Photo par CHUTTERSNAP sur Unsplash
Le rôle des données dans l'IA générative
L'efficacité et la polyvalence de tout système d'IA, y compris les systèmes d'IA générative, dépendent de la qualité, de la quantité et de la diversité des données utilisées pour entraîner ses modèles. Examinons certains aspects clés de la relation entre les données et le modèle d'IA générative.
Données d’entraînement
Les modèles d’IA Générative sont entraînés sur des ensembles de données très volumineux. Un modèle conçu pour le texte peut être entraîné sur des milliards d'articles, tandis qu'un autre modèle conçu pour les images peut être entraîné sur des millions d'images. Pour générer un contenu cohérent et pertinent, les LLM nécessitent de grandes quantités de données d'entraînement au machine learning. Plus les données sont diversifiées et complètes, plus la capacité du modèle à comprendre et à générer un large éventail de contenus s'améliore.
D'une manière générale, plus il y a de données, meilleurs sont les résultats du modèle. Avec un ensemble de données plus important, les modèles d'IA Générative peuvent identifier des modèles plus subtils, ce qui se traduit par des résultats plus précis et nuancés. Toutefois, la qualité des données est également extrêmement importante. Souvent, un petit ensemble de données de haute qualité peut être plus performant qu'un grand ensemble de données moins pertinent.
Données brutes et complexes
Les données brutes, en particulier si elles sont complexes et non structurées, peuvent nécessiter un prétraitement lors des premières étapes du pipeline de données, avant d'être utilisées pour entraîner le modèle. C'est aussi à ce moment-là qu'elles sont validées, afin de s'assurer qu'elles sont représentatives et correctes. Cette étape est essentielle pour éviter les résultats biaisés.
Données étiquetées et données non étiquetées
Les données étiquetées fournissent des informations spécifiques sur chaque point de données (par exemple, une description textuelle accompagnant une image), alors que les données non étiquetées ne comportent pas d'annotations de ce type. Les modèles génératifs fonctionnent souvent bien avec des données non étiquetées, car ils sont encore capables d'apprendre à générer du contenu en comprenant les structures et les modèles inhérents.
Données propriétaires
Certaines données sont propres à une organisation. Il peut s'agir de l'historique des commandes des clients, des indicateurs de performance des employés et des processus métier. De nombreuses entreprises collectent ces données, les rendent anonymes afin d'empêcher les fuites de données à caractère personnel (PII) ou de données de santé (PHI) en aval, puis procèdent à une analyse des données traditionnelles. Ces données contiennent une mine d'informations qui pourraient être davantage exploitées si elles étaient utilisées pour entraîner un modèle génératif. Les résultats obtenus seraient adaptés aux besoins et aux caractéristiques spécifiques de cette entreprise.
Le rôle des données dans la génération augmentée de récupération (RAG)
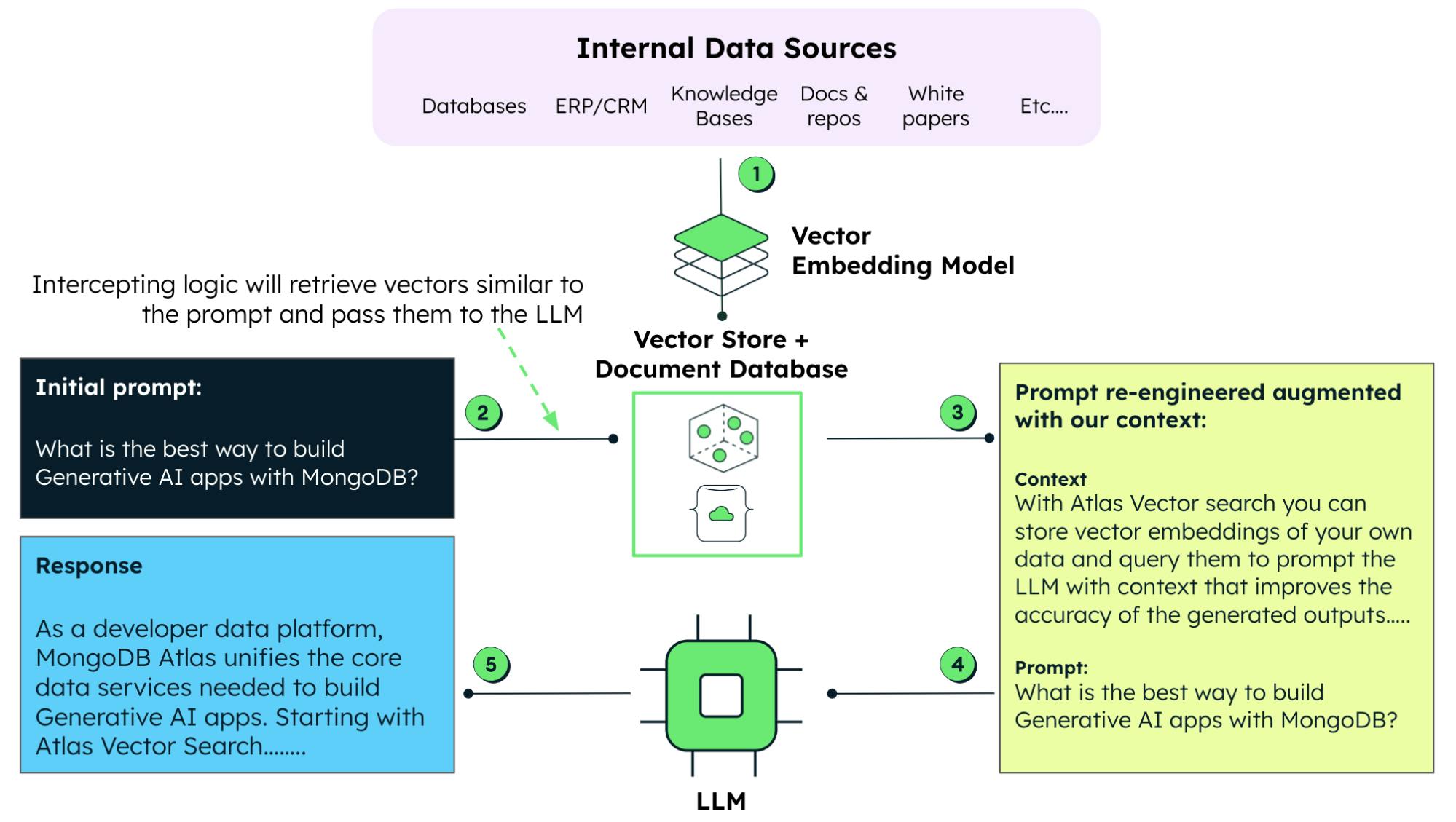
Comme mentionné ci-dessus, la RAG combine la puissance d'un LLM avec la recherche de données en temps réel. Avec la RAG, vous ne dépendez plus uniquement des données pré-entraînées. Au lieu de cela, vous pouvez exécuter une extraction juste à temps d'informations pertinentes à partir de bases de données externes. Cela permet de s'assurer que le contenu généré est à jour et fiable.
Lorsque vous travaillez avec des modèles génératifs, l'ingénierie rapide est une technique qui consiste à élaborer des requêtes ou des instructions de saisie spécifiques pour guider le modèle, afin de mieux adapter les résultats ou les réponses. Grâce à la RAG, nous pouvons compléter les invites avec des données propriétaires. Le modèle d'IA génère ainsi des réponses pertinentes et précises en tenant compte des données de l'entreprise. Cette approche est également préférable à l'approche chronophage et gourmande en ressources qui consiste à recycler ou à affiner un LLM à l'aide de ces données.
Défis et considérations
Bien entendu, travailler avec l'IA Générative n'est pas sans défis. Si votre organisation cherche à exploiter le potentiel de l'IA Générative, vous devez garder à l’esprit les questions clés suivantes.
Expertise en matière de données et puissance de calcul massive
Les modèles génératifs nécessitent des ressources substantielles. Tout d’abord, vous avez besoin de l’expertise de data scientists et d’ingénieurs qualifiés. Hormis les entreprises spécialisées dans les données, la plupart des entreprises ne disposent pas d'équipes dotées des compétences nécessaires pour former ou affiner les LLM.
En ce qui concerne les ressources informatiques, l'entraînement d'un modèle sur des données complètes peut nécessiter des semaines voire des mois, même si vous utilisez de puissants GPU ou TPU. En outre, bien que l'ajustement d'un LLM ne nécessite pas autant de puissance de calcul que la formation d'un LLM à partir de zéro, il requiert tout de même des ressources substantielles.
L'entraînement et la mise au point d'un LLM, qui nécessitent des ressources substantielles, font de la RAG une alternative intéressante pour intégrer des données actuelles (et propriétaires) aux données existantes disponibles pour un LLM pré-entraîné.
Considérations éthiques
L'essor de l'IA générative a également suscité d'intenses débats sur les considérations éthiques qui accompagnent son développement et son utilisation. Alors que les applications d'IA Générative deviennent de plus en plus courantes et accessibles au public, les réflexions se sont concentrées sur la façon de :
- Garantir des modèles équitables et impartiaux
- Se protéger contre les attaques telles que l'empoisonnement ou la falsification de modèles.
- Empêcher la désinformation.
- Se prémunir contre l’utilisation abusive de l’IA générative (par exemple, les deepfakes ou à la génération d’informations trompeuses)
- Préserver l’attribution
- Promouvoir la transparence avec les utilisateurs finaux, afin qu'ils sachent quand ils interagissent avec un chatbot d'IA générative plutôt qu'avec un humain
Comparaison avec d'autres outils et systèmes d'IA
Le battage médiatique et la nouveauté des outils d'IA générative ont éclipsé le paysage plus large des outils et des systèmes d'IA. Beaucoup pensent à tort que l'IA générative est l'outil par excellence qui leur permettra de résoudre tous leurs problèmes. Cependant, si elle excelle dans la création de nouveaux contenus, d'autres solutions pourraient être mieux adaptées à certaines tâches professionnelles. Comme pour tout autre outil que vous utilisez, vous devez comparer ses avantages à ceux des autres outils.
Défis spécifiques à la RAG
Cette approche, qui consiste à tirer parti d'un grand modèle de langage, est puissante, mais elle s'accompagne également de son lot de défis.
- Choisir une base de données vectorielles et des technologies de recherche : l'efficacité de cette approche dépend de sa capacité à récupérer rapidement les données pertinentes. Cela fait de la sélection d'une base de données vectorielle et d'une technologie de recherche une décision critique qui affectera les performances de la RAG.
- Cohérence des données : étant donné que la RAG extrait les données en temps réel, vous devez vous assurer que la base de données vectorielles est à jour et cohérente.
- Complexité de l'intégration : l'intégration de la RAG avec un LLM renforce la complexité de vos systèmes. La mise en œuvre efficace de l'IA Générative avec la RAG peut nécessiter une expertise.
En dépit de ces difficultés, la RAG offre aux entreprises un moyen simple et puissant de puiser dans leurs données opérationnelles et d'application pour en tirer de riches enseignements et prendre des décisions cruciales.
MongoDB Atlas pour les applications basées sur l'IA Générative
Nous avons abordé le potentiel de transformation de l’IA Générative, et nous avons vu comment la RAG améliorait considérablement les données en temps réel. Pour réunir ces technologies, il faut une plateforme de données flexible qui offre des fonctionnalités adaptées aux applications alimentées par GenAI. Pour les entreprises qui s’aventurent dans ce secteur, MongoDB Atlas changera la donne.
Voici les principales fonctionnalités de MongoDB Atlas :
- Fonctionnalités de recherche vectorielle natives : le stockage et la recherche vectorielle sont intégrés à MongoDB Atlas, ce garantit une récupération rapide et efficace des données pour la RAG sans nécessiter une base de données supplémentaire pour gérer les vecteurs.
- API unifiée et document model flexible : l'API unifiée de MongoDB Atlas permet aux développeurs de combiner la recherche vectorielle avec d'autres fonctionnalités de requête, telles que la recherche structurée ou la recherche textuelle. Associée au modèle de données documentaire de MongoDB, cette API offre une incroyable flexibilité à votre mise en œuvre.
- Évolutivité, fiabilité et sécurité : MongoDB Atlas offre une évolutivité horizontale qui évolue à mesure que vous (et vos données) vous développez. Grâce à sa tolérance aux pannes et à une mise à l'échelle horizontale et verticale simple, MongoDB Atlas garantit un service ininterrompu, quelles que soient les exigences de votre charge de travail. Et, bien entendu, MongoDB montre comment elle cible la sécurité en priorité en permettant un chiffrement des données de pointe, qui peut être interrogé.