摄: CHUTTERSNAP 发表在 Unsplash
数据在生成式 AI 中的作用
任何 AI 系统(包括生成式 AI 系统)的有效性和多功能性都取决于用来训练其模型的数据的质量、数量和多样性。我们来看看数据与生成式 AI 模型之间关系的一些关键方面。
训练数据
生成式 AI 模型是在海量大型数据集上进行训练的。为文本设计的模型可能经过数十亿篇文章的训练,而为图像设计的另一个模型可能经过数百万张图片的训练。如果大型语言模型要生成连贯且符合上下文的内容,则需要大量的机器学习训练数据。随着数据越来越多样化和全面,模型理解和生成广泛内容的能力得以提高。
一般而言,更多的数据可转化为更好的模型输出。使用更大的数据集,生成式 AI 模型可以识别更细微的模式,从而生成更准确、更细致的输出。但是,数据的质量也极其重要。通常,较小的高质量数据集的表现可能优于较大、不太相关的数据集。
原始数据和复杂数据
原始数据,尤其是复杂且非结构化的数据,可能需要在数据管道的早期阶段进行预处理,然后才能用于训练。这也是验证数据的时间,确保其具有适当的代表性且没有偏见。这一验证步骤对于避免扭曲或片面的输出至关重要。
标记数据与未标记数据
标记数据提供有关每个数据点的特定信息(例如,图像附带的文本描述),而未标记的数据则不包含此类注释。生成式模型通常适用于未标记的数据,因为它们仍然能够通过理解固有的结构和模式来学习如何生成内容。
专有数据
有些数据对于特定组织来说是唯一的。示例包括客户订单历史记录、员工绩效指标和业务流程。许多企业收集这些数据,将其匿名化以防止敏感的 PII 或 PHI 泄露给下游,然后进行传统的数据分析。这些数据包含大量信息,如果用于训练生成式模型,可以更深入地挖掘这些信息。由此生成的输出将根据该企业的具体需求和特点进行定制。
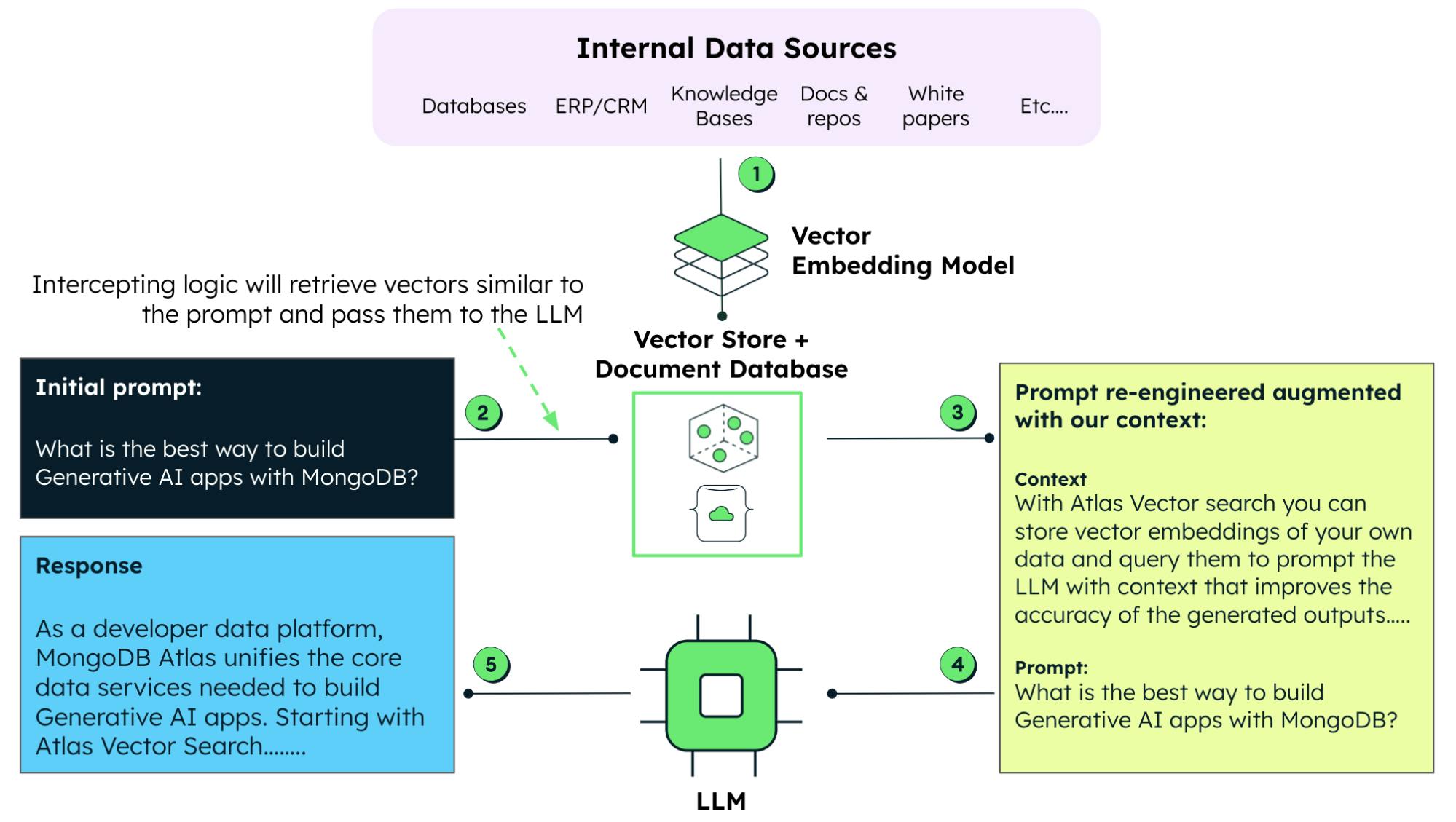
数据在 RAG 中的作用
如上所述,RAG 将 LLM 的强大功能与实时数据检索相结合。借助 RAG,您不再仅仅依赖预训练的数据。相反,您可以从外部数据库即时提取相关信息。这确保了生成的内容是最新且准确的。
如何使用专有数据增强生成式 AI 模型
在使用生成式模型时,提示工程是一种涉及精心设计特定输入查询或指令来指导模型、更好地定制输出或响应的技术。借助 RAG,我们可以使用专有数据来增强提示,使 AI 模型能够在考虑企业数据的情况下生成相关且准确的响应。这种方法也比使用这些数据重新训练或微调 LLM 的耗时和资源密集型方法更可取。
挑战和注意事项
当然,使用生成式 AI 并非没有挑战。如果您的组织希望发挥 GenAI 的潜力,您应该牢记以下关键问题。
需要数据专业知识和强大的计算能力
生成式模型需要大量资源。首先,您需要训练有素的数据科学家和工程师的专业知识。除数据组织外,大多数企业都没有具备训练或微调 LLM 所需专业技能的团队
就计算资源而言,对模型进行全面的数据训练可能需要数周或数月的时间,即使您使用功能强大的 GPU 或 TPU 也是如此。尽管微调 LLM 可能不像从头开始训练那样需要那么多的计算能力,但它仍然需要大量的资源。
LLM 的资源密集型训练和微调使得 RAG 成为一种有吸引力的替代技术,用于将当前(和专有)数据与预训练 LLM 可用的现有数据相结合。
道德考量
生成式 AI 的兴起也引发了对其开发和使用所带来的道德考量的激烈讨论。随着生成式 AI 应用程序变得更加主流并为公众所接受,对话集中在如何:
- 确保模型公平和无偏见
- 防范模型中毒或模型篡改等攻击
- 防止虚假信息的传播
- 防止滥用生成式 AI(例如深度伪造或生成误导性信息)
- 保留归属
- 提高最终用户的透明度,以便他们知道何时是在与生成式 AI 聊天机器人而不是人类进行交互
与其他 AI 工具和系统的比较
生成式 AI 工具的大肆宣传和新奇感已经让更广泛的 AI 工具和系统领域黯然失色。许多人错误地认为生成式 AI 是解决他们所有问题的 AI 工具。然而,虽然生成式 AI 擅长创建新内容,但其他 AI 工具可能更适合某些业务任务。就像堆栈中的任何工具一样,应该权衡生成式 AI 的优势与其他工具的优势。
RAG 特定的挑战
利用大型语言模型的 RAG 方法非常强大,但也面临着一系列挑战。
- 选择向量数据库和搜索技术: RAG 方法的效率最终取决于其快速检索相关数据的能力。因此,选择向量数据库和搜索技术是影响 RAG 性能的关键决策。
- 数据一致性: 由于 RAG 实时提取数据,因此确保向量数据库最新和一致至关重要。
- 集成复杂性: 将 RAG 与 LLM 集成会增加系统的复杂性。借助 RAG 有效实施生成式 AI 可能需要专业知识。
尽管存在这些挑战,RAG 为组织提供了一种简单而强大的方法,利用其运营和应用程序数据来收集丰富的见解并为关键业务决策提供信息。
用于 GenAI 应用程序的 MongoDB Atlas
我们已经了解生成式 AI 的变革性潜力,并且看到了 RAG 带来的实时数据的强大增强。将这些技术结合在一起需要一个灵活的数据平台,提供一套为 GenAI 应用程序量身定制的功能。对于涉足生成式 AI 和 RAG 领域的组织来说,MongoDB Atlas 将改变游戏规则。
MongoDB Atlas 的核心功能包括:
- 原生向量搜索功能: MongoDB Atlas 内置原生向量存储和搜索功能,可确保 RAG 快速高效地检索数据,而无需额外的数据库来处理向量。
- 统一的 API 和灵活的文档模型: MongoDB Atlas 的统一 API 允许开发者将向量搜索与其他查询功能(例如结构化搜索或文本搜索)相结合。再加上 MongoDB 的文档数据模型,为您的实施带来了难以置信的灵活性。
- 可扩展性、可靠性和安全性: MongoDB Atlas 提供水平扩展,可以随着您(和您的数据)的增长而轻松扩展。凭借容错能力和简单的水平和垂直扩展,MongoDB Atlas 可确保不间断的服务,无论您的工作负载需求如何。当然,MongoDB 展示了它如何通过启用行业领先的可查询数据加密来优先考虑安全性。