MongoDB Data Federation Setup


Ken W. Alger, Anaiya Raisinghani5 min read • Published Feb 07, 2022 • Updated Jan 23, 2024





Rate this tutorial


As an avid traveler, you have a love for staying at Airbnbs and have been keeping detailed notes about each one you’ve stayed in over the years. These notes are spread out across different storage locations, like MongoDB Atlas and AWS S3, making it a challenge to search for a specific Airbnb with the amenities your girlfriend desires for your upcoming Valentine’s Day trip. Luckily, there is a solution to make this process a lot easier. By using MongoDB’s Data Federation feature, you can combine all your data into one logical view and easily search for the perfect Airbnb without having to worry about where the data is stored. This way, you can make your Valentine’s Day trip perfect without wasting time searching through different databases and storage locations.
Don’t know how to utilize MongoDB’s Data Federation feature? This tutorial will guide you through exactly how to combine your Airbnb data together for easier query-ability.
Before we jump in, there are a few necessities we need to have in order to be on the same page. This tutorial requires:
- MongoDB Atlas.
- An Amazon Web Services (AWS) account.
- Access to the AWS Management Console.
- AWS CLI.
- MongoDB Compass.
Our first step is to import our Airbnb data into our Atlas cluster and our S3 bucket, so we have data to work with throughout this tutorial. Make sure to import the dataset into both of these storage locations.
Step 2: Once your cluster is set up, click the three ellipses and click “Load Sample Dataset."
Step 3: Once you get this green message you’ll know your sample dataset (Airbnb notes) is properly loaded into your cluster.

Step 1: We will be using this sample data set. Please download it locally. It contains the sample data we are working with along with the S3 bucket structure necessary for this demo.
Step 2: Once the data set is downloaded, access your AWS Management Console and navigate to their S3 service.
Step 3: Hit the button “Create Bucket” and follow the instructions to create your bucket and upload the sampledata.zip.
Step 4: Make sure to unzip your file before uploading the folders into S3.
Step 5: Once your data is loaded into the bucket, you will see several folders, each with varying data types.
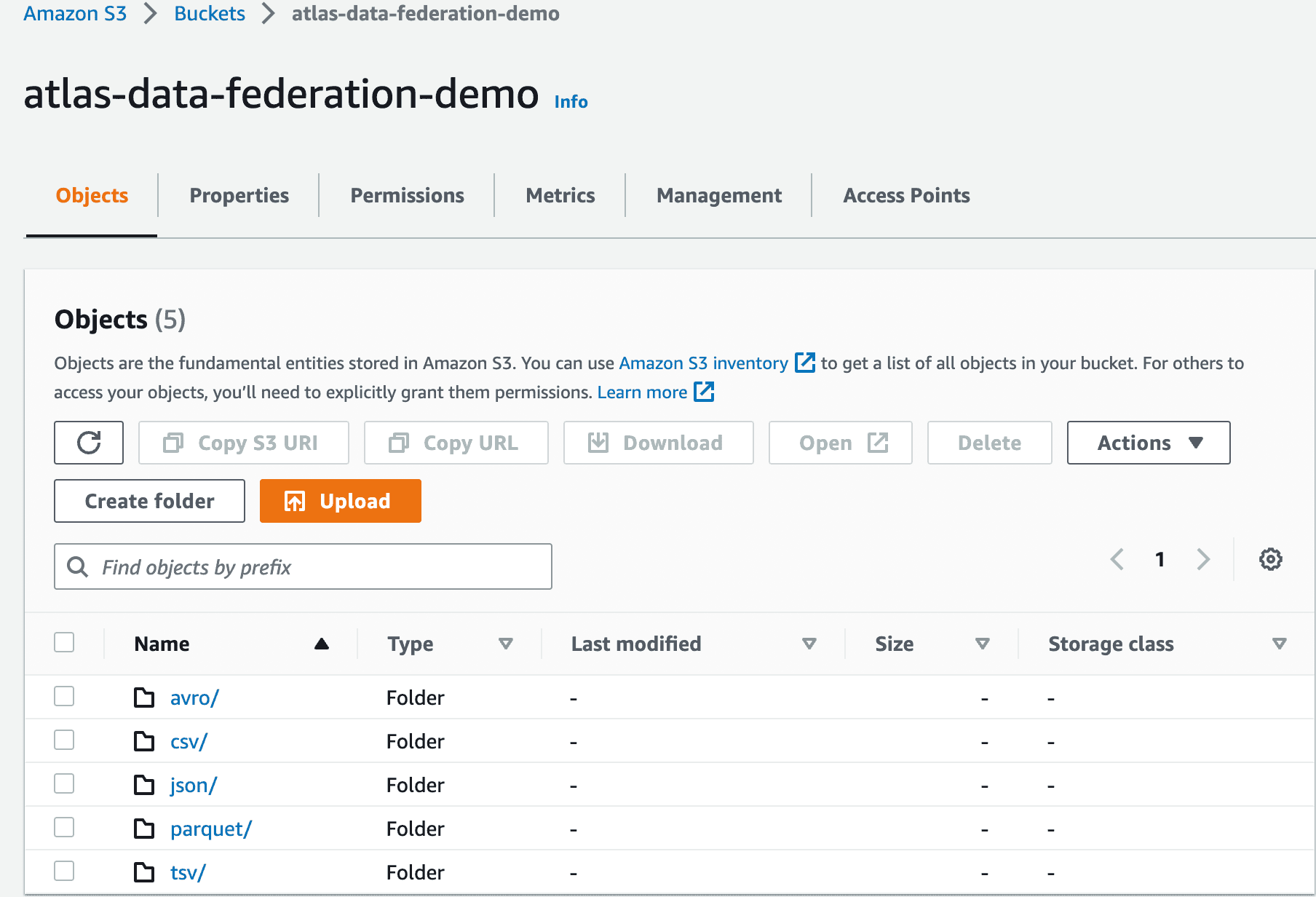
Step 6: Follow the path: Amazon S3 > Buckets > atlas-data-federation-demo > json/ > airbnb/ to view your Airbnb notes. Your bucket structure should look like this:

Congratulations! You have successfully uploaded your extensive Airbnb notes in not one but two storage locations. Now, let’s see how to retrieve this information in one location using Data Federation so we can find the perfect Airbnb. In order to do so, we need to get comfortable with the MongoDB Atlas Data Federation console.
Inside the MongoDB Atlas console, on the left side, click on Data Federation.
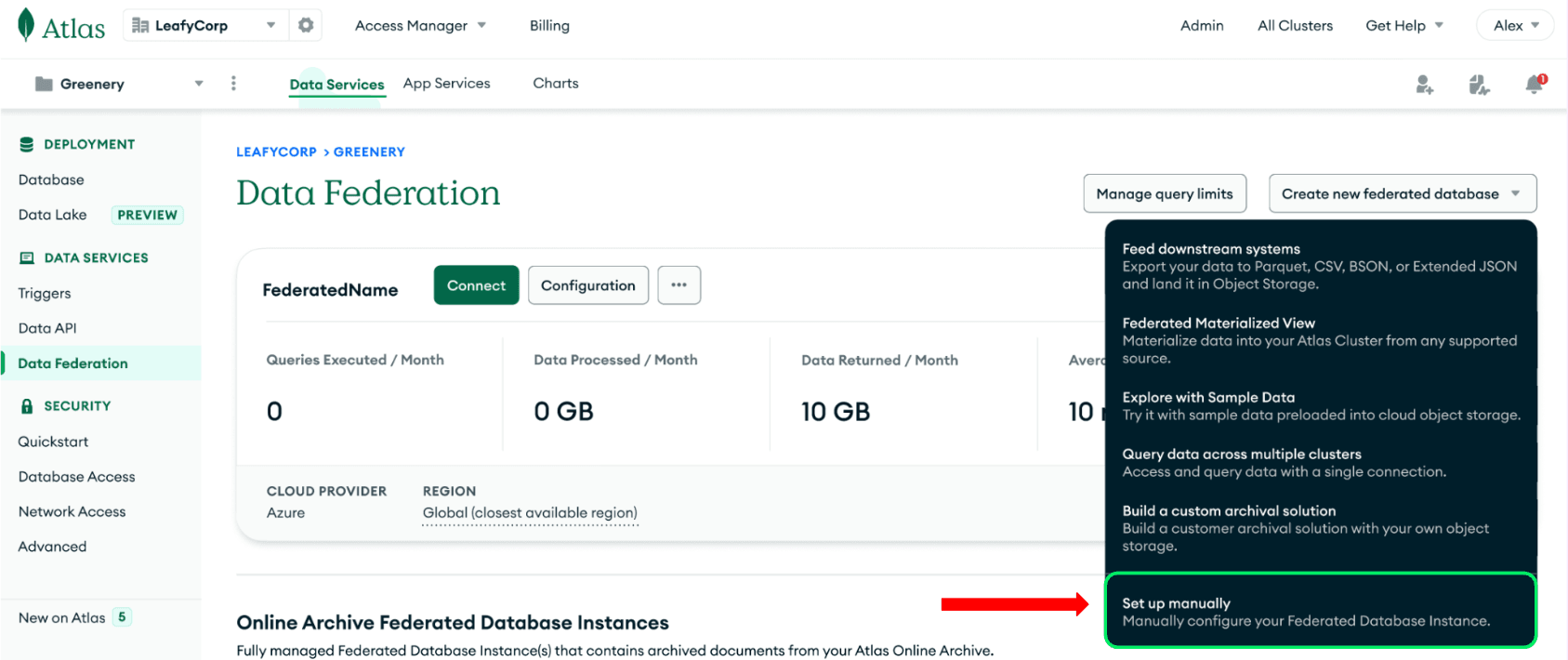
Here, click “set up manually” in the "create new federated database" dropdown in the top right corner of the UI. This will lead us to a page where we can add in our data sources. You can rename your Federated Database Instance to anything you like. Once you save it, you will not be able to change the name.

Let’s add in our data sources from our cluster and our bucket!
Step 1: Click on “Add Data Source.”
Step 2: Select the “Amazon S3” button and hit “Next.”
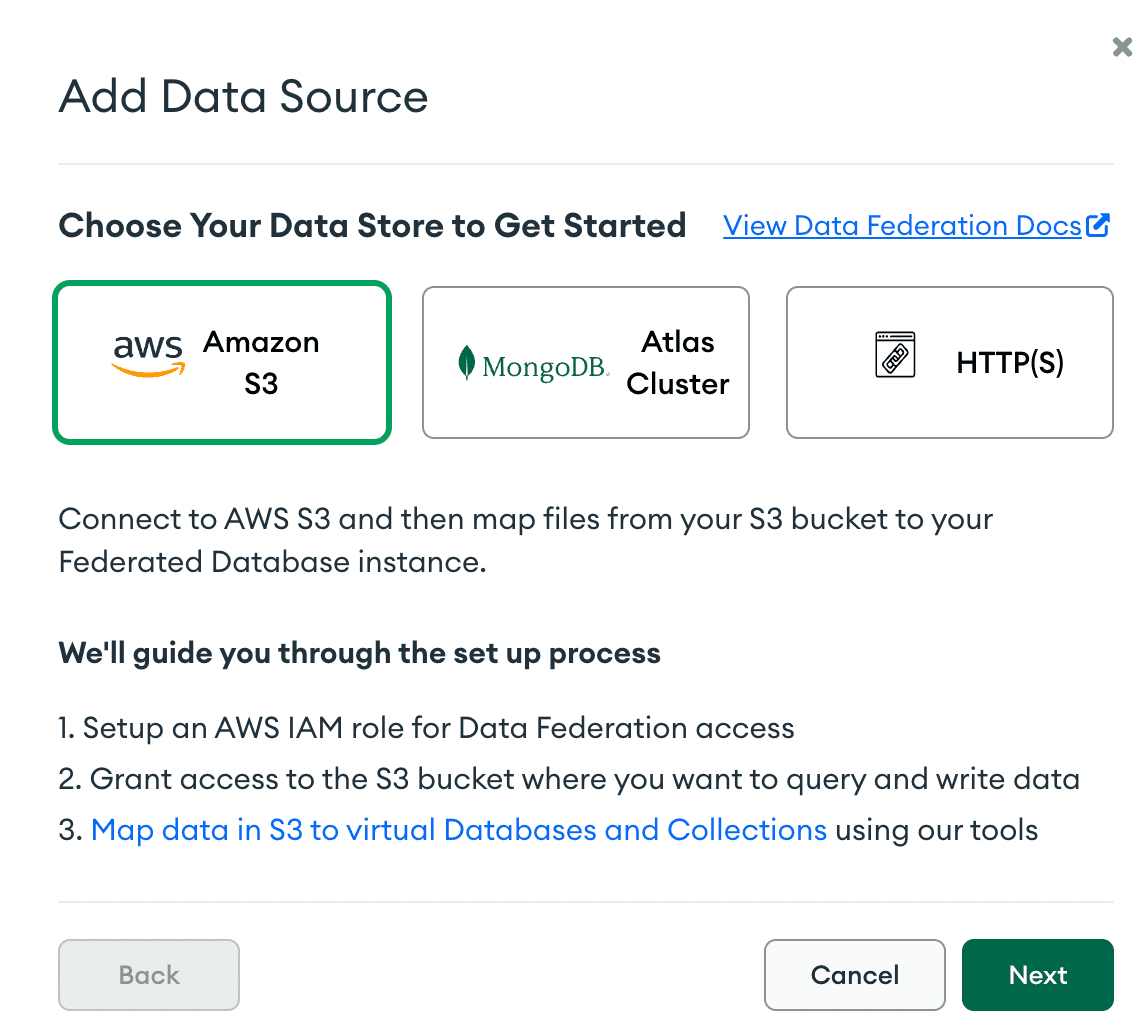
Step 3: From here, click Next on the “Authorize an AWS IAM Role”:
Step 4: Click on “Create New Role in the AWS CLI”:

Step 5: Now, you’re going to want to make sure you have AWS CLI configured on your laptop.
Step 6: Follow the steps below the “Create New Role with the AWS CLI” in your AWS CLI.

Step 7: You can find your “ARN” directly in your terminal. Copy that in — it should look like this:
Step 8: Enter the bucket name containing your Airbnb notes:
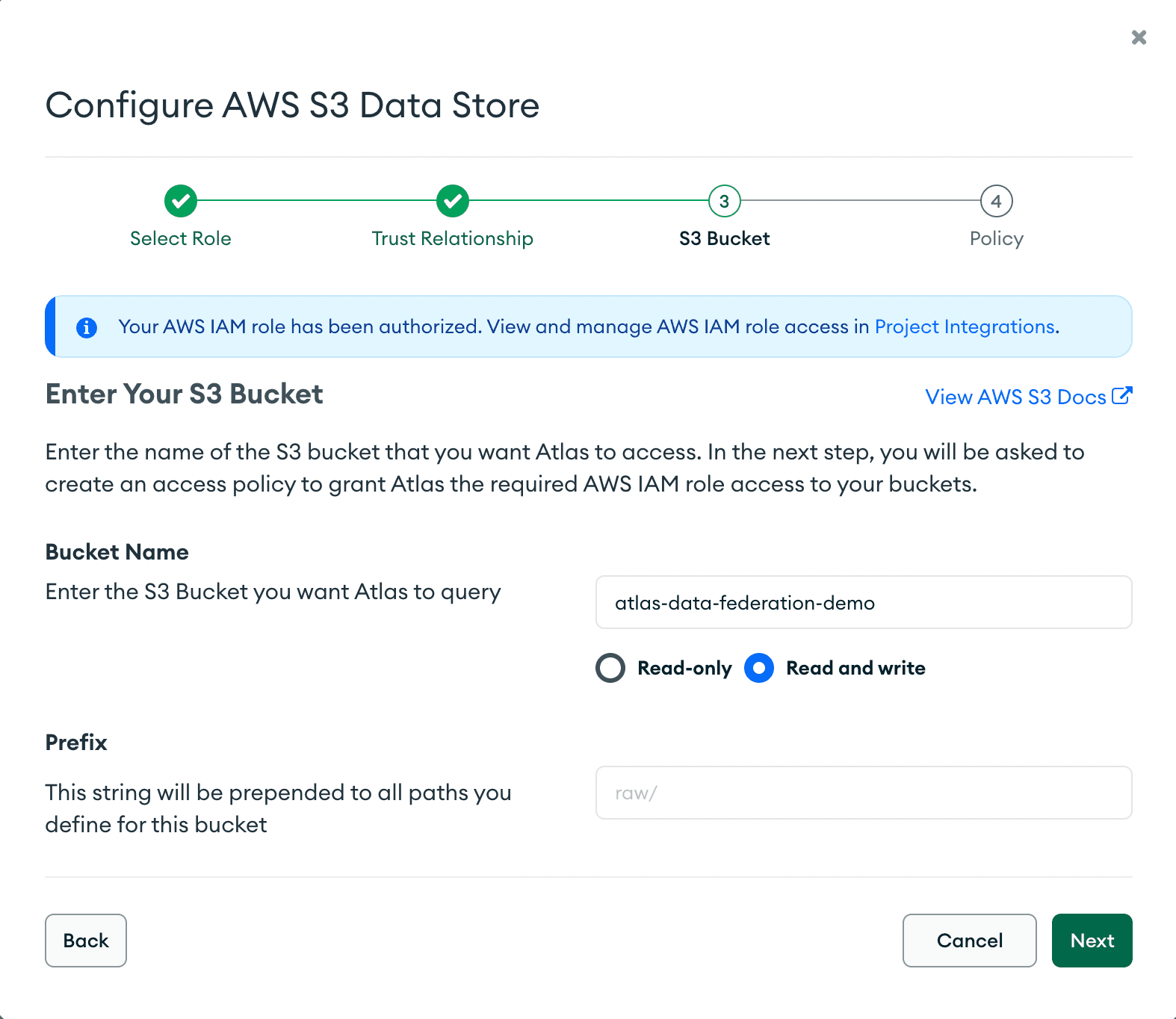
Step 9: Follow the instructions in Atlas and save your policy role.
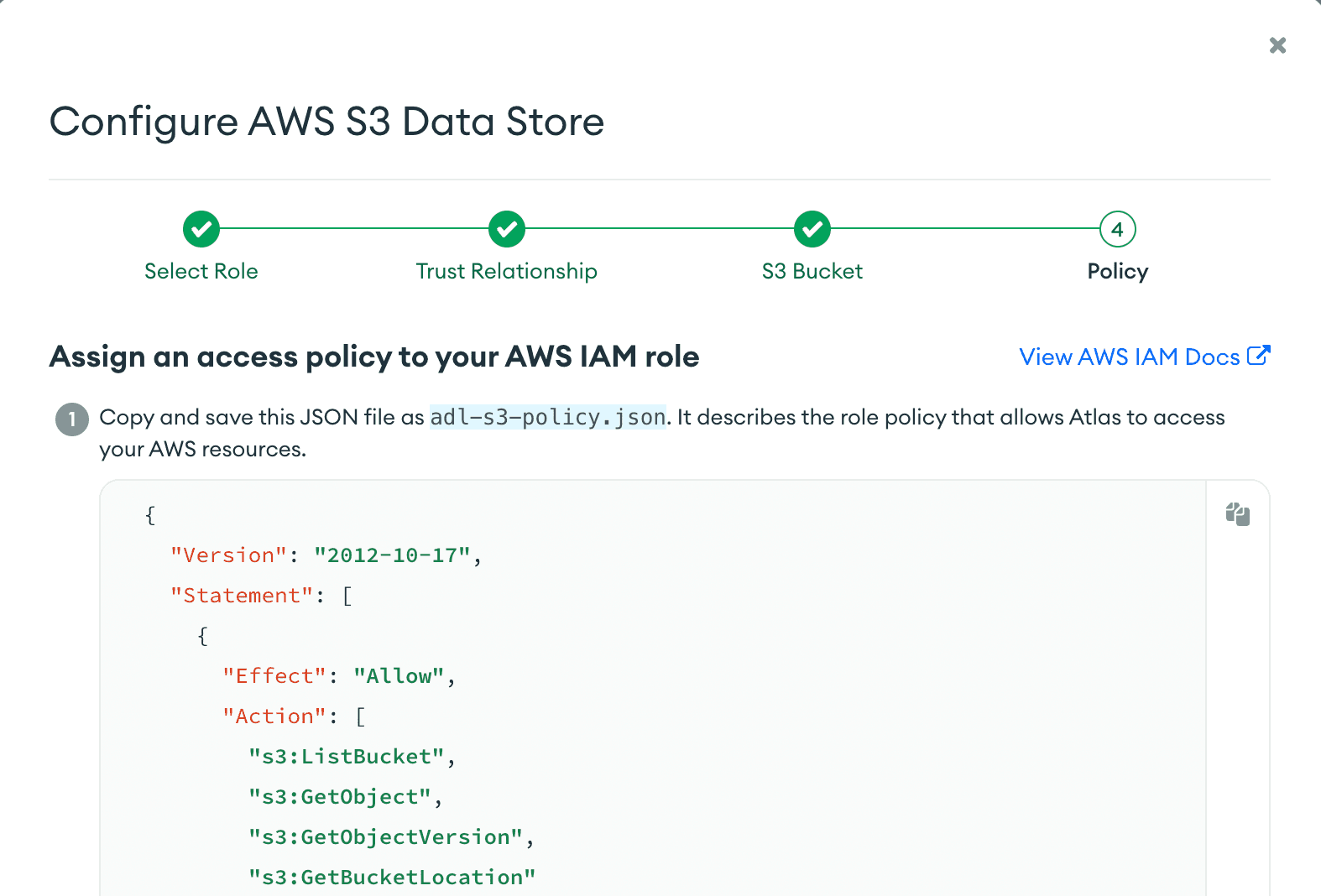
Step 10: Copy the CLI commands listed on the screen and paste them into your terminal like so:
Step 11: Access your AWS Console, locate your listingsAndReviews.json file located in your S3 bucket, and copy the S3 URI.
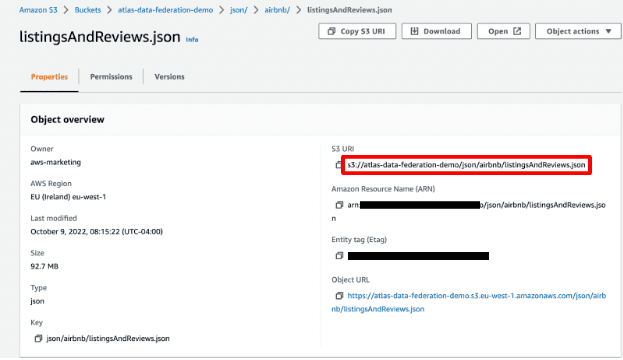
Step 12: Enter it back into your “Define ‘Data Sources’ Using Paths Inside Your S3” screen and change each step of the tree to “static.”
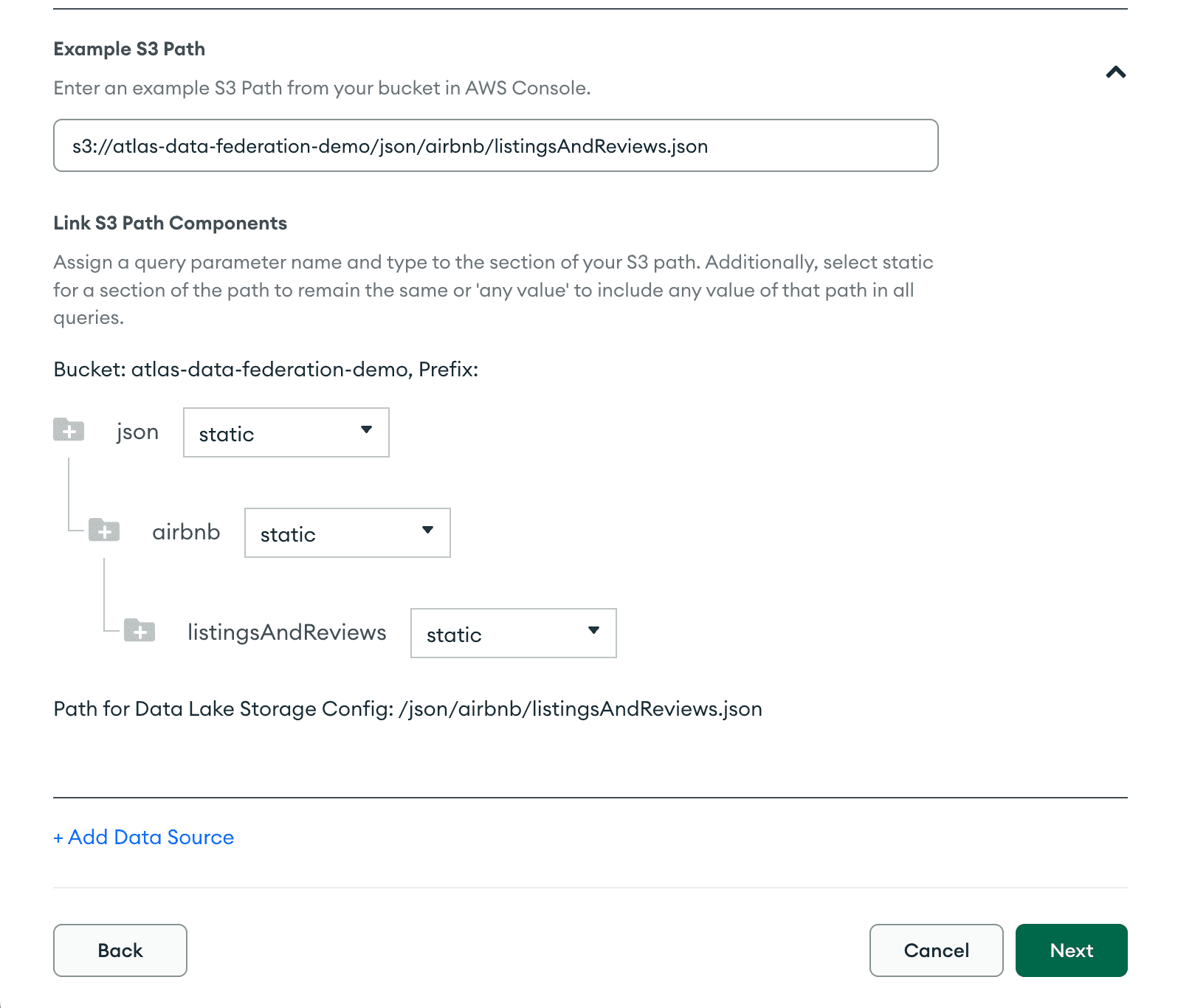
Step 13: Drag your file from the left side of the screen to the middle where it says, “Drag the dataset to your Federated Database.” Following these steps correctly will result in a page similar to the screenshot below.

You have successfully added in your Airbnb notes from your S3 bucket. Nice job. Let's do the same thing for the notes saved in our Atlas cluster.
Step 1: Click “Add Data Sources.”
Step 2: Select “MongoDB Atlas Cluster” and provide the cluster name along with our sample_airbnb collection. These are your Atlas Airbnb notes.

Step 3: Click “Next” and your sample_airbnb.listingsAndReviews will appear in the left-hand side of the console.
Step 4: Drag it directly under your Airbnb notes from your S3 bucket and hit “Save.” Your console should look like this when done:
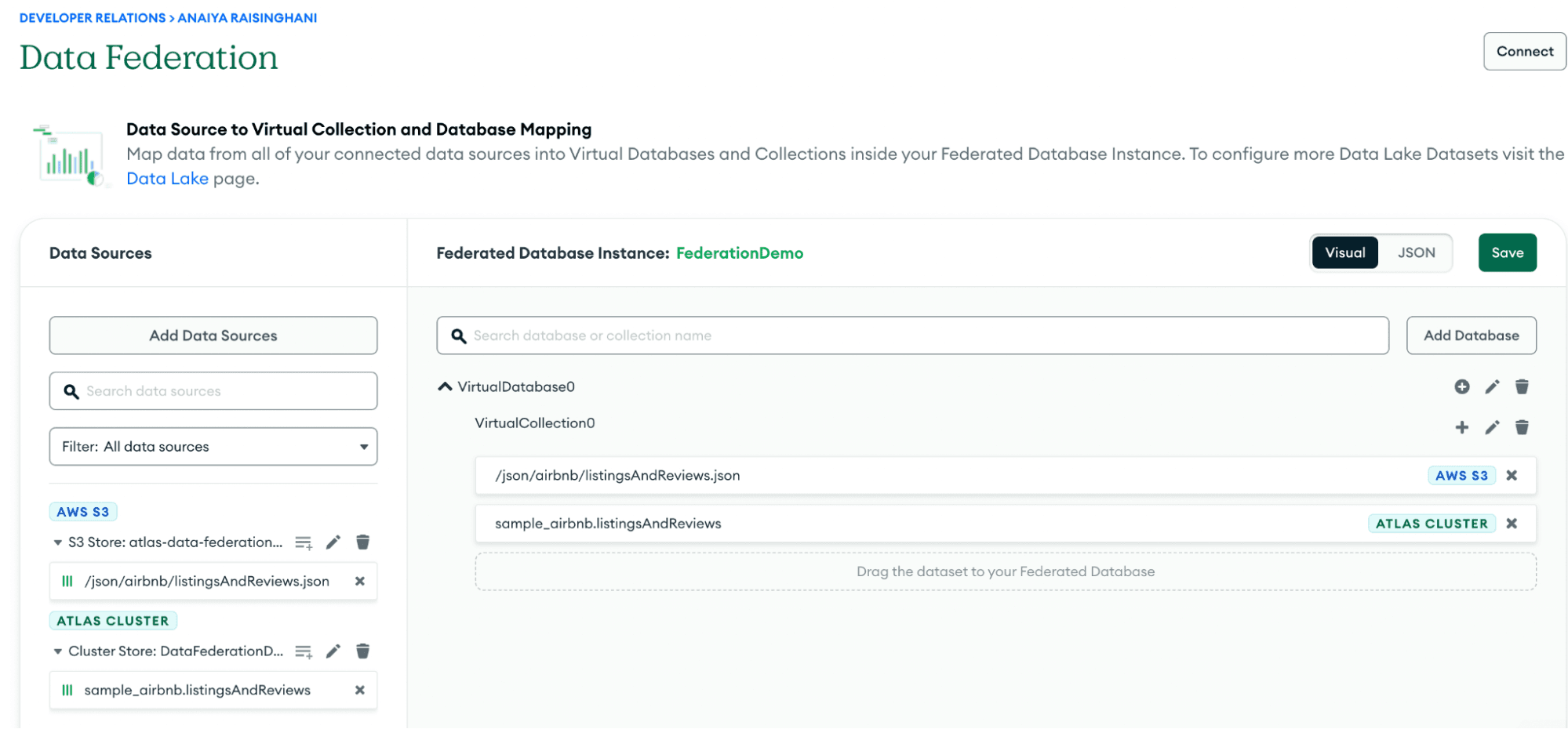
Great job. You have successfully imported your Airbnb notes from both your S3 bucket and your Atlas cluster into one location. Let’s connect to our Federated Database and see our data combined in one easily query-able location.
We are going to connect to our Federated Database using MongoDB Compass.
Step 1: Click the green “Connect” button and then select “Connect using MongoDB Compass.”
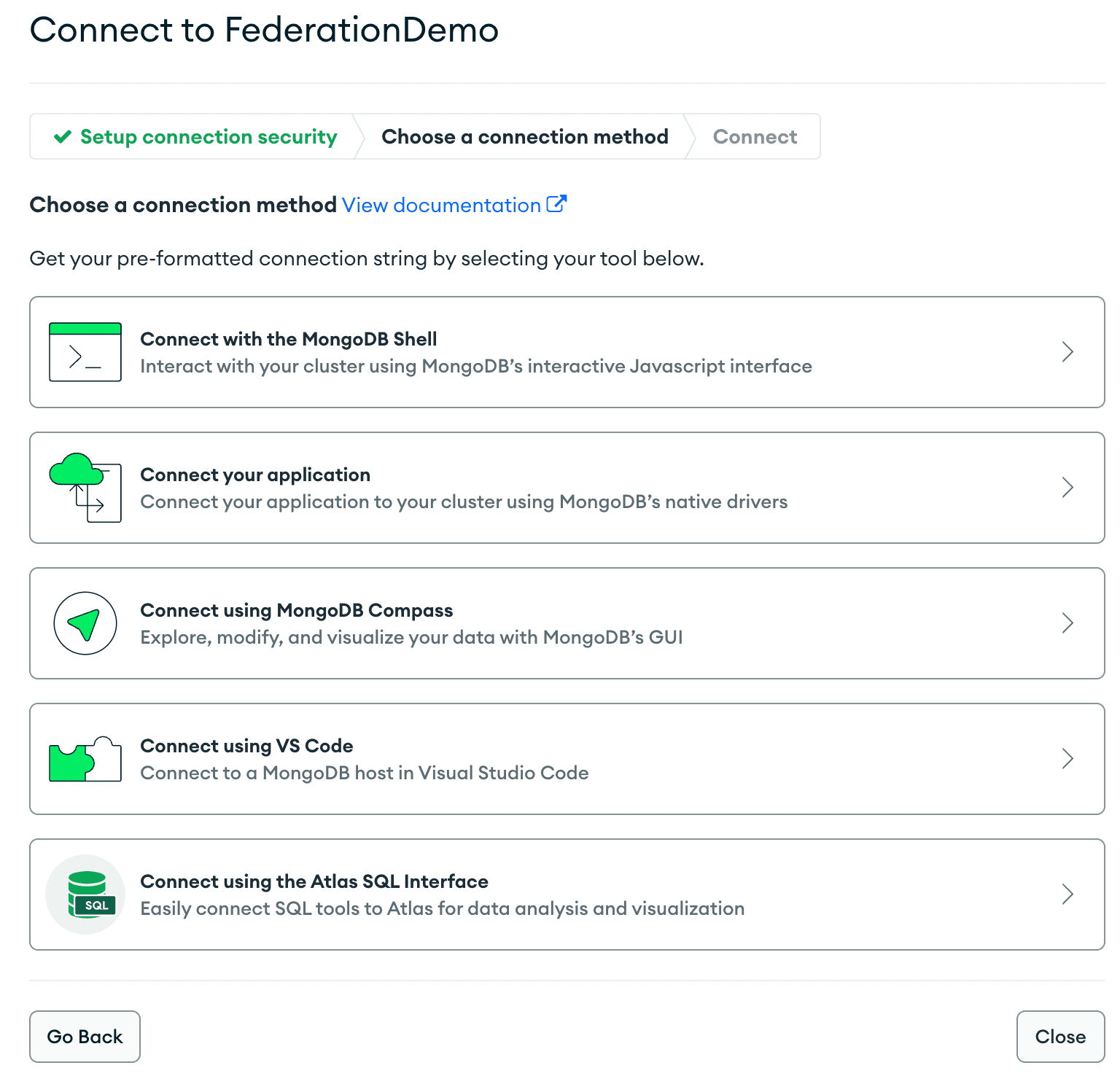
Step 2: Copy in the connection string, making sure to switch out the user and password for your own. This user must have admin access in order to access the data.
Step 3: Once you’re connected to Compass, click on “VirtualDatabase0” and once more on “VirtualCollection0.”
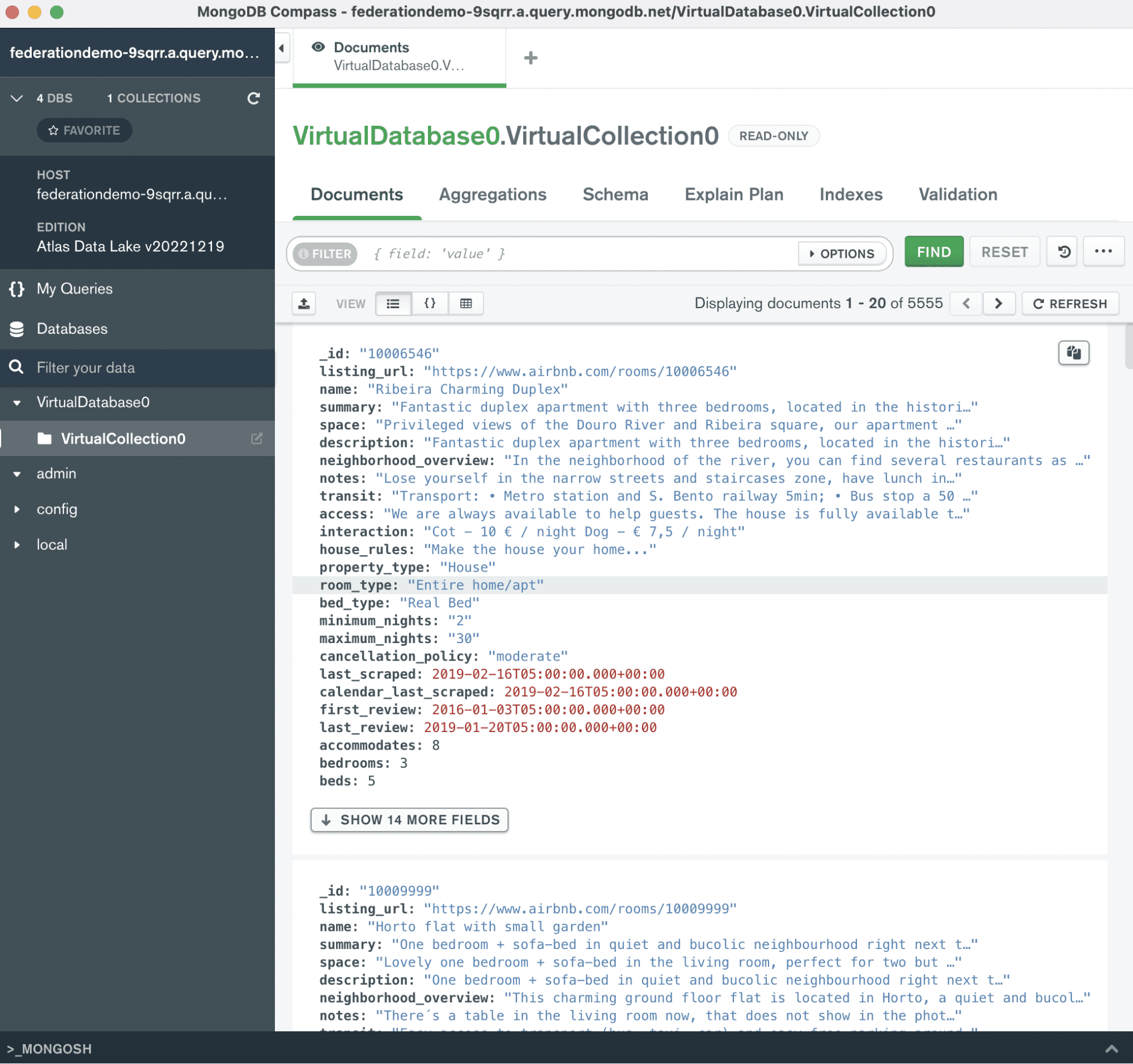
Amazing job. You can now look at all your Airbnb notes in one location!
In this tutorial, we have successfully stored your Airbnb data in various storage locations, combined these separate data sets into one via Data Federation, and successfully accessed our data back through MongoDB Compass. Now you can look for and book the perfect Airbnb for your trip in a fraction of the time.