Puedes estructurar tu clúster con diferentes tipos de implementaciones, proveedores de nube y niveles de clúster para satisfacer las necesidades de un entorno de preproducción o producción. Utilice estas recomendaciones para seleccionar el tipo de implementación, el proveedor de nube y la región, así como los niveles de clúster y búsqueda para realizar una búsqueda vectorial.
Entorno | Tipo de implementación | Nivel de clúster | Región del Proveedor de la Nube | Arquitectura de nodo |
|---|---|---|---|---|
Consultas de prueba | Clúster flexible, clúster dedicado | Clúster gratuito o nivel superior | Todos | Los procesos de MongoDB y búsqueda se ejecutan en el mismo nodo |
Prototipado de aplicaciones | clúster dedicado | Flex clúster, | Todo | Los procesos de MongoDB y búsqueda se ejecutan en el mismo nodo |
Producción | Clúster dedicado con nodos de búsqueda independientes |
| AWS y Azure en algunas regiones o Google Cloud en todas las regiones | Los procesos de MongoDB y Search se ejecutan en diferentes nodos |
Para obtener más información sobre estos modelos de implementación, revisa las siguientes secciones:
Uso de recursos
Requisitos de memoria para la indexación de vectores
MongoDB Vector Search mantiene todo el índice en la memoria, por lo que debes asegurarte de que haya suficiente memoria para el índice de MongoDB Vector Search y JVM si tu conjunto de datos incluye vectores de precisión total. Cada índice es una combinación de los vectores que se están indexando y metadatos adicionales. El tamaño del índice está determinado principalmente por el tamaño de los vectores que estás indexando, siendo el espacio de los metadatos normalmente relativamente nominal.
Cuando no se utiliza la cuantificación, MongoDB Vector Search almacena los vectores de fidelidad completa en memoria. Si se habilita la cuantificación automática, MongoDB Vector Search almacena los vectores cuantificados, que requieren significativamente menos recursos, en memoria y los vectores de fidelidad completa en disco. Se puede ver la diferencia entre los requisitos de disco y memoria para los índices vectoriales consultando las columnas Size y Required Memory en la página de búsqueda de MongoDB Search en la interfaz de usuario de Atlas.
Considera los siguientes requisitos para un único vector:
Modelo de incrustación | Dimensión vectorial | Requisitos de espacio |
|---|---|---|
Voyage AI | 2048 | 8kb (para |
OpenAI | 1536 | 6kb |
Google | 768 | 3kb |
Cohere | 1024 | 4kb (para |
Vectores cuantificados de BinData. Para obtener más información, consulte Ingestar vectores cuantificados.
El espacio requerido escalar linealmente con el número de vectores que estás indexación y con la dimensionalidad del vector. También puedes usar el Search Index Size métrica para determinar la cantidad de espacio y memoria que necesitas en tus Nodos de búsqueda.
Requisitos de almacenamiento para vectores
Si utilizas BinData o vectores cuantizados, reduces significativamente los requisitos de recursos en comparación con no utilizar binData o vectores cuantizados. Vas a notar:
El almacenamiento en disco de los vectores en
mongodse reduce un 66% cuando se utilizanbinDatavectores.El uso de RAM de los vectores en
mongotse reduce en 3.75x (escalar) o 24x (binario) debido a la compresión de vectores al utilizar quantización automática de vectores o ingestión de vectores cuantizados.
Cuando utilizas la cuantización automática, Atlas almacena los vectores de precisión total para el re-puntuación o la búsqueda exacta en disco, con un uso mínimo de RAM y caché para re-puntuación.
Si habilitas la cuantización automática en tu definición de índice de Vector Search de MongoDB, también debes considerar el espacio en disco al dimensionar tu clúster. Esto se debe a que MongoDB Vector Search también almacena vectores de precisión completa en el disco para la búsqueda ENN y para la reevaluación si has configurado la cuantización automática. Por lo tanto, asegúrate de que haya una relación adecuada disco/RAM en el hardware que utilices. Considera configurar nodos de búsqueda que puedan acomodar aproximadamente una proporción de almacenamiento a RAM de 4:1 para la cuantización escalar o una proporción de almacenamiento a RAM de 24:1 para la cuantización binaria.
Ejemplo
Este ejemplo demuestra cómo configurar la cuantificación binaria para 10 millones de incrustaciones de 1024dimensiones de Voyage AI almacenadas en el campo llamado my-embeddings:
{ "fields":[ { "type": "vector", "path": "my-embeddings", "numDimensions": 1024, "similarity": "euclidean", "quantization": "binary" } ] }
Utiliza la siguiente fórmula para calcular aproximadamente el espacio en disco para tu índice habilitado para cuantificación binaria con reponderación:
Original index size * (25/24)
Aquí, el 24 en el denominador representa el tamaño original del índice dividido en 24 partes para facilitar la representación de fracciones. El 25 en el numerador representa una asignación de espacio adicional, que es de aproximadamente 1/24 del tamaño del índice original, para los datos adicionales necesarios para almacenar vectores binarios. Tanto el índice original como el grafo de Hierarchical Navigable Small Worlds siguen almacenándose en disco. El factor de sobredimensionamiento es 1/24 en lugar de 1/32 porque el grafo HNSW no está comprimido.
Ejemplo
Supongamos que el tamaño original de tu índice es de 1 GB. Puede calcular el tamaño del índice cuantificado binario con reevaluación como se muestra a continuación:
1 GB * (25/24) = 1.042 GB
Importante
En la interfaz de usuario de Atlas, Atlas muestra el tamaño total del índice, que puede ser grande, ya que Atlas no muestra un desglose de las estructuras de datos dentro de un índice que se almacenan en la RAM y en el disco. Las métricas de MongoDB Search muestran un índice mucho más pequeño que se mantiene en memoria cuando habilitas la cuantización automática.
Para los vectores para los cuales configuraste la cuantización automática, se recomienda reservar un espacio libre en disco igual al 125% del tamaño estimado del índice.
Entornos de pruebas y prototipos
Para probar tus consultas de búsqueda vectorial y crear prototipos de tu aplicación, te recomendamos la siguiente configuración.
Tipo de implementación
Para probar las queries de MongoDB Vector Search, puedes implementar un clúster Flex, un clúster dedicado o usar una implementación local de Atlas.
Cluster Tiers
Los clústeres gratuitos (antes conocidos como M0) son un nivel gratuito de clúster. Los clústeres flex son tipos de clústeres de bajo costo adecuados para equipos que están aprendiendo MongoDB o desarrollando pequeñas aplicaciones de prueba de concepto. Puedes comenzar tu proyecto con un clúster Atlas Flex y actualizar a un nivel de clúster Dedicado listo para producción en el futuro.
Estos tipos de clúster de bajo costo están disponibles para evaluar tus MongoDB Vector Search queries. Sin embargo, en clústeres Flex puedes experimentar contención de recursos y latencia de queries. Si inicias tu proyecto con un clúster Flex, se recomienda actualizar a un nivel superior cuando tu aplicación esté lista para producción.
Los clústeres dedicados incluyen M10 y niveles superiores. Los niveles M10 y M20 son aptos para la creación de prototipos de tu aplicación. Puedes escalar a niveles superiores para gestionar grandes conjuntos de datos o implementar Nodos de Búsqueda dedicados para el aislamiento de carga de trabajo cuando tu aplicación esté lista para producción.
Proveedor de nube y región
El proveedor de nube y la región que elijas afectan las opciones de configuración disponibles para los niveles de clúster y el costo de ejecutar el clúster.
Todos los niveles de clúster están disponibles en todas las regiones de los proveedores de nubesoportadas
Si prefieres probar las consultas de búsqueda vectorial de MongoDB localmente, puedes usar la Atlas CLI para implementar un set de réplicas de un solo nodo alojado en tu computadora local. Para comenzar, completa el Tutorial de inicio rápido de búsqueda vectorial de MongoDB y selecciona la pestaña para implementaciones locales.
Cuando su aplicación esté lista para producción, migre su implementación local de Atlas a un entorno de producción utilizando Migración en vivo. Las implementaciones locales están limitadas por los recursos de CPU, memoria y almacenamiento de tu máquina local.
Arquitectura de nodo
Para entornos de prueba y creación de prototipos, recomendamos una arquitectura de nodo en la que los procesos de MongoDB y los procesos de MongoDB Search se ejecuten en el mismo nodo. En el siguiente diagrama de este modelo de implementación, el proceso de MongoDB Search mongot se ejecuta junto con mongod en cada nodo del clúster de Atlas y comparten los mismos recursos.

Por defecto, Atlas habilita el proceso mongot de MongoDB Search en el mismo nodo que ejecuta el proceso mongod cuando creas tu primer índice de MongoDB Vector Search.
Cuando ejecutas una query, MongoDB Search utiliza la preferencia de lectura configurada para identificar el nodo en el que ejecutar la query. La query primero va al proceso de MongoDB, que es mongod para un clúster de conjunto de réplicas o mongos para un clúster particionado.
Para un clúster de set de réplicas, el proceso mongod enruta la query al mongot en el mismo nodo. Para clusters fragmentados, los datos del clúster se particionan en mongod instancias (fragmentos) y cada proceso mongot solo puede acceder a los datos en la instancia mongod en el mismo nodo. Por lo tanto, no puedes ejecutar consultas de búsqueda de MongoDB que se dirijan a una partición específica. mongos envía la consulta a todas las particiones, convirtiéndolas en consultas scatter gather. Si usas zonas para distribuir una colección particionada sobre un subconjunto de los shards en el clúster, MongoDB Search enruta la query a la zona que contiene los shards para la colección que estás consultando y ejecuta tus $search queries solo en los shards donde se encuentra la colección.
Después de que la query se enruta a un proceso de MongoDB Search mongot, el proceso mongot realiza la búsqueda y el puntaje y devuelve los ID de documentos y otros metadatos de búsqueda de los resultados coincidentes a su proceso correspondiente mongod. Luego, el proceso mongod realiza implícitamente una búsqueda completa de documentos para los resultados coincidentes y devuelve los resultados al cliente. Si usas la opción $search simultánea en tu consulta, MongoDB Search habilita el paralelismo intraconsulta. Para obtener más información, consulta Paraleliza la ejecución de consultas entre segmentos.
Para obtener más información sobre el proceso de mongot, consulta Procesamiento de consultas.
Dimensiona tu clúster para prototipar tu aplicación
Cuando Atlas ejecuta tus cargas de trabajo de base de datos y búsqueda en el mismo nodo, el almacenamiento de MongoDB ocupa un cierto porcentaje de la memoria disponible del nodo (RAM), dejando el resto para el índice de MongoDB Vector Search y el proceso mongot.
Nivel | Memoria total (GB) | Memoria disponible para el índice de MongoDB Vector Search (GB) |
|---|---|---|
| 2 | 1 |
| 4 | 2 |
| 8 | 4 |
Para los niveles de clúster M10, M20 y M30, se reserva el 25% para MongoDB y el 75% restante es para otras operaciones, incluido tu índice MongoDB Vector Search. Para los niveles de clúster M40+, se reserva el 50% para MongoDB y el resto para otras operaciones, incluido tu índice de MongoDB Vector Search.
Limitaciones
Es posible que experimente disputas de recursos entre la base de datos mongod y los procesos de búsqueda mongot. Esto podría afectar negativamente el rendimiento de tu índice y la latencia de tus consultas. Recomendamos este modelo de implementación solo para entornos de prueba y creación de prototipos. Para aplicaciones listas para producción y cargas de trabajo de búsqueda asociadas, recomendamos migrar a nodos de búsqueda dedicados.
Ambiente de producción
Para tu aplicación lista para producción, recomendamos la siguiente configuración de clúster.
Tipo de implementación
Para aplicaciones listas para producción, necesitas un clúster dedicado con Nodos de búsqueda para el aislamiento de la carga de trabajo.separados.
Cluster Tiers
Los clústeres dedicados incluyen el nivel M10 y superiores. Los niveles M10 y M20 son adecuados tanto para entornos de desarrollo como de producción. Sin embargo, los niveles superiores pueden gestionar grandes conjuntos de datos y cargas de trabajo de producción. Te recomendamos que también implementar nodos de búsqueda dedicados para tu carga de trabajo de búsqueda. Esto le permite escalar su implementación de búsqueda de forma independiente y apropiada.
Proveedor de nube y región
Los nodos de búsqueda están disponibles en todas las regiones de Google Cloud, pero sólo están disponibles en un subconjunto de AWS y Azure regiones. Debe seleccionar un proveedor de nube y una región donde los Nodos de búsqueda estén disponibles para su implementación.
Todos los niveles de clúster están disponibles en las regiones admitidas del proveedor de nube. El proveedor de nube y la región que elijas afectan las opciones de configuración y los niveles de búsqueda disponibles para el clúster, así como el costo de ejecutarlo.
Arquitectura de nodo
Para entornos de producción, recomendamos una arquitectura de nodos en la que los procesos de MongoDB y los procesos de MongoDB Search se ejecuten en nodos separados. Para implementar nodos de búsqueda separados, consulta Migrar a nodos de búsqueda dedicados.
En el siguiente diagrama de este modelo de despliegue, el proceso MongoDB Search mongot se ejecuta en nodos de búsqueda dedicados, que están separados de los nodos del clúster en los que se ejecuta el proceso mongod.
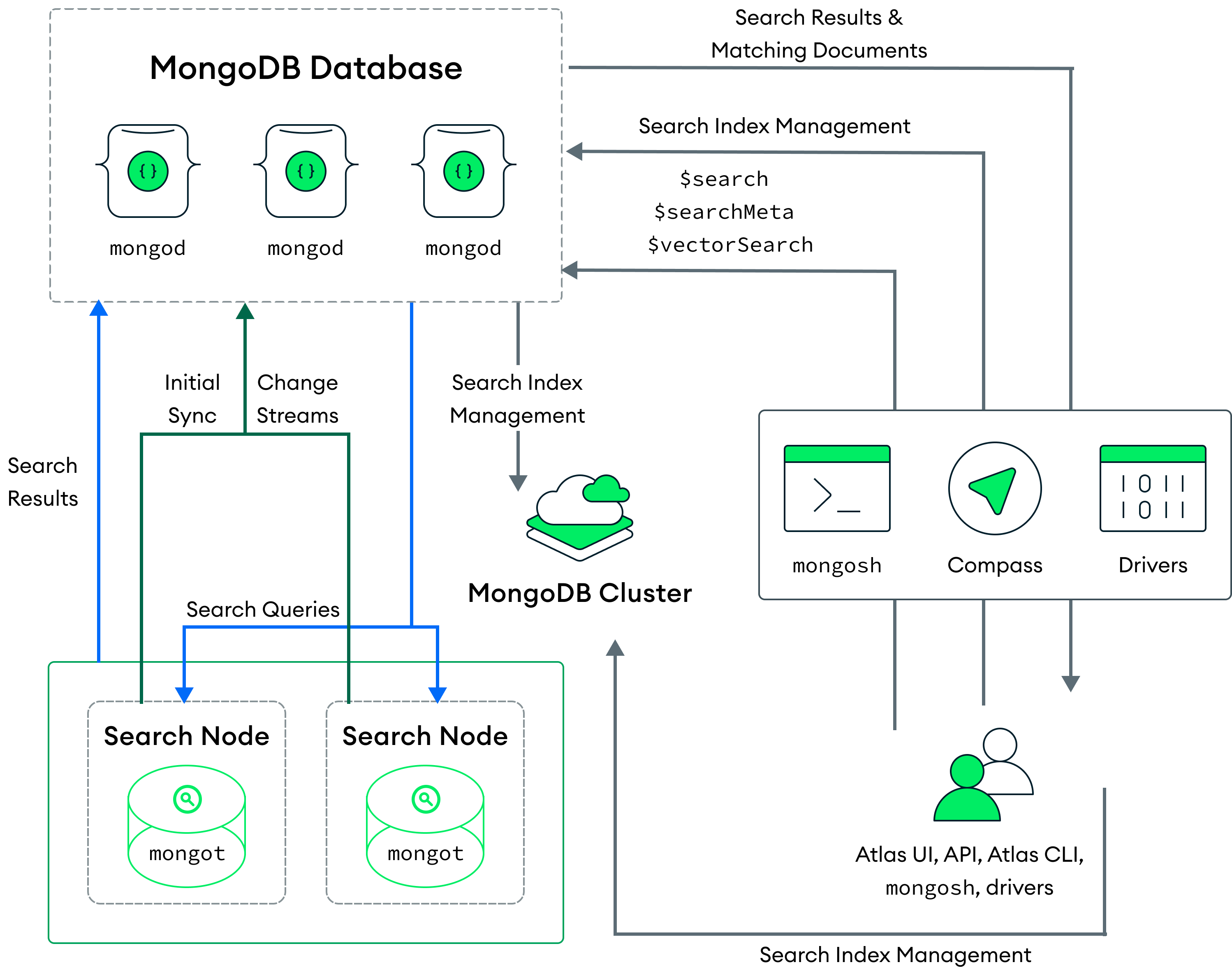
Atlas implementa nodos de búsqueda con cada clúster o con cada partición en el clúster. Por ejemplo, si implementas dos nodos de búsqueda para un clúster con tres particiones, Atlas implementa seis nodos de búsqueda (dos por partición). También puedes configurar el número de nodos de búsqueda y la cantidad de recursos aprovisionados para cada nodo de búsqueda.
Cuando despliegas nodos de búsqueda separados, Atlas asigna automáticamente un mongod para cada mongot para la indexación. El mongot se comunica con el mongod para escuchar y sincronizar cambios de índice en los índices que almacena. MongoDB Vector Search indexa y procesa tus queries de forma similar a una implementación en el que tanto los procesos mongod como mongot se ejecutan en el mismo nodo. Para obtener más información, consulta Cómo indexar campos para la búsqueda vectorial y Cómo ejecutar búsquedas vectoriales. Para aprender más sobre el despliegue de Nodos de búsqueda por separado, consulta Nodos de Búsqueda para Aislamiento de Cargas de Trabajo.
Cuando se migra a Search Nodes, Atlas implementa los Search Nodes, pero no sirve queries en los nodos hasta que se compila exitosamente todos los índices en el clúster en los Search Nodes. Mientras Atlas construye los índices en los nuevos nodos, continúa sirviendo queries usando los índices en los nodos del clúster. Atlas comienza a atender queries desde los nodos de búsqueda sólo después de compilar correctamente los índices en los nodos de búsqueda y remover los índices en los nodos del clúster.
Nota
El escalado de tu clúster mediante la adición de nodos de búsqueda o el cambio del nivel de búsqueda activa una reconstrucción del índice completo de MongoDB Search. Sin embargo, si tu cluster en AWS o Azure tiene nodos de búsqueda dedicados para los que no has habilitado Encriptación en reposo usando la gestión de claves del cliente, Atlas proporciona las siguientes optimizaciones:
Cuando escalas tus nodos de búsqueda, Atlas utiliza una copia reciente de tu índice en S3 o Azure Blob Storage en vez de reconstruir todo el índice de MongoDB Search en el nuevo nodo.
Para los nodos existentes, Atlas toma y carga periódicamente una nueva lista incremental de archivos de índice. Atlas conserva los archivos de índice durante un máximo de catorce (14) días.
Esto aún no está disponible para clústeres con nodos de búsqueda dedicados en Google Cloud.
Cuando ejecutas una query, esta se dirige a la mongod en base a la preferencia de lectura configurada. El proceso mongod enruta la consulta de búsqueda a través de un balanceador de carga en el mismo nodo, que distribuye las solicitudes a todos los procesos mongot.
El proceso MongoDB Search mongot realiza la búsqueda y la puntuación, y devuelve los IDs de los documentos y los metadatos de los resultados coincidentes a mongod. El mongod realiza entonces una búsqueda completa de documentos para obtener los resultados coincidentes y los devuelve al cliente. Si usas la opción $search concurrente en tu query, MongoDB Search habilita el paralelismo intra-query. Para obtener más información, consulte Ejecutar query en paralelo a través de segmentos.
Si eliminas todos los nodos de búsqueda de tu clúster, habrá una interrupción en el procesamiento de los resultados de tu consulta de búsqueda. Para obtener más información, consulta Modificar un clúster. Si borras tu clúster de Atlas, Atlas detendrá las implementaciones de MongoDB búsqueda vectorial asociadas (mongot procesos) y luego las borrará.
Beneficios
Este modelo de implementación aporta las siguientes ventajas:
Utiliza eficazmente tus recursos asegurando al mismo tiempo la alta disponibilidad de tus recursos para cargas de trabajo de búsqueda.
Ajuste el tamaño y **escalar** su **implementación** de búsqueda de forma independiente de su **implementación de la base de datos**.
Procese automáticamente las consultas de MongoDB Vector Search de manera concurrente, mejorando el tiempo de respuesta, especialmente en grandes conjuntos de datos. Para obtener más información, consulte Ejecución de query en paralelo entre segmentos.
Ajusta el tamaño de tus nodos de búsqueda para producción
MongoDB Vector Search mantiene todo el índice en memoria, por lo que necesitas asegurarte de que haya suficiente memoria para el índice de MongoDB Vector Search y para la JVM. Los nodos de búsqueda permiten el aislamiento de cargas de trabajo sin el aislamiento de datos, y casi el 90% de su asignación de RAM se puede usar para almacenar los datos de vectores e índices en la memoria, y lo que queda se puede usar para la JVM.
Cada índice es una combinación de los vectores a los que se les asigna un índice y metadatos adicionales. El tamaño del índice se determina principalmente por el tamaño de los vectores para los que estás realizando la indexación, siendo el espacio de metadatos típicamente relativamente nominal. Para obtener más información, consulte Requisitos de memoria para la indexación de vectores.
Cuando implemente nodos de búsqueda dedicados, podrá elegir entre varios niveles de búsqueda. Cada nivel de búsqueda tiene una capacidad de RAM, capacidad de almacenamiento y unidad central de procesamiento (CPU) por defecto. Esto te permite dimensionar y escalar tu clúster de forma independiente a tu implementación de la base de datos. Para escalar su implementación de búsqueda de manera independiente, puede realizar los siguientes cambios en la configuración de su clúster en cualquier momento:
Ajusta el número de nodos de búsqueda en tu clúster.
Ajusta la CPU, la RAM y el almacenamiento del nodo cambiando los niveles de búsqueda.
Nota
Para aprender más sobre el costo de los nodos de búsqueda y los niveles de búsqueda, expanda View all plan features y haga clic en MongoDB Vector Search en la página de Precios de MongoDB.
Recomendamos que tu nodo tenga una memoria RAM al menos 10% mayor que el tamaño total de tus índices de MongoDB Vector Search. También recomendamos que se asegure de tener suficientes CPUs disponibles. La latencia de la query depende del número de CPU disponibles, lo que puede afectar significativamente el nivel de concurrencia interna que acelera el rendimiento de la query.
Ejemplo
Supongamos que tienes 1M de vectores de 768 dimensiones de aproximadamente 3GB de tamaño. Tanto los niveles de búsqueda S30 (baja CPU) como S20 (alta CPU) tienen suficiente RAM para soportar el índice. En lugar de implementarse en el nivel de búsqueda S30 (Bajo procesador), recomendamos implementarse en el nivel de búsqueda S20 (Alto procesador) porque el nivel de búsqueda S20 (Alto procesador) tiene más procesadores disponibles para ejecutar consultas simultáneamente.
Activar el cifrado en reposo
Por defecto, MongoDB y los procesos de búsqueda se ejecutan en los mismos nodos. Con esta arquitectura, el cifrado gestionado por el cliente se aplica a los datos de tu base de datos, pero no se aplica a los índices de búsqueda.
Cuando se habilita nodos de búsqueda dedicados, los procesos de búsqueda se ejecutan en nodos separados. Esto te permite activar Cifrado de datos de nodo de búsqueda, así puedes cifrar tanto los datos de la base de datos como los índices de búsqueda con las mismas claves gestionadas por el cliente para una cobertura de cifrado integral.
Nota
Los nodos de la base de datos y los nodos de búsqueda utilizan diferentes métodos de cifrado con las mismas claves gestionadas por el cliente. Los nodos de la base de datos usan el motor de almacenamiento cifrado WiredTiger, mientras que los nodos de búsqueda usan cifrado a nivel de disco.
Para obtener más información, consulta Permitir la gestión de claves de cliente para los nodos de búsqueda.
Importante
Esta característica está disponible en todos los proveedores de KMS, pero los Nodos de búsqueda deben estar en AWS.
Migre a nodos de búsqueda dedicados
Los nodos de búsqueda dedicados permiten dimensionar y escalar su implementación de búsqueda por separado de su clúster. También elimina cualquier conflicto de recursos que pueda experimentar en un clúster que ejecute tanto la base de datos como los procesos de búsqueda en el mismo nodo.
Para migrar a Nodos de Búsqueda dedicados, realiza los siguientes cambios en tu implementación:
Si tu implementación está utilizando actualmente un clúster de nivel gratuito o un clúster Flex, actualiza tu clúster a un nivel superior. Los Nodos de Búsqueda Dedicados sólo son compatibles con
M10y niveles de clúster superiores. Para obtener más información sobre cómo migrar a un nivel de clúster diferente, consulte Modifique el nivel de clúster.Los nodos de búsqueda dedicada están disponibles en un subconjunto de las regiones AWS y Azure, y en todas las regiones de Google Cloud soportadas. Asegúrese de implementar su clúster en regiones donde los nodos de Búsqueda también estén disponibles. Si tu clúster existente está en regiones donde los Nodos de búsqueda no están disponibles, migra tu clúster a regiones donde los Nodos de búsqueda estén disponibles. Para obtener más información, consulte Región de proveedor de nube.
Habilita Search Nodes for workload isolation y configura nodos de búsqueda. Para obtener más información, consulta Agregar nodos de búsqueda.