "New York, NY", name: "Han Dynasty", menu: [ ... ] } { city: "New York, NY", name: "Harlem Taste", menu: [ ... ] } { city: "Chicago, IL", name: "Lou Malnati's", menu: [ ... ] } { city: "Chicago, IL", name: "Al's Beef", menu: [ ... ] } { city: "Chicago, IL", name: "Nando's", menu: [ ... ] } ]
每个文档都包含city 字段。对于地区分区策略而言,这是一个很好的分区键。它自然地将文档映射到特定的物理区域。这会将数据限制为用户当前城市的消息和元数据。用户对其当前地区的餐厅信息拥有读取访问权限。您可以在应用程序逻辑中确定用户的地区。
该策略将集合映射到以下 Realm:
realm New York, NY: [ { city: "New York, NY", name: "Joe's Pizza", menu: [ ... ] } { city: "New York, NY", name: "Han Dynasty", menu: [ ... ] } { city: "New York, NY", name: "Harlem Taste", menu: [ ... ] } ] realm Chicago, IL: [ { city: "Chicago, IL", name: "Lou Malnati's", menu: [ ... ] } { city: "Chicago, IL", name: "Al's Beef", menu: [ ... ] } { city: "Chicago, IL", name: "Nando's", menu: [ ... ] } ]
存储桶策略
存储桶分区策略按范围对文档进行分组。当文档沿着一个维度连续分布时,一个分区包含一个子范围。考虑基于时间的存储桶范围。当文档超出其存储桶范围时,触发器会将文档移动到新分区。
数据安全。限制用户只能读取或写入特定存储桶。数据可以在存储桶之间流动。考虑在所有可能的存储桶中对文档的访问权限。
存储容量。存储需求因每个存储桶的大小和使用模式而异。考虑用户需要访问哪些存储桶。限制存储桶的大小以适应设备的存储约束。如果用户同步许多存储桶,则应分成更小的存储桶。这有助于避免同步不需要的数据。
例子
一个物联网应用每秒多次显示传感器读数的实时视图。存储桶派生自有读数以来的秒数。考虑 readings 集合中的以下文档:
collection readings: [ { bucket: "0s<t<=60s", timestamp: 1625773000383 , data: { ... } } { bucket: "0s<t<=60s", timestamp: 1625772970383 , data: { ... } } { bucket: "0s<t<=60s", timestamp: 1625772965383 , data: { ... } } { bucket: "60s<t<=300s", timestamp: 1625772953383 , data: { ... } } { bucket: "60s<t<=300s", timestamp: 1625772933383 , data: { ... } } ]
每个文档都包含 bucket 字段。此字段将文档映射到特定的时间范围。用户设备只包含其所查看窗口的传感器读数。
用户可以读取任何时间存储桶的传感器读数。
传感器使用具有写入权限的客户端应用程序来上传读数。
该策略将集合映射到以下 Realm:
realm 0s<t<=60s: [ Reading { bucket: "0s<t<=60s", timestamp: 1625773000383 , data: { ... } } Reading { bucket: "0s<t<=60s", timestamp: 1625772970383 , data: { ... } } Reading { bucket: "0s<t<=60s", timestamp: 1625772965383 , data: { ... } } ] realm 60s<t<=300s: [ Reading { bucket: "60s<t<=300s", timestamp: 1625772953383 , data: { ... } } Reading { bucket: "60s<t<=300s", timestamp: 1625772933383 , data: { ... } } ]
数据导入
数据摄取是灵活同步的一项功能,无法在使用基于分区的同步的应用上启用。
基于分区的同步配置
当您使用 Partition-Based Sync 时,您的 Atlas App Services 应用使用以下同步配置:
{ "type": "partition", "state": <"enabled" | "disabled">, "development_mode_enabled": <Boolean>, "service_name": "<Data Source Name>", "database_name": "<Development Mode Database Name>", "partition": { "key": "<Partition Key Field Name>", "type": "<Partition Key Type>", "permissions": { "read": { <Expression> }, "write": { <Expression> } } }, "last_disabled": <Number>, "client_max_offline_days": <Number>, "is_recovery_mode_disabled": <Boolean> }
字段 | 说明 |
|---|---|
typeString | |
stateString | 应用程序同步协议的当前状态。 有效选项:
|
service_nameString | 要同步的 MongoDB 数据源名称。不能将同步与无服务器实例或联合数据库实例一起使用。 |
development_mode_enabledBoolean | 如果为 |
database_nameString | App Services 在开发模式下存储数据的同步集群中数据库的名称。App Services 自动为每个同步类型生成模式,并将每个对象类型映射到数据库内的集合。 |
partition.keyString | 应用的分区键的字段名称。必须在要同步的对象类型的模式中定义此字段。 |
partition.typeString | 分区键字段的值类型。此类型必须与对象模式中定义的类型匹配。 有效选项:
|
partition.permissions.readExpression | 当用户有权读取分区中的对象时,表达式的计算结果为 |
partition.permissions.writeExpression | 一个表达式,当用户有权写入分区中的对象时,该表达式的计算结果为 |
last_disabledNumber | 上次暂停或禁用同步的日期和时间,表示为自 Unix 纪元(1970 年 1 月 1 日,00:00:00 UTC)以来的秒数。 |
client_max_offline_daysNumber | 控制后端压缩进程在积极修剪元数据之前的等待时间,某些客户端需要元数据以从旧版本 Realm 同步。 |
is_recovery_mode_disabledBoolean | 如果为 |
更改基于分区的同步配置
要更改基于分区的 Device Sync 配置,必须终止 Device Sync,然后重新启用 Device Sync。当重新启用 Atlas Device Sync 时,您可以指定新的分区键,或更改读/写权限。在终止和重新启用 Device Sync 时对 Device Sync 配置进行更改,将会触发客户端重置。要了解有关处理客户端重置的更多信息,请阅读客户端重置文档。
基于分区的同步错误
当您的应用程序使用 Partition-Based Sync 时,可能会出现以下错误。
错误名称 | 说明 |
|---|---|
ErrorIllegalRealmPath | 此错误表明客户端试图使用错误类型的分区值打开 Realm。例如,您可能会看到错误消息“attempted to bind on illegal realm partition: expected partition to have type objectId but found string”(试图绑定非法 Realm 分区:预期分区的类型为 objectId,但发现了字符串)。 要从此错误中恢复,请确保用于打开 Realm 的分区值的类型与 Device Sync 配置中的分区键类型匹配。 |
后端压缩
Atlas Device Sync 使用应用的同步 Atlas 集群中的空间来存储元数据以进行同步。这包括每个 Realm 的变更历史记录。Atlas App Services 可最大程度地减少所用的 Atlas 集群空间。要减少同步所需的时间和数据,就必须尽量减少元数据。
使用基于分区的同步的应用程序执行后端压实,以减少 Atlas 集群中存储的元数据量。后端压实是一个维护过程,对于使用基于分区的同步的所有应用程序,会自动为其运行。使用压实,后端通过删除不需要的变更集元数据来优化 realm 的历史记录。如果指令的效果后来被新指令覆盖,则该过程会删除该指令。
例子
考虑以下 Realm 历史记录:
CREATE table1.object1 UPDATE table1.object1.x = 4 UPDATE table1.object1.x = 10 UPDATE table1.object1.x = 42
以下历史记录也会收敛到相同的状态,但没有不必要的临时变更:
CREATE table1.object1 UPDATE table1.object1.x = 42
注意
基于分区的同步使用后端压实来减少Atlas中存储的Device Sync历史记录。 Flexible Sync通过修剪和客户端最大离线时间来实现这一目标。