Data sources
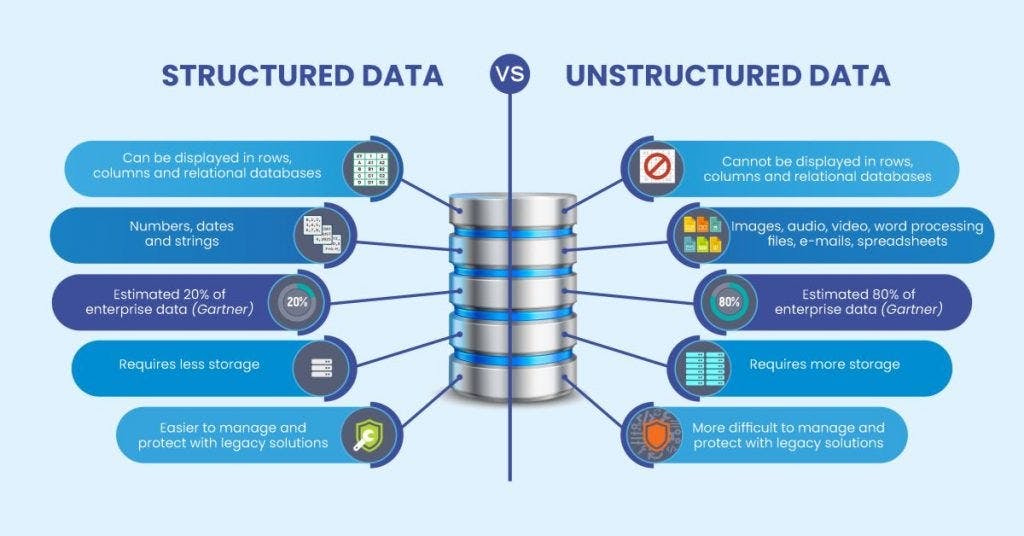
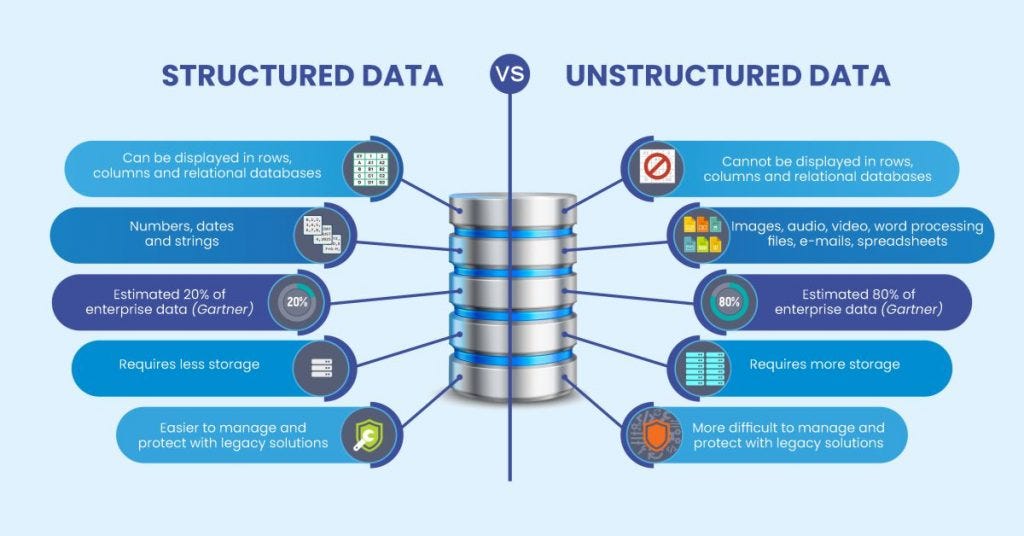
Data is sourced from multiple inputs in a variety of formats. Examples include structured data from financial systems and retail databases; semi-structured data from email systems, web logs, and XML/JSON files; and unstructured data from such sources as social media, facial recognition systems, sensors, scanned documents, and real-time streaming data inputs, such as those received from Internet of Things (IoT) devices.
Data collection and ingestion
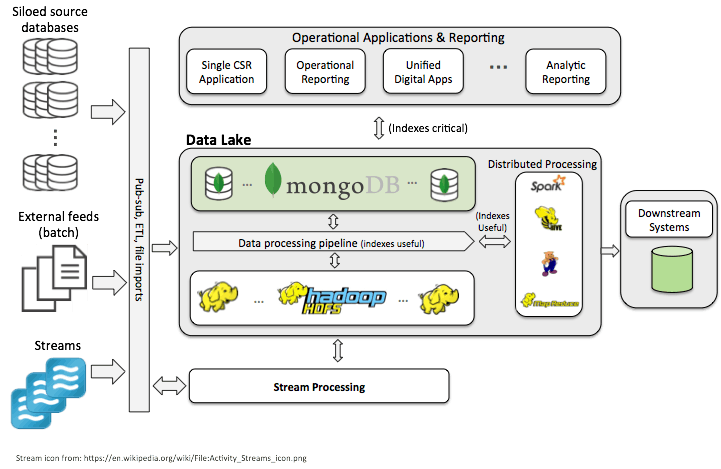
This is the layer that collects and receives data from diverse data sources. And, as much of the data used in big data is unstructured, big data architecture must be able to accommodate the ingestion of varying data types with varying formats. For this reason, while there are usually some types of data validation in place, data format and data schema requirements are more lax than the hardline ones common in traditional relational databases.
There are two general types of data ingestion — batch and real-time. Batch ingestion is usually a regularly scheduled event to bring new data into the database periodically. Real-time ingestion, required for real-time message ingestion and streaming data, occurs on a continuous basis. While captured in real-time, it is sometimes necessary to hold this data briefly (seconds) for buffering to enable scale-out processing and reliable output delivery.
Data storage
The data storage layer takes the ingested data and stores it in an efficient manner optimized for scalability and performance. Organizational data storage solutions are driven by anticipated data volume, data types, access patterns, and anticipated query requirements.
Data processing
This layer is responsible for filtering, combining, and rendering data into a usable state for further analysis. And, just as with ingestion, processing may occur via a batch or streaming process.
Source files are read and processed, with the output written to new files. These files often include distributed file systems, meaning files are stored on multiple machines in multiple locations. At this point, the output data may be formatted and relayed to a relational data warehouse where it can be queried via traditional business intelligence (BI) tools, or it may be served to NoSQL databases and interactive technologies that specialize in analytics of a variety of unstructured data.
One outlier in this process is the data lake. Data lakes are able store vast amounts of data in its original (raw data) format. This means that data ingestion into a data lake is possible without any type of preformatting required. In addition, data lakes are able to store both structured and unstructured data.
Data analytics
Big data analytics is a broad term relating to this layer. Not only are traditional, search-based, and predictive analytics conducted, but ad-hoc analysis is performed as well. In addition, stream analytics tools (e.g., analysis of vast pools of real-time data through the use of continuous queries) are employed to provide social media analytics and associated consumer data behavior trends.
Further, data science professionals often employ machine learning (ML) to create data models which enable self-service BI dashboards for business users. ML is also employed by data scientists to further explore raw and unstructured data sets through data mining and other advanced analytics practices.
Resources to learn more: Unstructured data analytics tools
Data visualization
Data visualization is the representation of data through graphic means. Data visualization tools and reporting platforms allow users to transform complex data insights into easily understandable graphic representations for business users and stakeholders. Tools such as Tableau, Power BI, and custom dashboards enable this data visualization, exploration, and reporting.
Data security and monitoring
In this layer, security protocols such as access control, user authentication, and encryption are in place to protect data resources. This layer also contains the software necessary to continuously monitor systems for cyberattacks and associated malware or viruses. In addition, data governance operations ensuring compliance with third-party regulations and access (e.g., government, industry standards entities) also reside here.
Finally, the health and performance of the big data architecture is monitored here. This includes logging, backups, system alerts, and the application of management tools to ensure high levels of system availability, access, and data quality.
{kind=link}