Esta guía describe cómo realizar búsquedas semánticas con los modelos de Voyage AI. Esta página incluye ejemplos de casos de uso básicos y avanzados de búsqueda semántica, incluida la búsqueda con reclasificación, así como la recuperación multilingüe, multimodal, de fragmentos contextualizados y de grandes corpus.
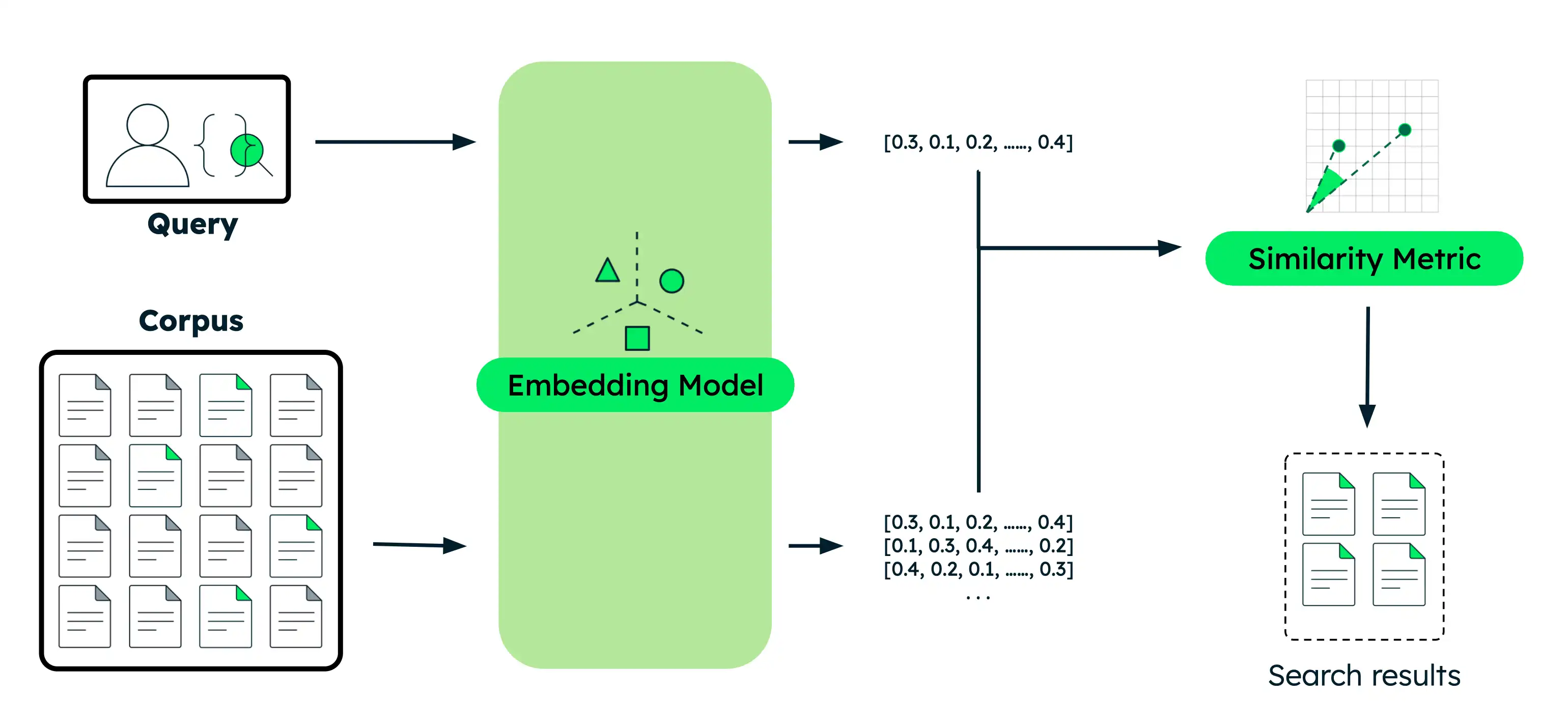
Realizar búsqueda semántica
Esta sección proporciona ejemplos de código para varios casos de uso de búsqueda semántica con diferentes modelos de IA de Voyage. Para cada ejemplo, realiza los mismos pasos básicos:
Incorpora los documentos: convierte tus datos en incrustaciones vectoriales que capturen su significado. Estos datos pueden ser texto, imágenes, fragmentos de documentos o un gran corpus de texto.
Embed the query: transforma tu query de búsqueda en la misma representación vectorial que tus documentos.
Encontrar documentos similares: Compara el vector de query con los vectores de tus documentos para identificar los resultados más semánticamente similares.
Trabaja con una versión ejecutable de este tutorial en un notebook de Python.
Configura tu entorno.
Antes de comenzar, cree un directorio de proyecto, instale bibliotecas y configure su clave API de modelo.
Ejecuta los siguientes comandos en tu terminal para crear un directorio nuevo para este tutorial e instalar las bibliotecas requeridas:
mkdir voyage-semantic-search cd voyage-semantic-search pip install --upgrade voyageai numpy datasets Si aún no lo has hecho, sigue los pasos para Cree una clave API de modelo y luego ejecute el siguiente comando en su terminal para exportarla como una variable de entorno:
export VOYAGE_API_KEY="your-model-api-key"
Ejecutar consultas de búsqueda semántica.
Ampliar cada sección para obtener ejemplos de código para cada tipo de búsqueda semántica.
Crea un archivo denominado
semantic_search_basic.pyen su proyecto y pegue el siguiente código en él:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents documents = [ "The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.", "Photosynthesis in plants converts light energy into glucose and produces essential oxygen.", "20th-century innovations, from radios to smartphones, centered on electronic advancements.", "Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.", "Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.", "Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature." ] # Search query query = "When is Apple's conference call scheduled?" # Generate embeddings for documents doc_embeddings = vo.embed( texts=documents, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(doc_embeddings, query_embedding) # Sort documents by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display results print(f"Query: '{query}'\n") for rank, idx in enumerate(ranked_indices, 1): print(f"{rank}. {documents[idx]}") print(f" Similarity: {similarities[idx]:.4f}\n")
Ejecute el siguiente comando en su terminal:
python semantic_search_basic.py
Query: 'When is Apple's conference call scheduled?' 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Similarity: 0.6691 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Similarity: 0.2751 3. Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature. Similarity: 0.2335 4. The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases. Similarity: 0.1955 5. Photosynthesis in plants converts light energy into glucose and produces essential oxygen. Similarity: 0.1881 6. Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems. Similarity: 0.1601
Cree un archivo llamado
semantic_search_reranker.pyen su proyecto y pegue el siguiente código en él:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents documents = [ "The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.", "Photosynthesis in plants converts light energy into glucose and produces essential oxygen.", "20th-century innovations, from radios to smartphones, centered on electronic advancements.", "Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.", "Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.", "Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature." ] # Search query query = "When is Apple's conference call scheduled?" # Generate embeddings for documents doc_embeddings = vo.embed( texts=documents, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(doc_embeddings, query_embedding) # Sort by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display results before reranking print(f"Query: '{query}'\n") print("Before reranker (embedding similarity only):") for rank, idx in enumerate(ranked_indices[:3], 1): print(f"{rank}. {documents[idx]}") print(f" Similarity Score: {similarities[idx]:.4f}\n") # Rerank documents for improved accuracy rerank_results = vo.rerank( query=query, documents=documents, model="rerank-2.5" ) # Display results after reranking print("\nAfter reranker:") for rank, result in enumerate(rerank_results.results[:3], 1): print(f"{rank}. {documents[result.index]}") print(f" Relevance Score: {result.relevance_score:.4f}\n")
Ejecute el siguiente comando en su terminal:
python semantic_search_reranker.py
Query: 'When is Apple's conference call scheduled?' Before reranker (embedding similarity only): 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Similarity Score: 0.6691 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Similarity Score: 0.2751 3. Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature. Similarity Score: 0.2335 After reranker: 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Relevance Score: 0.9453 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Relevance Score: 0.2832 3. The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases. Relevance Score: 0.2637
Cree un archivo llamado
semantic_search_multilingual.pyen su proyecto y pegue el siguiente código en él:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # English documents about technology companies english_docs = [ "Apple announced record-breaking revenue in its latest quarterly earnings report.", "The Mediterranean diet emphasizes fish, olive oil, and vegetables.", "Microsoft is investing heavily in artificial intelligence and cloud computing.", "Shakespeare's plays continue to influence modern literature and theater." ] # Spanish documents about technology companies spanish_docs = [ "Apple anunció ingresos récord en su último informe trimestral de ganancias.", "La dieta mediterránea enfatiza el pescado, el aceite de oliva y las verduras.", "Microsoft está invirtiendo fuertemente en inteligencia artificial y computación en la nube.", "Las obras de Shakespeare continúan influenciando la literatura y el teatro modernos." ] # Chinese documents about technology companies chinese_docs = [ "苹果公司在最新季度财报中宣布创纪录的收入。", "地中海饮食强调鱼类、橄榄油和蔬菜。", "微软正在大力投资人工智能和云计算。", "莎士比亚的作品继续影响现代文学和戏剧。" ] # Perform semantic search in English english_query = "tech company earnings" # Generate embeddings for English documents english_embeddings = vo.embed( texts=english_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for English query english_query_embedding = vo.embed( texts=[english_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product english_similarities = np.dot(english_embeddings, english_query_embedding) # Sort by similarity (highest to lowest) english_ranked = np.argsort(-english_similarities) print(f"English Query: '{english_query}'\n") for rank, idx in enumerate(english_ranked[:2], 1): print(f"{rank}. {english_docs[idx]}") print(f" Similarity: {english_similarities[idx]:.4f}\n") # Perform semantic search in Spanish spanish_query = "ganancias de empresas tecnológicas" # Generate embeddings for Spanish documents spanish_embeddings = vo.embed( texts=spanish_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for Spanish query spanish_query_embedding = vo.embed( texts=[spanish_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product spanish_similarities = np.dot(spanish_embeddings, spanish_query_embedding) # Sort by similarity (highest to lowest) spanish_ranked = np.argsort(-spanish_similarities) print(f"Spanish Query: '{spanish_query}'\n") for rank, idx in enumerate(spanish_ranked[:2], 1): print(f"{rank}. {spanish_docs[idx]}") print(f" Similarity: {spanish_similarities[idx]:.4f}\n") # Perform semantic search in Chinese chinese_query = "科技公司收益" # Generate embeddings for Chinese documents chinese_embeddings = vo.embed( texts=chinese_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for Chinese query chinese_query_embedding = vo.embed( texts=[chinese_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product chinese_similarities = np.dot(chinese_embeddings, chinese_query_embedding) # Sort by similarity (highest to lowest) chinese_ranked = np.argsort(-chinese_similarities) print(f"Chinese Query: '{chinese_query}'\n") for rank, idx in enumerate(chinese_ranked[:2], 1): print(f"{rank}. {chinese_docs[idx]}") print(f" Similarity: {chinese_similarities[idx]:.4f}\n")
Ejecute el siguiente comando en su terminal:
python semantic_search_multilingual.py
English Query: 'tech company earnings' 1. Apple announced record-breaking revenue in its latest quarterly earnings report. Similarity: 0.5172 2. Microsoft is investing heavily in artificial intelligence and cloud computing. Similarity: 0.4745 Spanish Query: 'ganancias de empresas tecnológicas' 1. Apple anunció ingresos récord en su último informe trimestral de ganancias. Similarity: 0.5232 2. Microsoft está invirtiendo fuertemente en inteligencia artificial y computación en la nube. Similarity: 0.4871 Chinese Query: '科技公司收益' 1. 苹果公司在最新季度财报中宣布创纪录的收入。 Similarity: 0.4725 2. 微软正在大力投资人工智能和云计算。 Similarity: 0.4426
Busca imágenes de muestra y guárdalas en el directorio de tu Proyecto. El siguiente ejemplo de código supone que tiene imágenes de un gato, un perro y un plátano.
Cree un archivo llamado
semantic_search_multimodal.pyen su proyecto y pegue el siguiente código en él:
import voyageai import numpy as np from PIL import Image # Initialize Voyage AI client vo = voyageai.Client() # Prepare interleaved text + image inputs interleaved_inputs = [ ["An orange cat", Image.open('cat.jpg')], ["A golden retriever", Image.open('dog.jpg')], ["A banana", Image.open('banana.jpg')], ] # Prepare image-only inputs image_only_inputs = [ [Image.open('cat.jpg')], [Image.open('dog.jpg')], [Image.open('banana.jpg')], ] # Labels for display labels = ["cat.jpg", "dog.jpg", "banana.jpg"] # Search query query = "a cute pet" # Generate embeddings for interleaved text + image inputs interleaved_embeddings = vo.multimodal_embed( inputs=interleaved_inputs, model="voyage-multimodal-3.5" ).embeddings # Generate embedding for query query_embedding = vo.multimodal_embed( inputs=[[query]], model="voyage-multimodal-3.5" ).embeddings[0] # Calculate similarity scores using dot product interleaved_similarities = np.dot(interleaved_embeddings, query_embedding) # Sort by similarity (highest to lowest) interleaved_ranked = np.argsort(-interleaved_similarities) print(f"Query: '{query}'\n") print("Search with interleaved text + image:") for rank, idx in enumerate(interleaved_ranked, 1): print(f"{rank}. {interleaved_inputs[idx][0]}") print(f" Similarity: {interleaved_similarities[idx]:.4f}\n") # Generate embeddings for image-only inputs image_only_embeddings = vo.multimodal_embed( inputs=image_only_inputs, model="voyage-multimodal-3.5" ).embeddings # Calculate similarity scores using dot product image_only_similarities = np.dot(image_only_embeddings, query_embedding) # Sort by similarity (highest to lowest) image_only_ranked = np.argsort(-image_only_similarities) print("\nSearch with image-only:") for rank, idx in enumerate(image_only_ranked, 1): print(f"{rank}. {labels[idx]}") print(f" Similarity: {image_only_similarities[idx]:.4f}\n")
Ejecute el siguiente comando en su terminal:
python semantic_search_multimodal.py
Query: 'a cute pet' Search with interleaved text + image: 1. An orange cat Similarity: 0.2685 2. A golden retriever Similarity: 0.2325 3. A banana Similarity: 0.1564 Search with image-only: 1. dog.jpg Similarity: 0.2485 2. cat.jpg Similarity: 0.2438 3. banana.jpg Similarity: 0.1210
Cree un archivo llamado
semantic_search_contextualized.pyen su proyecto y pegue el siguiente código en él:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents (each document is a list of chunks that share context) documents = [ [ "This is the SEC filing on Greenery Corp.'s Q2 2024 performance.", "The company's revenue increased by 7% compared to the previous quarter." ], [ "This is the SEC filing on Leafy Inc.'s Q2 2024 performance.", "The company's revenue increased by 15% compared to the previous quarter." ], [ "This is the SEC filing on Elephant Ltd.'s Q2 2024 performance.", "The company's revenue decreased by 2% compared to the previous quarter." ] ] # Search query query = "What was the revenue growth for Leafy Inc. in Q2 2024?" # Generate contextualized embeddings (preserves relationships between chunks) contextualized_result = vo.contextualized_embed( inputs=documents, model="voyage-context-3", input_type="document" ) # Flatten the embeddings and chunks for semantic search contextualized_embeddings = [] all_chunks = [] chunk_to_doc = [] # Maps chunk index to document index for doc_idx, result in enumerate(contextualized_result.results): for emb, chunk in zip(result.embeddings, documents[doc_idx]): contextualized_embeddings.append(emb) all_chunks.append(chunk) chunk_to_doc.append(doc_idx) # Generate contextualized query embedding query_embedding_ctx = vo.contextualized_embed( inputs=[[query]], model="voyage-context-3", input_type="query" ).results[0].embeddings[0] # Calculate similarity scores using dot product similarities_ctx = np.dot(contextualized_embeddings, query_embedding_ctx) # Sort by similarity (highest to lowest) ranked_indices_ctx = np.argsort(-similarities_ctx) # Display top 3 results print(f"Query: '{query}'\n") for rank, idx in enumerate(ranked_indices_ctx[:3], 1): doc_idx = chunk_to_doc[idx] print(f"{rank}. {all_chunks[idx]}") print(f" (From document: {documents[doc_idx][0]})") print(f" Similarity: {similarities_ctx[idx]:.4f}\n")
Ejecute el siguiente comando en su terminal:
python semantic_search_contextualized.py
Query: 'What was the revenue growth for Leafy Inc. in Q2 2024?' 1. The company's revenue increased by 15% compared to the previous quarter. (From document: This is the SEC filing on Leafy Inc.'s Q2 2024 performance.) Similarity: 0.7138 2. This is the SEC filing on Leafy Inc.'s Q2 2024 performance. (From document: This is the SEC filing on Leafy Inc.'s Q2 2024 performance.) Similarity: 0.6630 3. The company's revenue increased by 7% compared to the previous quarter. (From document: This is the SEC filing on Greenery Corp.'s Q2 2024 performance.) Similarity: 0.5531
Cree un archivo llamado
semantic_search_large_corpus.pyen su proyecto y pegue el siguiente código en él:
import voyageai import numpy as np from datasets import load_dataset from collections import defaultdict # Initialize Voyage AI client vo = voyageai.Client() # Load legal benchmark dataset corpus_ds = load_dataset("mteb/legalbench_consumer_contracts_qa", "corpus")["corpus"] queries_ds = load_dataset("mteb/legalbench_consumer_contracts_qa", "queries")["queries"] qrels_ds = load_dataset("mteb/legalbench_consumer_contracts_qa")["test"] # Extract corpus and query data corpus_ids = [row["_id"] for row in corpus_ds] corpus_texts = [row["text"] for row in corpus_ds] query_ids = [row["_id"] for row in queries_ds] query_texts = [row["text"] for row in queries_ds] # Build relevance mapping (defaultdict creates sets for missing keys) qrels = defaultdict(set) for row in qrels_ds: if row["score"] > 0: qrels[row["query-id"]].add(row["corpus-id"]) # Generate embeddings for the entire corpus print(f"Generating embeddings for {len(corpus_texts)} documents...") corpus_embeddings = vo.embed( texts=corpus_texts, model="voyage-4-large", input_type="document" ).embeddings # Select a sample query query_idx = 1 query = query_texts[query_idx] query_id = query_ids[query_idx] # Generate embedding for the query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(corpus_embeddings, query_embedding) # Sort by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display top 5 results print(f"Query: {query}\n") print("Top 5 Results:") for rank, idx in enumerate(ranked_indices[:5], 1): doc_id = corpus_ids[idx] is_relevant = "✓" if doc_id in qrels[query_id] else "✗" print(f"{rank}. [{is_relevant}] Document ID: {doc_id}") print(f" Similarity: {similarities[idx]:.4f}") print(f" Text: {corpus_texts[idx][:100]}...\n") # Show the ground truth most relevant document most_relevant_id = list(qrels[query_id])[0] most_relevant_idx = corpus_ids.index(most_relevant_id) print(f"Ground truth most relevant document:") print(f"Document ID: {most_relevant_id}") print(f"Rank in results: {np.where(ranked_indices == most_relevant_idx)[0][0] + 1}") print(f"Similarity: {similarities[most_relevant_idx]:.4f}")
Ejecute el siguiente comando en su terminal:
python semantic_search_large_corpus.py
Generating embeddings for 154 documents... Query: Will Google come to a users assistance in the event of an alleged violation of such users IP rights? Top 5 Results: 1. [✓] Document ID: 9NIQ0Wobtq Similarity: 0.6047 Text: Your content Some of our services give you the opportunity to make your content publicly available ... 2. [✗] Document ID: gAk7Gdp0CX Similarity: 0.5515 Text: Taking action in case of problems Before taking action as described below, well provide you with adv... 3. [✗] Document ID: S87XwXaHCP Similarity: 0.5178 Text: Privacy and Data Protection Our Privacy Center explains how we treat your personal data. By using th... 4. [✗] Document ID: 8IRh1E2JDB Similarity: 0.5134 Text: OUR PROPERTY The Service is protected by copyright, trademark, and other US and foreign laws. These ... 5. [✗] Document ID: 50OXirZRiR Similarity: 0.5098 Text: Uploading Content If you have a YouTube channel, you may be able to upload Content to the Service. Y... Ground truth most relevant document: Document ID: 9NIQ0Wobtq Rank in results: 1 Similarity: 0.6047
Sobre los Ejemplos
La siguiente tabla resume los ejemplos de esta página:
Ejemplo | Modelo utilizado | Comprender los resultados |
|---|---|---|
Búsqueda semántica básica |
| El documento de llamada de conferencia de Apple ocupa el primer lugar, significativamente más alto que los documentos no relacionados, lo que demuestra una coincidencia semántica precisa. |
Búsqueda semántica con reorganizador |
| La reclasificación mejora la precisión de la búsqueda al analizar la relación completa entre query y documento. Si bien la similitud de incrustaciones por sí sola sitúa el documento correcto en primer lugar con una puntuación moderada, el reranker refuerza significativamente su puntuación de relevancia, separándolo mejor de resultados irrelevantes. |
Búsqueda semántica multilingüe |
| Los modelos de viaje realizan búsquedas semánticas de forma eficaz en diferentes idiomas. El ejemplo muestra tres búsquedas independientes en inglés, español y chino, cada una de las cuales identifica correctamente los documentos más relevantes sobre las ganancias de empresas tecnológicas en sus respectivos idiomas. |
Búsqueda semántica multimodal |
| El modelo permite búsqueda intercalada de texto, imágenes y videos, y también búsqueda exclusiva por imágenes o exclusiva por videos. En ambos casos, las imágenes de mascotas (gato y perro) ocupan una posición significativamente más alta que la imagen no relacionada de un plátano, demostrando una recuperación precisa de contenido visual. Las entradas entrelazadas con texto descriptivo producen puntuaciones de similitud ligeramente superiores a las entradas sólo de imágenes. |
Embeddings de fragmentos contextualizados |
| El 15% de crecimiento de ganancia fragmento ocupa el primer lugar porque está vinculado al documento de Leafy Inc. El fragmento de crecimiento similar del 7% de Greenery Corp. obtiene puntuaciones más bajas, mostrando cómo el modelo considera con precisión el contexto del documento para distinguir entre fragmentos que de otro modo serían similares. |
Búsqueda semántica con un corpus grande |
| El documento de referencia sobre el contenido de usuario ocupa el primer lugar entre 154 documentos, lo que demuestra una recuperación eficaz a gran escala a pesar de la complejidad semántica. |
- Acceso a Embeddings
Los ejemplos utilizan el cliente de Python,
voyageai.Client(), que lee automáticamente la clave de API desde la variable de entornoVOYAGE_API_KEY. La API devuelve un objeto de respuesta. Utilice el atributo.embeddingspara acceder a los vectores de incrustación:result = vo.embed(texts=["example"], model="voyage-4-large", input_type="document") embeddings = result.embeddings # List of embedding vectors - Cálculo de similitud
Los ejemplos calculan puntuaciones de similitud entre las embeddings de query y las del documento usando la función producto punto de Numpy:
np.dot(). Dado que los embeddings de Voyage IA están normalizados a una longitud 1, el producto escalar es matemáticamente equivalente a la similitud del coseno.Para clasificar los resultados por similitud, los ejemplos utilizan la función
argsort()de Numpy para mostrar los N resultados principales. El signo negativo ordena en orden descendente, por lo que los puntajes de similitud más altos aparecen primero.- Parámetro de tipo de entrada
- El parámetro
input_typese establece enqueryodocumentpara optimizar la forma en que los modelos de Voyage IA crean los vectores. No omita este parámetro. Para aprender más, consulta Especificando el tipo de entrada.
Para obtener más información, consulta Acceso a modelos Voyage IA o explora la especificación completa de la API.
¿Qué es la búsqueda semántica?
La búsqueda semántica es un método que devuelve resultados basados en el significado semántico (o subyacente) de los datos. A diferencia de la búsqueda de texto completo tradicional, que encuentra coincidencias, la búsqueda semántica encuentra vectores cercanos a la consulta en un espacio multidimensional. Cuanto más cercanos estén los vectores a la consulta, mayor será su similitud de significado.
Ejemplo
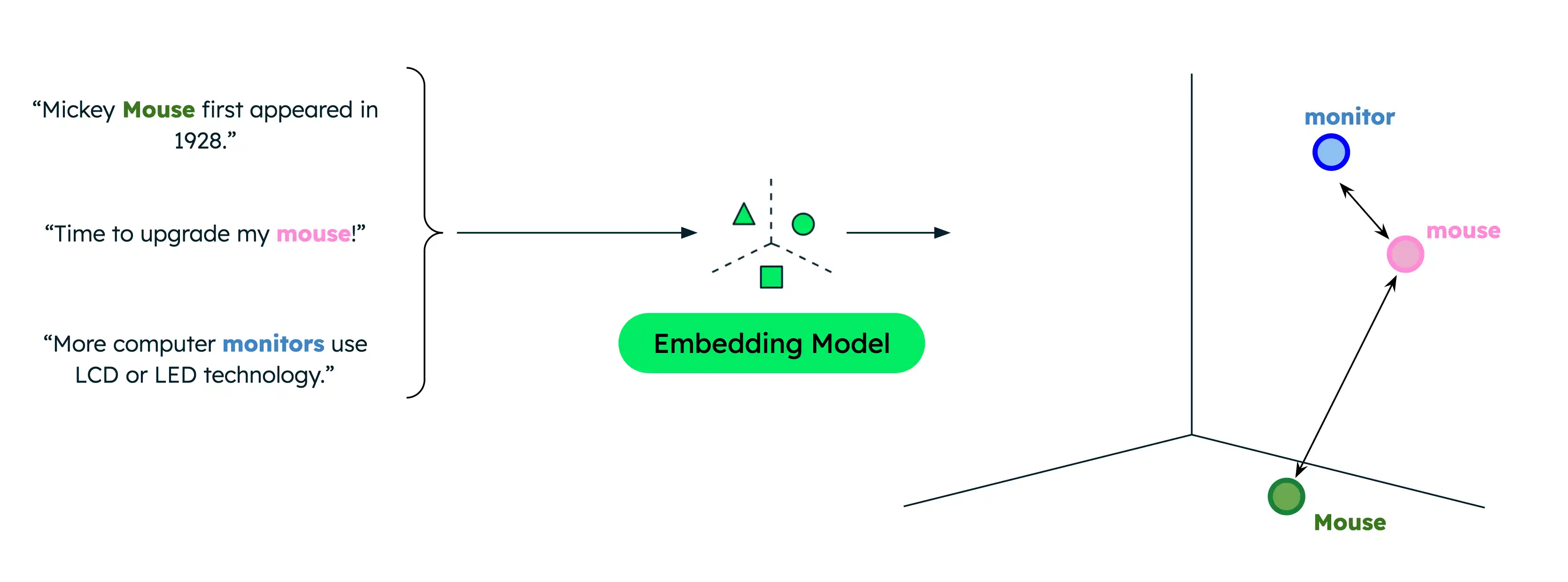
La búsqueda textual tradicional solo devuelve coincidencias exactas, limitando los resultados cuando los usuarios buscan con términos diferentes a los que hay en tus datos. Por ejemplo, si tus datos contienen documentos sobre ratones de computadora y ratones animales, la búsqueda de "mouse" cuando se pretende encontrar información sobre ratones de computadora da como resultado coincidencias incorrectas.
La búsqueda semántica, sin embargo, capta la relación subyacente entre palabras o frases incluso cuando no hay coincidencia léxica. Buscar "mouse" cuando se indica que se buscan productos informáticos resulta en resultados más relevantes. Esto se debe a que la búsqueda semántica compara el significado semántico de la consulta de búsqueda con los datos para devolver solo los resultados más relevantes, independientemente de los términos de búsqueda exactos.

Las funciones de similitud miden la proximidad entre dos vectores, y por lo tanto, cuán similares son. Las funciones comunes incluyen el producto punto, la similitud coseno y la distancia euclidiana. Las incrustaciones de IA de Voyage están normalizadas a una longitud de 1, lo que significa que:
La similitud de coseno es equivalente a la similitud de producto escalar, aunque esta última se puede calcular más rápidamente.
La similitud del coseno y la distancia euclidiana dan como resultado clasificaciones idénticas.
Búsqueda semántica en producción
Si bien almacenar sus vectores en la memoria e implementar sus propios procesos de búsqueda es adecuado para la creación de prototipos y la experimentación, utilice una base de datos de vectores y una solución de búsqueda empresarial para aplicaciones de producción, de modo que pueda realizar una recuperación eficiente de un corpus más grande.
MongoDB ofrece compatibilidad nativa con el almacenamiento y la recuperación de vectores, lo que lo convierte en una opción práctica para almacenar y buscar incrustaciones vectoriales junto con otros datos. Para completar un tutorial sobre cómo realizar búsquedas semánticas con MongoDB Vector Search, consulte "Cómo realizar búsquedas semánticas en los datos de su clúster Atlas".
Próximos pasos
Combina búsqueda semántica con un LLM para implementar una aplicación RAG.