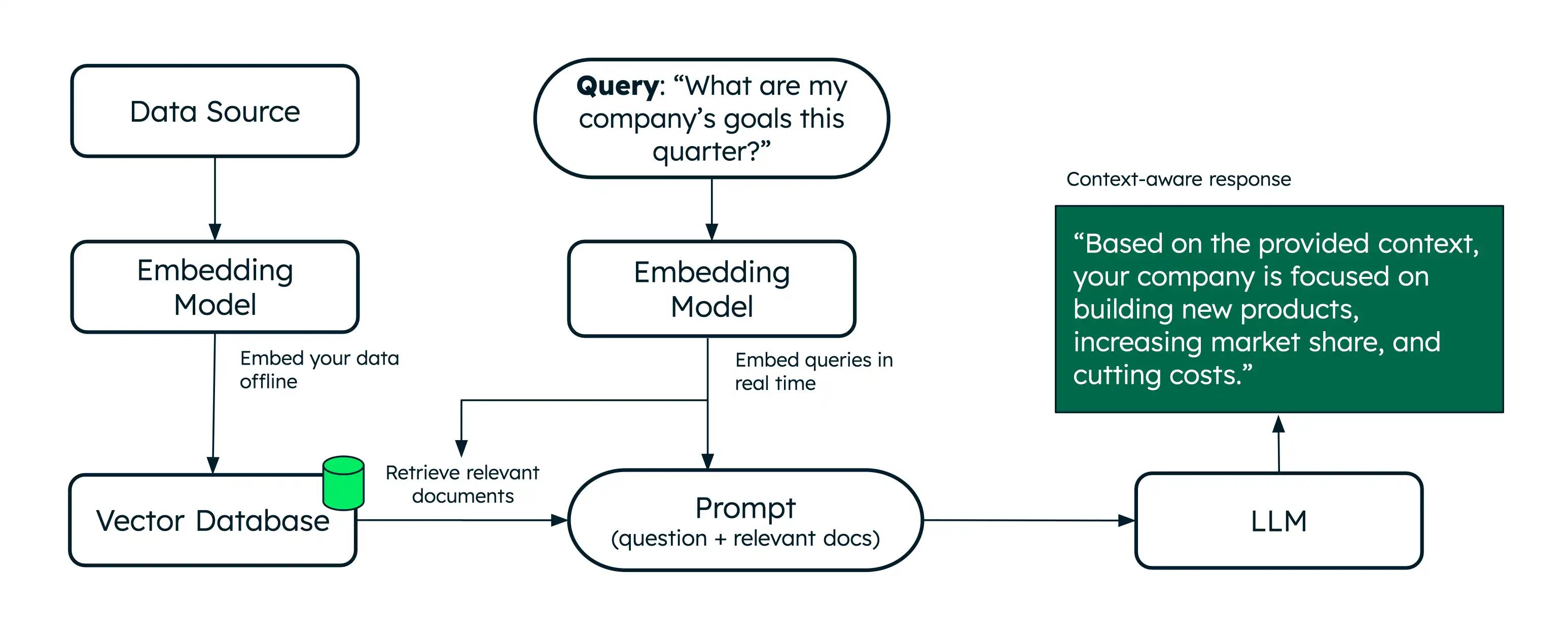
La generación de recuperación aumentada (RAG) es una arquitectura que utiliza búsqueda semántica para reforzar los grandes modelos de lenguaje (LLM) con datos adicionales, permitiéndoles generar respuestas más precisas.
Mientras que la búsqueda semántica recupera documentos relevantes basados en el significado, RAG lleva esto un paso más allá al proporcionar esos documentos recuperados como contexto a un LLM. Este contexto adicional ayuda al LLM a generar una respuesta más precisa a la query de un usuario, reduciendo las alucinaciones. Voyage IA proporciona modelos de embedding y reranking de primer nivel para potenciar la recuperación en tus aplicaciones RAG.
Para probar RAG sin programar, usa Playground para crear un chatbot de IA con Voyage AI. Para más información, consulta Chatbot Demo Builder.
Tutorial
El siguiente tutorial demuestra cómo implementar RAG con incrustaciones de Voyage.
También puede trabajar con el código de este tutorial clonando el repositorio de GitHub.
¿Por qué utilizar RAG?
Al trabajar con LLM, es posible que encuentres las siguientes limitaciones:
Datos obsoletos: los LLMs están entrenados con un conjunto de datos estáticos hasta un cierto punto en el tiempo. Esto significa que tienen una base de conocimientos limitada y podrían utilizar datos obsoletos.
Sin acceso a datos adicionales: Los LLM no tienen acceso a datos locales, personalizados o específicos del dominio. Por lo tanto, se puede carecer de conocimientos en dominios específicos.
Alucinaciones: Al utilizar datos incompletos u obsoletos, los LLM pueden generar respuestas inexactas.
RAG aborda estas limitaciones añadiendo un paso de recopilación, normalmente impulsado por búsqueda semántica, para obtener documentos relevantes en tiempo real. Proporcionar contexto adicional ayuda a los LLM a generar respuestas más precisas. Esto convierte a RAG en una arquitectura efectiva para crear chatbots de IA que ofrezcan respuestas personalizadas, específicas del dominio, y generación de texto.
¿Qué son las bases de datos vectoriales?
Las bases de datos vectoriales son bases de datos especializadas diseñadas para almacenar y recuperar eficazmente embeddings vectoriales. Si bien almacenar vectores en memoria es adecuado para el prototipado y la experimentación, las aplicaciones de RAG en producción normalmente requieren una base de datos vectorial para realizar una recuperación eficiente a partir de un corpus más grande.
MongoDB tiene soporte nativo para el almacenamiento y recuperación de vectores, lo que lo convierte en una opción conveniente para almacenar y buscar incrustaciones de vectores junto con tus demás datos. Para obtener más información, consulta MongoDB Vector Search Overview.
Próximos pasos
Para obtener tutoriales adicionales, consulte los siguientes recursos:
Para aprender cómo implementar RAG con marcos LLM populares y servicios de IA, consulta Integraciones de IA de MongoDB.
Para compilar agentes de IA e implementar RAG agéncico, consulta Compila agentes de IA con MongoDB.