Foto de CHUTTERSNAP on Unsplash
O papel dos dados em IA generativa
A eficácia e versatilidade de qualquer sistema de IA, e isso inclui sistemas de IA generativa, depende da qualidade, quantidade e diversidade de dados usados para treinar seus modelos. Vejamos alguns aspectos-chave da relação entre os dados e o modelo de IA generativa.
Dados para treinamento
Modelos de IA generativa são treinados em conjuntos de dados extremamente grandes. Um modelo projetado para gerar texto pode ser treinado com bilhões de artigos, enquanto outro modelo projetado para gerar imagens pode ser treinado com milhões de fotos. Os LLMs exigem enormes quantidades de dados para treinamento em aprendizado de máquina para gerar conteúdo coerente e contextualmente relevante. Quanto mais diversos e abrangentes forem os dados, melhor será a capacidade do modelo de entender e gerar uma ampla gama de conteúdos.
De um modo geral, mais dados se traduzem em resultados de modelo melhores. Com um conjunto de dados maior, os modelos de IA generativa podem identificar padrões mais sutis, resultando em saídas mais precisas e detalhadas. No entanto, a qualidade dos dados também é extremamente importante. Muitas vezes, um conjunto de dados menor e de alta qualidade pode superar um conjunto de dados maior e menos relevante.
Dados brutos e complexos
Os dados brutos, especialmente se forem complexos e não estruturados, podem exigir o pré-processamento nos estágios iniciais do pipeline de dados, antes que possam ser usados para treinamento.Esta também é a hora em que os dados são validados, para garantir que sejam devidamente representativos e livres de viés.Esta etapa de validação é crucial para evitar saídas distorcidas ou tendenciosas.
Dados rotulados contra dados não rotulados
Dados rotulados oferecem informações específicas sobre cada ponto de dados (por exemplo, descrição textual que acompanha uma imagem), enquanto dados não rotulados não incluem anotações como essa. Modelos generativos frequentemente trabalham bem com dados não rotulados, pois ainda são capazes de aprender a gerar conteúdo entendendo estruturas e padrões inerentes.
Dados proprietários
Alguns dados são exclusivos de uma determinada organização. Alguns exemplos incluem histórico de pedidos de clientes, métricas de desempenho de funcionários e processos comerciais. Muitas empresas coletam esses dados e os tornam anônimos para evitar o vazamento de PII ou PHI confidenciais e, em seguida, realizam a análise de dados tradicional. Esses dados contêm uma grande quantidade de informações que poderiam ser extraídas ainda mais profundamente se fossem usadas para treinar um modelo generativo. Os outputs resultantes seriam adaptados às necessidades e características específicas da empresa.
O papel dos dados na RAG
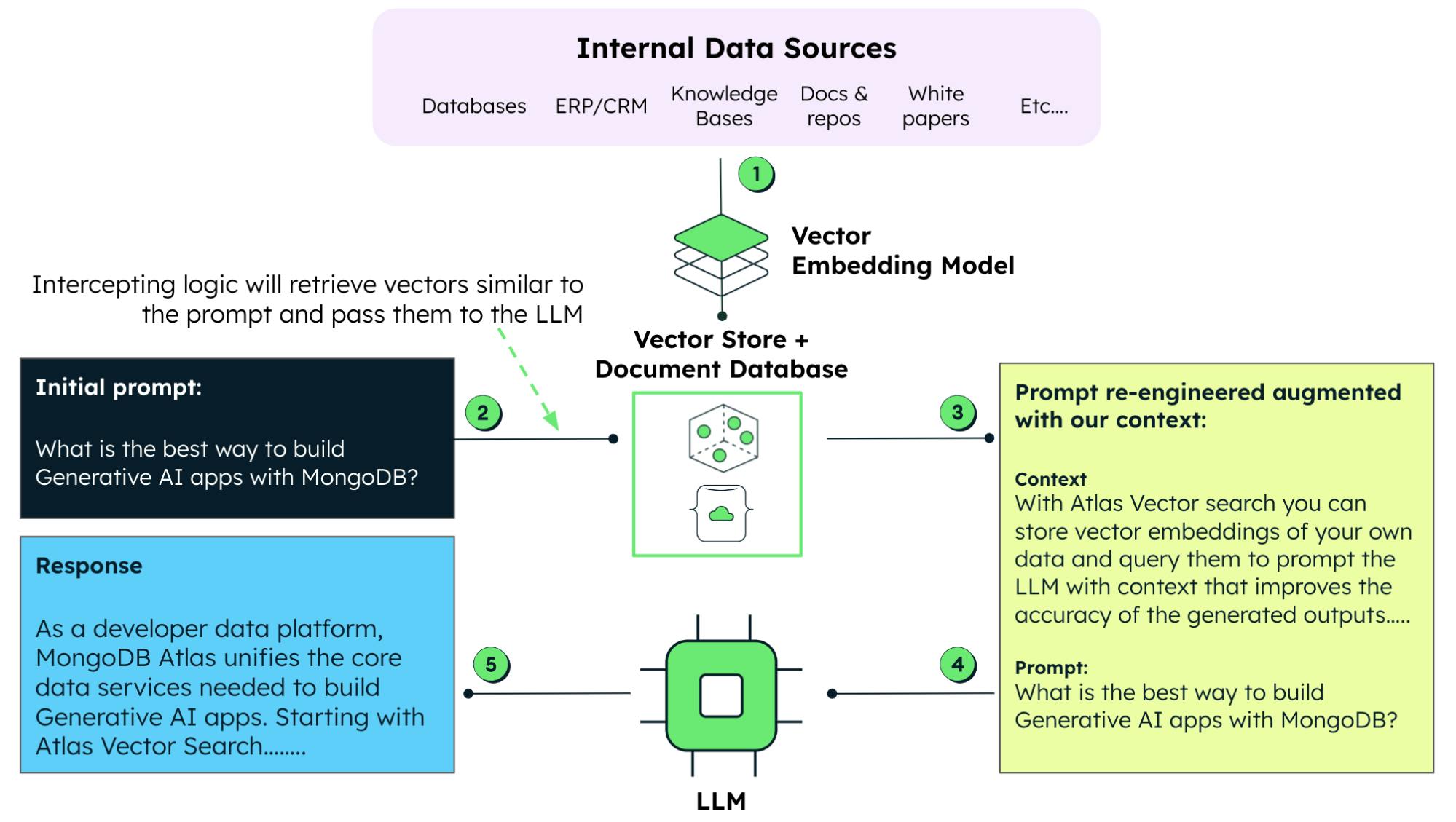
Conforme mencionado acima, o RAG combina o poder do LLM com a recuperação de dados em tempo real.Com o RAG, você não depende mais apenas de dados pré-treinados.Em vez disso, você pode executar uma coleta oportuna de informações relevantes de bancos de dados externos.Isso garante que o conteúdo gerado seja atual e preciso.
Ao trabalhar com modelos generativos, a engenharia de prompts é uma técnica que envolve a elaboração de consultas ou instruções de input específicas para guiar o modelo, adaptando melhor os inputs ou outputs. Com RAG, podemos aprimorar os prompts com dados proprietários, equipando o modelo de IA para gerar respostas relevantes e precisas com esses dados empresariais considerados. Essa abordagem também é preferível ao método demorado e intensivo em recursos de retreinar ou fazer ajuste fino em um LLM com esses dados.
Dificuldades e considerações
É claro que o trabalho com IA generativa não está livre de dificuldades. Se a sua organização pretende explorar o potencial da GenAI, você deve lembrar das questões-chave a seguir.
Necessidade de experiência em dados e enorme poder computacional
Modelos generativos exigem recursos substanciais.Primeiro, você precisa da experiência de cientistas e engenheiros de dados treinados.Com exceção de organizações de dados, a maioria das empresas não tem equipes com a especialização necessária para treinar ou ajustar LLMs.
Quando se trata de recursos de computação, treinar um modelo em dados abrangentes pode exigir semanas ou meses — e isso mesmo usando GPUs ou TPUs poderosos. E embora o ajuste fino de um LLM possa não exigir tanto poder de computação quanto treinar um do zero, ele ainda requer recursos significativos.
O treinamento intensivo em recursos e o ajuste de um LLM é o que torna o RAG uma técnica alternativa atraente para incorporar dados atuais (e proprietários) com os dados existentes disponíveis para um LLM pré-treinado.
Considerações éticas
O aumento da IA generativa também gerou discussões intensas sobre as considerações éticas que acompanham seu desenvolvimento e seu uso. À medida que os aplicativos de IA generativos tornam-se mais presentes e acessíveis ao público, as conversas concentram-se em como:
- Garantir modelos equitativos e livres de tendências
- Proteger contra ataques como envenenamento de modelo ou adulteração de modelo
- Impedir a disseminação de desinformação- Proteger contra o uso indevido de IA generativa (pense em falsificações ou deep fake ou na geração informações enganosas)
- Preservar atribuição
- Promover a transparência com os usuários finais, para saberem quando estão interagindo com um chatbot de IA generativo e não com um humano### Comparison with other AI tools and systems
A disposição e a novidade das ferramentas generativas de IA eclipsaram o panorama de IA mais amplo de ferramentas e sistemas. Muitos assumem erroneamente que a IA generativa é a ferramenta de IA para resolver todos os seus problemas. No entanto, enquanto a IA gerativa se destaca na criação de novo conteúdo, outras ferramentas de IA podem ser mais adequadas para certas tarefas empresariais. Os benefícios da IA gerativa devem — assim como qualquer ferramenta em seu arsenal — ser ponderados contra os benefícios de outras ferramentas.
Dificuldades específicas de
RAG A abordagem de RAG para utilizar um modelo de linguagem grande é poderosa, mas também traz seu próprio conjunto de desafios.
- Escolha do banco de dados vetorial e tecnologias de pesquisa: Em última análise, a eficiência da abordagem RAG depende de sua capacidade de recuperar dados relevantes com rapidez. Isso torna a seleção de um banco de dados vetorial e da tecnologia de busca uma decisão crítica que afetará o desempenho da RAG.
- Coerência dos dados: como a RAG obtém dados em tempo real, é fundamental garantir que o banco de dados esteja atualizado e coerente.
- Complexidade de integração: A integração da RAG com uma LLM adiciona uma camada de complexidade aos seus sistemas. A implementação eficaz de IA generativa com RAG pode exigir conhecimentos especializados.
Apesar dessas dificuldades, o RAG oferece às organizações um meio simples e poderoso de aproveitar seus dados operacionais e de aplicações para obter insights ricos e informar decisões críticas de negócios.
Abordamos o potencial transformador da IA generativa e vimos o poderoso aprimoramento dos dados em tempo real que acompanha a RAG. Para reunir essas tecnologias é preciso ter uma plataforma de dados flexível que ofereça um conjunto de recursos adaptados para aplicativos com GenAI. Para organizações que se aventuram no mundo da IA generativa e da RAG, o MongoDB Atlas será o divisor de águas.
As características principais do MongoDB Atlas incluem:
- Recursos de pesquisa de vetor nativo: O armazenamento e a pesquisa de vetor nativo são integrados no MongoDB Atlas, garantindo recuperação de dados rápida e eficiente para RAG sem a necessidade de um banco de dados adicional para lidar com vetores.
- API unificada e modelo de documento flexível: A API unificada do MongoDB Atlas possibilita que os desenvolvedores combinem a pesquisa vetorial com outros recursos de consulta, como pesquisa estruturada ou pesquisa de texto. Isso, combinado com o modelo de dados de documentos do MongoDB, traz uma flexibilidade incrível para sua implementação.
- Escalabilidade, confiabilidade e segurança: o MongoDB Atlas oferece dimensionamento horizontal para crescer facilmente junto com você (e seus dados). Com tolerância a falhas e dimensionamento horizontal e vertical simples, o MongoDB Atlas garante um serviço ininterrupto, independentemente das demandas de carga de trabalho. E, claro, o MongoDB mostra como prioriza a segurança, permitindo a criptografia de dados líder do setor que pode ser consultada.