Una MongoDB Vector Search query adopta la forma de una pipeline de agregación que utiliza $vectorSearch como la primera etapa. Esta página explica la sintaxis, las opciones y el comportamiento de la etapa $vectorSearch.
Clientes compatibles
Sintaxis
Campos
La etapa $vectorSearch procesa un documento con los siguientes campos:
Tipos de búsqueda vectorial
Cuando definís una etapa $vectorSearch, podés utilizar el campo exact para indicar si querés ejecutar una búsqueda ANN o ENN.
Para la búsqueda de Approximate Nearest Neighbors (ANN), MongoDB Vector Search encuentra las incrustaciones vectoriales en sus datos que están más cercanas a la incrustación vectorial de su query, basándose en su proximidad en el espacio multidimensional y en el número de vecinos que considera. Se debe usar el algoritmo Hierarchical Navigable Small Worlds y encontrar las incrustaciones vectoriales más similares a la incrustación vectorial en la query sin escanear todos los vectores. Por lo tanto, la búsqueda ANN es ideal para consultar grandes conjuntos de datos sin un filtro significativo.
Nota
El recall óptimo para la búsqueda ANN se considera típicamente alrededor de un solapamiento del 90-95% en los resultados con la búsqueda ENN, pero con una latencia significativamente menor. Esto ofrece un buen equilibrio entre precisión y rendimiento. Para lograr esto con MongoDB Vector Search, ajusta el parámetro numCandidates en el momento de la query.
numCandidates Selección
Se debe especificar el campo numCandidates para ejecutar una búsqueda ANN. Este campo determina cuántos vecinos más cercanos considera MongoDB búsqueda vectorial durante la búsqueda.
Al realizar una búsqueda vectorial utilizando la estructura de índice Hierarchical Navigable Small Worlds, MongoDB Vector Search acumula resultados llenando una cola de prioridad. El numCandidates parámetro controla el tamaño de esta cola, que determina cuánto tiempo se tarda en buscar antes de devolver los mejores limit resultados. Una cola más grande (un más numCandidates alto) permite que la búsqueda explore una mayor parte del grafo Hierarchical Navigable Small Worlds, lo que podría encontrar mejores coincidencias a costa de una mayor latencia en la consulta.
Recomendamos que especifiques un número numCandidates al menos 20 veces mayor que el número de documentos a devolver (limit) para aumentar la precisión y reducir las discrepancias entre tus resultados de query de ENN y ANN. Por ejemplo, si estableces limit para devolver 5 resultados, considera establecer numCandidates en 100 como punto de partida. Para obtener más información, consulte Cómo medir la precisión de los resultados de su query.
Este patrón de sobrepetición es la forma recomendada de equilibrar la latencia y la capacidad de recuperación en las búsquedas de ANN. Sin embargo, recomendamos ajustar el parámetro numCandidates en función del tamaño específico del conjunto de datos y los requisitos de las queries. Para garantizar la obtención de resultados precisos, se deben considerar las siguientes variables:
Para una búsqueda de vecinos más cercanos exactos (ENN), MongoDB Vector Search busca exhaustivamente en todos los embeddings de vectores indexados calculando la distancia entre todos los embeddings y encuentra el vecino más cercano exacto para el embedding de vector en tu query. Esto requiere un uso intensivo de cálculos y podría impactar negativamente la latencia de la query. Por lo tanto, recomendamos ENN búsquedas para los siguientes casos de uso:
Considerations
$vectorSearch debe ser la primera etapa de cualquier pipeline en el que aparezca.
Limitaciones
$vectorSearch no se puede utilizar en definición de vista ni en las siguientes etapas de la pipeline:
$facetetapa de pipeline
| [1] | Se pueden transferir los resultados de $vectorSearch a esta etapa. |
MongoDB Vector Search indexación
Para obtener más información sobre estos tipos de campos de búsqueda vectorial de MongoDB, consulte Cómo indexar campos para la búsqueda vectorial.
Puntuación de MongoDB Vector Search
La búsqueda vectorial de MongoDB asigna una puntuación, en un rango fijo de 0 a 1 (donde 0 indica baja similitud y 1 indica alta similitud), a cada documento que devuelve.
Nota
El prefiltrado de sus datos no afecta a la puntuación que devuelve la búsqueda vectorial de MongoDB mediante vectorSearchScore para queries $vectorSearch.
Filtrado de búsqueda vectorial en MongoDB
MongoDB Vector Search admite el filtrado de datos. Puedes:
Prefiltra tus datos usando la
filteropción en tu consulta de búsqueda vectorial de MongoDB.Filtre posteriormente los resultados de su consulta de búsqueda vectorial de MongoDB utilizando
$matchy otras etapas de canalización de agregación compatibles.
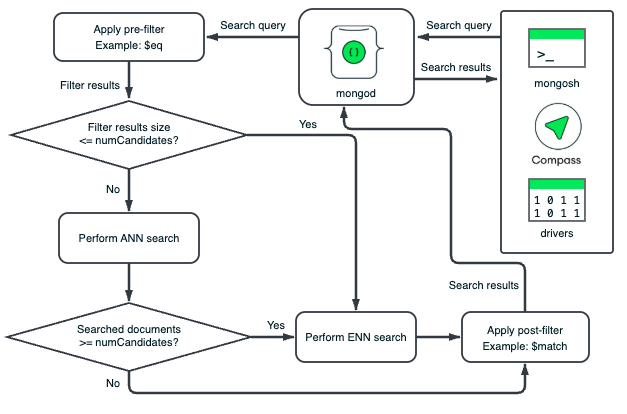
La búsqueda vectorial de MongoDB realiza operaciones de prefiltrado y postfiltrado de forma independiente en segmentos de datos. El grafo HNSW de cada segmento se basa únicamente en los vectores de dicho segmento. La búsqueda vectorial de MongoDB aplica los filtros a los documentos de cada segmento para eliminar aquellos que no cumplen con los criterios de filtrado. El prefiltrado garantiza la eliminación de documentos antes de que la búsqueda vectorial de MongoDB recorra el grafo HNSW, y el postfiltrado asegura la eliminación de documentos o campos irrelevantes de los resultados de la búsqueda vectorial.
Prefiltrar los datos de búsqueda
Puedes prefiltrar tus datos para delimitar el alcance de tu búsqueda semántica y asegurarte de que solo se consideren los vectores relevantes para la comparación. Al prefiltrar tus datos con la opción filter, MongoDB Vector Search realiza la búsqueda semántica solo en un subconjunto de tus datos, lo que reduce los recursos computacionales utilizados por tu consulta de MongoDB Vector Search y mejora el rendimiento.
El prefiltrado puede ser demasiado restrictivo, ya que puede excluir datos que no coinciden exactamente con el prefiltro, pero que son semánticamente similares a la consulta que se desea considerar durante la búsqueda vectorial. Para mitigar esto, recomendamos establecer criterios de filtrado amplios para garantizar que la consulta cumpla con lo siguiente:
Incluye tantos resultados relevantes como sea posible.
Excluye los datos irrelevantes de los resultados.
Devuelve el número de documentos solicitado en los resultados.
Importante
Las **query**s filtradas suelen ser más lentas que una **query** no filtrada equivalente.
Resultados de búsqueda posteriores al filtrado
Si el tamaño de su índice no es óptimo para el prefiltrado o si establece criterios de prefiltrado amplios, puede aplicar un postfiltrado a los resultados de su búsqueda vectorial para obtener solo los datos relevantes. Para filtrar los resultados de su búsqueda vectorial, puede usar cualquier etapa de la canalización de agregación compatible, como la etapa$match, después de la etapa$vectorSearch. Para obtener más información, consulte Recomendaciones adicionales de rendimiento.
Para seleccionar los campos que se mostrarán en los resultados, utilice la $project etapa a menos que necesite que se muestren todos los campos. Recomendamos excluir el campo vectorial en la $project etapa para mejorar el rendimiento de la consulta.
Por ejemplo, puede usar la etapa para incluir $project la vectorSearchScore y luego usar la etapa para devolver solo los documentos por encima de un cierto umbral de $match puntuación.
Consideraciones del filtro
La búsqueda vectorial de MongoDB admite la forma abreviada de
$eq. En la forma abreviada, no es necesario especificar$eqen la query.Por ejemplo, considere el siguiente filtro con
$eq:"filter": { "_id": { "$eq": ObjectId("5a9427648b0beebeb69537a5") } Esto es equivalente al siguiente filtro, que utiliza la forma corta de
$eq:"filter": { "_id": ObjectId("5a9427648b0beebeb69537a5") } Puedes usar el
$andMQL operador para especificar un arreglo de filtros en una sola query.Por ejemplo, considere el siguiente prefiltro para documentos con un campo
genresigual aActiony un campoyearcon el valor1999,2000o2001:"filter": { "$and": [ { "genres": "Action" }, { "year": { "$in": [ 1999, 2000, 2001 ] } } ] } Para capacidades avanzadas de filtrado como búsqueda difusa, coincidencia de frases, filtrado por ubicación y otros textos analizados, utiliza el operador vectorSearch en una etapa de
$search.
Ejemplos
Requisitos previos
Antes de ejecutar estos ejemplos, realiza las siguientes acciones:
Agrega el conjunto de datos de muestra utilizado en la query a tu clúster.
Cree índices de búsqueda de MongoDB para la colección. Para obtener instrucciones, consulta el procedimiento Crear un índice de búsqueda vectorial de MongoDB y copia las configuraciones para las query de muestra en tu lenguaje preferido.