您可以使用不同的部署类型、云提供商和集群层来构建集群,以满足预生产或生产环境的需求。使用这些建议来选择部署类型、云提供商和地区以及用于执行向量搜索的集群和搜索层。
environment | 部署类型 | 集群层 | 云提供商地区 | 节点架构 |
|---|---|---|---|---|
测试查询 | Flex cluster, dedicated cluster Local deployment | Free cluster or higher tier N/A | All N/A | MongoDB和Atlas Search进程在同一节点上运行 |
应用程序原型设计 | 专用集群 | Flex集群、 | 所有 | MongoDB和Atlas Search进程在同一节点上运行 |
生产 | 具有独立搜索节点的专用集群 |
| 某些 地区的 AWS 和Azure或所有地区的 Google Cloud | MongoDB和Atlas Search进程在不同节点上运行 |
要了解有关这些部署模型的更多信息,请查看以下部分:
资源使用情况
索引向量的内存要求
MongoDB Vector Search 将整个索引保存在内存中,因此如果数据集包含全精度向量,则需要确保有足够的内存用于MongoDB Vector Search索引和Java虚拟机(JVM) 。每个索引都是被索引向量和其他元数据的组合。索引大小主要由要索引的向量的大小决定,元数据空间通常相对较小。
不使用量化时, MongoDB Vector Search 会将全保真度向量存储在内存中。如果启用自动量化, MongoDB Vector Search 会将需要的资源显着减少的量化向量存储在内存中,并将全保真向量存储在磁盘上。您可以通过查看Atlas用户界面MongoDB搜索页面中的 Size 和 Required Memory 列,了解向量索引的磁盘和内存要求之间的差异。
考虑单个向量的以下要求:
嵌入模型 | 向量维度 | 空间要求 |
|---|---|---|
Voyage AI | 2048 | 8kb (for float)2.14kb (for int8)0.334kb (for int1) |
OpenAI | 1536 | 6 kb |
Google | 768 | 3 kb |
Cohere | 1024 | 4kb (for float)1.07kb (for int8)0.167kb (for int1) |
BinData 量化向量。要学习;了解更多信息,请参阅 摄取量化向量。
所需空间与要索引的向量数量和向量维度呈线性增长。您还可以使用Search Index Size 指标来确定搜索节点上所需的空间和内存量。
向量的存储要求
如果您使用了 BinData 或量化向量,则较之不使用 binData 或量化向量,您可大幅降低资源需求。您会发现:
在使用
binData向量时,mongod上的向量磁盘存储减少了 66%。在使用自动矢量量化或量化矢量引入时,由于矢量压缩,
mongot上的矢量 RAM 使用量减少了 3.75 倍(标量)或 24 倍(二进制)。
当您使用自动量化时,Atlas 会将全精度向量存储在磁盘上,以便重新评分或进行精确搜索,同时将重新评分时的 RAM 和缓存使用量降至最低。
如果在MongoDB Vector Search 索引定义 中启用 自动量化 ,则在调整集群大小时还必须考虑磁盘空间。这是因为 MongoDB Vector Search 还会将全精度向量存储在磁盘上,以用于 ENN 搜索和重新评分(如果配置了自动量化)。因此,请确保您使用的硬件上有适当的磁盘与RAM 的比率。考虑配置搜索节点,使其能够适应大致 4:1 的存储与RAM比率(用于标量量化)或 24:1 的存储与RAM比率(用于二进制量化)。
例子
此示例演示了如何为存储在名为 my-embeddings 的字段中且来自 Voyage AI 的 10 百万 1024 维度嵌入配置二进制量化:
{ "fields":[ { "type": "vector", "path": "my-embeddings", "numDimensions": 1024, "similarity": "euclidean", "quantization": "binary" } ] }
请使用以下公式粗略计算启用二进制量化和重新评分的索引的磁盘空间:
Original index size * (25/24)
此时,分母中的 24 表示将原始索引大小分割为 24 个部分,以便简化分数表示。分子中的 25 考虑了额外空间分配(约为原始索引大小的 1/24),而它可用于存储二进制向量所需的其他数据。原始索引和分层可导航小世界图仍会存储在磁盘上。超大因子为 1/24 而不是 1/32,因为 HNSW 图未进行压缩。
例子
假设您的原始索引大小为 1 GB。您可通过重新评分来计算二进制量化索引大小,如下所示:
1 GB * (25/24) = 1.042 GB
重要
在Atlas用户界面中, Atlas会显示整个索引的大小,该大小可能很大,因为Atlas不会详细显示索引中存储在RAM和磁盘中的数据结构。启用自动量化后, MongoDB搜索指标显示内存中保存的索引要小得多。
对于您配置了自动量化的向量,我们建议分配等于估计索引大小的 125% 的可用磁盘空间。
测试和原型环境
为了测试您的向量搜索查询和构建应用程序原型,我们建议使用以下配置。
部署类型
要测试MongoDB Vector Search 查询,您可以部署Flex集群、专用集群或使用本地Atlas部署。
Cluster Tiers
免费集群(以前称为 M0)是集群的免费套餐。Flex 集群是低成本集群类型,适合学习MongoDB或开发小型概念验证应用程序的团队。您可以从Atlas Flex集群开始您的项目,并在将来升级到生产就绪的专用集群层级。
这些低成本集群类型可用于测试MongoDB Vector Search 查询。但是,您可能会在 Flex 集群上遇到资源争用和查询延迟。如果您使用 Flex集群开始您的项目,我们建议您在应用程序准备投入生产时升级到更高层级。
专用集群包括M10 和更高层级。M10 和M20 层适合对应用程序进行原型设计。当您的应用程序准备投入生产时,您可以扩展到更高的层级以处理大型数据集,或部署专用的搜索节点以实现工作负载隔离性。
云提供商和地区
您选择的云提供商和区域会影响集群层可用的配置选项和集群运行成本。
如果您希望在本地测试MongoDB Vector Search 查询,则可以使用Atlas CLI部署在本地计算机上托管的单节点副本集。要开始使用,请完成MongoDB Vector Search 快速入门,然后选择用于本地部署的标签页。
当您的应用程序准备好投入生产时,使用实时迁移将本地Atlas部署迁移到生产环境。本地部署受到本地计算机的 CPU、内存和存储资源的限制。
节点架构
对于测试和原型环境,我们建议采用MongoDB进程和MongoDB搜索进程在同一节点上运行的节点架构。在此部署模型的下图中, MongoDB Search mongot进程与 mongod 一起在Atlas 集群中的每个节点上运行,并且它们股票相同的资源。

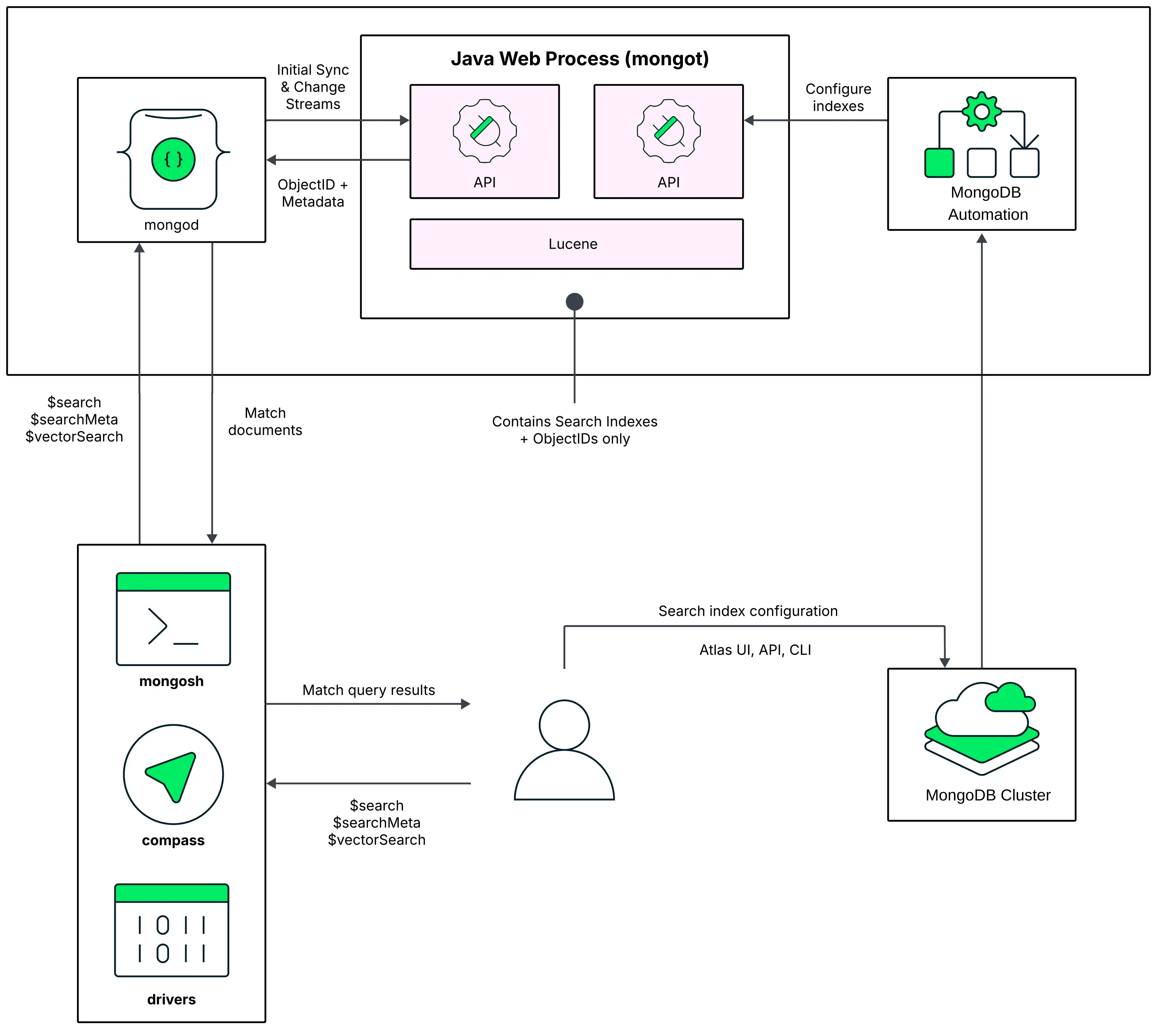
默认下,当您创建第一个MongoDB Vector Search索引时, Atlas会在运行 mongod进程的同一节点上启用MongoDB Search mongot进程。
运行查询时, MongoDB Search 会使用配置的读取偏好(read preference)来识别运行查询的节点。查询首先进入MongoDB进程,对于副本集集群为mongod mongos,对于分片集群为 。
对于副本集集群,mongod 进程会将查询路由到同一节点上的mongot 。对于分片的集群,您的集群数据跨mongod 实例(分片)进行分区,并且每个mongot 进程只能访问权限同一节点上的mongod 实例上的数据。因此,您无法运行针对特定分片的MongoDB Search 查询。mongos 将查询路由到所有分片,使这些查询成为分散聚集查询。如果您使用区域将分片的集合分布在集群中的一部分分片上,MongoDB Search 会将查询路由到包含您正在查询的集合的分片的区域,并仅对以下分片运行$search 查询,其中集合所在的位置。
将查询路由到MongoDB搜索mongot 进程后,mongot 进程执行搜索和评分,并将匹配结果的文档ID 和其他搜索元数据返回相应的mongod 进程。然后, 进程对匹配结果隐式执行完整文档查找,并将结果返回客户端。如果在查询中使用mongod $search并发选项, MongoDB Search 将启用查询内并行机制。要学习;了解更多信息,请参阅跨分段并行查询执行。
要学习;了解有关mongot 进程的详情,请参阅查询处理。
调整集群大小以为您的应用程序进行原型设计
当Atlas在同一节点上运行数据库和搜索工作负载时, MongoDB存储会占用一定比例的节点可用内存 (RAM),将剩余内存留给MongoDB Vector Search索引和 mongot进程。
层级 | 总内存 (GB) | 可用于MongoDB Vector Search 索引的内存 (GB) |
|---|---|---|
| 2 | 1 |
| 4 | 2 |
| 8 | 4 |
对于 M10、M20 和 M30集群层,25% 保留用于MongoDB ,剩余的 75% 用于其他操作,包括MongoDB Vector Search索引。对于 M40 个以上的集群层,50% 保留用于MongoDB ,剩余的用于其他操作,包括MongoDB Vector Search索引。
限制
您可能会遇到数据库 mongod 和搜索 mongot 进程之间的资源争用。这可能会对索引性能和查询延迟产生负面影响。我们建议这种部署模式仅用于测试和原型开发环境。对于生产就绪型应用程序和相关的搜索工作负载,我们建议迁移到专用的搜索节点。
生产环境
对于生产就绪的应用程序,我们建议使用以下集群配置。
部署类型
Cluster Tiers
专用集群包括M10 和更高层级。M10 和M20 层适用于开发和生产环境。但是,较高的层级可以处理大型数据集和生产工作负载。我们还建议您为搜索工作负载部署专用的搜索节点。这样,您就可以独立、适当地扩展搜索部署。
云提供商和地区
搜索节点在 Google Cloud 的所有区域中可用,但仅在部分 AWS 和Azure区域中可用。您必须选择搜索节点可用于您的部署的云提供商和地区。
所有集群层在支持的云提供商区域均可使用。您选择的云提供商和区域会影响集群可用的配置选项和搜索层级以及运行集群的成本。
节点架构
对于生产环境,我们建议采用一种节点架构,其中MongoDB进程和MongoDB搜索进程在单独的节点上运行。要部署单独的搜索节点,请参阅迁移到专用搜索节点。
在此部署模型的下图中, MongoDB Search mongot进程在专用搜索节点上运行,这些节点与运行 mongod进程的集群节点是分开的。

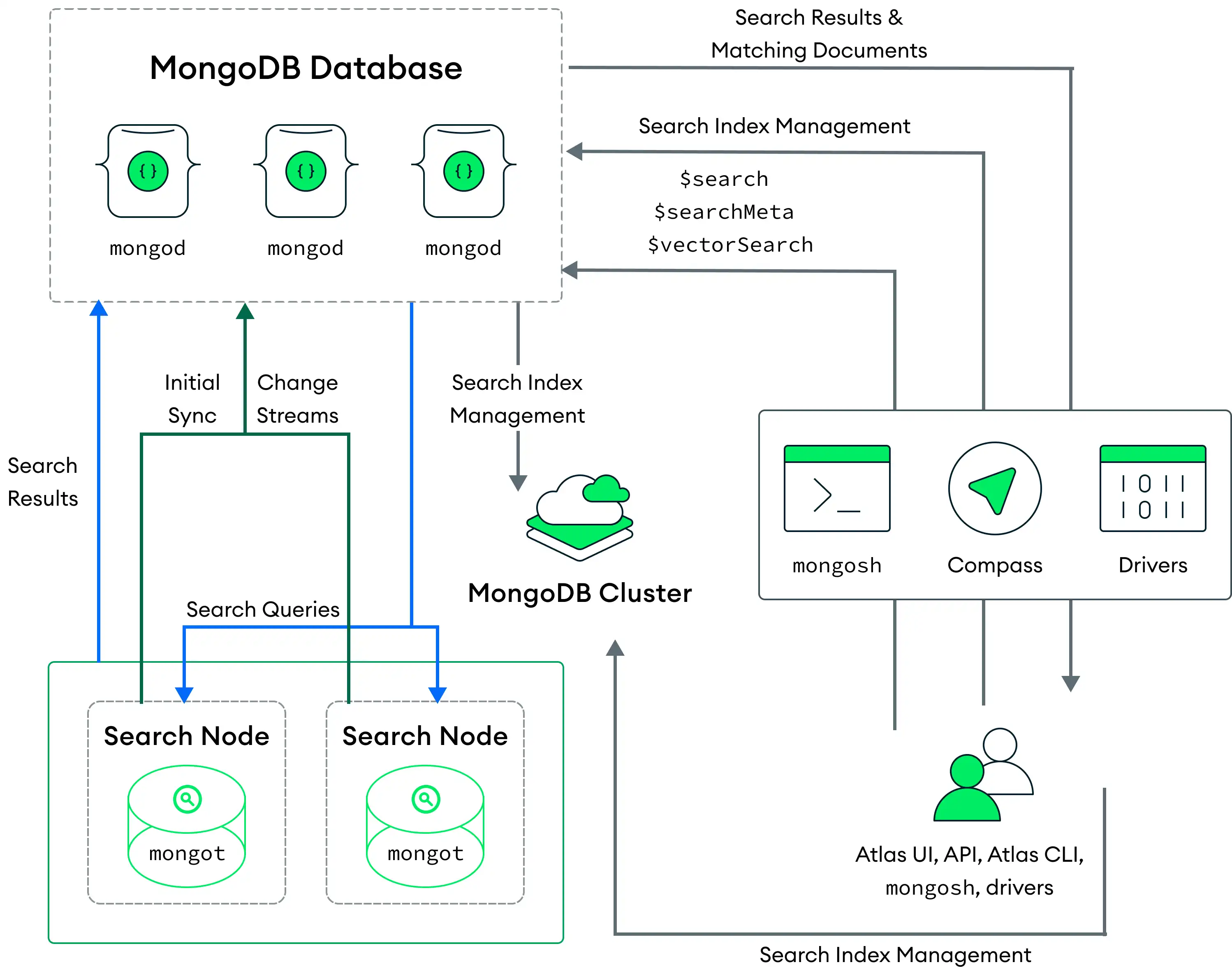
Atlas 为每个集群或集群上的每个分片部署搜索节点。例如,如果您为具有三个分片的集群部署两个搜索节点,则 Atlas 会部署六个搜索节点(每个分片两个)。您还可以配置搜索节点的数量,以及为每个搜索节点配置的资源量。
当您部署单独的搜索节点时, Atlas会自动为每个mongod 分配一个mongot 以便索引。mongot 与mongod 通信,侦听并同步其存储的索引的索引更改。 MongoDB Vector Search 对查询进行索引和处理的方式与mongod 和mongot 进程在同一节点上运行的部署类似。要学习;了解更多信息,请参阅如何为向量搜索的字段编制索引和运行向量搜索查询。要学习;了解有关单独部署搜索节点的更多信息,请参阅用于隔离工作负载的搜索节点。
当您迁移到搜索节点时,Atlas 会部署搜索节点,但不会在节点上提供查询,直到它在搜索节点上的集群上成功构建所有索引。当 Atlas 在新节点上构建索引时,它会继续使用集群节点上的索引提供查询。仅当 Atlas 在搜索节点上成功构建索引并删除集群节点上的索引后,它才会开始从搜索节点提供查询服务。
注意
运行查询时,查询会根据配置的读取偏好(readmongod preference)路由到 。mongod 进程通过同一节点上的负载负载均衡器路由搜索查询,这会将请求分发到所有mongot 进程。
MongoDB Searchmongot 进程执行搜索和评分,并将匹配结果的文档ID 和元数据返回给mongod 。然后, 对匹配结果执行完整文档查找,并将结果返回给客户端。如果在查询中使用mongod $search并发选项, MongoDB Search 将启用查询内并行机制。要学习;了解更多信息,请参阅跨分段并行查询执行。
如果删除集群上的所有搜索节点,则在处理搜索查询结果时会出现中断。要学习;了解更多信息,请参阅修改集群。如果删除Atlas 集群, Atlas会暂停,然后删除所有关联的MongoDB Vector Search 部署(mongot 进程)。
收益分析
此部署模型具有以下优点:
高效利用资源,同时确保资源对Atlas Search工作负载具有高可用性。
Atlas Search部署的大小和扩展独立于数据库部署。
同时自动进程MongoDB Vector Search 查询,从而缩短响应时间,尤其是在处理大型数据集时。要学习;了解更多信息,请参阅跨分段并行查询执行。
为生产环境调整搜索节点的大小
MongoDB Vector Search 将整个索引保存在内存中,因此您需要确保有足够的内存用于MongoDB Vector Search索引和Java虚拟机(JVM)。搜索节点支持工作负载隔离性,无需数据隔离性,其RAM分配的近 90% 可用于在内存中存储向量数据和索引,剩余部分用于Java虚拟机(JVM)。
每个索引都是所索引向量和附加元数据的组合。索引大小主要由要编制索引的向量的大小决定,元数据空间通常相对较小。要了解更多信息,请参阅索引向量的内存要求。
部署专用搜索节点时,您可以选择不同的搜索层级。每个搜索层级都有默认的RAM容量、存储容量和 CPU。这样,您就可以独立于数据库部署来调整集群的大小和扩展。要单独扩展搜索部署,您可以随时对集群配置进行以下更改:
调整集群上的 Search Nodes 数量。
通过更改 层来调整节点的 CPU、RAMAtlas Search 和存储。
注意
要进一步了解搜索节点和搜索层级的成本,请展开 View all plan features 并点击 MongoDB 定价页面中的 MongoDB Vector Search。
我们建议节点的RAM至少比MongoDB Vector Search 索引的总大小大 10%。我们还建议您确保有足够的可用 CPU。查询延迟取决于可用 CPU 的数量,这可能会严重影响可提高查询性能的内部并发级别。
例子
假设您有 1M 个 768 维向量,大小约为 3GB。S30(低 CPU)和 S20(高 CPU)搜索层级都有足够的 RAM 来支持索引。我们建议不要在 S30(低 CPU)搜索层级上部署,而是在 S20(高 CPU)搜索层级上部署,因为 S20(高 CPU)搜索层级有更多可用的 CPU 来并发运行查询。
启用静态加密
默认下, MongoDB和搜索进程在同一节点上运行。在这种架构中,客户管理的加密适用于数据库数据,但不适应用搜索索引。
启用专用搜索节点后,搜索进程将在单独的节点上运行。这允许您启用搜索节点数据加密,以便您可以使用相同的客户托管密钥对数据库数据和搜索索引进行加密,以实现全面的加密覆盖范围。
注意
数据库节点和搜索节点使用不同的加密方法以及相同的客户托管密钥。数据库节点使用WiredTiger加密存储引擎,而搜索节点则在磁盘级别使用加密。
如要了解更多信息,请参阅启用搜索节点的客户密钥管理。
重要
KMS 提供商均提供此功能,但搜索节点必须位于 AWS 上。
迁移到专用Atlas Search节点
专用搜索节点允许您独立于集群来调整搜索部署的大小和扩展。 它还消除了在同一节点上运行数据库和搜索进程的集群中可能出现的资源争用现象。
要迁移到专用搜索节点,请对您的部署进行以下更改:
如果您的部署当前使用的是免费套餐集群或 Flex集群,请将集群升级到更高层级。仅
M10及更高集群层支持专用搜索节点。要学习;了解有关迁移到不同集群层的更多信息,请参阅修改集群层。专用搜索节点在部分 AWS 和Azure区域以及所有支持的 Google Cloud 区域中可用。确保将集群部署在搜索节点也可用的区域。如果您的现有集群位于搜索节点不可用的地区,请将集群迁移到搜索节点可用的地区。要学习;了解更多信息,请参阅云提供商区域。
启用Search Nodes for workload isolation 并配置搜索节点。要学习;了解更多信息,请参阅添加搜索节点。