Página inicial do Docs → Desenvolver aplicações → MongoDB Drivers → Driver de sincronização Java
GridFS
Nesta página
- Visão geral
- Como funciona o GridFS
- Crie um intervalo GridFS
- Armazenar arquivos
- Carregar um arquivo usando um fluxo de entrada
- Carregar um arquivo usando um fluxo de saída
- Recuperar informações do arquivo
- Baixar arquivos
- Revisões de arquivos
- Baixar um arquivo para um fluxo de saída
- Baixar um arquivo para um fluxo de entrada
- Renomear arquivos
- Excluir arquivos
- Excluir um bucket do GridFS
- Recursos adicionais
Visão geral
Neste guia, você pode aprender como armazenar e recuperar arquivos grandes no MongoDB usando o GridFS. O GridFS é uma especificação implementada pelo driver que descreve como dividir os arquivos em blocos ao armazená-los e remontá-los ao recuperá-los. A implementação do driver do GridFS é uma abstração que gerencia as operações e a organização do armazenamento de arquivos.
Você deve usar GridFS se o tamanho dos arquivos exceder o limite de tamanho do documento BSON de 16MB. Para obter informações mais detalhadas sobre se o GridFS é adequado para seu caso de uso, consulte apágina de manual do servidor GridFS .
Consulte as seções a seguir que descrevem as operações do GridFS e como executá-las:
Como funciona o GridFS
O GridFS organiza os arquivos em um bucket, um grupo de coleções do MongoDB que contém os blocos de arquivos e as informações que os descrevem. O bloco contém as seguintes coleções, nomeadas usando a convenção definida na especificação do GridFS:
A coleção
chunksarmazena os blocos de arquivo binário.A coleção
filesarmazena os metadados do arquivo.
Quando você cria um novo bloco GridFS, o driver cria as coleções anteriores, prefixadas com o nome de bloco padrão fs, a menos que você especifique um nome diferente. O driver também cria um índice em cada coleção para garantir a recuperação eficiente de arquivos e metadados relacionados. O driver só cria o bloco GridFS na primeira operação de escrita se ele ainda não existir. O driver só cria índices se eles não existirem e quando o bloco estiver vazio. Para obter mais informações sobre os índices do GridFS, consulte a página do manual do servidor sobre Índices do GridFS.
Ao armazenar arquivos com GridFS, o driver divide os arquivos em blocos menores, cada um representado por um documento separado na coleção do chunks. Ele também cria um documento na coleção files que contém um ID de arquivo, nome de arquivo e outros metadados de arquivo. Você pode carregar o arquivo da memória ou de um stream. Confira o diagrama a seguir para ver como o GridFS divide os arquivos quando carregados em um bucket.

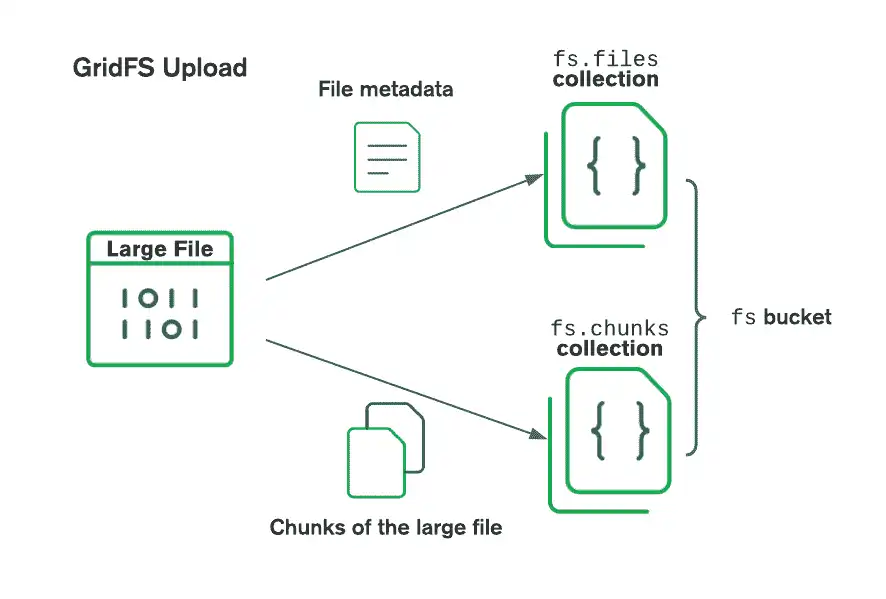
Ao recuperar arquivos, o GridFS obtém os metadados da coleção files no contêiner especificado e utiliza as informações para reconstruir o arquivo a partir de documentos na coleção chunks. Você pode ler o arquivo na memória ou enviá-lo para um fluxo.
Crie um intervalo GridFS
Para armazenar ou recuperar arquivos do GridFS, crie um bloco ou obtenha uma referência a um existente em um banco de dados MongoDB. Chame o método auxiliar do GridFSBuckets.create() com uma instância do MongoDatabase como o parâmetro para instanciar um GridFSBucket. Pode utilizar a instância GridFSBucket para chamar operações de leitura e escrita nos ficheiros no seu bloco.
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database);
Para criar ou referenciar um contêiner com um nome personalizado diferente do nome padrão fs, passe seu nome de contêiner como o segundo parâmetro para o método create() como mostrado abaixo:
GridFSBucket gridFSBucket = GridFSBuckets.create(database, "myCustomBucket");
Observação
Quando você chama create(), o MongoDB não cria o bucket se ele não existir. Na verdade, o MongoDB cria o bucket conforme necessário, como quando você carrega seu primeiro arquivo.
Para obter mais informações sobre as aulas e métodos mencionados nesta seção, consulte a seguinte documentação da API:
Armazenar arquivos
Para armazenar um arquivo em um contêiner GridFS, você pode carregá-lo de uma instância do InputStream ou gravar seus dados em um GridFSUploadStream.
Para qualquer processo de carregamento, você pode especificar informações de configuração, como tamanho do bloco de arquivo e outros pares de campo/valor a serem armazenados como metadados. Defina estas informações em uma instância do GridFSUploadOptions como mostrado no seguinte trecho de código:
GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) // 1MB chunk size .metadata(new Document("myField", "myValue"));
Consulte a documentação da API do GridFSUploadOptions para obter mais informações.
Carregar um arquivo usando um fluxo de entrada
Esta seção mostra como carregar um arquivo em um bucket GridFS usando um fluxo de entrada. O exemplo de código abaixo mostra como usar um FileInputStream para ler dados de um arquivo em seu sistema de arquivos e carregá-los no GridFS executando as seguintes operações:
Leia a partir do sistema de arquivos utilizando um
FileInputStream.Defina o tamanho do bloco usando
GridFSUploadOptions.Defina um campo de metadados personalizado denominado
typepara o valor "arquivo zip".Carregue um arquivo chamado
project.zip, especificando o nome do arquivo GridFS como "myProject.zip".
String filePath = "/path/to/project.zip"; try (InputStream streamToUploadFrom = new FileInputStream(filePath) ) { // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); // Uploads a file from an input stream to the GridFS bucket ObjectId fileId = gridFSBucket.uploadFromStream("myProject.zip", streamToUploadFrom, options); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + fileId.toHexString()); }
Este exemplo de código imprime o ID do arquivo carregado após ele ser salvo corretamente no GridFS.
Para obter mais informações, consulte a documentação da API em uploadFromStream().
Carregar um arquivo usando um fluxo de saída
Esta seção mostra como carregar um arquivo em um contêiner GridFS escrevendo em um fluxo de saída. O exemplo de código a seguir mostra como você pode gravar em um GridFSUploadStream para enviar dados ao GridFS executando as seguintes operações:
Leia um arquivo chamado "project.zip" do sistema de arquivos em uma array de bytes.
Defina o tamanho do bloco usando
GridFSUploadOptions.Defina um campo de metadados personalizado denominado
typepara o valor "arquivo zip".Escreva os bytes em um
GridFSUploadStream, atribuindo o nome do arquivo "myProject.zip". O stream lê os dados em um buffer até atingir o limite especificado na configuraçãochunkSizee os insere como um novo bloco na coleçãochunks.
Path filePath = Paths.get("/path/to/project.zip"); byte[] data = Files.readAllBytes(filePath); // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); try (GridFSUploadStream uploadStream = gridFSBucket.openUploadStream("myProject.zip", options)) { // Writes file data to the GridFS upload stream uploadStream.write(data); uploadStream.flush(); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + uploadStream.getObjectId().toHexString()); // Prints a message if any exceptions occur during the upload process } catch (Exception e) { System.err.println("The file upload failed: " + e); }
Este exemplo de código imprime o ID do arquivo carregado após ele ser salvo corretamente no GridFS.
Observação
Se o upload do arquivo não for bem-sucedido, a operação lançará uma exceção e todos os blocos carregados se tornarão blocos órfãos. Um bloco órfão é um documento em uma coleção GridFS chunks que não faz referência a nenhum ID de arquivo na coleção GridFS files. Os blocos de arquivos podem se tornar blocos órfãos quando uma operação de upload ou exclusão é interrompida. Para remover blocos órfãos, você deve identificá-los usando operações de leitura e removê-los usando operações de gravação.
Para obter mais informações, consulte a documentação da API em GridFSUploadStream.
Recuperar informações do arquivo
Nesta seção, você pode aprender como recuperar metadados de arquivo armazenados na coleção files do contêiner GridFS. Os metadados contêm informações sobre o arquivo a que se refere, incluindo:
O ID do arquivo
O nome do arquivo
O tamanho/comprimento do arquivo
A data e a hora do carregamento
Um documento
metadatano qual você pode armazenar qualquer outra informação
Para recuperar arquivos de um contêiner GridFS, chame o método find() na instância do GridFSBucket. O método retorna um GridFSFindIterable do qual você pode acessar os resultados.
O seguinte exemplo de código mostra como recuperar e imprimir metadados de arquivo de todos os seus arquivos em um bucket GridFS. Entre as diferentes maneiras pelas quais você pode percorrer os resultados recuperados de GridFSFindIterable, o exemplo usa uma interface funcional Consumer para imprimir os seguintes resultados:
gridFSBucket.find().forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
O próximo exemplo de código mostra como recuperar e imprimir os nomes de todos os arquivos que correspondem aos campos especificados no filtro de query. O exemplo também chama sort() e limit() no GridFSFindIterable retornado para especificar a ordem e o número máximo de resultados:
Bson query = Filters.eq("metadata.type", "zip archive"); Bson sort = Sorts.ascending("filename"); // Retrieves 5 documents in the bucket that match the filter and prints metadata gridFSBucket.find(query) .sort(sort) .limit(5) .forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
Como o metadata é um documento incorporado, o filtro de query especifica o campo type dentro do documento usando notação de ponto. Consulte o guia do manual do servidor sobre como fazer query de documentos incorporados/aninhados para obter mais informações.
Para obter mais informações sobre as classes e métodos mencionados nesta seção, consulte os seguintes recursos:
Documentação da API GridFSFindIterable
GridFSBucket.find() Documentação da API
Baixar arquivos
Você pode baixar um arquivo do GridFS diretamente para um fluxo ou salvá-lo na memória de um fluxo. Você pode especificar o arquivo a ser recuperado usando o ID do arquivo ou o nome do arquivo.
Revisões de arquivos
Quando seu bucket contém vários arquivos com o mesmo nome de arquivo, o GridFS escolhe a versão carregada mais recente do arquivo por padrão. Para diferenciar os arquivos que têm o mesmo nome, o GridFS atribui um número de revisão a eles, ordenado por tempo de carregamento.
O número de revisão do arquivo original é "0" e o próximo número de revisão do arquivo mais recente é "1". Você também pode especificar valores negativos que correspondem à recência da revisão. O valor de revisão "-1" faz referência à revisão mais recente e "-2" faz referência à próxima revisão mais recente.
O seguinte trecho de código mostra como você pode especificar a segunda revisão de um arquivo em uma instância do GridFSDownloadOptions:
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(1);
Para obter mais informações sobre a enumeração de revisões, consulte a documentação da API para GridFSDownloadOptions.
Baixar um arquivo para um fluxo de saída
Você pode baixar um arquivo em um contêiner GridFS para um fluxo de saída. O exemplo de código a seguir mostra como você pode chamar o método downloadToStream() para baixar a primeira revisão do arquivo chamado " myProject.zip " para um OutputStream.
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(0); // Downloads a file to an output stream try (FileOutputStream streamToDownloadTo = new FileOutputStream("/tmp/myProject.zip")) { gridFSBucket.downloadToStream("myProject.zip", streamToDownloadTo, downloadOptions); streamToDownloadTo.flush(); }
Para obter mais informações sobre este método, consulte o downloadToStream() Documentação da API.
Baixar um arquivo para um fluxo de entrada
Você pode baixar um arquivo em um contêiner GridFS para memória usando um fluxo de entrada. Você pode chamar o método openDownloadStream() no bucket GridFS para abrir um GridFSDownloadStream, um fluxo de entrada a partir do qual você pode ler o arquivo.
O exemplo de código abaixo mostra como baixar um arquivo referenciado pela variável fileId na memória e imprimir seu conteúdo como uma string:
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Opens an input stream to read a file containing a specified "_id" value and downloads the file try (GridFSDownloadStream downloadStream = gridFSBucket.openDownloadStream(fileId)) { int fileLength = (int) downloadStream.getGridFSFile().getLength(); byte[] bytesToWriteTo = new byte[fileLength]; downloadStream.read(bytesToWriteTo); // Prints the downloaded file's contents as a string System.out.println(new String(bytesToWriteTo, StandardCharsets.UTF_8)); }
Para obter mais informações sobre esse método, consulte o openDownloadStream(). Documentação da API.
Renomear arquivos
Você pode atualizar o nome de um arquivo GridFS em seu contêiner ligando para o método rename(). Você deve especificar o arquivo para renomear pelo ID do arquivo em vez do nome do arquivo.
Observação
O método rename() aceita somente a atualização do nome de um arquivo de cada vez. Para renomear vários arquivos, recupere uma lista de arquivos correspondentes ao nome do arquivo do bucket, extraia os valores de ID de arquivo dos arquivos que deseja renomear e passe cada ID de arquivo em chamadas separadas para o método rename().
O seguinte exemplo de código mostra como atualizar o nome do arquivo referenciado pela variável fileId para "mongodbTutorial.zip":
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Renames the file that has a specified "_id" value to "mongodbTutorial.zip" gridFSBucket.rename(fileId, "mongodbTutorial.zip");
Para obter mais informações sobre este método, consulte o renomear() Documentação da API.
Excluir arquivos
Você pode remover um arquivo do seu contêiner GridFS ligando para o método delete(). Você deve especificar o arquivo pelo ID do arquivo e não pelo nome do arquivo.
Observação
O método delete() só permite excluir um arquivo de cada vez. Para excluir vários arquivos, recupere os arquivos do bucket, extraia os valores de id dos arquivos que você deseja excluir e passe cada id de arquivo em chamadas separadas para o método delete().
O seguinte exemplo de código mostra como excluir o arquivo referenciado pela variável fileId:
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Deletes the file that has a specified "_id" value from the GridFS bucket gridFSBucket.delete(fileId);
Para obter mais informações sobre este método, consulte o método delete() Documentação da API.
Excluir um bucket do GridFS
O exemplo de código a seguir mostra como excluir o bucket padrão do GridFS no banco de dados chamado "mydb". Para fazer referência a um bucket de nome personalizado, consulte a seção deste guia sobre como criar um bucket personalizado.
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database); gridFSBucket.drop();
Para obter mais informações sobre esse método, consulte o método drop() Documentação da API.
Recursos adicionais
Exemplo executável GridFSTour.java do repositório do driver Java do MongoDB.