本番前または本番環境のニーズに合わせて、さまざまな配置タイプ、クラウドプロバイダー、およびクラスター階層を使用してクラスターを構造化できます。これらの推奨事項を使用して、配置タイプ、クラウドプロバイダーとリージョン、およびベクトル検索を実行するためのクラスターと検索階層を選択します。
environment | 配置タイプ | クラスター階層 | クラウドプロバイダーのリージョン | ノード アーキテクチャ |
|---|---|---|---|---|
クエリのテスト | Flex cluster, dedicated cluster Local deployment | M0 or higher tierN/A | All N/A | MongoDB プロセスと Search プロセスは同じノードで実行 |
アプリケーションのプロトタイプ作成 | 専用クラスター | Flex クラスター、 | すべて | MongoDB プロセスと Search プロセスは同じノードで実行 |
本番環境 | 個別の検索ノードを持つ専用クラスター |
| MongoDB プロセスと Search プロセスは異なるノードで実行 |
これらの配置モデルの詳細については、次のセクションを確認してください。
リソース使用
ベクトルのインデックス作成におけるメモリ要件
MongoDB ベクトル検索 はインデックス全体をメモリに保持するため、データセットに完全な精度のベクトルが含まれている場合は、 MongoDB ベクトル検索インデックスとJVMに十分なメモリがあることを確認する必要があります。各インデックスは、インデックスが作成されるベクトルと追加のメタデータの組み合わせです。インデックスのサイズは主にインデックスを作成するベクトルのサイズによって決まり、メタデータ領域は通常比較的少数含まれます。
量子化を使用しない場合、 MongoDB ベクトル検索 は完全な忠実度ベクトルをメモリに保存します。自動量化を有効にすると、 MongoDB ベクトル検索 は必要なリソースが大幅に少ない量化されたベクトルをメモリに保存し、完全な忠実度ベクトルをディスクに保存します。Atlas UI MongoDB Search ページの Size 列と Required Memory 列を表示すると、ベクトルインデックスのディスクとメモリ要件の違いを確認できます。
単一のベクトルの次の要件を考慮してください。
埋め込みモデル | ベクトル次元 | スペース要件 |
|---|---|---|
Voyage AI | 2048 | 8kb (for float)2.14kb (for int8)0.334kb (for int1) |
OpenAI | 1536 | 6kb |
Google | 768 | 3kb |
Cohere | 1024 | 4kb (for float)1.07kb (for int8)0.167kb (for int1) |
BinData 量子化ベクトル。詳しくは、「量子化されたベクトルの取り込み」をご覧ください。
必要なスペースは、インデックスを作成するベクトルの数とベクトル次元に応じて直線的に増加します。 また、 Search Index Sizeメトリクスを使用して、検索ノードに必要なスペースとメモリの量を判断できます。
ベクトルのストレージ要件
BinData または量子化ベクトルを使用すると、binData または量子化ベクトルを使用しない場合と比較して、リソース要件が大幅に削減されます。以下の点にご注意ください。
mongod上のベクトルのディスクストレージは、binDataベクトルを使用することで 66% 減少します。mongot上のベクトルの RAM 使用量は、自動ベクトル量子化または量子化ベクトル取り込みを使用することで、ベクトル圧縮により 3.75倍 (スカラー) または 24倍 (バイナリ) 減少します。
自動量子化を使用すると、Atlasは再スコアリングまたは正確な検索のために全精度ベクトルをディスクに保存し、再スコアリングのためのRAMとキャッシュの使用を最小限に抑えます。
MongoDB ベクトル検索 インデックス定義 で 自動量子化 を有効にする場合は、クラスターのサイズ設定時にディスク容量も考慮する必要があります。これは、自動量子化を構成した場合、 MongoDB ベクトル検索 がENN 検索用と再スコアリング用に全精度ベクトルもディスクに保存するためです。したがって、使用するハードウェアにディスクとRAMの比率が適切であることを確認してください。スカラー量化用のストレージとRAMの比率がほぼ 4:1 の比率、またはバイナリ量子化の場合はストレージとRAMの 24:1 比率に対応できる検索ノードの構成を検討してください。
例
この例は、my-embeddings という名前のフィールドに保存されている Voyage AI の 1000万、1024 次元の埋め込みのバイナリ量子化を構成する方法を示しています。
{ "fields":[ { "type": "vector", "path": "my-embeddings", "numDimensions": 1024, "similarity": "euclidean", "quantization": "binary" } ] }
次の式を使用して、再スコアリングを備えたバイナリ量子化対応インデックスのディスク容量を概算します。
Original index size * (25/24)
ここで、分母の 24 は、元のインデックスサイズを 24 の部分に分けて、分数をより簡単に表現しています。分子の 25 は、バイナリベクトルを格納するために必要な追加データのための、元のインデックスサイズの約 1 / 24 に相当する追加スペース割り当てを示しています。オリジナルのインデックスと Hierarchical Navigable Small Worlds(HNSW)グラフはディスクに保存されています。HNSW グラフが圧縮されていないため、オーバーサイズ係数は 1 / 32 ではなく 1 / 24 です。
例
元のインデックス サイズが 1 GB であると仮定します。以下に示すように、再スコアリングを使用してバイナリ量子化インデックスサイズを計算できます。
1 GB * (25/24) = 1.042 GB
重要
Atlas UIでは、Atlas はインデックスサイズ全体を表示します。これは、 RAMとディスクに保存されているインデックス内のデータ構造を Atlas が表示しないため、サイズが大きくなる可能性があります。MongoDB Search メトリクスでは、自動定量化を有効にすると、メモリに保持されるはるかに小さいインデックスが表示されます。
自動量子化を設定したベクトルには、推定インデックスサイズの 125% に相当する空きディスク容量を割り当てることをお勧めします。
環境のテストとプロトタイプ作成
ベクトル検索クエリをテストし、アプリケーションのプロトタイプ作成には、次の構成が推奨されます。
配置タイプ
MongoDB ベクトル検索クエリをテストするには、 Flex クラスター、専有クラスター、またはローカル Atlas 配置を使用できます。
Cluster Tiers
無料クラスターには、M0 階層が含まれています。Flex クラスターは、MongoDB を学習しているチームや、小規模な概念実証アプリケーションを開発しているチームに適した低コストのクラスタータイプです。Atlas Flex クラスターでプロジェクトを開始し、将来的に本番対応の Atlas 専有クラスター階層にアップグレードすることができます。
これらの低コストのクラスタータイプは、 MongoDB ベクトル検索クエリをテストするために使用できます。ただし、Flex クラスターではリソース競合とクエリレイテンシが発生する可能性があります。Flex クラスターでプロジェクトを開始した場合は、アプリケーションのアプリケーションが準備できたら、より高い階層にアップグレードすることをお勧めします。
専有クラスターにはM10 以上の階層が含まれます。 階層と 階層はアプリケーションのプロトタイプ作成M10 M20に適しています。アプリケーションが本番環境に進む準備ができたら、上位の階層に増やす、大規模なデータセットを処理したり、ワークロードを分離ために専用の検索ノードを配置したりできます。
クラウドプロバイダーとリージョン
選択したクラウド プロバイダーとリージョンは、クラスター階層で利用可能な構成オプションとクラスターの実行コストに影響します。
MongoDB ベクトル検索クエリをローカルでテストしたい場合は、Atlas CLI を使用してローカル コンピューターでホストされている単一ノードのレプリカセットを配置できます。開始するには、 MongoDB ベクトル検索クイック スタート を完了し、 ローカル配置のタブを選択します。
アプリケーションの本番環境が準備できたら、ライブ移行を使用してローカル Atlas の配置を本番環境に移行します。 ローカル配置は、ローカル マシンの CPU、メモリ、およびストレージ リソースによって制限されます。
ノード アーキテクチャ
テストおよびプロトタイプ作成環境には、 MongoDBプロセスとMongoDB Search プロセスが 同じノードで実行されるノードアーキテクチャを推奨します。この配置モデルの次の図では、 MongoDB Search mongot プロセスが Atlas クラスター内の各ノードで mongod と並行して実行され、これらは同じリソースを共有しています。

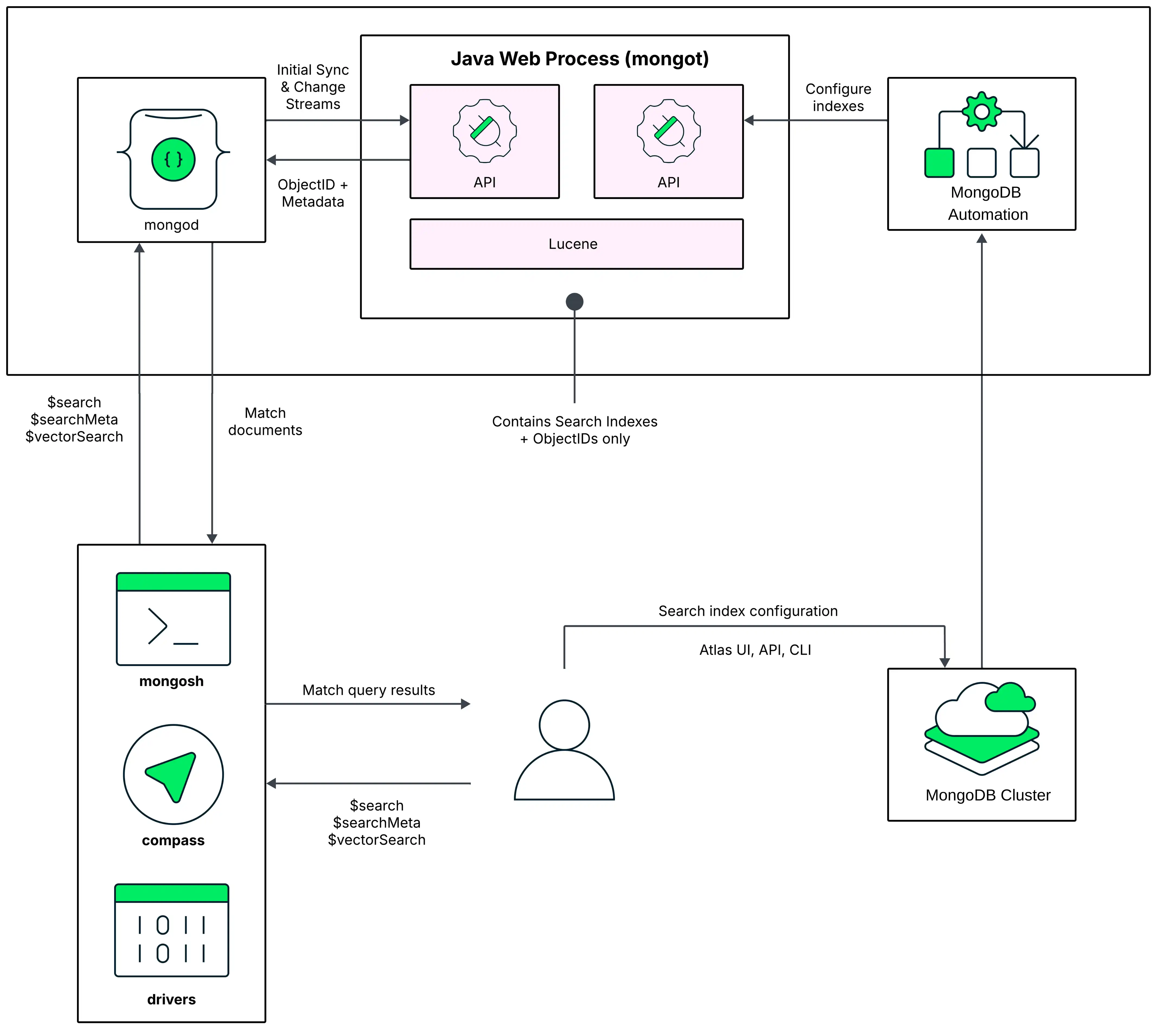
デフォルトでは 、Atlas は 最初のMongoDB ベクトル検索インデックスを作成するときに、mongod プロセスを実行するのと同じノードでMongoDB Search mongot プロセスを有効にします。
クエリを実行する際、 MongoDB Search は 構成済みの読み込み設定 (read preference)を使用して、クエリを実行するノードを識別します。クエリはまずMongoDBプロセスに送られます。このプロセスは、レプリカセットクラスターの場合は mongod、シャーディングされたクラスターの場合は mongos です。
レプリカセットクラスターの場合、mongod プロセスは同じノード上の mongot にクエリをルーティングします。シャーディングされたクラスターの場合、クラスター データは mongod インスタンス(シャード)全体で分割されます。各 mongot プロセスは、同じノード上にある mongodインスタンスのデータにのみアクセスできます。特定のシャードを対象とするMongoDB Search クエリは実行できません。mongos はクエリをすべてのシャードにルーティングするため、これらは scatter-gather パターンのクエリになります。If you use ゾーン を使用してシャーディングされたコレクションをクラスター内のシャードのサブセットにわたって分散する場合、 MongoDB Search はクエリしているコレクションのシャードを含むゾーンにクエリをルーティングして、次のシャードのみで $search クエリを実行します。コレクションが配置されている。
クエリがMongoDB Search mongot プロセスにルーティングされた後、mongot プロセスは検索とスコアリングを実行し、一致する結果のドキュメントID とその他の検索メタデータを対応する mongod プロセスに返します。次に、mongod プロセスは一致する結果のクエリをドキュメント全体で暗黙的に実行し、その結果をクライアントに返します。クエリで $search 同時実行 オプションを使用すると、 MongoDB Search はクエリ内並列処理を有効にします。詳細については、セグメント間でのクエリ実行の並列化 を参照してください。
mongot プロセスの詳細については、「クエリ処理」を参照してください。
アプリケーションのプロトタイプ作成に合わせたクラスターのサイズ設定
Atlas がデータベースと検索ワークロードを 同じノードで実行すると、 MongoDBストレージはノードの使用可能なメモリ(RAM)の特定のパーセンテージを消費し、残りはMongoDB ベクトル検索インデックスと mongot プロセスに残ります。
階層 | 合計メモリ(GB) | MongoDB ベクトル検索インデックスで使用可能なメモリ(GB) |
|---|---|---|
| 2 | 1 |
| 4 | 2 |
| 8 | 4 |
M10、M20、M30 のクラスター階層の場合、25% はMongoDB用に予約され、残りの 75% はMongoDB ベクトル検索インデックスを含む他の操作用です。M40+ クラスター階層の場合、50% はMongoDBに予約され、残りはMongoDB ベクトル検索インデックスを含む他の操作用に確保されます。
制限
データベースmongodと検索mongotプロセス間でリソース競合が発生する可能性があります。 これは、インデックスのパフォーマンスとクエリのレイテンシに悪影響を与える可能性があります。 この配置モデルは、環境のテストとプロトタイプ作成のみに推奨します。 本番環境に対応できるアプリケーションと関連する検索ワークロードの場合は、専用の検索ノードに移行することをお勧めします。
本番環境
本番環境のアプリケーションには、次のクラスター構成が推奨されます。
配置タイプ
本番対応のアプリケーションには、ワークロード分離のために専有クラスターに個別の検索ノードが必要です。
Cluster Tiers
専有クラスターにはM10以上の階層が含まれます。 M10階層とM20 階層は開発環境と本番環境に適しています。ただし、上位階層では大規模なデータセットと本番環境のワークロードを処理できます。 検索ワークロード用に専用の検索ノードも配置することをお勧めします。 これにより、検索配置を個別かつ適切に増やすことができます。
クラウドプロバイダーとリージョン
検索ノードはGoogle Cloud Platformのすべてのリージョンで利用できますが、 Amazon Web ServicesおよびAzureリージョン のサブセットでのみ利用できます。配置で検索ノードが利用できるクラウドプロバイダーとリージョンを選択する必要があります。
すべてのクラスター階層は、サポートされているクラウドプロバイダー リージョンで利用できます。選択したクラウド プロバイダーとリージョンは、クラスターで使用できる構成オプションと検索層、およびクラスターの実行コストに影響します。
ノード アーキテクチャ
本番環境では、 MongoDBプロセスとMongoDB Search プロセスが別々のノードで実行されるノードアーキテクチャを推奨します。個別の検索ノードを配置するには、専用検索ノードへの移行を参照してください。
この配置モデルの次の図では、 MongoDB Search mongot プロセスは専用の検索ノードで実行されます。このノードは、mongod プロセスが実行されるクラスター ノードとは別です。

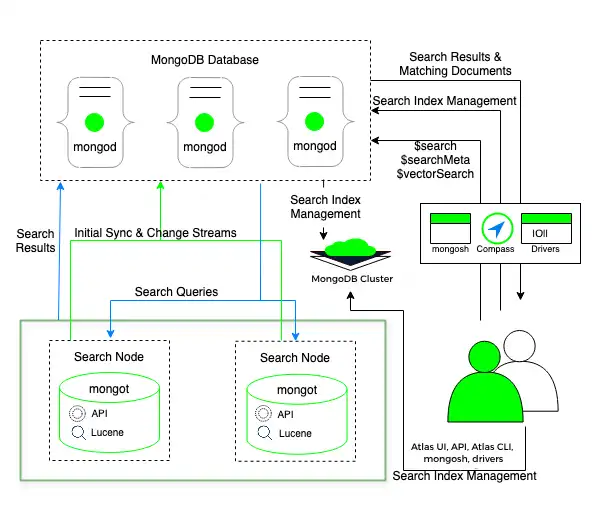
Atlas は、各クラスターまたはクラスター上の各シャードに検索ノードを配置します。たとえば、3 つのシャードを持つクラスターに 2 つの検索ノードを配置すると、Atlas は 6 つの検索ノード(シャードあたり 2 つ)を配置します。また、検索ノードの数と、各検索ノードにプロビジョニングされるリソースの量を構成することもできます。
別個の検索ノードを配置すると、Atlas はインデックス作成用に各 mongot に mongod を自動的に割り当てます。mongot は mongod と通信して、保存しているインデックスの変更をリッスンし、同期します。MongoDB ベクトル検索 は、 mongod と mongot プロセスの両方が 同じノードで実行される配置と同様に、クエリのインデックスと処理を行います。詳細については、 ベクトル検索のフィールドにインデックスを作成する方法 と ベクトル検索クエリの実行方法 を参照してください。検索ノードを個別に配置する方法の詳細については、ワークロード分離用の検索ノード を参照してください。
検索ノードに移行すると、Atlas は検索ノードを配置しますが、検索ノード上のクラスター上のすべてのインデックスが正常に構築されるまで、ノードに対するクエリを処理しません。 Atlas が新しいノードにインデックスをビルドする間も、クラスター ノードのインデックスを使用してクエリを処理し続けます。 Atlas は、検索ノードにインデックスを正常にビルドし、クラスター ノード上のインデックスを削除した後にのみ、検索ノードからクエリの処理を開始します。
注意
検索ノードを追加するか、検索階層を変更してクラスターを拡大すると、完全な MongoDB Search インデックスの再構築がトリガーされます。しかし、AWS または Azure のクラスターに専用の検索ノードがあり、カスタマー キー管理を使用した保管時の暗号化を有効にしていない場合、Atlas は以下の最適化を提供します。
検索ノードを増やすと、Atlas は新しいノードで MongoDB Search インデックス全体を再構築するのではなく、S3 または Azure Blob Storage のインデックスの最新のコピーを使用します。
既存のノードの場合、Atlas はインデックスファイルの新しい増分リストを定期的に取得してアップロードします。Atlas はインデックスファイルを最大14日間保存します。
これは、Google Cloud の専用検索ノードを持つクラスターではまだ使用できません。
クエリを実行すると、そのクエリは構成済みの読み込み設定に基づいて mongod にルーティングされます。mongod プロセスは、同一ノード上のロード バランサーを通じて検索クエリを転送します。その結果、mongot プロセス全体にリクエストが分散されます。
MongoDB Search mongot プロセスは検索とスコアリングを実行し、一致する結果のドキュメントID とメタデータを mongod に返します。次に、mongod はドキュメント全体で一致する結果の検索を実行し、その結果をクライアントに返します。クエリで $search 同時実行 オプションを使用すると、 MongoDB Search はクエリ内並列処理を有効にします。詳細については、セグメント間でのクエリ実行の並列化 を参照してください。
クラスター上のすべての検索ノードを削除すると、検索クエリー結果の処理が中断されます。詳細については、「 クラスターの変更 」を参照してください。Atlas クラスターを削除すると、Atlas は一時停止し、関連付けられているすべてのMongoDB ベクトル検索配置(mongot プロセス)を削除します。
メリット
この配置モデルには、次のメリットがあります。
リソースを効率的に利用しながら、検索ワークロード用にリソースの高可用性を確保します。
検索配置のサイズは、データベース配置とは独立してスケーリングします。
MongoDB ベクトル検索クエリを同時に自動的に処理することで、特に大規模なデータセットでの応答時間が向上します。詳細については、セグメント間での並列クエリ実行 を参照してください。
本番環境の検索ノードのサイズ設定
MongoDB ベクトル検索 はインデックス全体をメモリに保持するため、 MongoDB ベクトル検索インデックスとJVMに十分なメモリがあることを確認する必要があります。検索ノードでは、 データ分離でワークロードを分離できます。RAM 割り当てのほぼ 90% はベクトルデータとインデックスをメモリに保存するために使用でき、残りはJVMに使用されます。
各インデックスは、インデックスが作成されるベクトルと追加のメタデータの組み合わせです。インデックスのサイズは、主にインデックスを作成するベクトルのサイズによって決まります。メタデータの占める容量は通常、比較的わずかなものです。詳しくは、「ベクトルのインデックス作成におけるメモリ要件」をご覧ください。
専用の検索ノードを配置する場合は、さまざまな検索階層から選択できます。 各検索階層には、デフォルトの RAM 容量、ストレージ容量、および CPU が設定されています。 そのため、データベース配置とは別個にクラスターのサイズを設定および拡張することができます。 検索配置を個別にスケーリングするには、いつでもクラスター構成に次の変更を加えることができます。
クラスター上の検索ノードの数を調整します。
検索階層を変更して、ノードの CPU、RAM、ストレージを調整する。
注意
検索ノードと検索階層のコストの詳細については、[ MongoDB 料金] ページで [ View all plan featuresを展開し、[ Atlas Vector Search ] をクリックします。
ノードには、 MongoDB ベクトル検索インデックスの合計サイズより少なくとも 10% 大きいRAMがあることをお勧めします。また、使用可能な CPU が十分にあることを確認することをお勧めします。クエリのレイテンシは利用可能な CPU の数によって異なります。これは、クエリのパフォーマンスを向上させる内部同時実行のレベルに大きく影響可能性があります。
例
サイズが約 3 GB の 1M 768 次元ベクトルがあるとします。S30(低 CPU)と S20(高 CPU)検索階層のどちらにも、インデックスをサポートするのに十分な RAM があります。S30(低 CPU)検索階層に配置する代わりに、S20(高 CPU)検索階層に配置することをお勧めします。S20(高 CPU)検索階層ではクエリを同時に実行するために、より多くの CPU が使用できるためです。
保存時の暗号化の有効化
デフォルトでは、MongoDBプロセスと検索プロセスは同じノードで実行されます。このアーキテクチャでは、カスタマー マネージドの暗号化はデータベースデータに適用されますが、検索インデックスには適用されません。
専用の検索ノードを有効にすると、検索プロセスは別々のノードで実行されます。これにより、検索ノード データの暗号化が有効になり、データベースデータと検索インデックスの両方を同じカスタマー マネージド キーで暗号化して、包括的な暗号化をカバーすることができます。
注意
データベース ノードと検索ノードは、同じカスタマー マネージド キーを使用して異なる暗号化方法を使用します。データベース ノードはWiredTiger暗号化ストレージ エンジンを使用し、検索ノードはディスク レベルの暗号化を使用します。
詳細については、「検索ノードでカスタマーキー管理を有効にする」を参照してください。
重要
この機能は KMS プロバイダー全体で利用できますが、検索ノードは AWS 上にある必要があります。
専用検索ノードへの移行
専用検索ノードを使用すると、クラスターとは別に検索配置のサイズとスケーリングの両方を行うことができます。 また、データベース プロセスと検索プロセスの両方を同じノードで実行するクラスターで発生する可能性のあるリソースの競合も排除されます。
専用検索ノードに移行するには、配置を次の変更で行います。
現在、配置環境で無料階層クラスターまたはフレックスクラスターを使用している場合は、クラスターをより高い階層にアップグレードしてください。専用検索ノードは
M10以上のクラスター階層でのみサポートされます。別のクラスター階層への移行について詳しく学ぶには、Cluster Tierを変更するをご覧ください。専用検索ノードは、Amazon Web ServicesおよびAzureリージョンのサブセット、およびサポートされているすべてのGoogle Cloud Platformリージョンで利用できます。検索ノードも利用できるリージョンに クラスターを配置する ようにします。 既存のクラスターが検索ノードを利用できないリージョンにある場合は、検索ノードが利用できるリージョンにクラスターを移行します。 詳しくは、「 クラウドプロバイダーのリージョン 」を参照してください。
Search Nodes for workload isolationを有効にして、検索ノードを構成します。 詳しくは、「検索ノードを追加する 」を参照してください。