Foto di CHUTTERSNAP on Unsplash
Il ruolo dei dati nell'AI generativa
L'efficacia e la versatilità di qualsiasi sistema di IA, inclusi i sistemi di IA generativa, dipendono dalla qualità, dalla quantità e dalla diversità dei dati utilizzati per addestrare i suoi modelli. Diamo un'occhiata ad alcuni aspetti chiave della relazione tra dati e modello di IA generativa.
Addestramento dei dati
I modelli di IA generativa vengono addestrati su set di dati di grandi dimensioni. Un modello progettato per il testo può essere addestrato su miliardi di articoli, mentre un altro modello progettato per le immagini può essere addestrato su milioni di immagini. I LLM richiedono grandi quantità di dati di addestramento sull’apprendimento automatico se vogliono generare contenuti coerenti e contestualmente rilevanti. Poiché i dati sono più diversificati e completi, la capacità del modello di comprendere e generare una vasta gamma di contenuti migliora.
In generale, un maggior numero di dati si traduce in migliori output del modello. Con un set di dati più ampio, i modelli di IA generativa possono identificare pattern più sottili, ottenendo risultati più accurati e sfumati. Tuttavia, anche la qualità dei dati è estremamente importante. Spesso, un set di dati più piccolo e di alta qualità può superare le prestazioni di uno più grande ma meno rilevante.
Dati grezzi e complessi
I dati grezzi, soprattutto se complessi e non strutturati, possono richiedere la pre-elaborazione nelle fasi iniziali della pipeline di dati prima che possano essere utilizzabili per l'addestramento. Questo è anche il momento in cui i dati vengono convalidati, per garantire che siano adeguatamente rappresentativi e privi di bias. Questa fase di convalida è fondamentale per evitare risultati distorti o falsati.
Dati etichettati e dati non etichettati
Alcuni dati sono esclusivi per una particolare organizzazione. Gli esempi includono la cronologia degli ordini dei clienti, le metriche delle prestazioni dei dipendenti e i processi aziendali. Molte aziende raccolgono questi dati, li rendono anonimi per evitare che PII o PHI sensibili vengano divulgati, ed eseguono poi l'analisi tradizionale dei dati. Questi dati contengono una grande quantità di informazioni che potrebbero essere ancor più approfondite se utilizzate per addestrare un modello generativo. I risultati saranno così adattati alle esigenze e alle caratteristiche specifiche di tale attività.
Il ruolo dei dati nella RAG
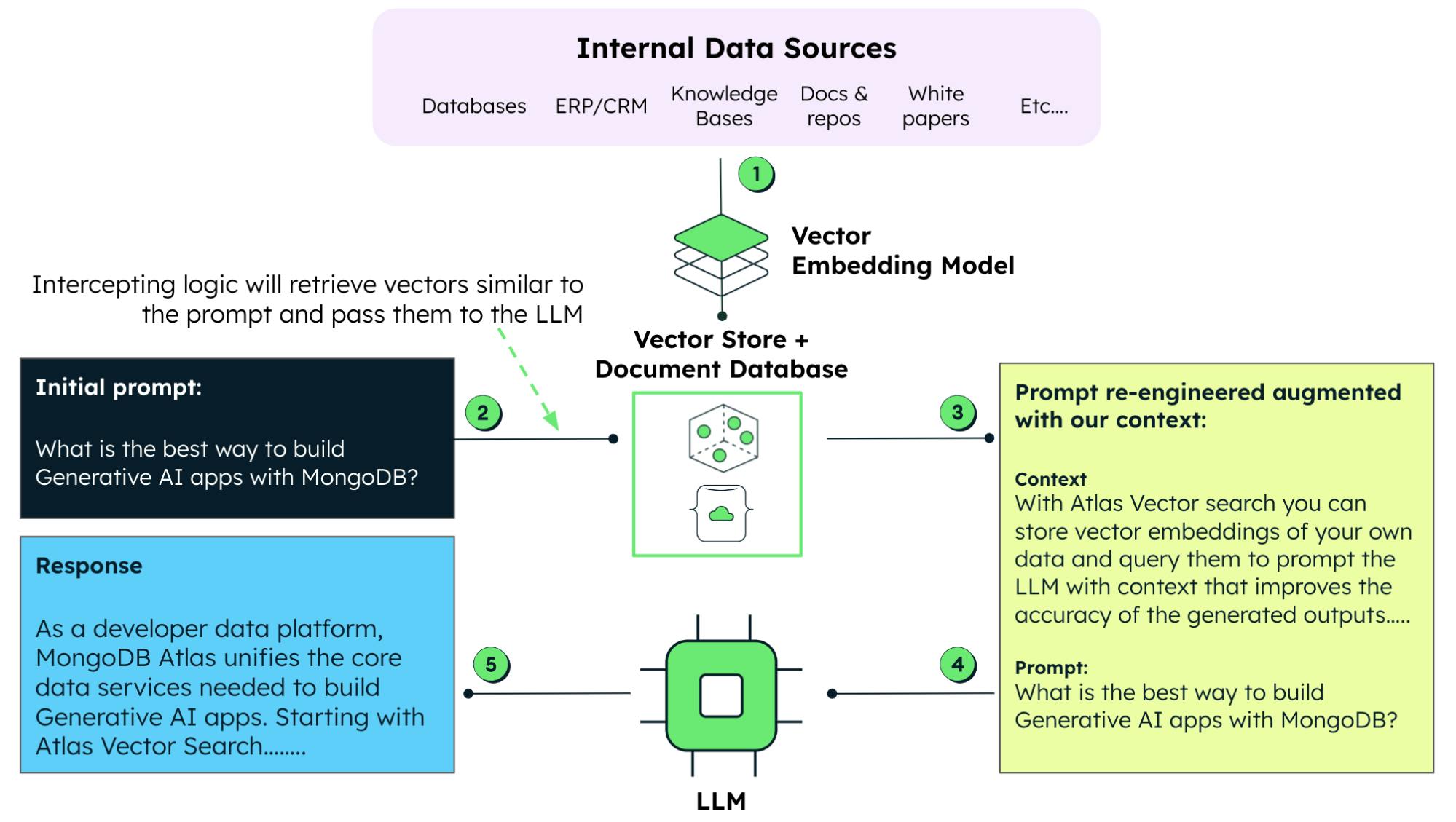
Come già detto, la RAG combina la potenza di un LLM con il recupero dei dati in tempo reale. Con una RAG, non dovrai affidarti più esclusivamente a dati pre-addestrati, ma potrai eseguire un pull di informazioni rilevanti just-in-time da database esterni. Ciò garantisce che i contenuti generati siano aggiornati e accurati.
Come potenziare i modelli di IA generativa con i dati proprietari
Quando si lavora con i modelli generativi, l'ingegneria dei prompt è una tecnica che prevede la creazione di query o istruzioni di input specifiche per guidare il modello, adattando meglio gli output o le risposte. Con il RAG, possiamo aumentare i prompt con dati proprietari, attrezzando il modello di IA per generare risposte pertinenti e accurate tenendo conto dei dati aziendali. Questo approccio è preferibile all'approccio lungo e costoso di riqualificare o mettere a punto un LLM con questi dati.
Sfide e considerazioni importanti
Ovviamente, lavorare con l'IA generativa porta con sé diverse sfide. Se la tua organizzazione sta cercando di sfruttare il potenziale della GenAI, tieni presente le seguenti questioni chiave.
Necessità di competenze in materia di dati e di un'enorme potenza di calcolo
I modelli generativi richiedono risorse importanti. Innanzitutto, è necessaria l’esperienza di data scientist e ingegneri qualificati. Ad eccezione delle organizzazioni che si occupano dei dati, la maggior parte delle aziende non dispone di team con le competenze specialistiche necessarie per addestrare o mettere a punto gli LLM.
Quando si tratta di risorse di elaborazione, l'addestramento di un modello su dati completi può richiedere settimane o mesi, anche se si utilizzano GPU o TPU potenti. Anche se la messa a punto di un LLM non richiede una potenza di calcolo pari a quella necessaria per addestrarne uno da zero, richiede comunque risorse significative.
La formazione e la messa a punto ad alta intensità di risorse di un LLM sono ciò che rende il RAG una tecnica alternativa interessante per incorporare i dati attuali (e proprietari) con i dati esistenti disponibili per un LLM pre-addestrato.
Considerazioni etiche
L'ascesa dell'IA generativa ha generato anche un intenso dibattito sulle considerazioni etiche legate al suo sviluppo e al suo utilizzo. Man mano che le applicazioni di IA generativa diventano più diffuse e accessibili al pubblico, le conversazioni si sono concentrate su argomenti come:
- Garantire modelli equi e privi di pregiudizi
- Proteggere da attacchi come manomissioni del modello
- Prevenire la diffusione della disinformazione
- Difendersi dall’uso improprio dell'IA generativa (si pensi ai deepfake o alla generazione di informazioni fuorvianti)
- Conservare attribuzione
- Promuovere la trasparenza con gli utenti finali, in modo che sappiano quando stanno interagendo con un chatbot di IA generativa invece che con un essere umano.
The hype and novelty of generative AI tools have eclipsed the broader AI landscape of tools and systems. Many mistakenly assume that generative AI is the AI tool to solve all their problems. However, while generative AI excels in creating new content, other AI tools might be better suited for certain business tasks. The benefits of generative AI should—just as with any tool in your stack—be weighed against the benefits of other tools.
Sfide specifiche della RAG
L'approccio RAG all'utilizzo di un LLM è potente, ma presenta una serie di sfide caratteristiche.
- Scegliere le tecnologie di database vettoriale e di ricerca: in ultima istanza, l'efficienza dell'approccio RAG dipende dalla sua capacità di recuperare rapidamente i dati pertinenti. Ciò rende la selezione di un database vettoriale e di una tecnologia di ricerca una scelta critica che influirà sulle prestazioni della RAG.
- Coerenza dei dati: poiché la RAG estrae i dati in tempo reale, è essenziale garantire che il database vettoriale sia aggiornato e coerente.
- Complessità delle integrazioni: L'integrazione della RAG con un LLM aggiunge un livello di complessità ai sistemi. L'implementazione efficace dell'IA generativa con una RAG può richiedere competenze specializzate.
Nonostante queste sfide, la RAG offre alle organizzazioni uno strumento semplice e potente per attingere ai propri dati operativi e applicativi per raccogliere informazioni approfondite e prendere decisioni aziendali critiche.
MongoDB Atlas per app basate sulla GenAI
Abbiamo accennato al potenziale trasformativo dell'IA generativa e abbiamo visto il potente miglioramento dei dati in tempo reale che deriva dalla RAG. L'unione di queste tecnologie richiede una piattaforma dati flessibile in grado di offrire una suite di funzionalità su misura per le applicazioni basate sulla GenAI. Per le organizzazioni che si avventurano nel mondo dell'IA generativa e della RAG, MongoDB Atlas sarà il fattore che cambierà le carte in tavola.
Le caratteristiche chiave di MongoDB Atlas includono:
- Funzionalità native di ricerca vettoriale: l'archiviazione e la ricerca vettoriali native sono integrate in MongoDB Atlas, garantendo un recupero rapido ed efficiente dei dati per RAG senza la necessità di un database aggiuntivo per gestire i vettori.
- API unificata e modello di documento flessibile: L'API unificata di MongoDB Atlas consente agli sviluppatori di combinare la ricerca vettoriale con altre funzionalità di query, come la ricerca strutturata o testuale. Questo, insieme al data model doc di MongoDB, offre un'incredibile flessibilità all'implementazione.
- Scalabilità, affidabilità e sicurezza: MongoDB Atlas fornisce scalabilità orizzontale per crescere facilmente insieme all'utente (e ai suoi dati). Grazie alla tolleranza di errore e alla scalabilità orizzontale e verticale intuitiva, MongoDB Atlas garantisce un servizio ininterrotto, quali che siano le esigenze del workload. E, naturalmente, MongoDB dà priorità alla sicurezza abilitando la crittografia dei dati interrogabile leader del settore.