業種: メディア、電気通信
製品およびツール: MongoDB Atlas、MongoDB Vector Search、MongoDB Atlas Stream Processing
パートナー: Voyage AI、Azure OpenAI
ソリューション概要
新規ユーザーがニュースサイトにアクセスした場合、興味を失いサイトを離れてしまう前に、ユーザーが探している内容を数秒で理解する必要があります。これにより、コールドスタート問題が発生してしまいます。ユーザーについての情報がない場合、どのようにコンテンツを推奨すればいいのでしょうか?
匿名のユーザーが貴社のサイトにアクセスし、3つの記事をクリックしたとします。
「NVIDI、新しいAIチップを設計」
「TSMC、アリゾナでの生産を拡大」
「Intel株式、遅延の影響で下落」
単純なキーワード検索では、Intel または Arizona に関する他の記事のみが推奨されます。しかし、インテリジェントシステムは3つのクリックすべてが半導体サプライチェーンに関連していることを認識します。これにより、キーワードがユーザーの閲覧履歴と共有されない場合でも、「シリコンバレーの未来」のような関連記事が推奨されます。
この記事で紹介するソリューションは、インテリジェントなメディア パーソナライズ システムをビルドし、クリックストリームデータを取得および処理して、ユーザーの興味に関する自然言語の要約を生成し、ユーザーが関心を持ちそうな関連記事を推奨します。
このソリューションは以下が組み合わさっています。
クリックストリームデータからユーザーの意図を要約するためのリアルタイムデータの取り込み、エンリッチメント、LLM 統合向けの Atlas Stream Processing
セマンティック検索と推奨向けの自動 Voyage AI が組み込まれたAtlas Vector Search
リファレンスアーキテクチャ
このアーキテクチャは、 MongoDB Atlas を使用して、ユーザーの行動をリアルタイムで取り込み、処理し、応答する AI 駆動型メディア推奨エンジンをビルドする方法を示しています。
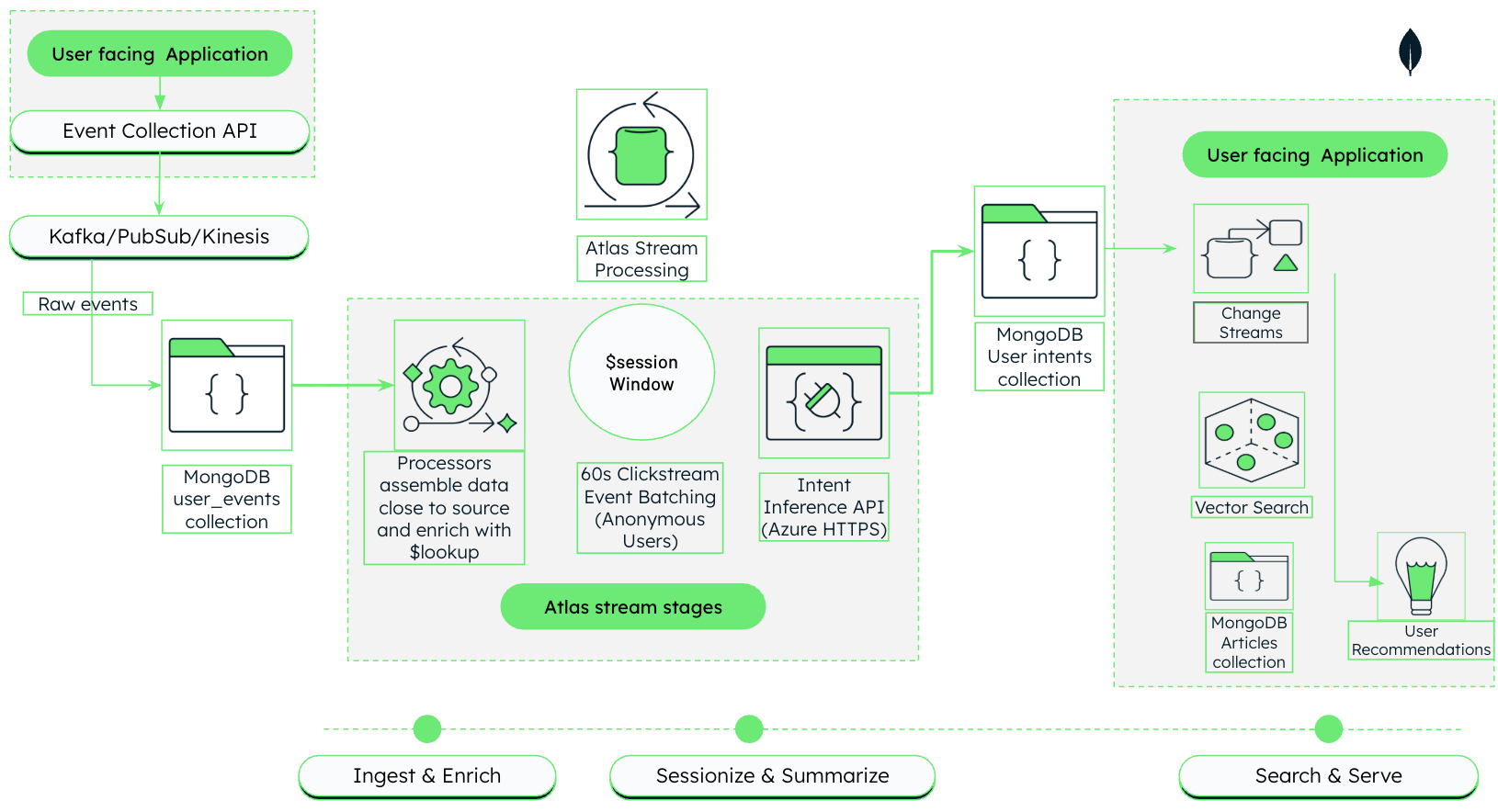
図 1. Atlas Stream Processing および MongoDB Vector Search を使用した AI 駆動型メディア パーソナライズ アーキテクチャ
このアーキテクチャは3つのフェーズで動作し、これらについては、次のセクションで詳しく説明します。
取り込みとエンリッチメント: ユーザー向けのアプリケーションから未加工のクリックストリームイベントをキャプチャし、Atlas Stream Processing を使用してリアルタイムで記事のメタデータと結合します。
セッション化と要約: 関連するクリックをセッションにグループ化し、LLM を使用してユーザーの興味を自然言語で要約します。
検索と配信: 生成された要約を使用してセマンティックベクトル検索を実行し、パーソナライズされた推奨を返します。
フェーズ 1: クリックストリームデータの取り込みとエンリッチメント
最初のフェーズでは、このソリューションアーキテクチャは Atlas Stream Processing を使用して、メディアプラットフォームから未加工のクリックストリームデータを取り込み、データベースの記事のメタデータで強化します。
データソースを設定してください。
このソリューションでは、同じMongoDBクラスターの newsデータベースにある次の 2 つのコレクションを使用します。
articles コレクションには、カタログの記事に関するメタデータが含まれています。この例では、コレクションは ClickstreamCluster クラスターの news データベースにあります。
コレクション内の各ドキュメントは記事を表しており、関連するメタデータが含まれています。たとえば、
{ "_id": { "$oid": "696493bfbc1084032ac0adfe" }, "title": "Ukraine updates, Day 6: ‘We are sacrificing our lives for freedom,’ Zelenskyy gets standing ovation after speech to European parliament", "link": "https://nationalpost.com/news/world/ukraine-updates-day-6-russia-kyiv", "keywords": null, "creator": [ "National Post Wire Services" ], "video_url": null, "description": "Russia escalated shelling overnight of key cities in Ukraine as its troops on the ground move slowly in a large convoy toward the capital, Kyiv", "content": "8:20 a.m. EST — Ukraine's Zelenskyy tells EU: 'Prove that you are with us\" Read More", "pubDate": "2022-03-01 13:45:04", "expire_at": "Wed, 07 Sep 2022 13:45:04 GMT", "image_url": null, "source_id": "nationalpost", "country": [ "canada" ], "category": [ "top" ], "language": "english" }
user_events コレクションには、ユーザー向けのアプリケーションから取り込まれた未加工のクリックストリーム イベントが含まれています。この例では、コレクションは ClickstreamCluster クラスターの news データベースにあります。
希望のイベントコレクションシステムを使用して、クリックストリームデータソースを設定できます。参照用のアーキテクチャ図に示されている方法を再現するには、ユーザー向けアプリケーションにイベントコレクション API を実装して、クリックイベントをApache Kafkaトピックに送信します。次に、MongoDB Kafka Sink Connector を使用して、クリックストリーム トピックから読み取り、MongoDB クラスターの user_events コレクションに書き込みます。
各記事のクリックごとに、session_id、article_id、timestamp などのフィールドを含むイベントドキュメントが生成されます。たとえば、
{ "_id": { "$oid": "696a1ecd66a51be18fffb8fa" }, "user_id": "user-2", "session_id": "sess-6a0d8837-a5f9-4ef5-8b00-78e9bf7a825c", "timestamp": { "$date": "2026-01-16T16:49:41.208Z" }, "event_type": "read", "article_id": { "$oid": "696493e6bc1084032ac116ed" }, "device": "desktop", "metadata": { "time_on_page": 54, "referral": "https://guzman.com/main/search/listmain.jsp" } }
Stream Processing ワークスペースを作成します。
Atlas で、プロジェクトの [Stream Processing] ページに移動します。
まだ表示されていない場合は、プロジェクトを含む組織をナビゲーション バーの [ Organizations ] メニューで選択します。
まだ表示されていない場合は、ナビゲーション バーの Projects メニューからプロジェクトを選択します。
サイドバーで、 Streaming Data見出しの下のStream Processingをクリックします。
Atlas Stream Processingページが表示されます。
[Create a workspace] をクリックします。
Create a stream processing workspaceページで、ワークスペースを次のように設定します。
Tier:
SP30Provider:
AWSRegion:
us-east-1Workspace Name:
article-personalization
クリックストリームと記事データの接続を追加します。
ストリーム プロセッサは、エンリッチメントを実行するために、クリックストリーム データと記事メタデータの両方に接続する必要があります。両方のデータソースは同じ Atlas クラスターにある必要があります。
Stream Processing ワークスペースのペインで、Manage をクリックします。
[ Connection Registryタブで、右上の [ + Add Connection ] をクリックします。
Edit Connectionページで、接続を次のように構成します。
接続タイプ:
Atlas Database接続名:
usereventsAtlas クラスター: クリックストリームと記事データが存在するクラスターの名前(例:
ClickstreamCluster)次として実行:
Read and write to any database
Save changes をクリックして接続を作成します。
永続的なストリーム プロセッサを作成します。
userIntentSummarizer というストリームプロセッサと、未加工のクリックストリームイベントを user_events コレクションから読み取り、記事メタデータでイベントを強化するステージを作成します。
Atlasプロジェクトの Stream Processing ページで、Stream Processing ワークスペースのペインにあるManage をクリックします。
JSON editor で、次のJSON定義をコピーしてJSONエディターのテキストボックスに貼り付け、これらのステージを持つ
userIntentSummarizerという名前のストリーム プロセッサを定義します。$source: 接続されたクリックストリームクラスター(userevents接続)のnewsデータベースにあるuser_eventsコレクションから未加工のクリックストリームイベントを読み取ります。$lookup:article_idフィールドに基づいてarticlesコレクションと生のクリックストリームイベントを結合し、description、keywords、titleフィールドから関連する記事のメタデータを取り込みます。$addFields:article_detailsフィールドからdescription、keywords、titleフィールドをイベントストリームのトップレベルに投影し、下流ステージから簡単にアクセスできるようにします。$project: 下流プロセシングの関連フィールドを投影します。
{ "$source": { "connectionName": "userevents", "db": "news", "collection": "user_events" } }, { "$lookup": { "from": { "connectionName": "userevents", "db": "news", "coll": "articles" }, "localField": "article_id", "foreignField": "_id", "as": "article_details", "pipeline": [ { "$project": { "_id": 0, "description": 1, "keywords": 1, "title": 1 } } ] } }, { "$addFields": { "description": { "$arrayElemAt": [ "$article_details.description", 0 ] }, "keywords": { "$arrayElemAt": [ "$article_details.keywords", 0 ] }, "title": { "$arrayElemAt": [ "$article_details.title", 0 ] } } }, { "$project": { "userId": 1, "article_id": 1, "eventTime": 1, "event_type": 1, "device": 1, "session_id": 1, "description": 1, "keywords": 1, "title": 1 } }, 変更を保存するには、[Update stream processor] をクリックします。
フェーズ 2: ユーザー行動のセッション化と要約
このフェーズでは、ストリーム プロセッサ パイプラインを拡張して、関連するクリックをセッションにグループ化し、LLM を使用して、ユーザーの興味を説明する各セッションの自然言語要約を生成します。
LLM プロバイダーをStream Processingワークスペースに接続します。
外部 HTTPS 接続を LLM プロバイダー(例: Azure OpenAI)に追加して、ストリームプロセッサを有効にし、パイプラインから LLM を直接呼び出してデータを強化します。
Stream Processing ワークスペースのペインで、Manage をクリックします。
[ Connection Registryタブで、右上の [ + Add Connection ] をクリックします。
次のように接続を構成します。
接続タイプ:
HTTPS接続名:
azureopenaiURL: Azure OpenAIインスタンスのエンドポイントURL
ヘッダー: これらのキーと値のペアをヘッダーに追加します。
キー:
Content-Type、値:application/jsonキー:
api-key、値: Azure OpenAI APIキー
$sessionWindowステージを使用して、クリックストリーム データをセッション化します。
$sessionWindow ステージをストリームプロセッサ パイプラインに追加して、特定のセッションギャップに基づいて関連するイベントをセッションにグループ化します。このソリューションでは、セッションを60秒を超える非アクティブギャップのない同じ session_id からのイベントのシーケンスとして定義します。
このステージを、エンリッチメントステージの後に userIntentSummarizer パイプラインに追加します。
{ "$sessionWindow": { "partitionBy": "$session_id", "gap": { "unit": "second", "size": 60 }, "pipeline": [{ "$group": { "_id": "$session_id", "titles": { "$push": "$title" } } }] } }
$https ステージを使用して、ユーザーセッションを要約します。
$https ステージを追加して、Stream Processing パイプラインから LLM プロバイダーを直接呼び出します。このソリューションは Azure OpenAI を呼び出して、セッションの記事のタイトルに基づいてユーザーの関心を説明する各セッションの自然言語要約を生成します。
$sessionWindowステージの後に、このステージをパイプラインに追加します。
{ "$https": { "connectionName": "azureopenai", "method": "POST", "as": "apiResults", "config": { "parseJsonStrings": true }, "payload": [ { "$project": { "_id": 0, "model": "gpt-4o-mini", "response_format": { "type": "json_object" }, "messages": [ { "role": "system", "content": "You are an analytical assistant that specializes in behavioral summarization. You analyze short-term reading activity and infer user interests without making personal or sensitive assumptions the create a special field called summary. Summary must be a special field in the response. Respond only in JSON format.Return a JSON object with the following keys in this order: \n reasoning: (Internal scratchpad, briefly explain your analysis) \n user_interests: (The list of inferred interests) \n summary: (A concise summary based on the interests above)" }, { "role": "user", "content": { "$toString": "$titles" } } ] } } ] } }
注意
ストリーム プロセッサ自体は「インテリジェント」です。データがディスクに到達する前に、タイトルのリストをセマンティックサマリーに変換します(例: 「ユーザーは半導体製造ロジスティクスについて調べています)。これは、通常、未加工のセッションデータをデータベースに書き込み、その後アプリケーション サーバーから外部 API を呼び出す従来のバッチプロセシングパイプラインとは根本的に異なります。
セッションサマリーを新しいコレクションに書き込みます。
次のステージをパイプラインに追加して、LLM 出力からサマリーを抽出し、それを新しいコレクションに書き込みます。
$match: LLM 呼び出しが失敗しエラーが返されたセッションを除外し、データベースへの不完全なデータの書き込みを回避します。$addFields: LLMの出力からsummaryフィールドを抽出し、ドキュメントの最上位に追加します。$project: ドキュメントから未加工の LLM 出力を削除し、ノイズとストレージのコストを削減します。$merge:結果のドキュメントをクリックストリーム クラスター(userevents接続)のnewsデータベースにあるuser_intentと言う新しいコレクションに書き込みます。このコレクションの各ドキュメントはユーザーセッションを表し、ユーザーの興味の要約が含まれています。
{ "$match": { "titles": { "$exists": true }, "apiResults": { "$exists": true } } }, { "$addFields": { "summary": { "$arrayElemAt": [ "$apiResults.choices.message.content.summary", 0 ] } } }, { "$project": { "apiResults": 0 } }, { "$merge": { "into": { "coll": "user_intent", "connectionName": "userevents", "db": "news" } } }
ストリーム プロセッサを起動します。
クリックストリームデータを要約する準備ができたら、Stream Processing ワークスペースのストリームプロセッサのリストにある userIntentSummarizer プロセッサの Start アイコンをクリックします。
このパイプラインは、ユーザーの関心を捉えたセッション要約を含むドキュメントを user_intent コレクションに書き込みます。たとえば、
{ "_id": "sess-6a0d8837-a5f9-4ef5-8b00-78e9bf7a825c", "summary": "The user seems interested in geopolitical developments, especially in the Middle East, US political strategies involving Trump, and legal aspects of government operations.", "titles": [ "Israel and Hamas agree to part of Trump's Gaza peace plan, will free hostages and prisoners", "Top officials from US and Qatar join talks aimed at brokering peace in Gaza", "How Trump secured a Gaza breakthrough", "Ontario's anti-tariff ad is clever, effective and legally sound, experts say", "Shutdown? Trump's been dismantling the government all year", "AP News Summary at 7:58 p.m. EDT" ] }
以下は、完全な JSON 定義です。クリックストリーム データの取り込み、記事メタメタデータでの強化、ユーザー動作のセッション化、集約コマンドの呼び出しなど、フェーズ 1 と 2 で説明されているすべての操作を実行する userIntentSummarizer Stream プロセッサのユーザーの意図 および 新しいコレクションへのサマリーの書込み 。
{ "name": "userIntentSummarizer", "pipeline": [ { "$source": { "connectionName": "userevents", "db": "news", "collection": "user_events" } }, { "$lookup": { "from": { "connectionName": "userevents", "db": "news", "coll": "articles" }, "localField": "article_id", "foreignField": "_id", "as": "article_details", "pipeline": [ { "$project": { "_id": 0, "description": 1, "keywords": 1, "title": 1 } } ] } }, { "$addFields": { "description": { "$arrayElemAt": [ "$article_details.description", 0 ] }, "keywords": { "$arrayElemAt": [ "$article_details.keywords", 0 ] }, "title": { "$arrayElemAt": [ "$article_details.title", 0 ] } } }, { "$project": { "userId": 1, "article_id": 1, "eventTime": 1, "event_type": 1, "device": 1, "session_id": 1, "description": 1, "keywords": 1, "title": 1 } }, { "$sessionWindow": { "partitionBy": "$session_id", "gap": { "unit": "second", "size": 60 }, "pipeline": [{ "$group": { "_id": "$session_id", "titles": { "$push": "$title" } } }] } }, { "$https": { "connectionName": "azureopenai", "method": "POST", "as": "apiResults", "config": { "parseJsonStrings": true }, "payload": [ { "$project": { "_id": 0, "model": "gpt-4o-mini", "response_format": { "type": "json_object" }, "messages": [ { "role": "system", "content": "You are an analytical assistant that specializes in behavioral summarization. You analyze short-term reading activity and infer user interests without making personal or sensitive assumptions then create a special field called summary. Summary must be a special field in the response. Respond only in JSON format.Return a JSON object with the following keys in this order: \n reasoning: (Internal scratchpad, briefly explain your analysis) \n user_interests: (The list of inferred interests) \n summary: (A concise summary based on the interests above)" }, { "role": "user", "content": { "$toString": "$titles" } } ] } } ] } }, { "$match": { "titles": { "$exists": true }, "apiResults": { "$exists": true } } }, { "$addFields": { "summary": { "$arrayElemAt": [ "$apiResults.choices.message.content.summary", 0 ] } } }, { "$project": { "apiResults": 0 } }, { "$merge": { "into": { "coll": "user_intent", "connectionName": "userevents", "db": "news" } } } ] }
フェーズ 3:セマンティック検索とパーソナライズされた推薦の提供
最後に、MongoDB Vector Search を使用して、前のフェーズで生成されたセッションの概要に基づいて記事カタログのセマンティック検索を実行し、パーソナライズされたコンテンツを推奨します。
セマンティック検索用に記事データを準備します。
セマンティック検索を実行する前に、記事データのベクトル埋め込みを生成する必要があります。これを行うには、articles コレクションの description フィールドを autoEmbed タイプとしてインデックス化する vector_index という MongoDB Vector Search インデックスを作成します。これは、MongoDB Vector Search に自動埋め込みを使用して、コレクションにドキュメントが挿入または更新されるたびに description フィールドのベクトル埋め込みを自動的に生成するように指示します。
重要
自動埋め込みは、 MongoDB Community Edition v8.2 以降でのみプレビュー機能として利用できます。機能および関連するドキュメントは、プレビュー期間中にいつでも変更される可能性があります。「プレビュー機能」を参照してください。
Atlasは、MongoDB のすべてのエディションで手動の埋め込みをサポートしています。
このJSON定義を使用して、これらのフィールドにベクトルインデックスを作成します。
autoEmbedタイプとしてのdescriptionフィールドは、ドキュメントがコレクションに挿入された場合や更新された場合に、MongoDB Vector Search にvoyage-4-large埋め込みモデルを使用して、descriptionフィールドのベクトル埋め込みを自動生成するよう指示します。titleフィールドをfilterタイプとして使用し、フィールドの string 値を使用してセマンティック検索のデータを前処理します。これにより、ユーザーがすでに読んだ記事を除外できます。
{ "fields": [ { "type": "autoEmbed", "modalitytype": "text", "path": "description", "model": "voyage-4-large" }, { "type": "filter", "path": "title" } ] }
セマンティック検索クエリを実行して、パーソナライズされた推薦を提供します。
ユーザーがサイトにアクセスすると、現在のセッションの概要を取得し、クエリとして使用して記事のカタログにたいしベクトル検索を実行します。インデックスで自動埋め込みを有効にしたため、MongoDB Vector Search はクエリ時に概要の埋め込みを自動的に生成し、それを有効なクエリベクトルとして使用します。
この例は、セッション summary をクエリベクトルとして使用し、titles フィールドに基づいてユーザーがすでに読んだ記事を除外する簡素化されたベクトル検索を示しています。
[{ "$vectorSearch": { "index": "vector_index", // Vector index with autoEmbed on article descriptions "path": "description", "query": { "text": "<session-summary>" // Session summary from user_intent document }, "numCandidates": 100, "filter": { "title": { "$nin": [<read-titles>] } // Exclude articles the array of titles in the user_intent document } } }]
キーポイント
このアーキテクチャは、最新のデータ製品を構築する際のいくつかの重要な利点を示しています。
レイテンシを削減: LLM 呼び出しをストリームプロセッサ内に直接埋め込むことで、複数のネットワークホップと中間的な永続性レイヤーが排除されます。システムは、未加工のクリックをほぼリアルタイムで実行可能な意図に変換します。
開発者体験の向上: JSONベースのMQLでパイプラインを定義すると、 MongoDB クエリをすでに知っているチームは、新しい DSL を学習したり、追加のインフラストラクチャをプロビジョニングしたりすることなく、高度なストリーミングと AI 活用型のワークロードを構築できます。
セマンティックのパーソナライズ: キーワードマッチングや夜間バッチジョブを超えてユーザーの行動を即座に聞き、考え、反応するシステムを構築します。
作成者
- Vinod Krishnan、ソリューションアーキテクト、MongoDB
詳細
Atlas ベクトル検索 がセマンティック検索を強化し、リアルタイム分析を可能にする方法については、Atlas ベクトル検索ページ をご覧ください。
MongoDB がメディア操作をどのように変換しているかについては、「 AI経由でのメディアのパーソナライズ: MongoDBとベクトル検索 」に関する記事をお読みください。
MongoDB が最新のメディアワークフローをどのようにサポートしているかを確認するには、MongoDB for メディアとエンタープライズ ページをご覧ください。
Atlas Stream Processingの詳細については、Atlas Stream Processing のドキュメントをご覧ください。