Overview
Puedes estructurar tu clúster con diferentes tipos de implementaciones, proveedores de nube y niveles de clúster para satisfacer las necesidades de un entorno de preproducción o producción. Utilice estas recomendaciones para seleccionar el tipo de implementación, el proveedor de nube y la región, así como los niveles de clúster y búsqueda para realizar una búsqueda vectorial.
Entorno | Tipo de implementación | Nivel de clúster | Región del Proveedor de la Nube | Arquitectura de nodo |
|---|---|---|---|---|
Consultas de prueba | Clúster Flexible o Dedicado | Clúster gratuito, Flex o de nivel superior | Todos | Los procesos de MongoDB y búsqueda se ejecutan en el mismo nodo |
Prototipado de aplicaciones | Clúster dedicado, particionado o sin partición |
| Todo | Los procesos de MongoDB y búsqueda se ejecutan en el mismo nodo |
Producción | clúster dedicado con nodos de búsqueda separados, particionado o no particionado |
| AWS y Azure en algunas regiones o Google Cloud en todas las regiones | Los procesos de MongoDB y Search se ejecutan en diferentes nodos |
Las siguientes secciones describen cada entorno:
Entornos de pruebas y prototipos
Para probar tus consultas de búsqueda y prototipar tu aplicación, te recomendamos el tipo de implementación y la arquitectura de nodos que se describen en las siguientes secciones.
Esta configuración es la más adecuada para los siguientes casos de uso:
Menos de 2M de documentos totales para indexar
Menos de 10GB de datos indexados.
Menos de 10,000 consultas en un período de 7días
Si tu uso excede los valores listados, migra a nodos de búsqueda dedicados.
Las siguientes secciones describen esta arquitectura de nodo con más detalle.
- Tipo de implementación
Para probar consultas de MongoDB Search en clústeres en la nube, puedes implementar un clúster Flex o un clúster dedicado.
Para probar las consultas de MongoDB Search localmente, crea una implementación local de Atlas usando el Atlas CLI. Esto podría ser un set de réplicas de un solo nodo alojado en tu computadora local. Las implementaciones locales están limitadas por la CPU, la memoria y los recursos de almacenamiento de tu computadora local. Cuando tu aplicación esté lista para producción, migra tu implementación local de Atlas a un entorno de producción.
- Cluster Tiers
Para probar sus consultas de MongoDB Search, use clústeres gratuitos (antes conocidos como
M0) y clústeres flexibles.Para la creación de prototipos de tu aplicación, usa clústeres
M10,M20y de nivel superior dedicados, o implementa nodos dedicados de búsqueda para el aislamiento de cargas de trabajo. Cuando su aplicación esté lista para producción y para gestionar conjuntos de datos grandes, escalar a niveles superiores.- Proveedor de nube y región
Utiliza cualquier región de proveedor de nube compatible.
El proveedor de nube y la región que elijas afectan las opciones de configuración disponibles para los niveles del clúster y el costo de operar el clúster.
Arquitectura de nodo
Para entornos de prueba y creación de prototipos, recomendamos una arquitectura de nodo en la que los procesos de MongoDB y los procesos de MongoDB Search se ejecuten en el mismo nodo. En el siguiente diagrama de este modelo de implementación, el proceso de MongoDB Search mongot se ejecuta junto con mongod en cada nodo del clúster de Atlas y comparten los mismos recursos.
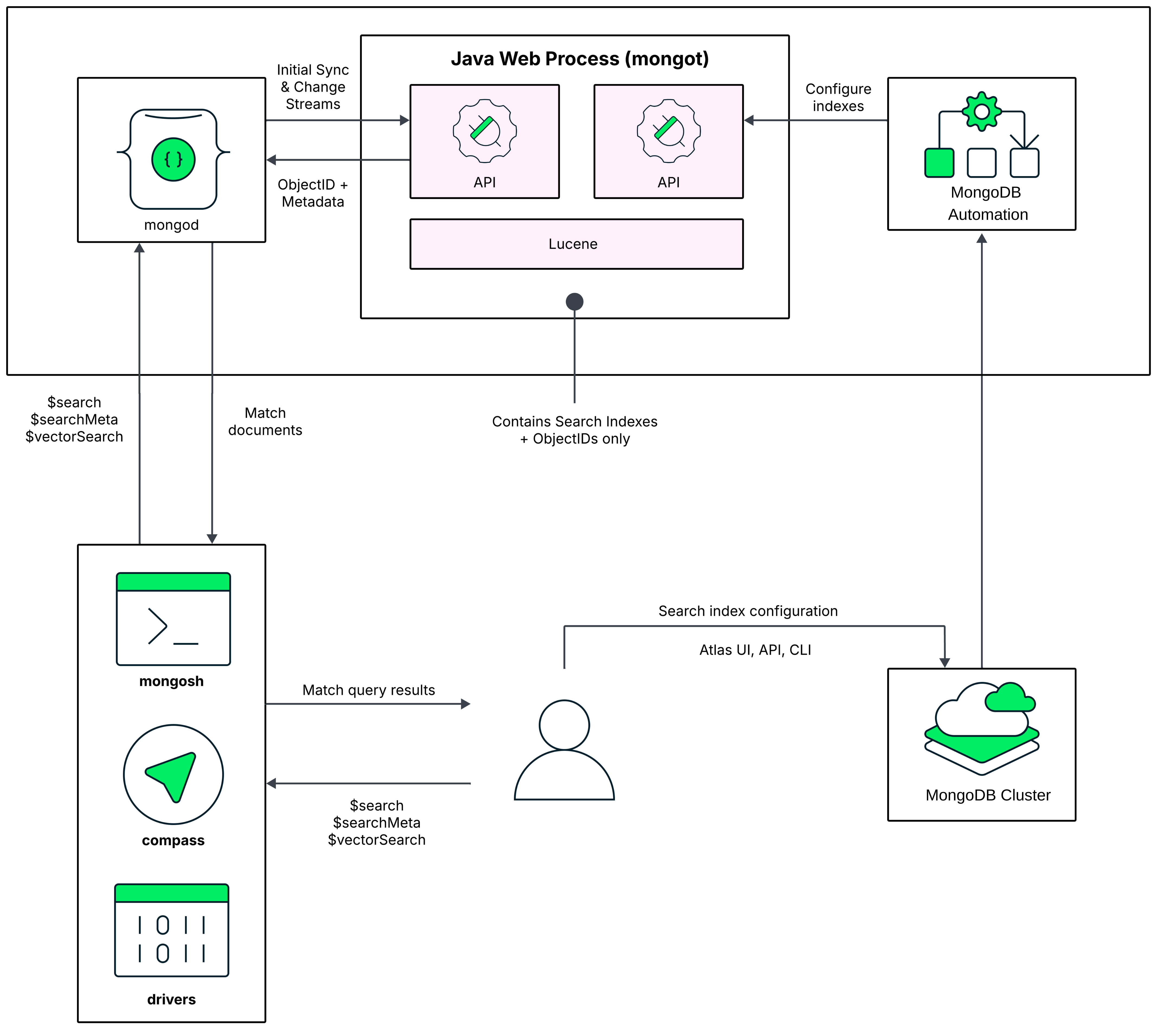
Por defecto, Atlas habilita el proceso MongoDB Search mongot en el mismo nodo que ejecuta el proceso mongod cuando creas tu primer índice MongoDB Search.
Para aprender cómo MongoDB Search procesa las query en esta arquitectura, consulte Procesamiento de query.
Puede definir fuentes almacenadas campos en su índice de MongoDB Search para que el proceso mongot pueda almacenar los campos especificados en mongot. Luego puede utilizar la opción returnStoredSource en su consulta MongoDB Search para recuperar los campos almacenados para los documentos coincidentes directamente desde mongot en lugar de realizar una búsqueda completa de documentos en la base de datos.
Beneficios
Cuando activas MongoDB Search, puedes generar búsquedas fácilmente sobre tus datos con un motor de búsqueda integrado, totalmente gestionado y que se sincroniza automáticamente con tu base de datos. MongoDB Search ofrece un languaje del query robusto que utiliza etapas del pipeline de agregación de MongoDB Search como $search y $searchMeta para búsquedas de texto completo, y $vectorSearch para búsquedas semánticas junto con otras etapas del pipeline de agregación de MongoDB y clasificación de los resultados basada en puntuaciones.
Dependiendo de los recursos aprovisionados para tu clúster, implementar ambos procesos en el mismo nodo podría ser más rentable que ejecutar el proceso de búsqueda en un nodo dedicado por separado.
Limitaciones
Puedes experimentar una contención de recursos entre la base de datos mongod y los procesos de búsqueda mongot. Esto podría afectar negativamente al rendimiento de su índice y a la latencia de sus consultas. Para admitir aplicaciones listas para producción y sus cargas de trabajo de búsqueda, migra a nodos de búsqueda dedicados.
Costo
No hay tarifas ni cargos adicionales por habilitar MongoDB Search en tu clúster. Sin embargo, podrías observar un aumento en la utilización de recursos en el clúster para grandes colecciones indexadas o definiciones de índices.
Considerations
Puesto que los procesos mongod y mongot se ejecutan en el mismo nodo, es posible que mongot deje de estar disponible en determinadas circunstancias. En la siguiente tabla se describen las posibles causas:
Causa | Descripción |
|---|---|
Escalado de nivel de clúster - almacenamiento de red | Cuando escales un clúster hacia arriba o hacia abajo, Atlas aprovisiona una nueva instancia. Una vez que la instancia está lista, Atlas adjunta el almacenamiento de red e inicia Si |
Escalado de nivel de clúster - SSDlocal | Cuando escalas un clúster Atlas usando SSD local (SSD), no puedes conservar el almacenamiento y volver a adjuntarlo a los nuevos nodos. Por lo tanto, Atlas realiza una sincronización inicial para reconstruir los índices de búsqueda. Las consultas de búsqueda fallan hasta que se complete la sincronización inicial. |
Downgrade de Lucene | En casos excepcionales en los que se requiere realizar un downgrade de Lucene, es posible que no se puedan leer los formatos de índice de Lucene más recientes. |
Ajuste de almacenamiento | Se puede conservar el almacenamiento en red conectado a los nodos del clúster de Atlas. Esto le permite expandir o contraer la capacidad de volumen sin impacto en Sin embargo, conservar el almacenamiento en red puede no ser posible en ciertas regiones, cuando el clúster utiliza discos locales NVMe, o en otras circunstancias poco frecuentes. En estos casos, Atlas realiza una sincronización inicial y las consultas de búsqueda fallan hasta que se complete la sincronización inicial. |
| Durante una actualización de la versión |
Nuevo nodo | Cuando añades un nuevo nodo a tu clúster, Atlas realiza una sincronización inicial para crear los índices de búsqueda. Las consultas de búsqueda que utilizan el nuevo nodo |
Reinicio o reemplazo de instancia |
|
| Cada vez que el proceso |
Ambiente de producción
Para su aplicación lista para producción, recomendamos utilizar el tipo de implementación y la arquitectura de nodos descritos en las siguientes secciones.
Esta configuración es la más adecuada para los siguientes casos de uso:
Si decides migrar tu entorno de pruebas existente a producción, agrega Search Nodes (nodos de búsqueda) exclusivos a tu clúster. Para obtener más información, consulta Migrar a nodos de búsqueda dedicados.
Si creas una nueva implementación de producción desde cero, asegúrate de utilizar
M10o clústeres de mayor nivel que sean compatibles con MongoDB Search en las regiones y zonas donde MongoDB Search está disponible, y añade Nodos de Búsqueda dedicados a tu entorno. Para obtener más información, consulte Agregar nodos de búsqueda dedicados.
- Tipo de implementación
Para las aplicaciones listas para producción, utiliza
M10,M20y los niveles superiores de clústeres dedicados. Estos clústeres de nivel superior pueden gestionar grandes conjuntos de datos y cargas de trabajo de producción.Recomendamos también que implementes nodos de búsqueda dedicados. Si tus necesidades de búsqueda aumentan, puedes escalar tu implementación de búsqueda independientemente de escalar los nodos MongoDB.
- Proveedor de nube y región
Utiliza nodos de búsqueda en todas las regiones de Google Cloud y en un subconjunto de AWS y Azure regiones. Debes seleccionar un proveedor de nube y una región donde los nodos de búsqueda estén disponibles para tu implementación.
Todos los niveles de clúster están disponibles en las regiones de proveedores de nube compatibles. El proveedor de nube y la región que elijas afectan las opciones de configuración y los niveles de búsqueda disponibles para el clúster y el costo de operar el clúster.
Arquitectura de nodo
Para entornos de producción, recomendamos una arquitectura de nodos en la que los procesos de MongoDB y los procesos de MongoDB Search se ejecuten en nodos separados. Para implementar nodos de búsqueda separados, consulta Migrar a nodos de búsqueda dedicados.
En el siguiente diagrama de este modelo de despliegue, el proceso MongoDB Search mongot se ejecuta en nodos de búsqueda dedicados, que están separados de los nodos del clúster en los que se ejecuta el proceso mongod.
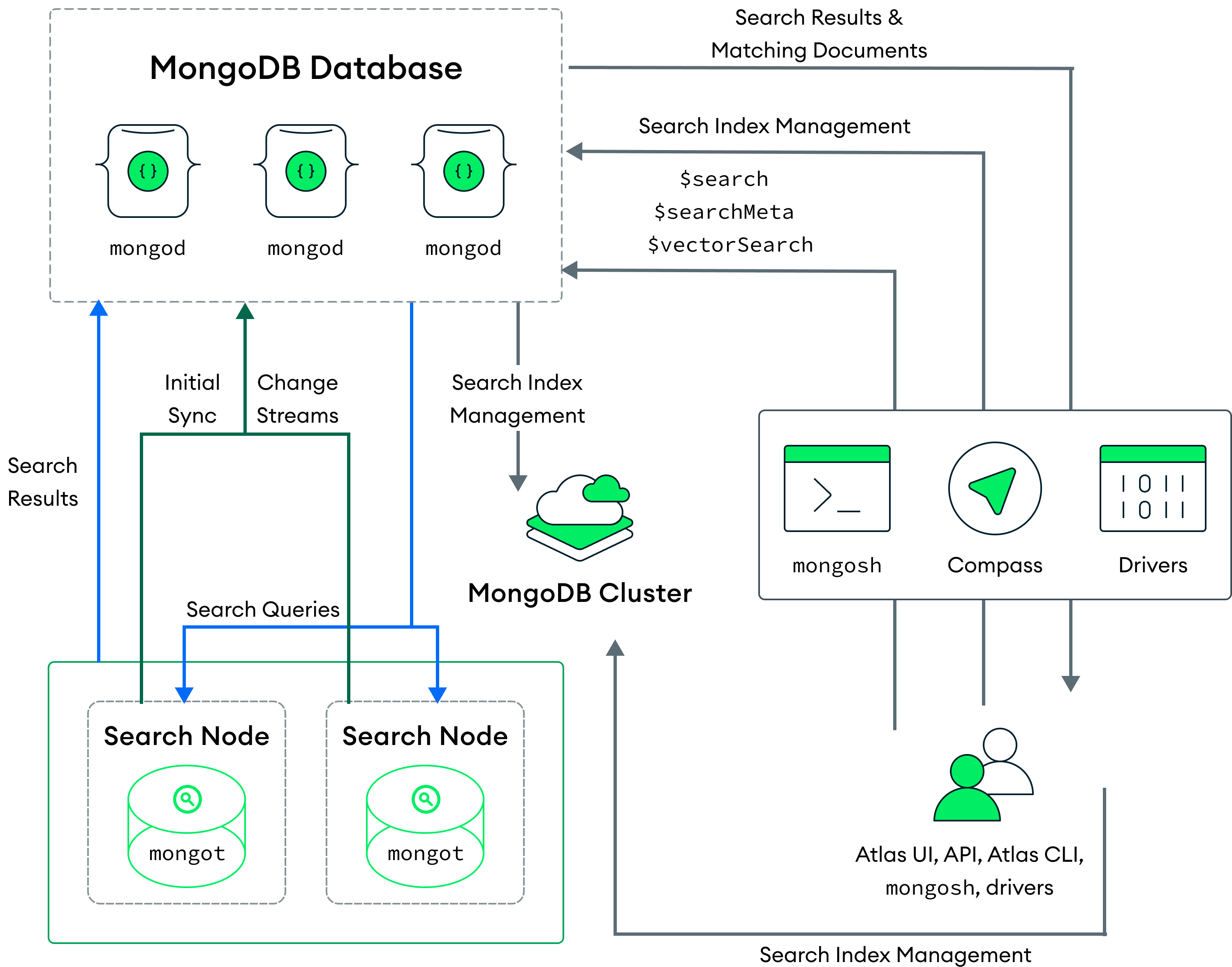
Atlas implementa nodos de búsqueda con cada clúster o con cada partición en el clúster. Por ejemplo, si implementas dos nodos de búsqueda para un clúster con tres particiones, Atlas implementa seis nodos de búsqueda (dos por partición). También puedes configurar el número de nodos de búsqueda y la cantidad de recursos aprovisionados para cada nodo de búsqueda.
Para aprender cómo MongoDB Search procesa las query en esta arquitectura, consulte Procesamiento de query.
Puede definir fuentes almacenadas campos en su índice de MongoDB Search para que el proceso mongot pueda almacenar los campos especificados en mongot. Luego puede utilizar la opción returnStoredSource en su consulta MongoDB Search para recuperar los campos almacenados para los documentos coincidentes directamente desde mongot en lugar de realizar una búsqueda completa de documentos en la base de datos.
Beneficios
El despliegue de nodos de búsqueda separados proporciona los siguientes beneficios:
- Alta disponibilidad
- Cuando implementas nodos de búsqueda separados, Atlas aplica un mínimo de dos nodos de búsqueda para garantizar que tu carga de trabajo siga operativa, con un tiempo de inactividad mínimo, en caso de una falla o interrupción.
- Escalabilidad
Cuando despliegue nodos de búsqueda por separado, puede escalar el almacenamiento y la computación independientemente de su clúster de MongoDB. Esto permite también escalar la carga de queries de forma independiente de MongoDB.
Para escalar los nodos de búsqueda horizontalmente, incrementa o reduce el número de nodos de búsqueda. Puedes provisionar desde un mínimo de 2 hasta un máximo de 32 nodos de búsqueda. Para equilibrar la carga de consultas, MongoDB Search distribuye las consultas de búsqueda entre todos los nodos de búsqueda disponibles.
Para escalar verticalmente los Nodos de Búsqueda, seleccione diferentes niveles de búsqueda, configuraciones de CPU, RAM y almacenamiento que admitan sus cargas de trabajo de texto completo.
- Rendimiento
Cuando implementas nodos de búsqueda dedicados, mejoras el rendimiento y la utilización de recursos tanto para los procesos
mongodcomomongot, y eliminas la competencia de recursos entre estos procesos.Los nodos de búsqueda dedicados admiten búsqueda de segmentos concurrentes, lo que permite a MongoDB Search buscar varios segmentos de índices al mismo tiempo. El uso de una búsqueda de segmentos concurrentes mejora el tiempo de respuesta de las consultas en algunos casos.
- Aislamiento de cargas de trabajo
- La implementación de nodos de búsqueda dedicados no afecta directamente la transferencia de datos a los nodos principales de la base de datos. Los Nodos de Búsqueda gestionan las consultas de búsqueda por separado de las operaciones principales de la base de datos, proporcionando aislamiento de la carga de trabajo mientras solo incurres en cargos de red para el tráfico entre los Nodos de Búsqueda y los nodos de la base de datos.
Consejos para dimensionar y escalar nodos de búsqueda
Para determinar los requisitos de memoria para Search nodos, utiliza las siguientes métricas de Atlas:
Tamaño del índice de búsqueda
Memoria RAM total en el nodo de búsqueda
Considere una aplicación que tenga un 10GB de Índice de Búsqueda y 4GB de RAM total en el Nodo de Búsqueda. En este caso, si 1GB de RAM son utilizados por otros procesos y solo 3GB están disponibles para los datos del índice, el resto de 7GB de los datos del índice (10GB- 3GB = 7GB) se carga según sea necesario desde el disco. La paginación frecuente desde disco causa un aumento de fallos de página, operaciones de E/S en disco y IOWait de CPU, lo que resulta en una degradación del rendimiento.
Si utiliza un nivel de clúster de búsqueda superior con más RAM, como 8GB o más, esto permite que Atlas sirva la mayor parte de los datos para el índice de búsqueda desde la memoria, minimizando las lecturas en disco y los errores de página, mejorando así el rendimiento.
Nota
Las SSDlocales usadas para los nodos de búsqueda requieren un 20% de almacenamiento adicional para soportar las operaciones del índice.
Costo de nodos de búsqueda
MongoDB admite nodos de búsqueda independientes en clústeres dedicados (M10 o superiores). Los nodos de búsqueda se despliegan en instancias de computación intensiva con almacenamiento local de alto rendimiento. Debes implementar un mínimo de dos nodos. Se le facturará diariamente por el uso del recurso por hora por nodo. Para obtener más información, consulta Costos de nodo de búsqueda.
Activar el cifrado en reposo
Por defecto, MongoDB y los procesos de búsqueda se ejecutan en los mismos nodos. Con esta arquitectura, el cifrado gestionado por el cliente se aplica a los datos de su base de datos, pero no se aplica a los índices de búsqueda.
Cuando se habilita nodos de búsqueda dedicados, los procesos de búsqueda se ejecutan en nodos separados. Esto te permite activar Cifrado de datos de nodo de búsqueda, así puedes cifrar tanto los datos de la base de datos como los índices de búsqueda con las mismas claves gestionadas por el cliente para una cobertura de cifrado integral.
Nota
Los nodos de la base de datos y los nodos de búsqueda utilizan diferentes métodos de cifrado con las mismas claves gestionadas por el cliente. Los nodos de la base de datos usan el motor de almacenamiento cifrado WiredTiger, mientras que los nodos de búsqueda usan cifrado a nivel de disco.
Para obtener más información, consulta Permitir la gestión de claves de cliente para los nodos de búsqueda.
Importante
Esta característica está disponible en todos los proveedores de KMS, pero los Nodos de búsqueda deben estar en AWS.
Agregar nodos de búsqueda dedicados
Agregar nodos de búsqueda dedicados a un nuevo clúster permite:
Cambia el tamaño y **escalar** tu implementación de búsqueda de forma independiente de tu **implementación de la base de datos**.
Elimina la competencia por recursos que puedas experimentar en un clúster que ejecuta tanto la base de datos MongoDB como los procesos de búsqueda en el mismo nodo.
Para implementar Nodos de Búsqueda dedicados, debes tener acceso Project Owner al proyecto.
Para agregar nodos de búsqueda dedicados:
Crea tu clúster como un
M10o superior en un proveedor de nube y una región que soporte el aislamiento de nodos. Para obtener más información, consulte Crear un clúster.Los nodos de búsqueda dedicados solo son compatibles con
M10y niveles superiores de clúster y en las regiones de proveedores de nube que admiten el aislamiento de nodos.Habilitar Search Nodes for workload isolation y Configurar nodos de búsqueda.
Migre a nodos de búsqueda dedicados
Para migrar del entorno de staging a producción y agregar nodos de búsqueda dedicados, realiza los siguientes cambios en tu implementación actual de staging y prototipado:
Si su implementación utiliza un clúster Flex, cambie el nivel del clúster a un nivel superior. Los nodos de búsqueda dedicados se admiten solo para
M10y niveles de clúster superiores.Implementa tu clúster en regiones donde también estén disponibles los nodos de búsqueda. Los nodos de búsqueda dedicados están disponibles en un subconjunto de las regiones de AWS y Azure y en todas las regiones compatibles de Google Cloud. Si tu clúster actual está alojado en regiones donde los nodos de Search no están disponibles, migra tu clúster a regiones donde los nodos de Search sí estén disponibles. Para obtener más información, consulta Regiones de proveedores de nube que admiten el aislamiento de nodos.
Habilita Search Nodes for workload isolation y configura nodos de búsqueda. Para obtener más información, consulta Agregar nodos de búsqueda.
Cuando se implementan nodos de búsqueda dedicados, ocurre la siguiente secuencia de acciones:
Atlas compila los índices de búsqueda en los Search Nodes y remueve los índices de los nodos del clúster.
Atlas enruta las consultas de búsqueda a los nodos de búsqueda.
MongoDB Search utiliza los índices de búsqueda para servir queries en el clúster.
Solucionar problemas de implementación
Failed to Execute search Command Error
Si implementas mongot para ejecutarlo junto con mongod y no configuras nodos de búsqueda, es posible que mongot finalice y devuelva el error Failed to Execute search Command durante cualquiera de los siguientes eventos:
Escalado de un clúster
Failover de nodo
Actualización
mongot
Si se implementa mongot en nodos de búsqueda dedicados, mongod utiliza un proxy que dirige las consultas de búsqueda solo a los nodos saludables donde el proceso mongot está activo.