業種: メディア、電気通信
製品およびツール: MongoDB Atlas、 MongoDB ベクトル検索、 MongoDB Atlas Stream Processing
パートナー: 投票AI 、 Azure OpenAI
ソリューション概要
新しいユーザーがニュースサイトにアクセスしても、価値を失って離れる前に、ユーザーが何を求めているかを理解する秒数があります。これにより、コールド スタートの問題が発生します。つまり、以前のデータを持たないユーザーにコンテンツをどのように推奨するか?
サイトにアクセスし、3 つの記事をクリックする匿名ユーザーを考えてみましょう。
「NVIDI は新しいAIチャンクを作成します」
「TSMC がアナライザの本番環境を拡大します」
「遅延の中で遅延が発生します」
単純なキーワード検索では、Intel または Ar書込み保証 に関する他の記事のみが推奨されます。ただし、インテリジェント システムでは、3 つのすべてのクリックがメモリ チェーンに関連していることを認識します。これにより、ユーザーの閲覧履歴とキーワードを共有していない場合でも、「シノニムの将来」などの関連記事を推奨できます。
この記事のソリューションでは、クリックストリーム データを取り込んで処理するインテリジェントなメディア・パーソナライズ システムを構築し、ユーザーの興味に関する自然言語の概要を生成し、ユーザーが参加する可能性の高い関連記事を推奨します。
このソリューションは以下を組み合わせたものです。
クリックストリーム データのユーザー意向を要約するための、リアルタイムデータの取り込み、エンタープライズ、および LM 統合のための Atlas Stream Processing
セマンティック検索と推奨事項のための自動 Vyage AI埋め込みを備えた Atlas ベクトル検索
リファレンスアーキテクチャ
このアーキテクチャでは、 MongoDB Atlasを使用して、ユーザーの動作をリアルタイムで取り込み、処理し、応答するAI駆動型メディア推奨エンジンを構築する方法を示します。

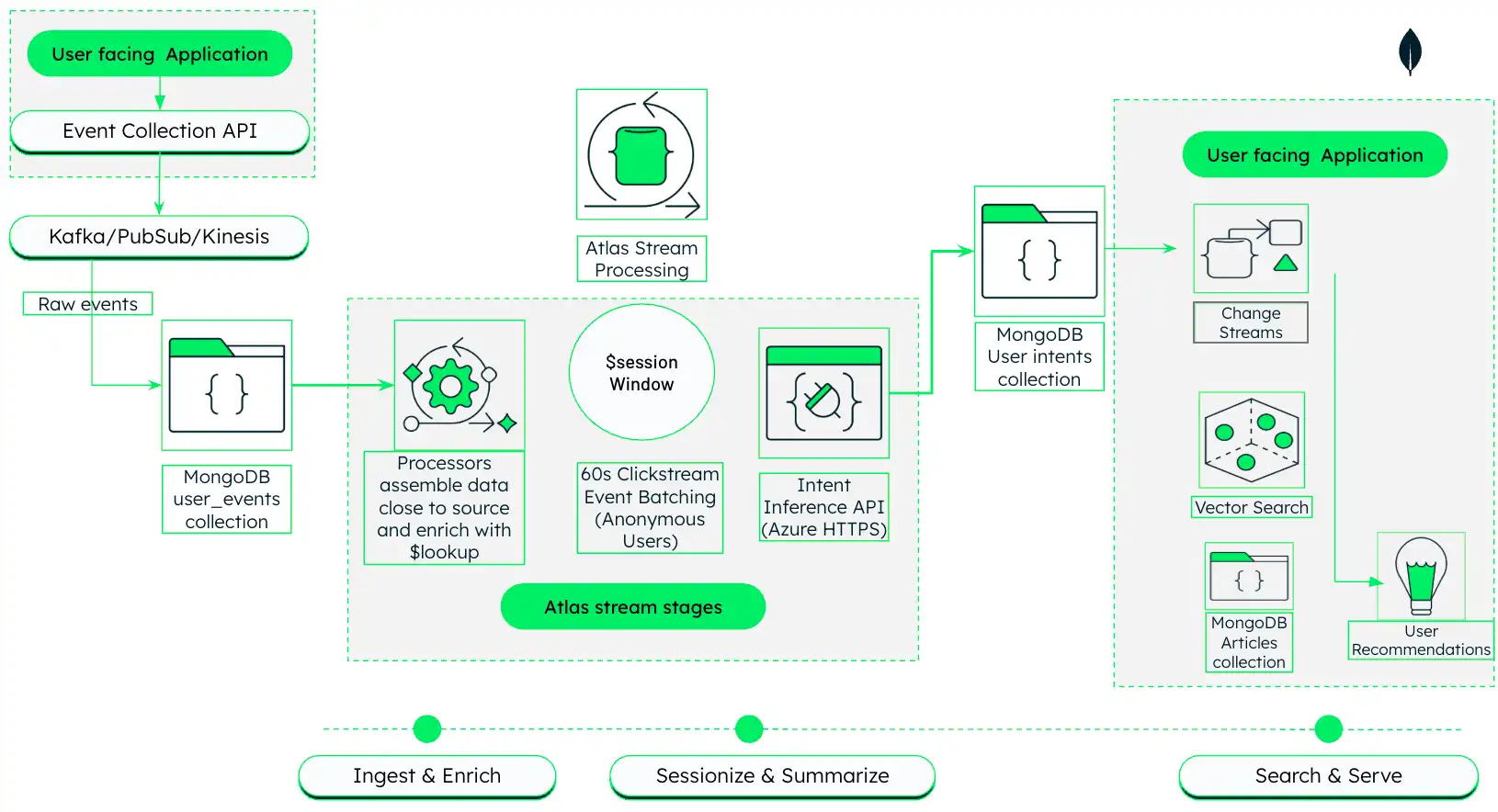
図の 1。 Atlas Stream Processing とMongoDB ベクトル検索を備えたAI駆動型メディアパーソナライズ アーキテクチャ
このアーキテクチャは 3 つのフェーズで動作します。これらについては、次のセクションで詳しく説明します。
Ingest と Encryption : ユーザー向けアプリケーションから未加工のクリックストリーム イベントをキャプチャし、Atlas Stream Processing を使用してリアルタイムで記事メタメタデータと結合します。
セッション化とサマリー: 関連するクリックをセッションにグループ化し、LDM を使用してユーザーの興味に関する自然言語のサマリーを生成します。
検索とサーバー: 生成されたサマリーを使用してセマンティックベクトル検索を実行し、パーソナライズされた推奨事項を返します。
フェーズ 1: クリックストリーム データの取り込みと豊富
最初のフェーズでは、このソリューション アーキテクチャは Atlas Stream Processing を使用して、メディアプラットフォームから未加工のクリックストリーム データを取り込み、データベース内の記事のメタデータで強化します。
データソースを設定します。
このソリューションでは、同じMongoDBクラスターの newsデータベースにある次の 2 つのコレクションを使用します。
articlesコレクションには、カタログ内の記事に関するメタデータが含まれています。この例ではコレクションはClickstreamCluster クラスターの newsデータベース内にあります。
コレクション内の各ドキュメントは記事を表し、関連するメタデータが含まれています。 (例: )。
{ "_id": { "$oid": "696493bfbc1084032ac0adfe" }, "title": "Ukraine updates, Day 6: ‘We are sacrificing our lives for freedom,’ Zelenskyy gets standing ovation after speech to European parliament", "link": "https://nationalpost.com/news/world/ukraine-updates-day-6-russia-kyiv", "keywords": null, "creator": [ "National Post Wire Services" ], "video_url": null, "description": "Russia escalated shelling overnight of key cities in Ukraine as its troops on the ground move slowly in a large convoy toward the capital, Kyiv", "content": "8:20 a.m. EST — Ukraine's Zelenskyy tells EU: 'Prove that you are with us\" Read More", "pubDate": "2022-03-01 13:45:04", "expire_at": "Wed, 07 Sep 2022 13:45:04 GMT", "image_url": null, "source_id": "nationalpost", "country": [ "canada" ], "category": [ "top" ], "language": "english" }
user_eventsコレクションには、 ユーザー向けアプリケーションから取り込まれた未加工のクリックストリーム イベントが含まれています。この例ではコレクションはClickstreamCluster クラスターの newsデータベース内にあります。
ご希望のイベントコレクションシステムを使用して、 クリックストリームデータソースを設定できます。参照アーキテクチャ図に示されているメソッドを再作成するには、ユーザー向けアプリケーションにイベントコレクションAPIを実装して、クリック イベントをApache Kafkaトピックに送信します。次に、 MongoDB Kafka Sink Connector を使用してクリックストリームトピックから読み取り、 MongoDBクラスターのuser_events コレクションに書き込みます。
記事をクリックするたびに、session_id、article_id、timestamp などのフィールドを含むイベントドキュメントが生成されます。 (例: )。
{ "_id": { "$oid": "696a1ecd66a51be18fffb8fa" }, "user_id": "user-2", "session_id": "sess-6a0d8837-a5f9-4ef5-8b00-78e9bf7a825c", "timestamp": { "$date": "2026-01-16T16:49:41.208Z" }, "event_type": "read", "article_id": { "$oid": "696493e6bc1084032ac116ed" }, "device": "desktop", "metadata": { "time_on_page": 54, "referral": "https://guzman.com/main/search/listmain.jsp" } }
Stream Processing ワークスペースを作成します。
Atlasで、プロジェクトのGo Stream Processing{0 ページに します。
まだ表示されていない場合は、プロジェクトを含む組織をナビゲーション バーの Organizations メニューで選択します。
まだ表示されていない場合は、ナビゲーション バーの Projects メニューからプロジェクトを選択します。
サイドバーで、 Streaming Data見出しの下のStream Processingをクリックします。
Atlas Stream Processingページが表示されます。
[Create a workspace] をクリックします。
Create a stream processing workspaceページで、ワークスペースを次のように設定します。
Tier:
SP30Provider:
AWSRegion:
us-east-1Workspace Name:
article-personalization
クリックストリームと記事データの接続を追加します。
ストリーム プロセッサは、エンティティを実行するためにクリックストリーム データと記事メタデータの両方に接続する必要があります。どちらのデータソースも同じ Atlas クラスター内になければなりません。
Stream Processing ワークスペースのペインで、Manage をクリックします。
[ Connection Registryタブで、右上の [ + Add Connection ] をクリックします。
Edit Connection ページで、次のように接続を構成します。
接続タイプ:
Atlas Database接続名:
usereventsAtlas クラスター: クリックストリームと記事 データが存在するクラスターの名前(例: 、
ClickstreamCluster)実行方法:
Read and write to any database
接続を作成するには、Save changes をクリックします。
永続的なストリーム プロセッサを作成します。
ステージを使用して、user_eventsコレクションから未加工のクリックストリーム イベントを読み取り、記事メタデータでイベントを強化するステージを持つ、userIntentSummarizer という名前のストリーム プロセッサを作成します。
Atlasプロジェクトの Stream Processing ページで、ストリーム処理ワークスペースのManage ペインにある [] をクリックします。
JSON editorで、次の JSON定義をコピーしてJSONエディターのテキストボックスに貼り付け、これらのステージを持つ という名前のストリーム
userIntentSummarizerプロセッサを定義します。$source:user_eventsnews接続されたクリックストリーム クラスター(userevents接続)の データベース内の コレクションから未加工のクリックストリーム イベントを読み取ります。$lookup: フィールドに基づいてarticlesコレクションと未加工のクリックストリーム イベントを結合し、article_iddescription、keywords、titleフィールドから関連する記事メタデータを取得します。$addFields:descriptionkeywordstitlearticle_detailsフィールドから 、 、 フィールドをイベントストリームの最上位にプロジェクションし、下流のステージから簡単にアクセスできるようにします。$project: 下流処理の関連フィールドをプロジェクションします。
{ "$source": { "connectionName": "userevents", "db": "news", "collection": "user_events" } }, { "$lookup": { "from": { "connectionName": "userevents", "db": "news", "coll": "articles" }, "localField": "article_id", "foreignField": "_id", "as": "article_details", "pipeline": [ { "$project": { "_id": 0, "description": 1, "keywords": 1, "title": 1 } } ] } }, { "$addFields": { "description": { "$arrayElemAt": [ "$article_details.description", 0 ] }, "keywords": { "$arrayElemAt": [ "$article_details.keywords", 0 ] }, "title": { "$arrayElemAt": [ "$article_details.title", 0 ] } } }, { "$project": { "userId": 1, "article_id": 1, "eventTime": 1, "event_type": 1, "device": 1, "session_id": 1, "description": 1, "keywords": 1, "title": 1 } }, 変更を保存するには、[Update stream processor] をクリックします。
フェーズ 2: ユーザー動作のセッション化と要約
このフェーズでは、ストリーム プロセッサパイプラインを拡張して、関連するクリックをセッションにグループ化し、LVM を使用して各セッションの自然言語のサマリーを生成し、ユーザーの興味を説明します。
LVM プロバイダーをストリーム処理ワークスペースに接続します。
LM プロバイダー(例、 Azure OpenAI)に外部 HTTPS 接続を追加して、ストリーム プロセッサがパイプラインから LM を直接呼び出してデータを増やすようにします。
Stream Processing ワークスペースのペインで、Manage をクリックします。
[ Connection Registryタブで、右上の [ + Add Connection ] をクリックします。
次のように接続を構成します。
接続タイプ:
HTTPS接続名:
azureopenaiURL : Azure OpenAIインスタンスのエンドポイントURL
ヘッダー: 次のキーと値のペアを ヘッダーに追加します。
キー:
Content-Type、値:application/jsonキー:
api-key、値: Azure OpenAI APIキー
ステージを使用してクリックストリーム$sessionWindow データをセッション化します。
$sessionWindow指定されたセッション ギャップに基づいて関連するイベントをセッションにグループ化するには、ストリーム プロセッサパイプラインに ステージを追加します。このソリューションでは、セッションは、非アクティブなギャップがsession_id 60秒以上ない同じ からのイベントのシーケンスとして定義されます。
このステージを エンタープライズ ステージの後に userIntentSummarizerパイプラインに追加します。
{ "$sessionWindow": { "partitionBy": "$session_id", "gap": { "unit": "second", "size": 60 }, "pipeline": [{ "$group": { "_id": "$session_id", "titles": { "$push": "$title" } } }] } }
$httpsステージを使用してユーザー セッションを要約します。
$httpsストリーム処理パイプラインから LM プロバイダーを直接呼び出すには、 ステージを追加します。このソリューションではAzure OpenAI を呼び出して、セッションの記事タイトルに基づいてユーザーの希望を説明する各セッションの自然言語のサマリーを生成します。
このステージを $sessionWindow ステージの後にパイプラインに追加する。
{ "$https": { "connectionName": "azureopenai", "method": "POST", "as": "apiResults", "config": { "parseJsonStrings": true }, "payload": [ { "$project": { "_id": 0, "model": "gpt-4o-mini", "response_format": { "type": "json_object" }, "messages": [ { "role": "system", "content": "You are an analytical assistant that specializes in behavioral summarization. You analyze short-term reading activity and infer user interests without making personal or sensitive assumptions the create a special field called summary. Summary must be a special field in the response. Respond only in JSON format.Return a JSON object with the following keys in this order: \n reasoning: (Internal scratchpad, briefly explain your analysis) \n user_interests: (The list of inferred interests) \n summary: (A concise summary based on the interests above)" }, { "role": "user", "content": { "$toString": "$titles" } } ] } } ] } }
注意
ストリーム プロセッサ自体は「インテリジェント」です。データがディスクに到達する前に、タイトルのリストをセマンティックなサマリー(例:これは、通常未加工のセッション データをデータベースに書込み、その後アプリケーションサーバーから外部APIを呼び出す従来のバッチする処理パイプラインとは基本的に異なります。
セッションのサマリーを新しいコレクションに書き込みます。
次のステージをパイプラインに追加して、LM 出力からサマリーを抽出し、それを新しいコレクションに書込みます。
$match: LM 呼び出しが失敗しエラーが返されたセッションをフィルタリングで除外し、データベースへの不完全なデータの書込みを回避します。$addFields:summaryLM 出力から フィールドを抽出し、それをドキュメントの最上位に追加します。$project:ドキュメントから未加工の LM 出力を排除し、ノイズとストレージのコストを削減します。$merge:user_intentnews結果のドキュメントを、クリックストリーム クラスターの データベースにある という新しいコレクションに書き込みます(userevents接続)。このコレクション内の各ドキュメントはユーザー セッションを表し、ユーザーの興味の概要が含まれています。
{ "$match": { "titles": { "$exists": true }, "apiResults": { "$exists": true } } }, { "$addFields": { "summary": { "$arrayElemAt": [ "$apiResults.choices.message.content.summary", 0 ] } } }, { "$project": { "apiResults": 0 } }, { "$merge": { "into": { "coll": "user_intent", "connectionName": "userevents", "db": "news" } } }
ストリーム プロセッサを起動します。
クリックストリーム データの概要を開始する準備ができたら、ストリーム処理ワークスペースのストリーム プロセッサのリストにある userIntentSummarizer プロセッサの Start アイコンをクリックします。
このパイプラインは、ユーザーの興味をキャプチャするセッション サマリーを含むドキュメントを user_intentコレクションに書き込む必要があります。 (例: )。
{ "_id": "sess-6a0d8837-a5f9-4ef5-8b00-78e9bf7a825c", "summary": "The user seems interested in geopolitical developments, especially in the Middle East, US political strategies involving Trump, and legal aspects of government operations.", "titles": [ "Israel and Hamas agree to part of Trump's Gaza peace plan, will free hostages and prisoners", "Top officials from US and Qatar join talks aimed at brokering peace in Gaza", "How Trump secured a Gaza breakthrough", "Ontario's anti-tariff ad is clever, effective and legally sound, experts say", "Shutdown? Trump's been dismantling the government all year", "AP News Summary at 7:58 p.m. EDT" ] }
以下は、クリックストリーム userIntentSummarizerデータの取り込み、記事メタメタデータでの強化、ユーザー動作のセッション化、LM の呼び出しなど、フェーズ1 と で説明されているすべての操作を実行する ストリーム プロセッサの完全なJSON定義です。ユーザーの意図2 および 新しいコレクションへのサマリーの書込み 。
{ "name": "userIntentSummarizer", "pipeline": [ { "$source": { "connectionName": "userevents", "db": "news", "collection": "user_events" } }, { "$lookup": { "from": { "connectionName": "userevents", "db": "news", "coll": "articles" }, "localField": "article_id", "foreignField": "_id", "as": "article_details", "pipeline": [ { "$project": { "_id": 0, "description": 1, "keywords": 1, "title": 1 } } ] } }, { "$addFields": { "description": { "$arrayElemAt": [ "$article_details.description", 0 ] }, "keywords": { "$arrayElemAt": [ "$article_details.keywords", 0 ] }, "title": { "$arrayElemAt": [ "$article_details.title", 0 ] } } }, { "$project": { "userId": 1, "article_id": 1, "eventTime": 1, "event_type": 1, "device": 1, "session_id": 1, "description": 1, "keywords": 1, "title": 1 } }, { "$sessionWindow": { "partitionBy": "$session_id", "gap": { "unit": "second", "size": 60 }, "pipeline": [{ "$group": { "_id": "$session_id", "titles": { "$push": "$title" } } }] } }, { "$https": { "connectionName": "azureopenai", "method": "POST", "as": "apiResults", "config": { "parseJsonStrings": true }, "payload": [ { "$project": { "_id": 0, "model": "gpt-4o-mini", "response_format": { "type": "json_object" }, "messages": [ { "role": "system", "content": "You are an analytical assistant that specializes in behavioral summarization. You analyze short-term reading activity and infer user interests without making personal or sensitive assumptions then create a special field called summary. Summary must be a special field in the response. Respond only in JSON format.Return a JSON object with the following keys in this order: \n reasoning: (Internal scratchpad, briefly explain your analysis) \n user_interests: (The list of inferred interests) \n summary: (A concise summary based on the interests above)" }, { "role": "user", "content": { "$toString": "$titles" } } ] } } ] } }, { "$match": { "titles": { "$exists": true }, "apiResults": { "$exists": true } } }, { "$addFields": { "summary": { "$arrayElemAt": [ "$apiResults.choices.message.content.summary", 0 ] } } }, { "$project": { "apiResults": 0 } }, { "$merge": { "into": { "coll": "user_intent", "connectionName": "userevents", "db": "news" } } } ] }
フェーズ 3: セマンティック検索とパーソナライズされた推奨事項の提供
最後に、 MongoDB ベクトル検索 を使用して、前のフェーズで生成されたセッションサマリーを使用して、記事カタログに対してセマンティック検索を実行し、パーソナライズされたコンテンツの推奨を実現します。
セマンティック検索用に記事データを準備します。
セマンティック検索を実行する前に、記事データのベクトル埋め込みを生成する必要があります。そのためには、 という名前のMongoDBvector_index ベクトル検索インデックスを作成し、description articlesコレクションのautoEmbed フィールドを タイプとしてインデックス化します。これは、ドキュメントがコレクションに挿入または更新されるたびに、自動埋め込みを使用して フィールドのベクトル埋め込みを自動的に生成するようにMongoDB descriptionベクトル検索に指示します。
重要
自動埋め込みは、 MongoDB Community Edition v8.2 以降でのみプレビュー機能として利用できます。機能および関連するドキュメントは、プレビュー期間中にいつでも変更される可能性があります。「プレビュー機能」を参照してください。
Atlas はMongoDBのすべてのエディションで手動埋め込みをサポートしています。
このJSON定義を使用して、これらのフィールドにベクトルインデックスを作成します。
autoEmbedタイプとしてのdescriptionフィールドは、ドキュメントがコレクションに挿入または更新されるたびに、voyage-4-large埋め込みモデルを使用してdescriptionフィールドのベクトル埋め込みを自動的に生成するようにMongoDB ベクトル検索に指示します。フィールドの string 値を使用して、セマンティック検索のデータを事前にフィルタリングするための
filterタイプとしてのtitleフィールド。これにより、ユーザーがすでに読み取った記事を検索結果から除外できます。
{ "fields": [ { "type": "autoEmbed", "modalitytype": "text", "path": "description", "model": "voyage-4-large" }, { "type": "filter", "path": "title" } ] }
パーソナライズされた推奨事項を提供するには、 セマンティック検索クエリ を実行します。
ユーザーがサイトにアクセスすると、 は現在のセッションの概要を取得し、それをクエリとして使用して記事カタログに対するベクトル検索を実行します。インデックスで自動埋め込みを有効にしたため、 MongoDB ベクトル検索 はクエリ時にサマリーとしての埋め込みを自動的に生成し、それを有効なクエリベクトルとして使用します。
この例では、セッション summary をクエリベクトルとして使用し、titlesフィールドに基づいてユーザーがすでに読み取った記事を除外する単純化されたベクトル検索クエリーを示します。
[{ "$vectorSearch": { "index": "vector_index", // Vector index with autoEmbed on article descriptions "path": "description", "query": { "text": "<session-summary>" // Session summary from user_intent document }, "numCandidates": 100, "filter": { "title": { "$nin": [<read-titles>] } // Exclude articles the array of titles in the user_intent document } } }]
キーポイント
このアーキテクチャは、最新のデータ製品を構築する際のいくつかの重要な利点を示しています。
レイテンシを削減 : LVM 呼び出しをストリーム プロセッサ内に直接埋め込むことで、複数のネットワーク ドロップと中間永続性レイヤーが排除されます。システムは、未加工のクリックをほぼリアルタイムで実行可能な意向に変換します。
開発者エクスペリエンスの向上: JSONベースのMQLでパイプラインを定義し、 MongoDBクエリをすでに知っているチームは、新しい DSL を学習したり、追加のインフラストラクチャをプロビジョニングことなく、高度なストリーミングとAIを使用したワークロードを構築できます。
セマンティック パーソナライズ: キーワード マッチングやオーバーライドバッチするジョブを超え、ユーザーの動作をリッスンし、判断して、即座に応答するシステムを構築します。
作成者
MongoDB 、ソリューション アーキテクチャ、V ind KrishMany
詳細
Atlas ベクトル検索 がセマンティック検索を強化し、リアルタイム分析を可能にする方法については、Atlas ベクトル検索ページ をご覧ください。
MongoDB がメディア操作をどのように変換しているかについては、「 AI経由でのメディアのパーソナライズ: MongoDBとベクトル検索 」に関する記事をお読みください。
MongoDB が最新のメディアワークフローをどのようにサポートしているかを確認するには、MongoDB for メディアとエンタープライズ ページをご覧ください。
Atlas Stream Processing の詳細については、 Atlas Stream Processing のドキュメントを参照してください。