就计算、数据和货币成本而言,AI 应用程序通常可以从小规模开始。随着用户参与度的提高,生产应用程序的规模也在不断扩大,与存储和检索大量数据相关的成本等关键因素成为重要的优化机会。这些挑战可以通过专注于以下几个方面来解决:
高效的向量搜索算法
自动化量化过程
优化的嵌入策略
检索增强生成 (RAG) 和基于代理的系统均依赖于向量数据——如图像、视频和文本等数据对象的数值表示——以执行语义相似性搜索。使用 RAG 或代理驱动工作流的系统必须高效地处理海量、高维数据集,以保持快速响应时间、最大限度减少检索延迟并控制基础设施成本。
关于教程
本教程向您传授设计、部署和管理大规模高级 AI 工作负载所需的技术,确保实现最佳性能和成本效率。
具体来说,在本教程中,您将学习如何:
使用 Voyage AI 的
voyage-3-large生成嵌入,这是一种通用的多语言嵌入模型,也具有量化感知能力,并将其导入到 MongoDB 数据库中。自动将嵌入量化为较低精度的数据类型,优化内存使用和查询延迟。
运行查询,比较浮点 32、整数 8 和二进制嵌入,权衡数据类型的精度与效率和检索准确性。
测量量化嵌入的召回率(也称为保持率),该指标评估量化 ANN 搜索在检索与全精度 ENN 搜索相同文档方面的效果。
注意
二进制量化在需要降低资源消耗的场景中是最佳选择,但可能需要进行重新评分以解决精度损失的问题。
标量量化提供了一种实用的折中方案,适用于大多数需要在性能和精度之间取得平衡的应用场景。
浮点 32 可确保最大保真度,但性能和内存开销最大,因此不太适合大规模或延迟敏感的系统。
先决条件
如要完成本教程,您必须具备以下条件:
步骤
导入所需的库并设置环境变量。
通过保存扩展名为
.ipynb的文件来创建交互式 Python 笔记本。安装库。
在本教程中,您必须导入以下库:
pymongo
MongoDB Python 驱动程序,用于连接到您的集群、创建索引和运行查询。
voyageai
Voyage AI Python 客户端 用于生成数据嵌入。
pandas
数据操作和分析工具用于加载数据并为向量搜索做好准备。
数据集
Hugging Face 库提供访问现成数据集的功能。
matplotlib
绘制和可视化库,使数据可视化。
要安装这些库,请运行以下命令:
pip install --quiet -U pymongo voyageai pandas datasets matplotlib 安全地获取和设置环境变量。
以下
set_env_securely辅助函数安全地获取和设置环境变量。复制、粘贴并运行以下代码,并在出现提示时设立密钥值,例如您的 Voyage AI API密钥 和集群连接字符串。1 import getpass 2 import os 3 import voyageai 4 5 # Function to securely get and set environment variables 6 def set_env_securely(var_name, prompt): 7 value = getpass.getpass(prompt) 8 os.environ[var_name] = value 9 10 # Environment Variables 11 set_env_securely("VOYAGE_API_KEY", "Enter your Voyage API Key: ") 12 set_env_securely("MONGO_URI", "Enter your MongoDB URI: ") 13 MONGO_URI = os.environ.get("MONGO_URI") 14 if not MONGO_URI: 15 raise ValueError("MONGO_URI not set in environment variables.") 16 17 # Voyage Client 18 voyage_client = voyageai.Client()
将数据导入集群。
在此步骤中,您可以从以下数据集中加载最多 250000 个文档:
wikipedia-22-12-en-voyage-embed 数据集包含维基百科文章片段,这些片段具有从 Voyage AI 的 voyage-3-large 模型预先生成的 1024 维浮点32嵌入。这是包含元数据的主节点 (primary node in the replica set)文档集合。该数据集可作为多样化向量语料库,用于测试语义搜索中向量量化的效果。此数据集中的每个文档都包含以下字段:
| 文档的 ObjectId ( |
| 文档的唯一标识符。 |
| 文档的标题。 |
| 文档的内容。 |
| 文档的 URL。 |
| 文档的 Wikipedia ID。 |
| 文档浏览次数。 |
| 文档中的段落 ID。 |
| 文档中语言的数量。 |
| 1024 维向量嵌入用于该文档。 |
wikipedia-22-12-en-annotation 数据集包含召回率测量函数的带注释参考数据。该数据用作基准数据集,以验证准确性并评估量化对检索质量的影响。此数据集中的每个文档都包含以下字段,这些字段是用于评估向量搜索性能的基本事实:
| 文档的 ObjectId ( |
| 文档的唯一标识符。 |
| 文档的 Wikipedia ID。 |
| 包含关键短语、问题、部分信息和句子的文档查询。 |
| 用于评估文档向量搜索性能的关键短语数组。 |
| 用于评估文档向量搜索性能的部分信息数组。 |
| 用于评估文档向量搜索性能的问题数组。 |
| 用于评估文档向量搜索性能的句子数组。 |
定义将数据加载到您的集群中的函数。
在您的笔记本中复制、粘贴并运行以下代码。示例代码定义了以下函数:
generate_bson_vector将数据集中的嵌入转换为 BSON 二进制向量,以便高效存储和处理向量。get_mongo_client获取集群连接字符串。insert_dataframe_into_collection将数据引入集群。
1 import pandas as pd 2 from datasets import load_dataset 3 from bson.binary import Binary, BinaryVectorDtype 4 import pymongo 5 6 # Connect to Cluster 7 def get_mongo_client(uri): 8 """Connect to MongoDB and confirm the connection.""" 9 client = pymongo.MongoClient(uri) 10 if client.admin.command("ping").get("ok") == 1.0: 11 print("Connected to MongoDB successfully.") 12 return client 13 print("Failed to connect to MongoDB.") 14 return None 15 16 # Generate BSON Vector 17 def generate_bson_vector(array, data_type): 18 """Convert an array to BSON vector format.""" 19 array = [float(val) for val in eval(array)] 20 return Binary.from_vector(array, BinaryVectorDtype(data_type)) 21 22 # Load Datasets 23 def load_and_prepare_data(dataset_name, amount): 24 """Load and prepare streaming datasets for DataFrame.""" 25 data = load_dataset(dataset_name, streaming=True, split="train").take(amount) 26 return pd.DataFrame(data) 27 28 # Insert datasets into MongoDB Collection 29 def insert_dataframe_into_collection(df, collection): 30 """Insert Dataset records into MongoDB collection.""" 31 collection.insert_many(df.to_dict("records")) 32 print(f"Inserted {len(df)} records into '{collection.name}' collection.") 将数据加载到集群。
在笔记本中复制、粘贴并运行以下代码,以将数据集加载到集群中。此代码执行以下操作:
获取数据集。
将嵌入转换为 BSON 格式。
在集群中创建集合并插入数据。
1 import pandas as pd 2 from bson.binary import Binary, BinaryVectorDtype 3 from pymongo.errors import CollectionInvalid 4 5 wikipedia_data_df = load_and_prepare_data("MongoDB/wikipedia-22-12-en-voyage-embed", amount=250000) 6 wikipedia_annotation_data_df = load_and_prepare_data("MongoDB/wikipedia-22-12-en-annotation", amount=250000) 7 wikipedia_annotation_data_df.drop(columns=["_id"], inplace=True) 8 9 # Convert embeddings to BSON format 10 wikipedia_data_df["embedding"] = wikipedia_data_df["embedding"].apply( 11 lambda x: generate_bson_vector(x, BinaryVectorDtype.FLOAT32) 12 ) 13 14 # MongoDB Setup 15 mongo_client = get_mongo_client(MONGO_URI) 16 DB_NAME = "testing_datasets" 17 db = mongo_client[DB_NAME] 18 19 collections = { 20 "wikipedia-22-12-en": wikipedia_data_df, 21 "wikipedia-22-12-en-annotation": wikipedia_annotation_data_df, 22 } 23 24 # Create Collections and Insert Data 25 for collection_name, df in collections.items(): 26 if collection_name not in db.list_collection_names(): 27 try: 28 db.create_collection(collection_name) 29 print(f"Collection '{collection_name}' created successfully.") 30 except CollectionInvalid: 31 print(f"Error creating collection '{collection_name}'.") 32 else: 33 print(f"Collection '{collection_name}' already exists.") 34 35 # Clear collection and insert fresh data 36 collection = db[collection_name] 37 collection.delete_many({}) 38 insert_dataframe_into_collection(df, collection) Connected to MongoDB successfully. Collection 'wikipedia-22-12-en' created successfully. Inserted 250000 records into 'wikipedia-22-12-en' collection. Collection 'wikipedia-22-12-en-annotation' created successfully. Inserted 87200 records into 'wikipedia-22-12-en-annotation' collection. 重要提示:将嵌入转换为BSON向量并将数据集引入集群可能需要一些时间。
登录集群并在 数据浏览器中目视检查集合,验证数据集是否已成功加载。
在集合上创建MongoDB Vector Search 索引。
在此步骤中,您需要在 embedding 字段上创建以下三个索引:
标量量化索引 | 使用标量量化方法对嵌入进行量化。 |
二进制量化索引 | 使用二进制量化方法对嵌入进行量化。 |
Float32 ANN Index | 使用浮点 32 ANN 方法量化嵌入。 |
定义用于创建MongoDB Vector Search索引的函数。
在您的笔记本中复制、粘贴并运行以下内容:
1 import time 2 from pymongo.operations import SearchIndexModel 3 4 def setup_vector_search_index(collection, index_definition, index_name="vector_index"): 5 new_vector_search_index_model = SearchIndexModel( 6 definition=index_definition, name=index_name, type="vectorSearch" 7 ) 8 9 # Create the new index 10 try: 11 result = collection.create_search_index(model=new_vector_search_index_model) 12 print(f"Creating index '{index_name}'...") 13 14 # Wait for initial sync to complete 15 print("Polling to check if the index is ready. This may take a couple of minutes.") 16 predicate=None 17 if predicate is None: 18 predicate = lambda index: index.get("queryable") is True 19 while True: 20 indices = list(collection.list_search_indexes(result)) 21 if len(indices) and predicate(indices[0]): 22 break 23 time.sleep(5) 24 print(f"Index '{index_name}' is ready for querying.") 25 return result 26 27 except Exception as e: 28 print(f"Error creating new vector search index '{index_name}': {e!s}") 29 return None 定义索引。
以下索引配置实现了不同的量化策略:
vector_index_definition_scalar_quantized此配置使用标量量化 (int8),其:
将每个向量维度从 32 位浮点数转换为 8 位整数
在精度和内存效率之间保持良好的平衡
适用于大多数需要内存优化的生产用例
vector_index_definition_binary_quantized此配置使用二进制量化(int1),其:
将每个向量维度压缩为单个比特位
提供最大内存效率
非常适合内存紧张的超大规模部署
自动量化在创建这些索引时透明地进行, MongoDB Vector Search 在索引创建和搜索操作期间处理从 float32 到指定量化格式的转换。
vector_index_definition_float32_ann索引配置通过使用cosine相似性函数来索引1024维度的全保真向量。1 # Scalar Quantization 2 vector_index_definition_scalar_quantized = { 3 "fields": [ 4 { 5 "type": "vector", 6 "path": "embedding", 7 "quantization": "scalar", 8 "numDimensions": 1024, 9 "similarity": "cosine", 10 } 11 ] 12 } 13 # Binary Quantization 14 vector_index_definition_binary_quantized = { 15 "fields": [ 16 { 17 "type": "vector", 18 "path": "embedding", 19 "quantization": "binary", 20 "numDimensions": 1024, 21 "similarity": "cosine", 22 } 23 ] 24 } 25 # Float32 Embeddings 26 vector_index_definition_float32_ann = { 27 "fields": [ 28 { 29 "type": "vector", 30 "path": "embedding", 31 "numDimensions": 1024, 32 "similarity": "cosine", 33 } 34 ] 35 } 使用
setup_vector_search_index函数创建标量、二进制和浮点32索引。为索引设置集合名称和索引名称。
wiki_data_collection = db["wikipedia-22-12-en"] wiki_annotation_data_collection = db["wikipedia-22-12-en-annotation"] vector_search_scalar_quantized_index_name = "vector_index_scalar_quantized" vector_search_binary_quantized_index_name = "vector_index_binary_quantized" vector_search_float32_ann_index_name = "vector_index_float32_ann" 创建MongoDB Vector Search 索引。
1 setup_vector_search_index( 2 wiki_data_collection, 3 vector_index_definition_scalar_quantized, 4 vector_search_scalar_quantized_index_name, 5 ) 6 setup_vector_search_index( 7 wiki_data_collection, 8 vector_index_definition_binary_quantized, 9 vector_search_binary_quantized_index_name, 10 ) 11 setup_vector_search_index( 12 wiki_data_collection, 13 vector_index_definition_float32_ann, 14 vector_search_float32_ann_index_name, 15 ) Creating index 'vector_index_scalar_quantized'... Polling to check if the index is ready. This may take a couple of minutes. Index 'vector_index_scalar_quantized' is ready for querying. Creating index 'vector_index_binary_quantized'... Polling to check if the index is ready. This may take a couple of minutes. Index 'vector_index_binary_quantized' is ready for querying. Creating index 'vector_index_float32_ann'... Polling to check if the index is ready. This may take a couple of minutes. Index 'vector_index_float32_ann' is ready for querying. vector_index_float32_ann' 重要提示:操作可能需要几分钟才能完成。索引必须处于 Ready 状态才能在查询中使用。
登录集群并目视检查 Atlas Search 中的索引,验证索引创建是否成功。
定义函数以生成嵌入并使用MongoDB Vector Search 索引查询集合。
此代码定义了以下函数:
get_embedding()函数使用 Voyage AI 的voyage-3-large嵌入模型,为给定文本生成 1024 维度的嵌入。custom_vector_search函数接受以下输入参数并返回向量搜索操作的结果。user_query查询文本字符串,用于生成嵌入。
collection要搜索的 MongoDB 集合。
embedding_path集合中包含嵌入的字段。
vector_search_index_name用于查询的索引名称。
top_k要返回的结果中顶级文档的数量。
num_candidates要考虑的候选人数。
use_full_precision执行 ANN(如果是
False)或 ENN(如果是True)搜索的标记。默认情况下,ANN 搜索的
use_full_precision值设置为False。将use_full_precision的值设置为True以执行 ENN 搜索。具体来说,此函数执行以下操作:
为查询文本生成嵌入。
构建
$vectorSearch阶段配置搜索类型
指定要返回的集合中的字段
在收集性能统计数据后执行管道
返回结果
1 def get_embedding(text, task_prefix="document"): 2 """Fetch embedding for a given text using Voyage AI.""" 3 if not text.strip(): 4 print("Empty text provided for embedding.") 5 return [] 6 result = voyage_client.embed([text], model="voyage-3-large", input_type=task_prefix) 7 return result.embeddings[0] 8 9 def custom_vector_search( 10 user_query, 11 collection, 12 embedding_path, 13 vector_search_index_name="vector_index", 14 top_k=5, 15 num_candidates=25, 16 use_full_precision=False, 17 ): 18 19 # Generate embedding for the user query 20 query_embedding = get_embedding(user_query, task_prefix="query") 21 22 if query_embedding is None: 23 return "Invalid query or embedding generation failed." 24 25 # Define the vector search stage 26 vector_search_stage = { 27 "$vectorSearch": { 28 "index": vector_search_index_name, 29 "queryVector": query_embedding, 30 "path": embedding_path, 31 "limit": top_k, 32 } 33 } 34 35 # Add numCandidates only for approximate search 36 if not use_full_precision: 37 vector_search_stage["$vectorSearch"]["numCandidates"] = num_candidates 38 else: 39 # Set exact to true for exact search using full precision float32 vectors and running exact search 40 vector_search_stage["$vectorSearch"]["exact"] = True 41 42 project_stage = { 43 "$project": { 44 "_id": 0, 45 "title": 1, 46 "text": 1, 47 "wiki_id": 1, 48 "url": 1, 49 "score": { 50 "$meta": "vectorSearchScore" 51 }, 52 } 53 } 54 55 # Define the aggregate pipeline with the vector search stage and additional stages 56 pipeline = [vector_search_stage, project_stage] 57 58 # Execute the explain command 59 explain_result = collection.database.command( 60 "explain", 61 {"aggregate": collection.name, "pipeline": pipeline, "cursor": {}}, 62 verbosity="executionStats", 63 ) 64 65 # Extract the execution time 66 vector_search_explain = explain_result["stages"][0]["$vectorSearch"] 67 execution_time_ms = vector_search_explain["explain"]["query"]["stats"]["context"][ 68 "millisElapsed" 69 ] 70 71 # Execute the actual query 72 results = list(collection.aggregate(pipeline)) 73 74 return {"results": results, "execution_time_ms": execution_time_ms}
运行MongoDB Vector Search查询以评估搜索性能。
以下查询在不同的量化策略下执行向量搜索,测量标量量化、二进制量化和全精度(float32)向量的性能指标,同时捕获每个精度级别的延迟测量值,并将结果格式标准化,以便进行分析比较。它使用 Voyage AI 生成的嵌入向量来处理查询字符串“如何提升工作效率以实现最大产出。”
该查询将关键的基本性能指标存储在 results 变量中,包括精度级别(标量、二进制、浮点32)、结果集大小(top_k)、查询延迟(以毫秒为单位)和检索的文档内容,提供全面的指标以评估不同量化策略的搜索性能。
1 vector_search_indices = [ 2 vector_search_float32_ann_index_name, 3 vector_search_scalar_quantized_index_name, 4 vector_search_binary_quantized_index_name, 5 ] 6 7 # Random query 8 user_query = "How do I increase my productivity for maximum output" 9 test_top_k = 5 10 test_num_candidates = 25 11 12 # Result is a list of dictionaries with the following headings: precision, top_k, latency_ms, results 13 results = [] 14 15 for vector_search_index in vector_search_indices: 16 # Conduct a vector search operation using scalar quantized 17 vector_search_results = custom_vector_search( 18 user_query, 19 wiki_data_collection, 20 embedding_path="embedding", 21 vector_search_index_name=vector_search_index, 22 top_k=test_top_k, 23 num_candidates=test_num_candidates, 24 use_full_precision=False, 25 ) 26 # Include the precision in the results 27 precision = vector_search_index.split("vector_index")[1] 28 precision = precision.replace("quantized", "").capitalize() 29 30 results.append( 31 { 32 "precision": precision, 33 "top_k": test_top_k, 34 "num_candidates": test_num_candidates, 35 "latency_ms": vector_search_results["execution_time_ms"], 36 "results": vector_search_results["results"][0], # Just taking the first result, modify this to include more results if needed 37 } 38 ) 39 40 # Conduct a vector search operation using full precision 41 precision = "Float32_ENN" 42 vector_search_results = custom_vector_search( 43 user_query, 44 wiki_data_collection, 45 embedding_path="embedding", 46 vector_search_index_name="vector_index_scalar_quantized", 47 top_k=test_top_k, 48 num_candidates=test_num_candidates, 49 use_full_precision=True, 50 ) 51 52 results.append( 53 { 54 "precision": precision, 55 "top_k": test_top_k, 56 "num_candidates": test_num_candidates, 57 "latency_ms": vector_search_results["execution_time_ms"], 58 "results": vector_search_results["results"][0], # Just taking the first result, modify this to include more results if needed 59 } 60 ) 61 62 # Convert the results to a pandas DataFrame with the headings: precision, top_k, latency_ms 63 results_df = pd.DataFrame(results) 64 results_df.columns = ["precision", "top_k", "num_candidates", "latency_ms", "results"] 65 66 # To display the results: 67 results_df.head()
precision top_k num_candidates latency_ms results 0 _float32_ann 5 25 1659.498601 {'title': 'Henry Ford', 'text': 'Ford had deci... 1 _scalar_ 5 25 951.537687 {'title': 'Gross domestic product', 'text': 'F... 2 _binary_ 5 25 344.585193 {'title': 'Great Depression', 'text': 'The fir... 3 Float32_ENN 5 25 0.231693 {'title': 'Great Depression', 'text': 'The fir...
结果中的性能指标显示了不同精度级别的延迟差异。这表明,虽然量化提供了显著的性能改进,但在精度和检索速度之间存在明显的权衡,与量化后的对应物相比,全精度浮点32操作需要显著更多的计算时间。
使用不同的 top-k 和 num_candidates 值测量延迟。
以下查询介绍了一个系统延迟测量框架,该框架可评估不同精度级别和检索规模的向量搜索性能。参数 top-k 不仅决定返回结果的数量,还设置了 MongoDB 的 HNSW 图表搜索中的 numCandidates 参数。
numCandidates值会影响 MongoDB Vector Search 在 ANN 搜索期间探索的 HNSW 图表中的节点数量。在这里,较高的值会增加找到真正最近邻的可能性,但需要更多的计算时间。
定义函数,将
latency_ms格式化为人类可读的格式。1 from datetime import timedelta 2 3 def format_time(ms): 4 """Convert milliseconds to a human-readable format""" 5 delta = timedelta(milliseconds=ms) 6 7 # Extract minutes, seconds, and milliseconds with more precision 8 minutes = delta.seconds // 60 9 seconds = delta.seconds % 60 10 milliseconds = round(ms % 1000, 3) # Keep 3 decimal places for milliseconds 11 12 # Format based on duration 13 if minutes > 0: 14 return f"{minutes}m {seconds}.{milliseconds:03.0f}s" 15 elif seconds > 0: 16 return f"{seconds}.{milliseconds:03.0f}s" 17 else: 18 return f"{milliseconds:.3f}ms" 定义函数以测量向量搜索查询的延迟。
以下函数接受
user_query、collection、vector_search_index_name、use_full_precision值、top_k_values值和num_candidates_values值作为输入,并返回向量搜索的结果。在此,请注意以下内容:随着
top_k和num_candidates值的增加,延迟时间增加,因为向量搜索操作会使用更多的文档,导致搜索时间更长。完全保真搜索 (
use_full_precision=True) 的延迟高于近似搜索 (use_full_precision=False),因为完全保真搜索需要更长时间来搜索整个数据集,并使用全精度浮点32向量。量化搜索的延迟低于全精度搜索,因为量化搜索使用了近似搜索和量化向量。
1 def measure_latency_with_varying_topk( 2 user_query, 3 collection, 4 vector_search_index_name="vector_index_scalar_quantized", 5 use_full_precision=False, 6 top_k_values=[5, 10, 100], 7 num_candidates_values=[25, 50, 100, 200, 500, 1000, 2000, 5000, 10000], 8 ): 9 results_data = [] 10 11 # Conduct vector search operation for each (top_k, num_candidates) combination 12 for top_k in top_k_values: 13 for num_candidates in num_candidates_values: 14 # Skip scenarios where num_candidates < top_k 15 if num_candidates < top_k: 16 continue 17 18 # Construct the precision name 19 precision_name = vector_search_index_name.split("vector_index")[1] 20 precision_name = precision_name.replace("quantized", "").capitalize() 21 22 # If use_full_precision is true, then the precision name is "_float32_" 23 if use_full_precision: 24 precision_name = "_float32_ENN" 25 26 # Perform the vector search 27 vector_search_results = custom_vector_search( 28 user_query=user_query, 29 collection=collection, 30 embedding_path="embedding", 31 vector_search_index_name=vector_search_index_name, 32 top_k=top_k, 33 num_candidates=num_candidates, 34 use_full_precision=use_full_precision, 35 ) 36 37 # Extract the execution time (latency) 38 latency_ms = vector_search_results["execution_time_ms"] 39 40 # Store results 41 results_data.append( 42 { 43 "precision": precision_name, 44 "top_k": top_k, 45 "num_candidates": num_candidates, 46 "latency_ms": latency_ms, 47 } 48 ) 49 50 return results_data 运行MongoDB Vector Search查询以测量延迟。
延迟评估操作通过在所有量化策略中执行搜索、测试多个结果集大小、捕获标准化性能指标,并聚合结果进行比较分析,从而能够对不同配置和检索负载下的向量搜索行为进行详细评估。
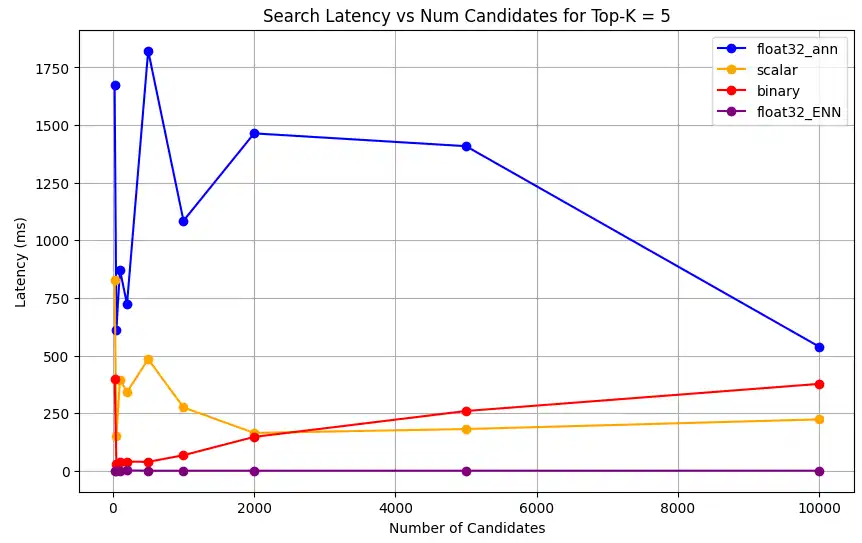
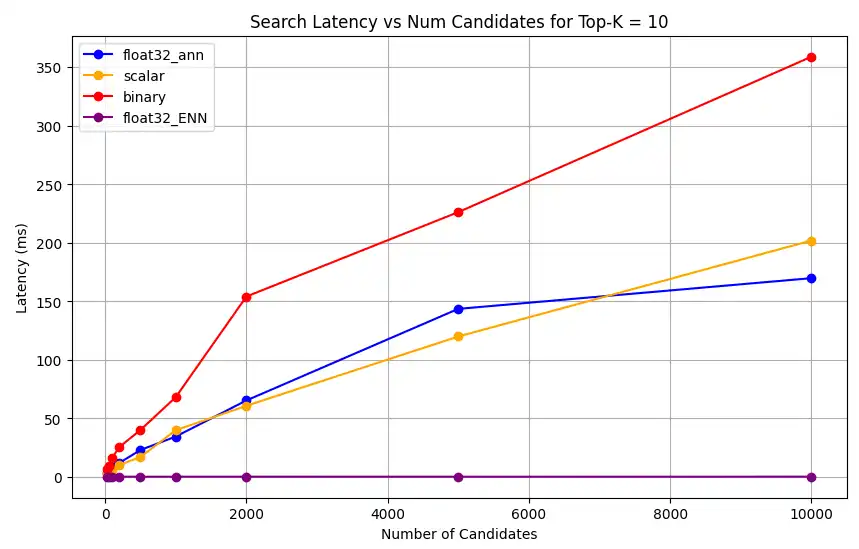
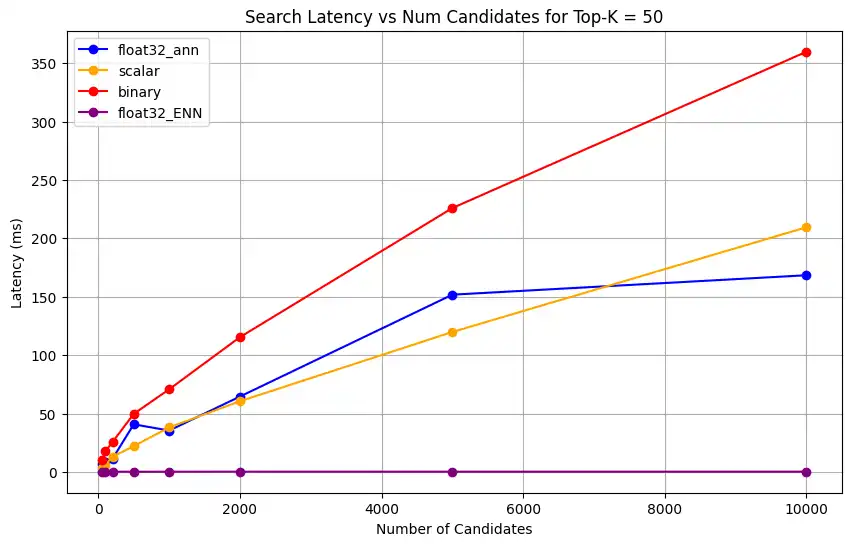
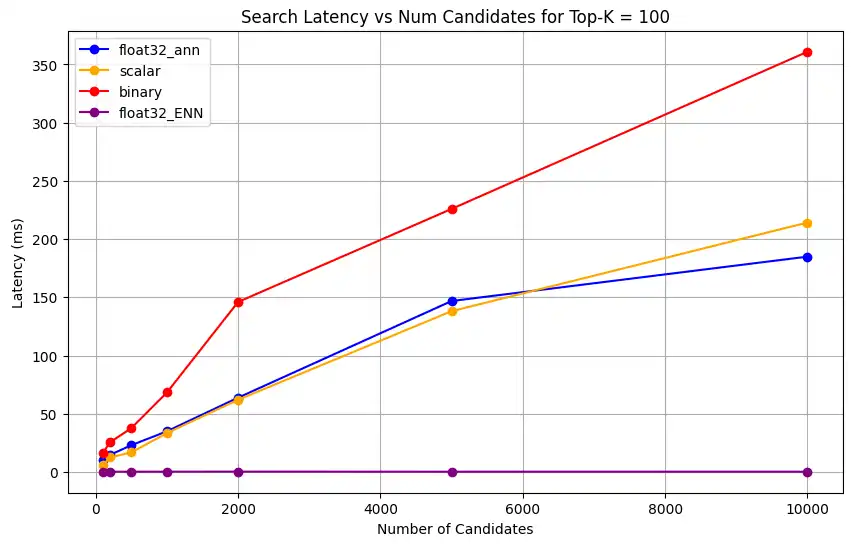
1 # Run the measurements 2 user_query = "How do I increase my productivity for maximum output" 3 top_k_values = [5, 10, 50, 100] 4 num_candidates_values = [25, 50, 100, 200, 500, 1000, 2000, 5000, 10000] 5 6 latency_results = [] 7 8 for vector_search_index in vector_search_indices: 9 latency_results.append( 10 measure_latency_with_varying_topk( 11 user_query, 12 wiki_data_collection, 13 vector_search_index_name=vector_search_index, 14 use_full_precision=False, 15 top_k_values=top_k_values, 16 num_candidates_values=num_candidates_values, 17 ) 18 ) 19 20 # Conduct vector search operation using full precision 21 latency_results.append( 22 measure_latency_with_varying_topk( 23 user_query, 24 wiki_data_collection, 25 vector_search_index_name="vector_index_scalar_quantized", 26 use_full_precision=True, 27 top_k_values=top_k_values, 28 num_candidates_values=num_candidates_values, 29 ) 30 ) 31 32 # Combine all results into a single DataFrame 33 all_latency_results = pd.concat([pd.DataFrame(latency_results)]) Top-K: 5, NumCandidates: 25, Latency: 1672.855906 ms, Precision: _float32_ann ... Top-K: 100, NumCandidates: 10000, Latency: 184.905389 ms, Precision: _float32_ann Top-K: 5, NumCandidates: 25, Latency: 828.45855 ms, Precision: _scalar_ ... Top-K: 100, NumCandidates: 10000, Latency: 214.199836 ms, Precision: _scalar_ Top-K: 5, NumCandidates: 25, Latency: 400.160243 ms, Precision: _binary_ ... Top-K: 100, NumCandidates: 10000, Latency: 360.908558 ms, Precision: _binary_ Top-K: 5, NumCandidates: 25, Latency: 0.239107 ms, Precision: _float32_ENN ... Top-K: 100, NumCandidates: 10000, Latency: 0.179203 ms, Precision: _float32_ENN 延迟测量结果显示,不同精度类型之间存在明显的性能层次结构,其中二进制量化展现出最快的检索时间,其次是标量量化。全精度浮点数 32 ANN 运算显示出明显更高的延迟。随着 Top-K 值增加,量化搜索与全精度搜索之间的性能差距变得更加明显。浮点32 ENN 运算最慢,但提供最高精度的结果。
绘制搜索延迟与不同 top-k 值的关系图。
1 import matplotlib.pyplot as plt 2 3 # Map your precision field to the labels and colors you want in the legend 4 precision_label_map = { 5 "_scalar_": "scalar", 6 "_binary_": "binary", 7 "_float32_ann": "float32_ann", 8 "_float32_ENN": "float32_ENN", 9 } 10 11 precision_color_map = { 12 "_scalar_": "orange", 13 "_binary_": "red", 14 "_float32_ann": "blue", 15 "_float32_ENN": "purple", 16 } 17 18 # Flatten all measurements and find the unique top_k values 19 all_measurements = [m for precision_list in latency_results for m in precision_list] 20 unique_topk = sorted(set(m["top_k"] for m in all_measurements)) 21 22 # For each top_k, create a separate plot 23 for k in unique_topk: 24 plt.figure(figsize=(10, 6)) 25 26 # For each precision type, filter out measurements for the current top_k value 27 for measurements in latency_results: 28 # Filter measurements with top_k equal to the current k 29 filtered = [m for m in measurements if m["top_k"] == k] 30 if not filtered: 31 continue 32 33 # Extract x (num_candidates) and y (latency) values 34 x = [m["num_candidates"] for m in filtered] 35 y = [m["latency_ms"] for m in filtered] 36 37 # Determine the precision, label, and color from the first measurement in this filtered list 38 precision = filtered[0]["precision"] 39 label = precision_label_map.get(precision, precision) 40 color = precision_color_map.get(precision, "blue") 41 42 # Plot the line for this precision type 43 plt.plot(x, y, marker="o", color=color, label=label) 44 45 # Label axes and add title including the top_k value 46 plt.xlabel("Number of Candidates") 47 plt.ylabel("Latency (ms)") 48 plt.title(f"Search Latency vs Num Candidates for Top-K = {k}") 49 50 # Add a legend and grid, then show the plot 51 plt.legend() 52 plt.grid(True) 53 plt.show() 该代码会返回以下延迟图表,说明随着
top-k(检索结果数量)的增加,向量搜索文档检索在二进制、标量和浮点 32 等不同嵌入精度类型下的表现:



测量表示容量和保留率。
以下查询衡量MongoDB Vector Search 从地面实况数据集中检索相关文档的效率。它的计算公式为正确找到的相关文档与参考标准中相关文档总数的比率(找到/总数)。示例,如果某个查询在参考标准中包含 5 个相关文档,并且MongoDB Vector Search 找到其中 4 个,则召回率为 0.8或 80%。
定义一个函数,用于衡量向量搜索操作的表征能力和保持率。该函数执行以下操作:
使用全精度浮点 32 向量和 ENN 搜索来创建基线搜索。
使用量化向量和近似最近邻 (ANN)搜索创建量化搜索。
计算量化搜索相对于基线搜索的保留率。
对于量化搜索,表征率必须保持在合理范围内。如果表征能力不足,则意味着向量搜索操作无法准确捕捉查询的语义信息,可能导致检索结果失准。这表明量化效果不佳,所使用的初始嵌入模型对量化过程无效。我们建议使用具有量化意识的嵌入模型,即在训练过程中,对模型进行专门优化,以便在量化后仍能保持其语义属性。
1 def measure_representational_capacity_retention_against_float_enn( 2 ground_truth_collection, 3 collection, 4 quantized_index_name, # This is used for both the quantized search and (with use_full_precision=True) for the baseline. 5 top_k_values, # List/array of top-k values to test. 6 num_candidates_values, # List/array of num_candidates values to test. 7 num_queries_to_test=1, 8 ): 9 retention_results = {"per_query_retention": {}} 10 overall_retention = {} # overall_retention[top_k][num_candidates] = [list of retention values] 11 12 # Initialize overall retention structure 13 for top_k in top_k_values: 14 overall_retention[top_k] = {} 15 for num_candidates in num_candidates_values: 16 if num_candidates < top_k: 17 continue 18 overall_retention[top_k][num_candidates] = [] 19 20 # Extract and store the precision name from the quantized index name. 21 precision_name = quantized_index_name.split("vector_index")[1] 22 precision_name = precision_name.replace("quantized", "").capitalize() 23 retention_results["precision_name"] = precision_name 24 retention_results["top_k_values"] = top_k_values 25 retention_results["num_candidates_values"] = num_candidates_values 26 27 # Load ground truth annotations 28 ground_truth_annotations = list( 29 ground_truth_collection.find().limit(num_queries_to_test) 30 ) 31 print(f"Loaded {len(ground_truth_annotations)} ground truth annotations") 32 33 # Process each ground truth annotation 34 for annotation in ground_truth_annotations: 35 # Use the ground truth wiki_id from the annotation. 36 ground_truth_wiki_id = annotation["wiki_id"] 37 38 # Process only queries that are questions. 39 for query_type, queries in annotation["queries"].items(): 40 if query_type.lower() not in ["question", "questions"]: 41 continue 42 43 for query in queries: 44 # Prepare nested dict for this query 45 if query not in retention_results["per_query_retention"]: 46 retention_results["per_query_retention"][query] = {} 47 48 # For each valid combination of top_k and num_candidates 49 for top_k in top_k_values: 50 if top_k not in retention_results["per_query_retention"][query]: 51 retention_results["per_query_retention"][query][top_k] = {} 52 for num_candidates in num_candidates_values: 53 if num_candidates < top_k: 54 continue 55 56 # Baseline search: full precision using ENN (Float32) 57 baseline_result = custom_vector_search( 58 user_query=query, 59 collection=collection, 60 embedding_path="embedding", 61 vector_search_index_name=quantized_index_name, 62 top_k=top_k, 63 num_candidates=num_candidates, 64 use_full_precision=True, 65 ) 66 baseline_ids = { 67 res["wiki_id"] for res in baseline_result["results"] 68 } 69 70 # Quantized search: 71 quantized_result = custom_vector_search( 72 user_query=query, 73 collection=collection, 74 embedding_path="embedding", 75 vector_search_index_name=quantized_index_name, 76 top_k=top_k, 77 num_candidates=num_candidates, 78 use_full_precision=False, 79 ) 80 quantized_ids = { 81 res["wiki_id"] for res in quantized_result["results"] 82 } 83 84 # Compute retention for this combination 85 if baseline_ids: 86 retention = len( 87 baseline_ids.intersection(quantized_ids) 88 ) / len(baseline_ids) 89 else: 90 retention = 0 91 92 # Store the results per query 93 retention_results["per_query_retention"][query].setdefault( 94 top_k, {} 95 )[num_candidates] = { 96 "ground_truth_wiki_id": ground_truth_wiki_id, 97 "baseline_ids": sorted(baseline_ids), 98 "quantized_ids": sorted(quantized_ids), 99 "retention": retention, 100 } 101 overall_retention[top_k][num_candidates].append(retention) 102 103 print( 104 f"Query: '{query}' | top_k: {top_k}, num_candidates: {num_candidates}" 105 ) 106 print(f" Ground Truth wiki_id: {ground_truth_wiki_id}") 107 print(f" Baseline IDs (Float32): {sorted(baseline_ids)}") 108 print( 109 f" Quantized IDs: {precision_name}: {sorted(quantized_ids)}" 110 ) 111 print(f" Retention: {retention:.4f}\n") 112 113 # Compute overall average retention per combination 114 avg_overall_retention = {} 115 for top_k, cand_dict in overall_retention.items(): 116 avg_overall_retention[top_k] = {} 117 for num_candidates, retentions in cand_dict.items(): 118 if retentions: 119 avg = sum(retentions) / len(retentions) 120 else: 121 avg = 0 122 avg_overall_retention[top_k][num_candidates] = avg 123 print( 124 f"Overall Average Retention for top_k {top_k}, num_candidates {num_candidates}: {avg:.4f}" 125 ) 126 127 retention_results["average_retention"] = avg_overall_retention 128 return retention_results 评估和比较MongoDB Vector Search 索引的性能。
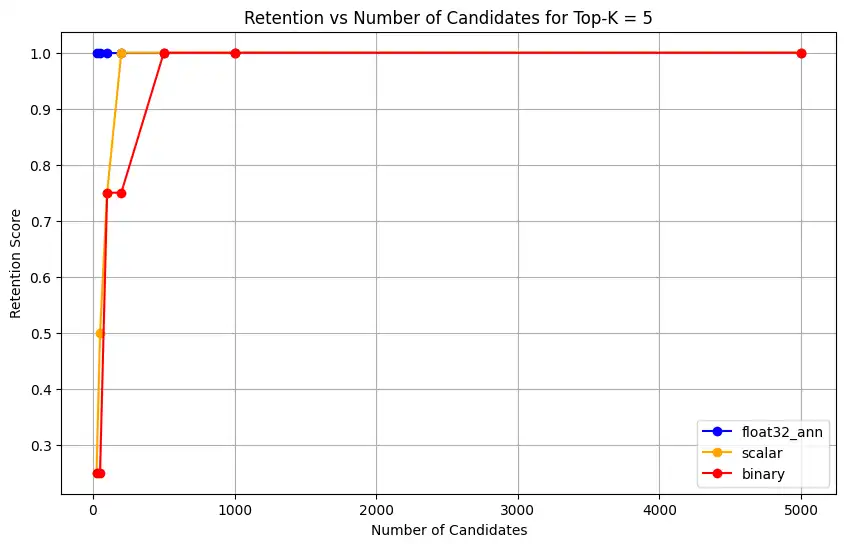
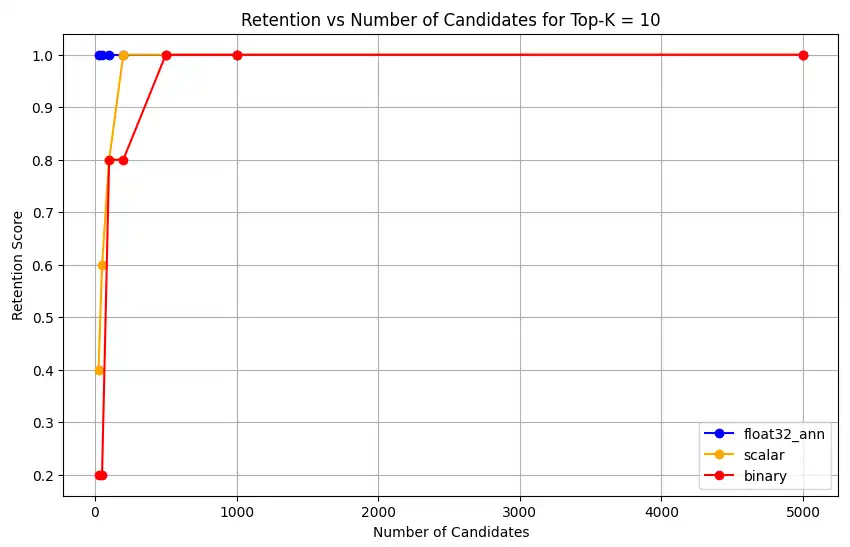
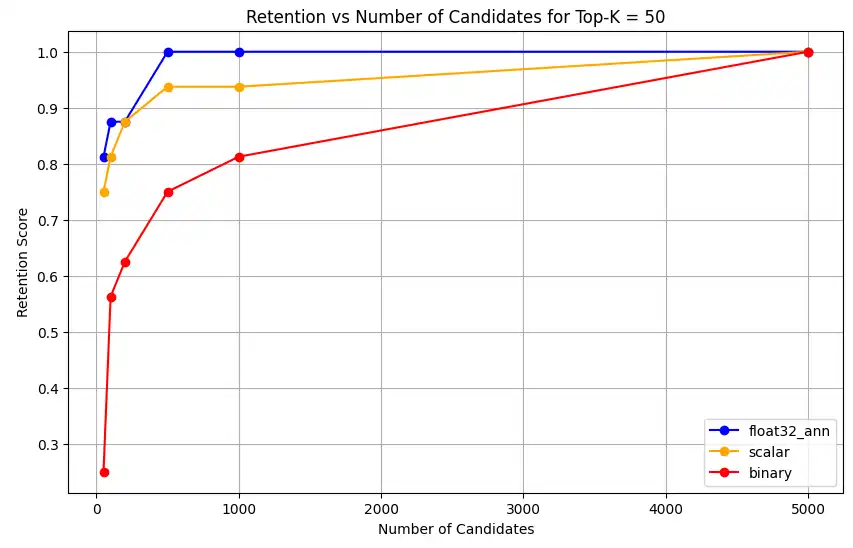
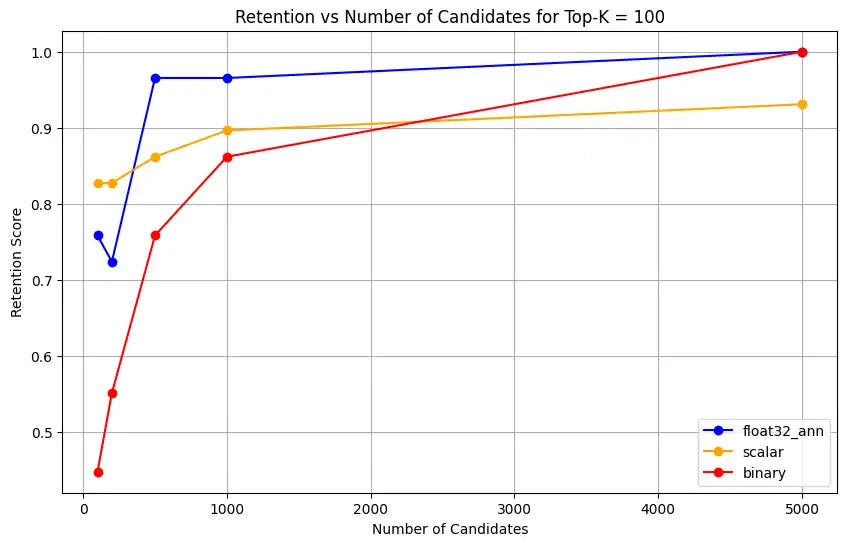
1 overall_recall_results = [] 2 top_k_values = [5, 10, 50, 100] 3 num_candidates_values = [25, 50, 100, 200, 500, 1000, 5000] 4 num_queries_to_test = 1 5 6 for vector_search_index in vector_search_indices: 7 overall_recall_results.append( 8 measure_representational_capacity_retention_against_float_enn( 9 ground_truth_collection=wiki_annotation_data_collection, 10 collection=wiki_data_collection, 11 quantized_index_name=vector_search_index, 12 top_k_values=top_k_values, 13 num_candidates_values=num_candidates_values, 14 num_queries_to_test=num_queries_to_test, 15 ) 16 ) Loaded 1 ground truth annotations Query: 'What happened in 2022?' | top_k: 5, num_candidates: 25 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871] Quantized IDs: _float32_ann: [60254944, 64483771, 69094871] Retention: 0.7500 ... Query: 'What happened in 2022?' | top_k: 5, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871] Quantized IDs: _float32_ann: [52251217, 60254944, 64483771, 69094871] Retention: 1.0000 Query: 'What happened in 2022?' | top_k: 10, num_candidates: 25 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871, 69265870] Quantized IDs: _float32_ann: [60254944, 64483771, 65225795, 69094871, 70149799] Retention: 1.0000 ... Query: 'What happened in 2022?' | top_k: 10, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871, 69265870] Quantized IDs: _float32_ann: [52251217, 60254944, 64483771, 69094871, 69265870] Retention: 1.0000 Query: 'What happened in 2022?' | top_k: 50, num_candidates: 50 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [25391, 832774, 8351234, 18426568, 29868391, 52241897, 52251217, 60254944, 63422045, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [25391, 8351234, 29868391, 40365067, 52241897, 52251217, 60254944, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 0.8125 ... Query: 'What happened in 2022?' | top_k: 50, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [25391, 832774, 8351234, 18426568, 29868391, 52241897, 52251217, 60254944, 63422045, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [25391, 832774, 8351234, 18426568, 29868391, 52241897, 52251217, 60254944, 63422045, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 1.0000 Query: 'What happened in 2022?' | top_k: 100, num_candidates: 100 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [16642, 22576, 25391, 547384, 737930, 751099, 832774, 8351234, 17742072, 18426568, 29868391, 40365067, 52241897, 52251217, 52851695, 53992315, 57798792, 60163783, 60254944, 62750956, 63422045, 64483771, 65225795, 65593860, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [22576, 25391, 243401, 547384, 751099, 8351234, 17742072, 18426568, 29868391, 40365067, 47747350, 52241897, 52251217, 52851695, 53992315, 57798792, 60254944, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 0.7586 ... Query: 'What happened in 2022?' | top_k: 100, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [16642, 22576, 25391, 547384, 737930, 751099, 832774, 8351234, 17742072, 18426568, 29868391, 40365067, 52241897, 52251217, 52851695, 53992315, 57798792, 60163783, 60254944, 62750956, 63422045, 64483771, 65225795, 65593860, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [16642, 22576, 25391, 547384, 737930, 751099, 832774, 8351234, 17742072, 18426568, 29868391, 40365067, 52241897, 52251217, 52851695, 53992315, 57798792, 60163783, 60254944, 62750956, 63422045, 64483771, 65225795, 65593860, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 1.0000 Overall Average Retention for top_k 5, num_candidates 25: 0.7500 ... 输出显示了基准数据集中每个查询的保留结果。保留率表示为 0 和 1 之间的小数,其中 1.0 表示保留基准真值 ID,而 0.25 表示仅保留 25% 的基准真值 ID。
绘制不同精度类型的保留功能。
1 import matplotlib.pyplot as plt 2 3 # Define colors and labels for each precision type 4 precision_colors = {"_scalar_": "orange", "_binary_": "red", "_float32_": "green"} 5 6 if overall_recall_results: 7 # Determine unique top_k values from the first result's average_retention keys 8 unique_topk = sorted(list(overall_recall_results[0]["average_retention"].keys())) 9 10 for k in unique_topk: 11 plt.figure(figsize=(10, 6)) 12 # For each precision type, plot retention vs. number of candidates at this top_k 13 for result in overall_recall_results: 14 precision_name = result.get("precision_name", "unknown") 15 color = precision_colors.get(precision_name, "blue") 16 # Get candidate values from the average_retention dictionary for top_k k 17 candidate_values = sorted(result["average_retention"][k].keys()) 18 retention_values = [ 19 result["average_retention"][k][nc] for nc in candidate_values 20 ] 21 22 plt.plot( 23 candidate_values, 24 retention_values, 25 marker="o", 26 label=precision_name.strip("_"), 27 color=color, 28 ) 29 30 plt.xlabel("Number of Candidates") 31 plt.ylabel("Retention Score") 32 plt.title(f"Retention vs Number of Candidates for Top-K = {k}") 33 plt.legend() 34 plt.grid(True) 35 plt.show() 36 37 # Print detailed average retention results 38 print("\nDetailed Average Retention Results:") 39 for result in overall_recall_results: 40 precision_name = result.get("precision_name", "unknown") 41 print(f"\n{precision_name} Embedding:") 42 for k in sorted(result["average_retention"].keys()): 43 print(f"\nTop-K: {k}") 44 for nc in sorted(result["average_retention"][k].keys()): 45 ret = result["average_retention"][k][nc] 46 print(f" NumCandidates: {nc}, Retention: {ret:.4f}") 该代码返回以下内容的保留率图表:
对于
float32_ann、scalar和binary嵌入,代码还返回详细的平均保留结果,如下所示:Detailed Average Retention Results: _float32_ann Embedding: Top-K: 5 NumCandidates: 25, Retention: 1.0000 NumCandidates: 50, Retention: 1.0000 NumCandidates: 100, Retention: 1.0000 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 10 NumCandidates: 25, Retention: 1.0000 NumCandidates: 50, Retention: 1.0000 NumCandidates: 100, Retention: 1.0000 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 50 NumCandidates: 50, Retention: 0.8125 NumCandidates: 100, Retention: 0.8750 NumCandidates: 200, Retention: 0.8750 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 100 NumCandidates: 100, Retention: 0.7586 NumCandidates: 200, Retention: 0.7241 NumCandidates: 500, Retention: 0.9655 NumCandidates: 1000, Retention: 0.9655 NumCandidates: 5000, Retention: 1.0000 _scalar_ Embedding: Top-K: 5 NumCandidates: 25, Retention: 0.2500 NumCandidates: 50, Retention: 0.5000 NumCandidates: 100, Retention: 0.7500 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 10 NumCandidates: 25, Retention: 0.4000 NumCandidates: 50, Retention: 0.6000 NumCandidates: 100, Retention: 0.8000 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 50 NumCandidates: 50, Retention: 0.7500 NumCandidates: 100, Retention: 0.8125 NumCandidates: 200, Retention: 0.8750 NumCandidates: 500, Retention: 0.9375 NumCandidates: 1000, Retention: 0.9375 NumCandidates: 5000, Retention: 1.0000 Top-K: 100 NumCandidates: 100, Retention: 0.8276 NumCandidates: 200, Retention: 0.8276 NumCandidates: 500, Retention: 0.8621 NumCandidates: 1000, Retention: 0.8966 NumCandidates: 5000, Retention: 0.9310 _binary_ Embedding: Top-K: 5 NumCandidates: 25, Retention: 0.2500 NumCandidates: 50, Retention: 0.2500 NumCandidates: 100, Retention: 0.7500 NumCandidates: 200, Retention: 0.7500 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 10 NumCandidates: 25, Retention: 0.2000 NumCandidates: 50, Retention: 0.2000 NumCandidates: 100, Retention: 0.8000 NumCandidates: 200, Retention: 0.8000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 50 NumCandidates: 50, Retention: 0.2500 NumCandidates: 100, Retention: 0.5625 NumCandidates: 200, Retention: 0.6250 NumCandidates: 500, Retention: 0.7500 NumCandidates: 1000, Retention: 0.8125 NumCandidates: 5000, Retention: 1.0000 Top-K: 100 NumCandidates: 100, Retention: 0.4483 NumCandidates: 200, Retention: 0.5517 NumCandidates: 500, Retention: 0.7586 NumCandidates: 1000, Retention: 0.8621 NumCandidates: 5000, Retention: 1.0000 召回结果显示,三种嵌入类型的性能模式各不相同。
标量量化显示出稳定的改进,表明在 K 值较高时,检索精度很高。二进制量化虽然起始性能较低,但在 Top-K 50 和 100 中表现有所提升,这表明计算效率与召回性能之间存在权衡关系。浮点 32 嵌入展示了最强的初始性能,并在 Top-K 50 和 100 达到了与标量量化相同的最大召回率。
这表明,虽然浮点 32 在较低的 Top-K 值下提供更好的召回率,但标量量化可以在较高的 Top-K 值下实现相同的性能,同时提供更高的计算效率。尽管二进制量化的召回上限较低,但在内存和计算限制超过对最大召回准确性需求的情况下,二进制量化可能仍然很有价值。