Foto de CHUTTERSNAP en Unsplash
El papel de los datos en la IA generativa
La eficacia y versatilidad de cualquier sistema de IA, lo que incluye los sistemas de IA generativa, depende de la calidad, cantidad y diversidad de los datos utilizados para entrenar sus modelos. Veamos algunos aspectos clave de la relación entre los datos y el modelo de IA generativa.
Datos de entrenamiento
Los modelos de IA generativa se entrenan en conjuntos de datos de gran tamaño. Un modelo diseñado para texto puede entrenarse con miles de millones de artículos, mientras que otro modelo diseñado para imágenes puede entrenarse con millones de imágenes. Los LLM necesitan grandes cantidades de datos de machine learning para generar contenidos coherentes y relevantes para el contexto. A medida que los datos son más variados y completos, mejora la capacidad del modelo para comprender y generar una amplia gama de contenido.
En términos generales, más datos se traducen en mejores resultados de modelos. Con un conjunto de datos más grande, los modelos de IA generativa pueden identificar patrones más sutiles, lo que lleva a resultados más precisos y matizados. Sin embargo, la calidad de los datos también es de suma importancia. A menudo, un conjunto de datos más pequeño y de alta calidad puede superar a uno más grande y menos relevante.
Datos sin procesar y complejos
Los datos sin procesar, en especial si son complejos y no estructurados, pueden requerir un procesamiento previo en las primeras etapas del pipeline de datos, antes de poder utilizarlos para el entrenamiento. Este también es el momento en que se validan los datos, para garantizar que sean una representación adecuada y no estén sesgados. Este paso de validación es crucial para evitar resultados sesgados.
Datos etiquetados frente a datos no etiquetados
Los datos etiquetados proporcionan información específica sobre cada punto de datos (por ejemplo, la descripción textual que acompaña a una imagen), mientras que los datos no etiquetados no incluyen anotaciones como ésta. Los modelos generativos a menudo funcionan bien con datos no etiquetados, ya que aún pueden aprender a generar contenido mediante la comprensión de estructuras y patrones inherentes.
Datos patentados
Algunos datos son exclusivos de una organización en particular. Los ejemplos incluyen el historial de pedidos del cliente, las métricas de desempeño de los empleados y los procesos de la empresa. Muchas empresas recopilan estos datos, los hacen anónimos para evitar que se filtren hacia abajo los PII o PHI confidenciales y luego realizan análisis de datos tradicionales. Estos datos contienen una gran cantidad de información que podría extraerse con aún más profundidad si se utilizara para entrenar un modelo generativo. Los productos resultantes se adaptarían a las necesidades y características específicas de esa empresa.
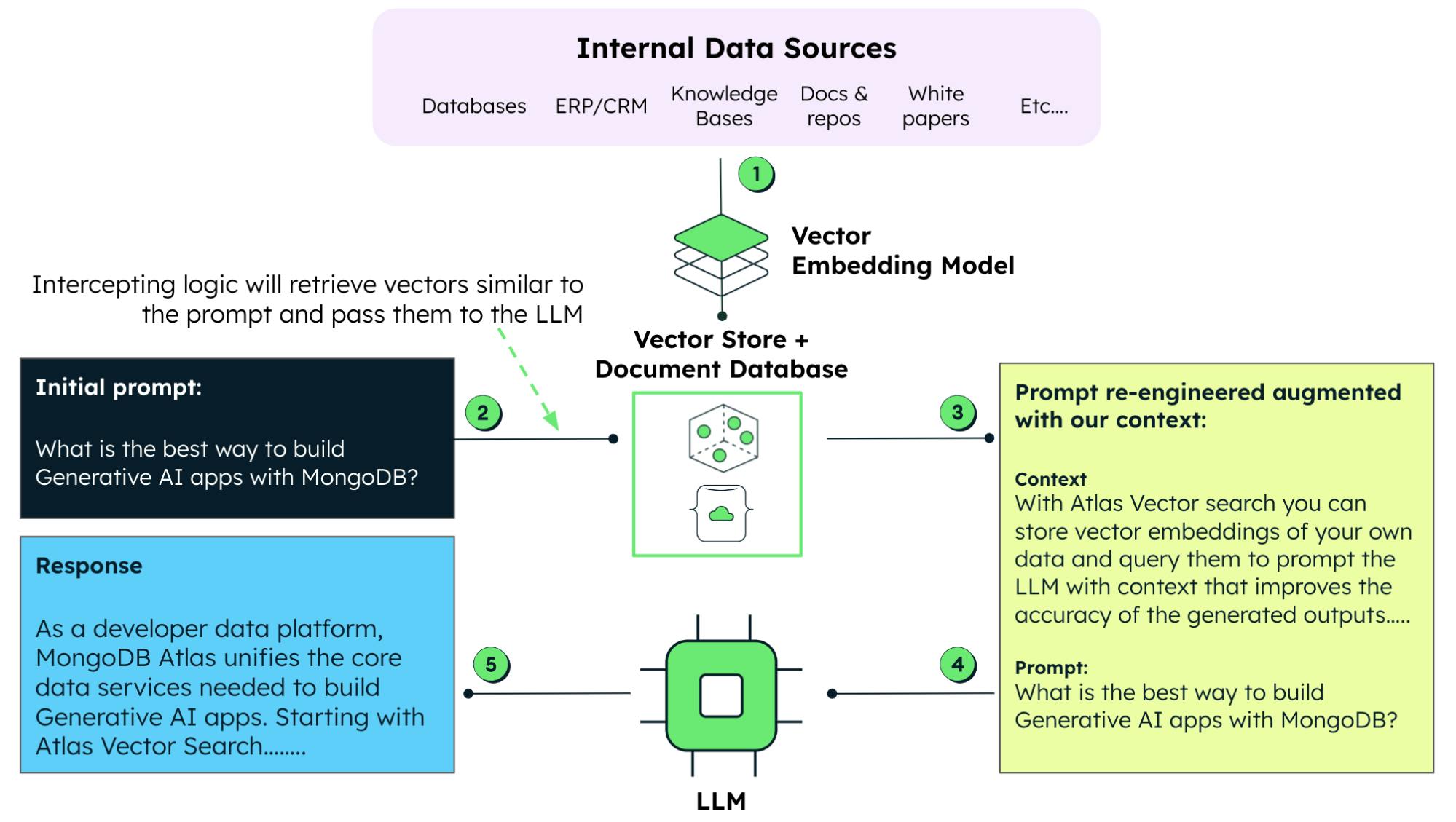
El papel de los datos en RAG
Como ya se mencionó, RAG combina la potencia de un LLM con la recuperación de datos en tiempo real. Con la RAG, ya no depende solo de los datos del entrenamiento previo. En cambio, puede ejecutar justo a tiempo una extracción de información relevante de bases de datos externas. Esto garantiza que el contenido generado sea actual y preciso.
Cómo aumentar los modelos de IA generativa con datos patentados
Cuando se trabaja con modelos generativos, la ingeniería de consulta es una técnica que implica elaborar consultas de entrada específicas o instrucciones para guiar el modelo, para que los resultados o respuestas se adapten mejor. Con la RAG, podemos aumentar las indicaciones con datos patentados y equipar el modelo de IA para generar respuestas relevantes y precisas con los datos empresariales tomados en cuenta. Este enfoque también es preferible al enfoque que requiere mucho tiempo y recursos para volver a entrenar u optimizar un LLM con estos datos.
Retos y consideraciones
Por supuesto, trabajar con IA generativa no está exento de retos. Si su organización está buscando aprovechar el potencial de GenAI, debe tener en cuenta las siguientes cuestiones clave.
Necesidad de experiencia en datos y una enorme potencia de procesamiento
Los modelos generativos requieren recursos esenciales. En primer lugar, necesita la experiencia de científicos de datos e ingenieros capacitados. Con la excepción de las organizaciones de datos, la mayoría de las empresas no tienen equipos con las habilidades especializadas que se necesitarían para entrenar u optimizar los LLM.
Cuando se trata de recursos informáticos, el entrenamiento de un modelo con datos completos puede requerir semanas o meses, y esto pasa incluso si utiliza GPU o TPU potentes. Y aunque la optimización de un LLM puede no requerir tanta potencia de procesamiento como entrenar uno desde cero, aún requiere una significativa cantidad de recursos.
El entrenamiento intensivo con recursos y la optimización de un LLM es lo que convierte a la RAG en una técnica alternativa atractiva para incorporar datos actuales (y patentados) con los datos existentes disponibles a un LLM ya entrenado.
Consideraciones éticas
El auge de la IA generativa también suscitó un intenso debate sobre las consideraciones éticas que conlleva su desarrollo y uso. A medida que las aplicaciones de IA generativa se generalizan y se hacen más accesibles al público, las conversaciones se centraron en cómo:
- Cómo garantizar modelos equitativos y libres de sesgos
- Cómo protegerse contra ataques como la contaminación o manipulación de modelo
- Cómo evitar la propagación de la desinformación
- Cómo protegerse contra el uso indebido de la IA generativa (como los deepfakes o generación de información engañosa)
- Cómo conservar la atribución
- Cómo fomentar la transparencia con los usuarios finales, para que sepan cuándo están interactuando con un chatbot de IA generativa en lugar de con un humano
Comparación con otras herramientas y sistemas de IA
El entusiasmo por las herramientas de IA generativa y su novedad eclipsaron el panorama más amplio de herramientas y sistemas de IA. Muchos se equivocan al suponer que la IA generativa es la herramienta de IA que resolverá todos sus problemas. Sin embargo, aunque la IA generativa se destaca en la creación de nuevos contenidos, otras herramientas de IA podrían resultar más adecuadas para determinadas tareas empresariales. Las ventajas de la IA generativa, al igual que con cualquier otra herramienta de su pila, deben sopesarse con las ventajas de otras herramientas.
Retos específicos de la GAR
El enfoque de la GAR para aprovechar un LLM es potente, pero también conlleva su propio conjunto de retos.
- Elegir vector Database y tecnologías de búsqueda: En última instancia, la eficiencia del enfoque GAR depende de su capacidad para recuperar datos relevantes rápidamente. Esto hace que la selección de una vector database y la tecnología de búsqueda sea una decisión crítica que afectará el rendimiento de RAG.
Coherencia de datos: debido a que la RAG extrae datos en tiempo real, es esencial garantizar que la vector database esté actualizada y sea coherente.
- Complejidad de la integración: la integración de RAG con un LLM agrega una capa de complejidad a sus sistemas. La implementación eficaz de la IA generativa con RAG puede requerir experiencia especializada.
A pesar de estos desafíos, la RAG brinda a las organizaciones un medio sencillo y poderoso para aprovechar sus datos operativos y de aplicaciones para obtener información estratégica rica e informar decisiones comerciales críticas.
MongoDB Atlas para aplicaciones impulsadas por GenAI
Hablamos del potencial transformador de la IA generativa y vimos la poderosa mejora de los datos en tiempo real que viene con RAG. La unión de estas tecnologías requiere una plataforma de datos flexible que ofrezca un conjunto de funciones adaptadas a las aplicaciones impulsadas por GenAI. Para las organizaciones que se avecinan en el mundo de la IA generativa y RAG, MongoDB Atlas será el que cambie las reglas del juego.
Las características principales de MongoDB Atlas incluyen:
- Capacidades nativas de búsqueda de vectores: El almacenamiento y la búsqueda de vectores nativos están integrados en MongoDB Atlas, lo que garantiza una recuperación de datos rápida y eficiente para RAG sin la necesidad de una base de datos adicional para manejar vectores.
- API unificada y modelo de documento flexible: La API unificada de MongoDB Atlas permite a los desarrolladores combinar la búsqueda vectorial con otras capacidades de consulta, como la búsqueda estructurada o la búsqueda de texto. Esto, junto con el modelo de datos de documentos de MongoDB, aporta una flexibilidad increíble a su implementación.
- Escalabilidad, confiabilidad y seguridad: MongoDB Atlas ofrece escalado horizontal para crecer fácilmente a medida que crece (y sus datos). Con tolerancia a fallas y escalado horizontal y vertical simple, MongoDB Atlas garantiza un servicio ininterrumpido independientemente de sus demandas de carga de trabajo. Y, por supuesto, MongoDB muestra cómo prioriza la seguridad habilitando un cifrado de datos líder en la industria que se puede consultar.