MongoDB proporciona una API para los modelos de incrustación y reevaluación de clase mundial de Voyage IA. Utiliza los modelos de Voyage AI con otras partes de tu pila de IA, incluyendo bases de datos vectoriales y grandes modelos de lenguaje (LLM), para compilar aplicaciones listas para producción con una búsqueda y recuperación de IA precisas.
Comenzar a desarrollar
Utilice los recursos siguientes para comenzar:
Cree una clave API, genere sus primeras incorporaciones y cree una aplicación RAG.
Aprende cómo administrar tus claves API en MongoDB Atlas.
Explora la especificación de la API.
Modelos Voyage IA
Los modelos de integración y reorganización de Voyage IA son lo último en precisión de recuperación. Para obtener más información sobre los modelos, consulta Descripción general de los modelos.
viaje-4-grande
La mejor calidad de recuperación multilingüe y de uso general. Todos los modelos de la serie 4 comparten el mismo espacio de inserción.
contexto de viaje3
Incrustaciones de fragmentos contextualizados optimizados para una calidad de recuperación multilingüe y de propósito general.
viaje-multimodal-3.5
Modelo de incrustación multimodal enriquecido que puede vectorizar texto intercalado y datos visuales, como capturas de pantalla de archivos PDF, diapositivas, tablas, figuras, videos y más.
rerank-2.5
Nuestro reranqueador generalista optimizado para la calidad con seguimiento de instrucciones y soporte multilingüe.
Casos de uso
Los modelos de Voyage AI admiten los siguientes casos de uso:
Utiliza la búsqueda semántica para recuperar información contextual relevante.
Implemente RAG para fundamentar los LLM en sus datos y reducir las alucinaciones.
Mejor juntos
Aprovecha Voyage AI con MongoDB Vector Search e integraciones de IA para agilizar el desarrollo de tus aplicaciones de IA.
Combine los modelos de IA de Voyage con MongoDB Vector Search para crear aplicaciones de IA listas para producción.
Integre con LangChain, LlamaIndex y otros marcos de IA populares.
Conceptos clave
- modelo de incrustación
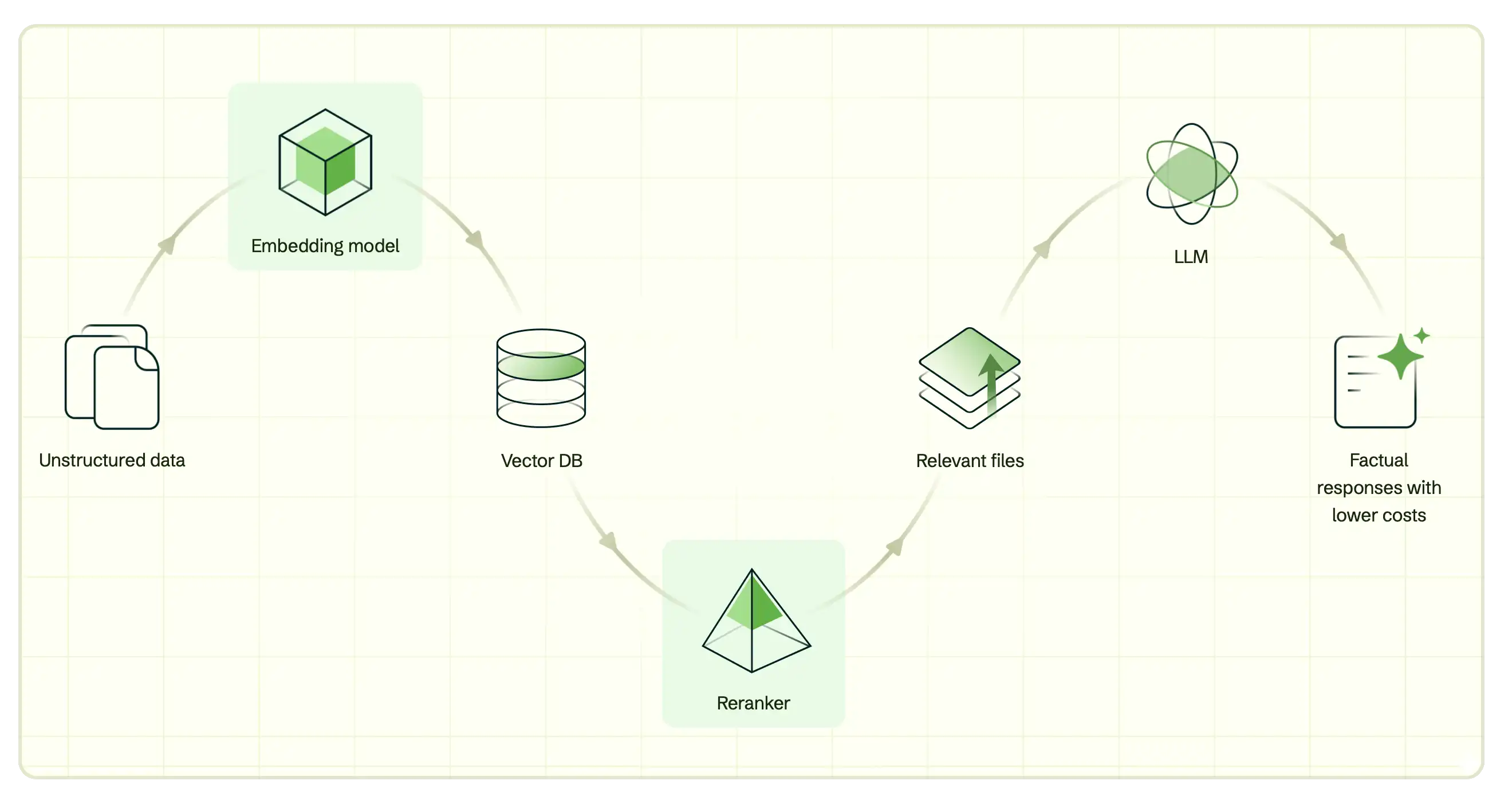
- Los modelos de embedding son algoritmos que convierten datos en vector embedding que capturan el significado semántico o subyacente de los datos. Estos vectores permiten la búsqueda vectorial y sirven como elementos esenciales para generación de recuperación aumentada (RAG), el enfoque predominante para desarrollar aplicaciones de IA confiables.
- reranker
- Los reordenadores son algoritmos que evalúan la relevancia entre una consulta de búsqueda y sus resultados de búsqueda. Los clasificadores te ayudan a perfeccionar los resultados iniciales reordenando los documentos en función de las puntuaciones de relevancia, generando un subconjunto de resultados más precisos.
- embeddings vectoriales
- Una incrustación vectorial es un arreglo de números, siendo cada dimensión la representación de una funcionalidad o atributo diferente de sus datos. Los vectores se pueden utilizar para representar cualquier tipo de datos, desde texto, imágenes y videos hasta datos no estructurados. Crea representaciones vectoriales pasando tus datos por un modelo de representaciones, y puedes almacenar estas representaciones en una base de datos que soporte representaciones vectoriales como MongoDB.
- Búsqueda vectorial
- Búsqueda vectorial es el método de búsqueda que potencia la búsqueda semántica y RAG. Al medir la distancia entre los vectores, se puede determinar la similitud semántica entre diferentes puntos de datos. Esto le permite obtener resultados de búsqueda relevantes al comparar su query vectorizada con sus incrustaciones vectoriales. Puedes utilizar los modelos de Voyage IA con prácticamente cualquier solución de búsqueda vectorial y base de datos vectorial, pero se integran perfectamente con MongoDB Vector Search y MongoDB Atlas.
- RAG
- La generación de recuperación aumentada (RAG) es una arquitectura utilizada para complementar grandes modelos de lenguaje (LLM) con datos adicionales para que puedan generar respuestas más precisas. Para obtener más información, consulta RAG con Voyage AI.
- tokens
- En el contexto de los modelos de embebido y los LLM, los tokens son las unidades fundamentales de texto, como palabras, subpalabras o caracteres, que el modelo procesa para crear embebidos o generar texto. Los tokens son la forma en que se le factura por el uso de modelos de incrustación y LLMs.
- límites de velocidad
- Los límites de tasa son restricciones impuestas por los proveedores de API respecto a la cantidad de solicitudes que un usuario puede realizar en un período de tiempo específico, a menudo medidos en tokens por minuto (TPM) o solicitudes por minuto (RPM). Estos límites garantizan un uso equitativo, previenen abusos y mantienen la estabilidad y el rendimiento del servicio para todos los usuarios.