$rankFusion y $scoreFusion etapas están disponibles como funcionalidades de vista previa. Para obtener más información, consulte Funcionalidades de Previsualización.Importante
$rankFusion solo está disponible para implementaciones que utilizan MongoDB 8.0 o superior.
Definición
$rankFusion$rankFusionPrimero ejecuta todas las canalizaciones de entrada de forma independiente y luego desduplica y combina los resultados de las canalizaciones de entrada en un conjunto de resultados clasificados finales.$rankFusiongenera un conjunto clasificado de documentos en función de los rangos en que aparecen los documentos de entrada en sus pipelines de entrada y los pesos de los pipelines. Esta etapa utiliza el algoritmo de Fusión de Ranking Recíproco para clasificar los resultados combinados de los pipelines de entrada.Utiliza
$rankFusionpara buscar documentos en una sola colección basándose en múltiples criterios y recuperar un conjunto de resultados finales clasificados que tiene en cuenta todos los criterios especificados.
Sintaxis
La etapa tiene la siguiente sintaxis:
{ $rankFusion: { input: { pipelines: { <myPipeline1>: <expression>, <myPipeline2>: <expression>, ... } }, combination: { weights: { <myPipeline1>: <numeric expression>, <myPipeline2>: <numeric expression>, ... } }, scoreDetails: <bool> } }
Campos de comandos
$rankFusion requiere los siguientes campos:
Campo | Tipo | Descripción |
|---|---|---|
| Objeto | Define la entrada que clasifica |
input.pipelines | Objeto | Contiene un mapa de nombres de pipelines a las etapas de agregación que definen ese pipeline. Para obtener más información sobre las restricciones de la canalización de entrada, consulte Canalizaciones de entrada y nombres de canalizaciones de entrada. |
| Objeto | Opcional. Define cómo combinar los resultados del pipeline |
combination.weights | Objeto | opcional. Contiene un mapa desde Si no especifica un peso, el valor predeterminado es 1. |
| Booleano | El valor predeterminado es falso. Especifica si |
Comportamiento
Colecciones
Solo puedes usar $rankFusion con una única colección. No puedes usar esta etapa de agregación en el ámbito de la base de datos.
De-Duplication
$rankFusion Desduplica los resultados de múltiples canales de entrada en la salida final. Cada documento de entrada único aparece como máximo una vez en la salida $rankFusion, independientemente del número de veces que aparezca en las salidas del canal de entrada.
Tuberías de entrada
Cada input pipeline debe ser tanto un pipeline de selección como un pipeline de clasificación.
Selección pipeline
Una pipeline de selección recupera un conjunto de documentos de una colección sin realizar ninguna modificación después de la recuperación. $rankFusion compara documentos a través de diferentes pipelines de entrada, lo que requiere que todas las pipelines de entrada produzcan los mismos documentos sin modificar.
Nota
Si deseas modificar los documentos que buscas con $rankFusion, realiza esas modificaciones después de la etapa $rankFusion.
Una pipeline de selección debe contener únicamente las siguientes etapas:
Tipo | Etapas |
|---|---|
Etapas de búsqueda |
Si usas |
Etapas de ordenamiento | |
Etapas de paginación |
Pipeline clasificado
Una canalización clasificada ordena los documentos. $rankFusion utiliza el orden de los resultados de la canalización clasificada para influir en la clasificación de los resultados. Las canalizaciones clasificadas deben cumplir uno de los siguientes criterios:
Comienza con una de las siguientes etapas ordenadas:
Contenga una etapa explícita de
$sort.
Nombres de canalizaciones de entrada
Los nombres de las pipeline en input deben cumplir con las siguientes restricciones:
No debe ser una cadena vacía
No debe comenzar con una
$No debe contener el delimitador de carácter nulo ASCII
\0en ninguna parte de la cadenaNo debe contener una
.
Fórmula de fusión de rangos recíprocos (RRF)
$rankFusion Los resultados se ordenan según la Fórmula de Fusión de Rangos Recíprocos (RRF). Esta etapa coloca la puntuación RRF de cada documento en el campo de metadatos score de los resultados. La fórmula RRF clasifica los documentos mediante una combinación de los siguientes factores:
La ubicación de documentos en los resultados de la pipeline de entrada
La cantidad de veces que un documento aparece en diferentes canales de entrada
El
weightsde los pipelines de entrada.
Por ejemplo, si un documento tiene una alta clasificación en múltiples conjuntos de resultados de la pipeline, la puntuación RRF para ese documento sería más alta que si ese mismo documento tiene la misma clasificación en algunas pipelines de entrada, pero no está presente (o tiene una clasificación más baja) en las otras pipelines
La Fórmula de Fusión de Rango Recíproco (RRF) es equivalente a la siguiente operación algebraica:

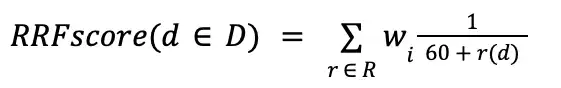
Nota
En esta fórmula, 60 es un parámetro de sensibilidad que MongoDB determinó.
La siguiente tabla contiene las variables que utiliza la fórmula RRF:
Variable | Descripción |
|---|---|
D | El conjunto de documentos de resultados de toda la operación. |
d | El documento para el que se está calculando la puntuación RRF. |
R | El conjunto de rangos para las canalizaciones de entrada en las que aparece |
r(d) | El rango del documento |
w | El peso de la tubería de entrada en la que aparece |
Cada término en la suma representa la aparición de un documento d en uno de los input pipelines. La puntuación total RRF para d es la suma de cada uno de estos términos en todos los pipelines de entrada en los que aparece d.
Ejemplo de cálculo de RRF
Considera una etapa de la pipeline $rankFusion con una pipeline de entrada de $search y una de $vectorSearch.
Todas los pipelines de entrada producen los mismos 3 documentos: Document1, Document2 y Document3.
La $search pipeline clasifica los documentos en el siguiente orden:
Document3Document2Document1
La $vectorSearch pipeline clasifica los documentos en el siguiente orden:
Document1Document2Document3.
rankFusion calcula la puntuación RRF para Document1 mediante la siguiente operación:
RRFscore(Document1) = 1/(60 + search_rank_of_Document1) + (1/(60 + vectorSearch_rank_of_Document1)) RRFscore(Document1) = 1/63 + 1/61 RRFscore(Document1) = 0.0322664585
El campo de metadatos score para Document1 es 0.0322664585.
scoreDetails
Si estableces scoreDetails en true, $rankFusion crea un campo de metadatos scoreDetails para cada documento. El campo scoreDetails contiene información sobre la clasificación final.
Nota
Cuando se establece scoreDetails en true, $rankFusion establece el campo de metadatos scoreDetails para cada documento, pero no genera automáticamente el metacampo scoreDetails.
Para ver el campo de metadatos scoreDetails, debe:
usa una etapa
$projectdespués de$rankFusionpara proyectar el camposcoreDetailsusa una etapa
$addFieldsdespués de$rankFusionpara agregar el camposcoreDetailsa la salida del pipeline
El campo scoreDetails contiene los siguientes subcampos:
Campo | Descripción |
|---|---|
| El valor numérico del PuntuaciónRRF para este documento. |
| Una descripción de cómo |
| Un arreglo en el que cada entrada contiene información sobre las pipelines de entrada que generan este documento. |
Cada entrada de arreglo en el campo details contiene los siguientes subcampos:
Campo | Descripción |
|---|---|
| El nombre de la pipeline de entrada que generó este documento. |
| El rango de este documento en la pipeline de entrada. El rango es |
| El peso de la pipeline de entrada. |
| Opcional. Si la canalización de entrada genera un |
| opcional. Si la pipeline de entrada da salida a un campo |
| El campo |
Advertencia
MongoDB no garantiza ningún formato de salida específico para scoreDetails.
Por ejemplo, los siguientes bloques de código muestran el campo scoreDetails para una operación $rankFusion con los pipelines de entrada $search, $vectorSearch y $match:
{ value: 0.030621785881252923, description: "value output by reciprocal rank fusion algorithm, computed as sum of weight * (1 / (60 + rank)) across input pipelines from which this document is output, from:" details: [ { inputPipelineName: 'search', rank: 2, weight: 1, value: 0.3876491287, description: "sum of:", details: [... omitted for brevity in this example ...] }, { inputPipelineName: 'vector', rank: 9, weight: 3, value: 0.7793490886688232, details: [ ] }, { inputPipelineName: 'match', rank: 10, weight: 1, details: [] } ] }
Explique los resultados
MongoDB convierte las operaciones $rankFusion en un conjunto de etapas de agregación existentes que, en combinación, computan el resultado de salida antes de la ejecución de la query. La Explicación de resultados para una operación $rankFusion muestran la ejecución completa de las etapas de agregación subyacentes que $rankFusion utiliza para componer el resultado final.
Ejemplos
Este ejemplo utiliza una colección con incrustaciones y campos de texto. Cree índices de tipo search y vectorSearch en la colección.
La siguiente definición de índice indexa automáticamente todos los campos indexables dinámicamente en la colección para ejecutar consultas contra los campos $search indexados.
db.embedded_movies.createSearchIndex( "search_index", { mappings: { dynamic: true } } )
La siguiente definición de índice indexa el campo con las incrustaciones en la colección para ejecutar consultas de $vectorSearch query contra ese campo.
db.embedded_movies.createSearchIndex( "vector_index", "vectorSearch", { "fields": [ { "type": "vector", "path": "<FIELD_NAME>", "numDimensions": <NUMBER_OF_DIMENSIONS>, "similarity": "dotProduct" } ] } );
El siguiente pipeline de agregación usa $rankFusion con los siguientes pipelines de entrada:
pipeline | Número de Documentos Devueltos | Descripción |
|---|---|---|
| 20 | Ejecuta una búsqueda vectorial en el campo indexado como tipo |
| 20 | Ejecuta una búsqueda de texto completo para el mismo término y limita los resultados a 20 documentos. |
1 db.embedded_movies.aggregate( [ 2 { 3 $rankFusion: { 4 input: { 5 pipelines: { 6 searchOne: [ 7 { 8 "$vectorSearch": { 9 "index": "<INDEX_NAME>", 10 "path": "<FIELD_NAME>", 11 "queryVector": <QUERY_EMBEDDINGS>, 12 "numCandidates": 500, 13 "limit": 20 14 } 15 } 16 ], 17 searchTwo: [ 18 { 19 "$search": { 20 "index": "<INDEX_NAME>", 21 "text": { 22 "query": "<QUERY_TERM>", 23 "path": "<FIELD_NAME>" 24 } 25 } 26 }, 27 { "$limit": 20 } 28 ], 29 } 30 } 31 } 32 }, 33 { $limit: 20 } 34 ] )
Esta operación realiza las siguientes acciones:
Ejecuta las
inputpipelinesCombina los resultados devueltos
Muestra los primeros 20 documentos que son los primeros 20 resultados clasificados del pipeline
$rankFusion
Los ejemplos de Node.js en esta página utilizan la base de datos sample_mflix de los conjuntos de datos de muestra de Atlas. Para aprender a crear un clúster gratuito de MongoDB Atlas y cargar los conjuntos de datos de muestra, consulte Primeros pasos en la documentación del controlador de MongoDB Node.js.
Para utilizar el controlador de MongoDB Node.js para agregar una etapa de $rankFusion a una canalización de agregación, utilice el Operador $rankFusion en un objeto de canalización.
Antes de ejecutar el siguiente ejemplo, debes crear un índice de búsqueda de Atlas llamado default. Incluye el siguiente código en tu aplicación para crear un índice de búsqueda en la colección movies:
const index = { name: "default", definition: { mappings: { dynamic: true } } } const result = collection.createSearchIndex(index);
El siguiente ejemplo crea una etapa en la canalización que ejecuta dos pipelines, searchPlot y searchGenre, que realizan operaciones de $search usando el índice de búsqueda default. La etapa $rankFusion clasifica luego los resultados de búsqueda en base al peso asignado a cada pipeline $search y devuelve los resultados ordenados. La etapa $addFields incluye el campo scoreDetails en los documentos devueltos. El ejemplo luego ejecuta la canalización de agregación:
const pipeline = [ { $rankFusion: { input: { pipelines: { searchPlot: [ { $search: { index: "default", text: { query: "space", path: "plot"} } } ], searchGenre: [ { $search: { index: "default", text: { query: "adventure", path: "genres" } } } ] } }, combination: { weights: {searchPlot: 0.6, searchGenre: 0.4} }, scoreDetails: true } }, { $addFields: { scoreDetails: { $meta: "searchScoreDetails" } } } ]; const cursor = collection.aggregate(pipeline); return cursor;