Foto von CHUTTERSNAP auf Unsplash
Die Rolle der Daten bei der generativen KI
Die Effektivität und Vielseitigkeit eines jeden KI-Systems, einschließlich generativer KI-Systeme, hängt von der Qualität, der Menge und der Vielfalt der Daten ab, die zum Trainieren der Modelle verwendet werden. Lassen Sie uns einige Schlüsselaspekte der Beziehung zwischen Daten und dem generativen KI-Modell betrachten.
Trainingsdaten
Generative KI-Modelle werden anhand großer Datenmengen trainiert. Ein Modell, das für Texte entwickelt wurde, kann auf Milliarden von Artikeln trainiert werden, während ein anderes Modell, das für Bilder entwickelt wurde, auf Millionen von Bildern trainiert werden kann. Large Language Models benötigen große Mengen an Trainingsdaten für maschinelles Lernen, wenn sie kohärente und kontextbezogene Inhalte erzeugen sollen. Je vielfältiger und umfassender die Daten sind, desto besser ist das Modell in der Lage, eine breite Palette von Inhalten zu verstehen und zu generieren.
Generell gilt, dass mehr Daten zu besseren Modellergebnissen führen. Mit einem größeren Datensatz können generative KI-Modelle feinere Muster erkennen, was zu genaueren und differenzierteren Ergebnissen führt. Aber auch die Qualität der Daten ist extrem wichtig. Oftmals ist ein kleinerer, hochwertiger Datensatz leistungsfähiger als ein größerer, weniger relevanter Datensatz.
Rohe und komplexe Daten
Rohdaten, insbesondere wenn sie komplex und unstrukturiert sind, müssen möglicherweise in den frühen Phasen der Datenpipeline vorverarbeitet werden, bevor sie für das Training verwendet werden können. Dies ist auch der Zeitpunkt, an dem die Daten validiert werden, um sicherzustellen, dass sie angemessen repräsentativ und frei von Verzerrungen sind. Dieser Validierungsschritt ist entscheidend, um verzerrte oder verfälschte Ergebnisse zu vermeiden.
„Gekennzeichnete Daten“ versus „nicht gekennzeichnete Daten“
Gekennzeichnete Daten enthalten spezifische Informationen zu jedem Datenpunkt (z. B. eine textliche Beschreibung zu einem Bild), während nicht gekennzeichnete Daten keine derartigen Anmerkungen enthalten. Generative Modelle arbeiten oft gut mit nicht gekennzeichneten Daten, da sie immer noch in der Lage sind, zu lernen, wie man Inhalte generiert, indem sie inhärente Strukturen und Muster verstehen.
Proprietäre Daten
Einige Daten sind einzigartig für ein bestimmtes Unternehmen. Beispiele hierfür sind die Bestellhistorie von Kunden, Leistungskennzahlen von Mitarbeitern und Geschäftsprozesse. Viele Unternehmen sammeln diese Daten, anonymisieren sie, um zu verhindern, dass sensible personenbezogene Daten (PII oder PHI) nach unten durchsickern, und führen dann eine herkömmliche Datenanalyse durch. Diese Daten enthalten eine Fülle von Informationen, die noch tiefer gehend ausgewertet werden könnten, wenn sie zum Trainieren eines generativen Modells verwendet würden. Die daraus resultierenden Ergebnisse würden auf die spezifischen Bedürfnisse und Merkmale des jeweiligen Unternehmens zugeschnitten sein.
Die Rolle von Daten in RAG
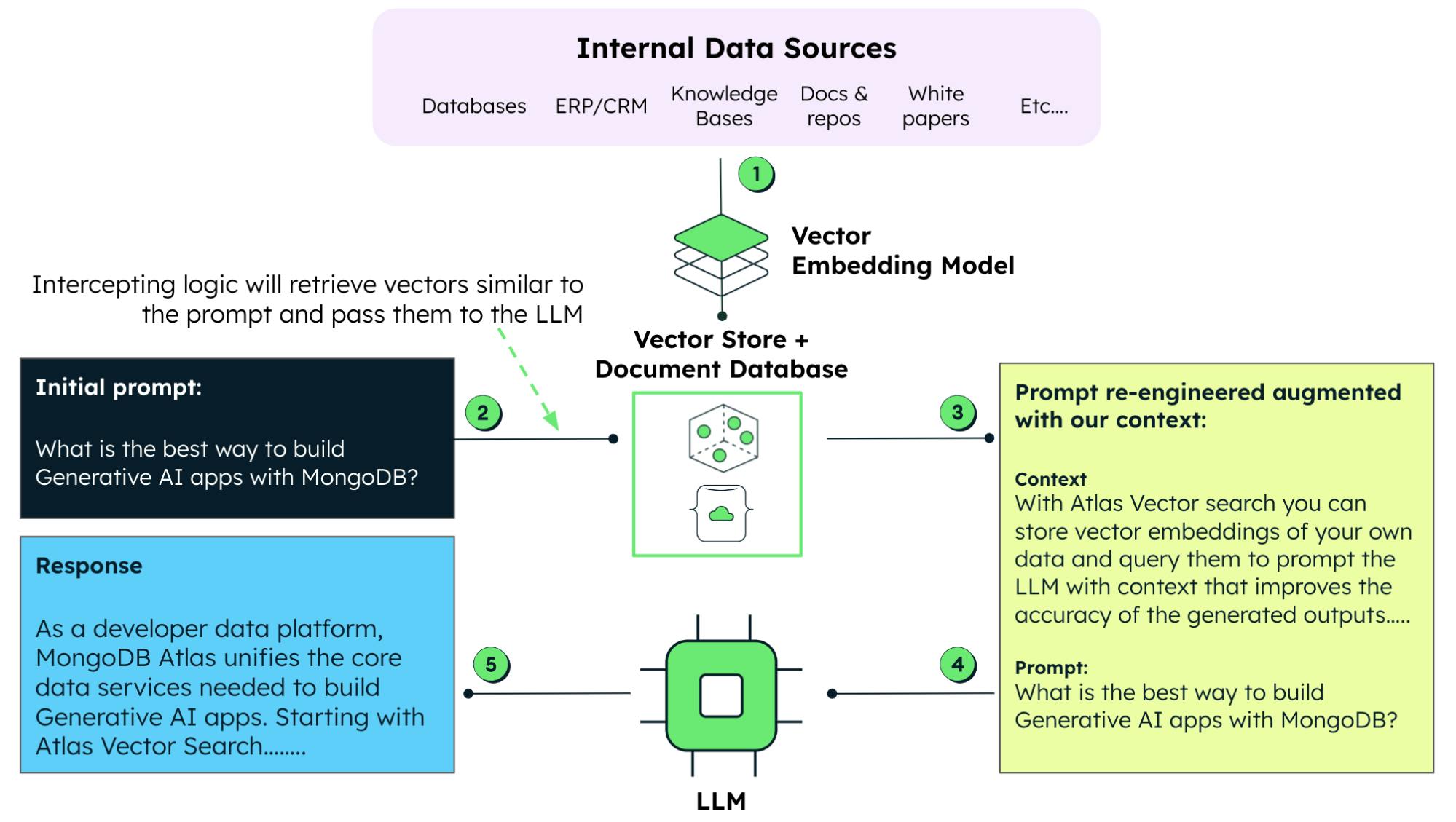
Wie bereits erwähnt, kombiniert RAG die Leistungsfähigkeit eines LLM mit dem Abruf von Daten in Echtzeit. Mit RAG verlassen Sie sich nicht mehr ausschließlich auf vorab trainierte Daten. Stattdessen können Sie einen Just-in-Time-Pull von relevanten Informationen aus externen Datenbanken durchführen. Dadurch wird sichergestellt, dass die generierten Inhalte aktuell und korrekt sind.
Ergänzung von generativen KI-Modellen mit eigenen Daten
Bei der Arbeit mit generativen Modellen ist das Prompt-Engineering eine Technik, bei der spezifische Eingabeabfragen oder Anweisungen erstellt werden, um das Modell zu steuern und die Ergebnisse oder Antworten besser anzupassen. Mit RAG können wir Prompts mit unternehmenseigenen Daten ergänzen und das KI-Modell so ausstatten, dass es unter Berücksichtigung dieser Unternehmensdaten relevante und genaue Antworten generiert. Dieser Ansatz ist auch dem zeitraubenden und ressourcenintensiven Ansatz vorzuziehen, ein LLM mit diesen Daten neu zu trainieren oder fein abzustimmen.
Herausforderungen und Überlegungen
Natürlich kommt die Arbeit mit generativer KI nicht ohne Herausforderungen. Wenn Ihr Unternehmen das Potenzial von generativer KI nutzen möchte, sollten Sie die folgenden Kernpunkte berücksichtigen.
Bedarf an Datenkompetenz und massiver Rechenleistung
Generative Modelle erfordern erhebliche Ressourcen. Zunächst benötigen Sie das Fachwissen ausgebildeter Datenwissenschaftler und Ingenieure. Mit Ausnahme von Datenorganisationen verfügen die meisten Unternehmen nicht über Teams mit den speziellen Fähigkeiten, die für die Schulung oder Feinabstimmung von LLMs erforderlich wären.
Wenn es um Rechenressourcen geht, kann das Training eines Modells auf umfassenden Daten Wochen oder Monate dauern – selbst wenn Sie leistungsstarke GPUs oder TPUs verwenden. Und obwohl die Feinabstimmung eines LLM nicht so viel Rechenleistung erfordert wie das Trainieren eines LLM von Grund auf, werden dennoch erhebliche Ressourcen benötigt.
Das ressourcenintensive Training und die Feinabstimmung eines LLM macht RAG zu einer attraktiven alternativen Technik, um aktuelle (und eigene) Daten mit den vorhandenen Daten zu verbinden, die einem vortrainierten LLM zur Verfügung stehen.
Ethische Überlegungen
Der Aufstieg der generativen KI hat auch eine intensive Diskussion über die ethischen Überlegungen ausgelöst, die mit ihrer Entwicklung und Nutzung einhergehen. In dem Maße, wie generative KI-Anwendungen sich durchsetzen und für die Öffentlichkeit zugänglich werden, dreht sich die Diskussion um die Frage, wie man sie einsetzen kann:
- Sorgen Sie für gerechte und vorurteilsfreie Modelle
- Schutz vor Angriffen wie Modellvergiftung oder Modellmanipulationen
- Schützen Sie sich vor dem Missbrauch generativer KI ( z. B. Deepfakes oder die Erzeugung irreführender Informationen)
- Preserve attribution
- Fördern Sie die Transparenz gegenüber den Endnutzern, damit diese wissen, wann sie mit einem generativen KI-Chatbot und nicht mit einem Menschen interagieren
Der Hype und die Neuartigkeit der generativen KI-Tools haben die breitere KI-Landschaft der Tools und Systeme in den Schatten gestellt. Viele gehen fälschlicherweise davon aus, dass generative KI das KI-Tool ist, das alle ihre Probleme löst. Während sich generative KI jedoch bei der Erstellung neuer Inhalte auszeichnet, sind andere KI-Tools für bestimmte Geschäftsaufgaben möglicherweise besser geeignet. Die Vorteile der generativen KI sollten – wie bei jedem anderen Tool in Ihrem Stack – gegen die Vorteile anderer Tools abgewogen werden.
RAG-spezifische Herausforderungen
Der RAG-Ansatz zur Nutzung eines LLMs ist leistungsstark, aber er bringt auch eine Reihe von Herausforderungen mit sich.
- Auswahl von Vektordatenbanken und Suchtechnologien: Letztlich hängt die Effizienz des RAG-Ansatzes von seiner Fähigkeit ab, relevante Daten schnell abzurufen. Daher ist die Auswahl einer Vektordatenbank und einer Suchtechnologie eine wichtige Entscheidung, die sich auf die Leistung der RAG auswirkt.
- Datenkonsistenz: Da RAG Daten in Echtzeit abruft, ist es wichtig, dass die Vektordatenbank aktuell und konsistent ist.
- Komplexität der Integration: Die Integration von RAG mit einem LLM fügt Ihren Systemen eine zusätzliche Ebene der Komplexität hinzu. Die effektive Implementierung generativer KI mit RAG erfordert möglicherweise spezielles Fachwissen.
Ungeachtet dieser Herausforderungen bietet RAG Unternehmen eine einfache und leistungsstarke Möglichkeit, ihre Betriebs- und Anwendungsdaten zu nutzen, um umfangreiche Erkenntnisse zu gewinnen und wichtige Geschäftsentscheidungen zu treffen.
MongoDB Atlas für GenAI-gestützte Apps
Wir haben das transformative Potenzial der generativen KI angesprochen und die leistungsstarke Verbesserung von Echtzeitdaten gesehen, die mit RAG einhergeht. Um diese Technologien zusammenzubringen, bedarf es einer flexiblen Datenplattform, die eine Reihe von Funktionen bietet, die auf GenAI-gestützte Anwendungen zugeschnitten sind. Für Unternehmen, die den Einstieg in die Welt der generativen KI und RAG wagen, wird MongoDB Atlas den entscheidenden Unterschied ausmachen.
Die wichtigsten Funktionen von MongoDB Atlas umfassen:
- Native Vektorsuchfunktionen: Native Vektorspeicherung und -suche sind in MongoDB Atlas integriert und gewährleisten einen schnellen und effizienten Datenabruf für RAG, ohne dass eine zusätzliche Datenbank für die Verarbeitung von Vektoren erforderlich ist.
- Einheitliche API und flexibles Dokumentenmodell: Die einheitliche API von MongoDB Atlas ermöglicht es Entwicklern, die Vektorsuche mit anderen Abfragefunktionen wie der strukturierten Suche oder der Textsuche zu kombinieren. In Verbindung mit dem Dokumentdatenmodell von MongoDB bietet dies eine unglaubliche Flexibilität für Ihre Projekte.
- Skalierbarkeit, Zuverlässigkeit und Sicherheit: MongoDB Atlas bietet horizontale Skalierung, damit Sie (und Ihre Daten) problemlos mitwachsen können. Mit Fehlertoleranz und einfacher horizontaler und vertikaler Skalierung gewährleistet MongoDB Atlas einen unterbrechungsfreien Service, unabhängig von den Anforderungen Ihrer Arbeitslast. Und natürlich zeigt MongoDB, dass es die Sicherheit in den Vordergrund stellt, indem es eine branchenführende Datenverschlüsselung ermöglicht, die abgefragt werden kann.