Las implementaciones multirregión de Atlas son clústeres configurados en varias regiones. Una implementación multirregional puede tener varias regiones dentro de la misma geografía (una área grande como un continente o país), o múltiples regiones en múltiples geografías. Implementaciones multiregión:
Mejore la protección en caso de una interrupción del servicio regional redirigiendo automáticamente el tráfico a otra región para una disponibilidad continua y una experiencia de usuario fluida.
Mejora el rendimiento y la disponibilidad de algunas aplicaciones al ubicar los datos más cerca de los usuarios.
Al considerar si una implementación multi-región es adecuada para ti, debes evaluar la criticidad de tu aplicación y cómo esto se corresponde con diferentes requisitos de RTO/RPO. La resiliencia existe en un espectro que va desde cero tiempo de inactividad con una implementación en multiregión hasta diferentes cronogramas de copia de seguridad en una implementación en una sola región. La compensación es un mayor costo por más disponibilidad.
Consulta la sección Confiabilidad para obtener más orientación sobre si una implementación multiregión es adecuada para tu carga de trabajo.
Nota
Las implementaciones multirregionales están disponibles solo para M10 clústeres dedicados y más grandes.
Estrategias de Implementación Multiregión
El siguiente diagrama muestra 2 ejemplos de una topología 2+2+1, que se analiza en detalle a continuación. Muestra un solo clúster con 5 nodos en 3 regiones diferentes: 2 nodos en US1, 2 en US2 y 1 en US3.

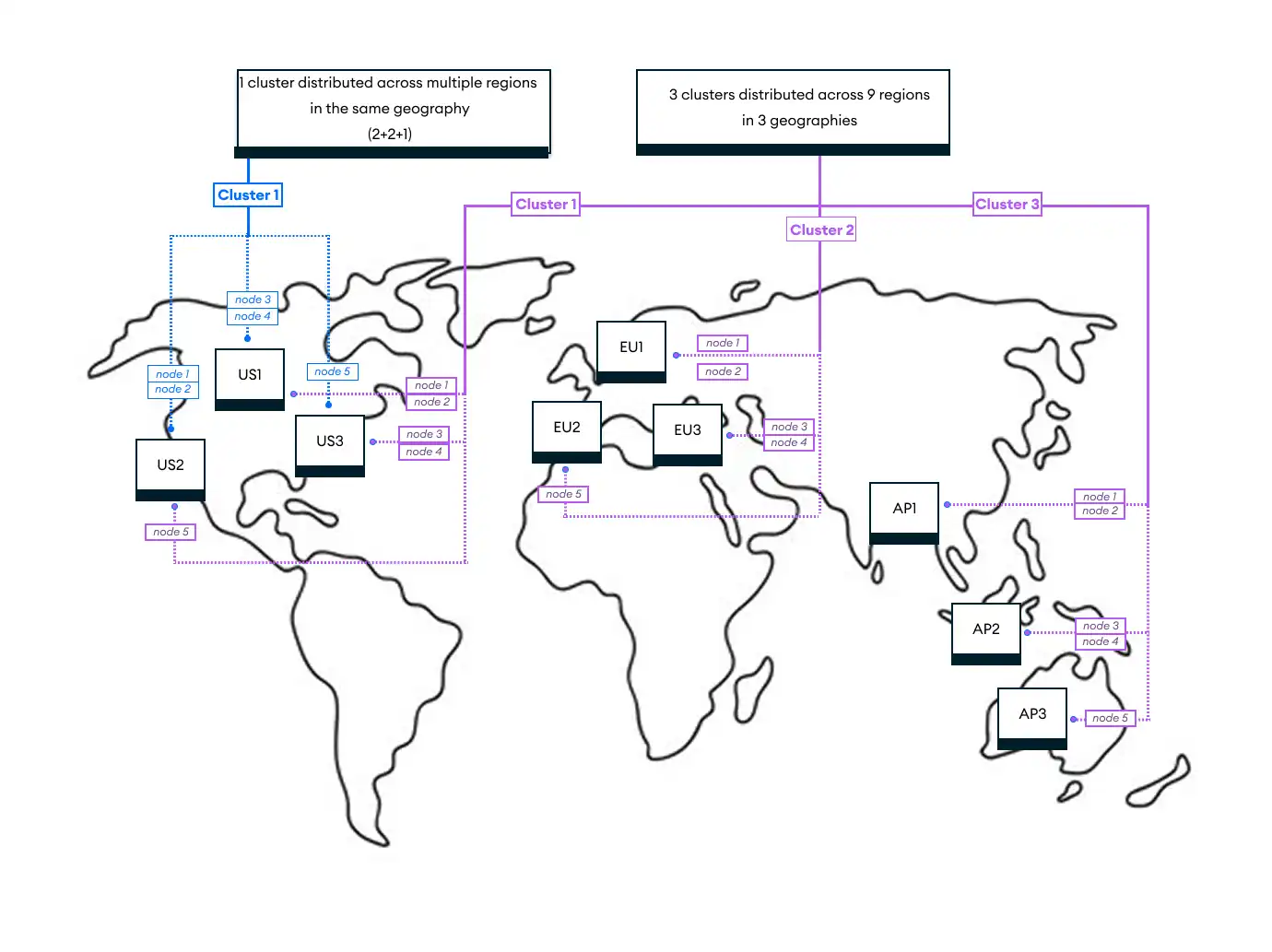
Arquitectura de 5nodos y 3regiones (2+2+1)
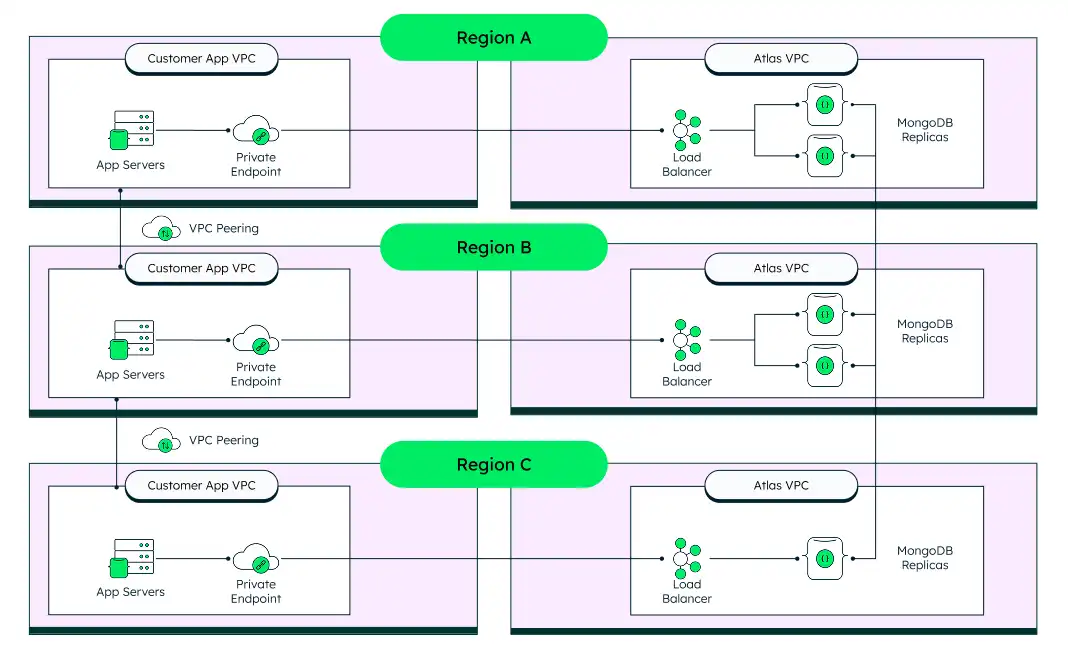
Para lograr una recuperación casi instantánea en caso de una interrupción regional, recomendamos una arquitectura con un mínimo de 5 nodos distribuidos en 3 regiones. Esta arquitectura garantiza que las operaciones de mantenimiento regulares se puedan realizar sin forzar la conmutación por error a una segunda región, a la vez que garantiza la conmutación por error automatizada y la protección contra la pérdida de datos en caso de una interrupción regional completa.
El siguiente diagrama muestra los detalles de esta arquitectura:

Notas y consideraciones
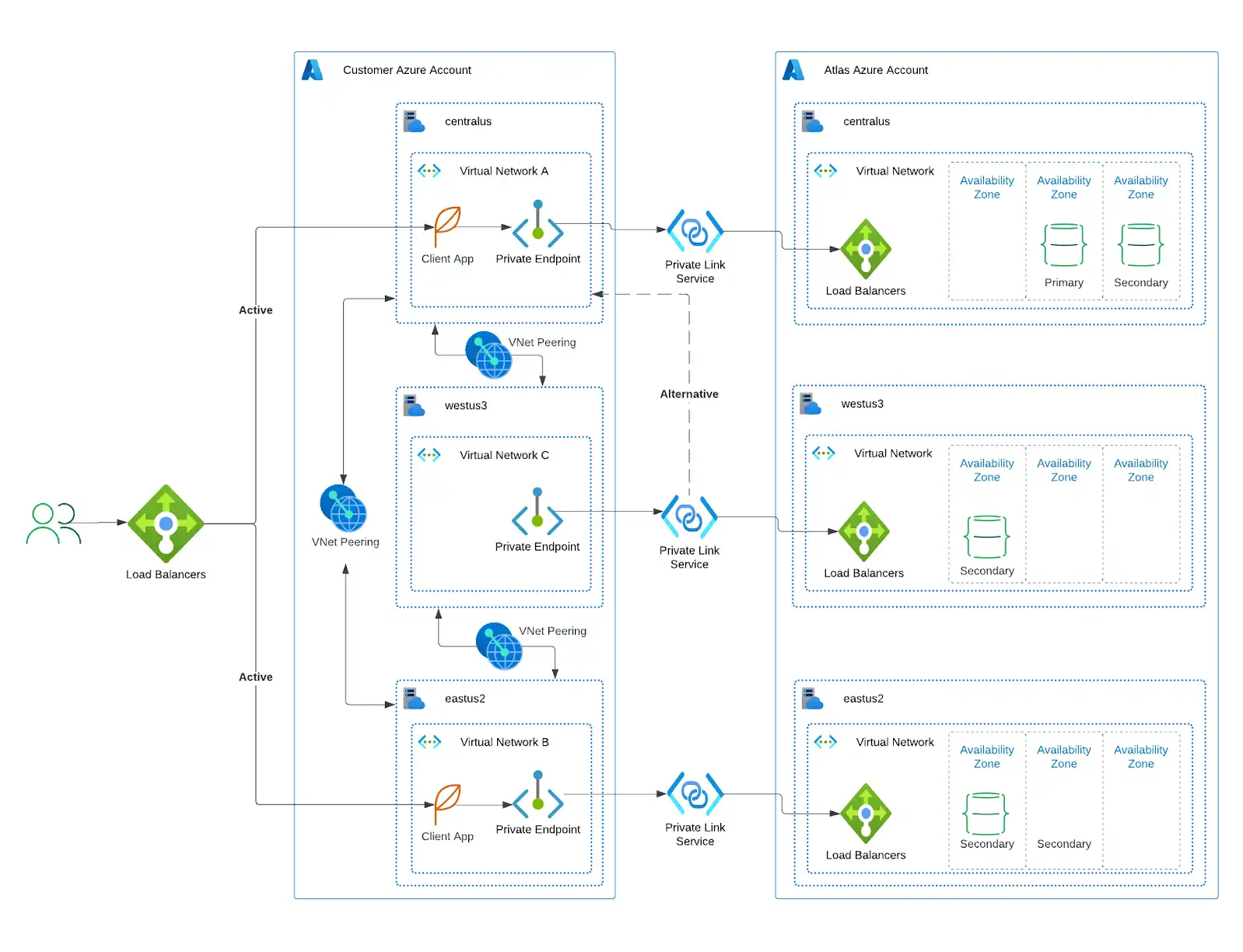
Usar Puntos finales privados para conectarse al clúster y emparejamiento de VPC entre las VPC de su servidor de aplicaciones. El emparejamiento de VPC garantiza que, si se interrumpe una conexión de red o Atlas en esa región deja de funcionar, la capa de aplicación aún puede enrutar al nodo principal, primero a través del emparejamiento de VPC y luego a través del punto final privado.
Esta arquitectura tiene el costo más alto debido al tráfico de red entre regiones y a tener 5 o más nodos que contienen datos.
Esta arquitectura proporciona la mayor resiliencia. No hay interrupciones durante las operaciones de Atlas (como una actualización automatizada), y tu aplicación puede soportar una falla regional completa sin interrupciones ni intervención manual.
Esta arquitectura tiene el costo más alto debido al tráfico de red entre regiones y a tener 5 o más nodos que contienen datos.
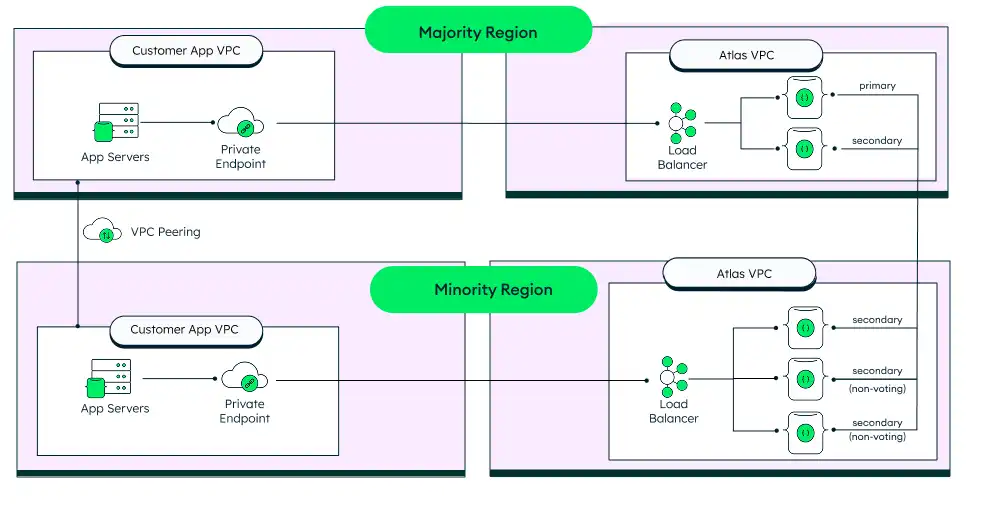
Arquitectura 5-Nodo, 2-Región (2+3)
Si su empresa está limitada a solo 2 regiones, puede usar una variante de la arquitectura de 5nodos y 3regiones, en la que tiene 5 nodos distribuidos entre dos regiones. La región principal tiene 2 nodos elegibles, y la secundaria tiene 1 nodos elegibles y 2 nodos de solo lectura (sin derecho a voto).
Esto generalmente no se recomienda si se pueden usar regiones 3 porque el operador debe intervenir manualmente para realizar un conmutación por error si la región de mayoría falla. Sin embargo, es una opción para clientes con solo 2 regiones aprobadas.

Notas y consideraciones
Esta arquitectura ofrece mayor protección contra la pérdida de datos. Si se pierde la región minoritaria, no se requiere ninguna acción del usuario, ya que la región mayoritaria sigue siendo un clúster completamente funcional. Si se pierde la región mayoritaria, el sistema seguirá disponible en modo de solo lectura hasta que la mayoría de los nodos estén habilitados. Sin embargo, es posible que no ofrezca una protección completa contra la pérdida de datos si algunos datos aún no se han replicado a un nodo secundario tras un fallo. En este caso, esos datos no estarán disponibles hasta que se recupere la región principal.
Esta arquitectura viene con algunas advertencias:
Si se pierde la región mayoritaria, la región minoritaria no es un clúster completamente funcional; no tiene un primario y solo puede aceptar lecturas pero no escrituras.
Como no hay una mayoría de nodos con derecho a voto, no hay un primario y sólo puede aceptar lecturas (no escrituras).
Para restaurar el clúster funcional, un administrador debe reconfigurar los 2 nodos de solo lectura como nodos elegibles. Sin embargo, es posible que se pierdan datos. Durante la interrupción, cualquier escritura nueva en los nodos secundarios se almacena en una colección especial para su recuperación manual. Sin embargo, cualquier escritura en el nodo principal que no se haya replicado en al menos un nodo secundario antes de la interrupción del principal se perderá. Para obtener más información, consulte "Reconfigurar un conjunto de réplicas durante una interrupción regional" o utilice el parámetro de API acceptDataRisksAndForceReplicaSetReconfig.
En los clústeres particionados, si tu proceso de MongoDB no replico las migraciones de fragmentos, la incongruencia de datos podría causar documentos huérfanos.
Variación de menor costo
Para un mayor ahorro de costos, puedes diseñar esta arquitectura sin los nodos 2 de solo lectura. Además de las advertencias enumeradas anteriormente, el tamaño de los datos tiene un impacto significativo en tu decisión, ya que los datos deben sincronizarse con los secundarios cada vez que se añaden nuevos nodos al clúster. Por ejemplo, 1 TB de datos promedian 1 horas de recuperación y tiempo de sincronización. Recomendamos tener 2 nodos de solo lectura en la región minoritaria porque ya están completamente sincronizados, y la recuperación a un clúster totalmente funcional toma solo segundos o minutos.
Arquitectura de 3nodos y 3regiones (1+1+1)
Para cargas de trabajo menos críticas que puedan tolerar interrupciones, puedes aprovechar una arquitectura menos costosa utilizando 1 nodo en cada una de las 3 regiones. Tienes un nodo elegible en cada una de las regiones, lo que significa que si el nodo primario no está disponible, tu clúster pasará a una nueva región para garantizar la disponibilidad continua. Sin embargo, si tu nivel de aplicación en la región principal original sigue atendiendo solicitudes de usuarios, se producirá una mayor latencia ya que las solicitudes se enrutan entre varias regiones. Además, no habrá capacidad de realizar una sincronización inicial optimizada en caso de reconstruir un nodo.
Nota
En general, no recomendamos esta configuración porque el mantenimiento regular y planificado de los nodos de Atlas provocará picos temporales de latencia.
Recomendaciones para implementaciones multirregionales
Para aprender a configurar implementaciones multirregionales y conocer los diferentes tipos de nodos que puede agregar, consulte Configurar alta disponibilidad y aislamiento de carga de trabajo en la documentación de Atlas.
Si tu aplicación está implementada en uno de los siguientes proveedores de nube, MongoDB recomienda firmemente que implementes tus recursos de Atlas en el mismo proveedor y región. Además, sugerimos que mapees la implementación de los recursos de tu aplicación en las regiones a la implementación de tus recursos de Atlas, como se muestra a continuación.
Desplegar los recursos de la aplicación junto a los recursos de Atlas:
Reduce la latencia de las operaciones de base de datos ejecutadas por su aplicación.
Permite mayor seguridad mediante nodos privados que conectan tus recursos en la nube autogestionados con tus recursos de Atlas. Los nodos privados ofrecen el mejor nivel de seguridad de red, asegurando que el tráfico solo pueda iniciarse desde tu cuenta.
Te permite un control más granular sobre el almacenamiento de datos específicos de la región.
Le permite redirigir el tráfico a regiones saludables en caso de que ocurra una interrupción en otro lugar.
Para obtener más información sobre aplicaciones y recomendaciones de implementación de Atlas, consulta:

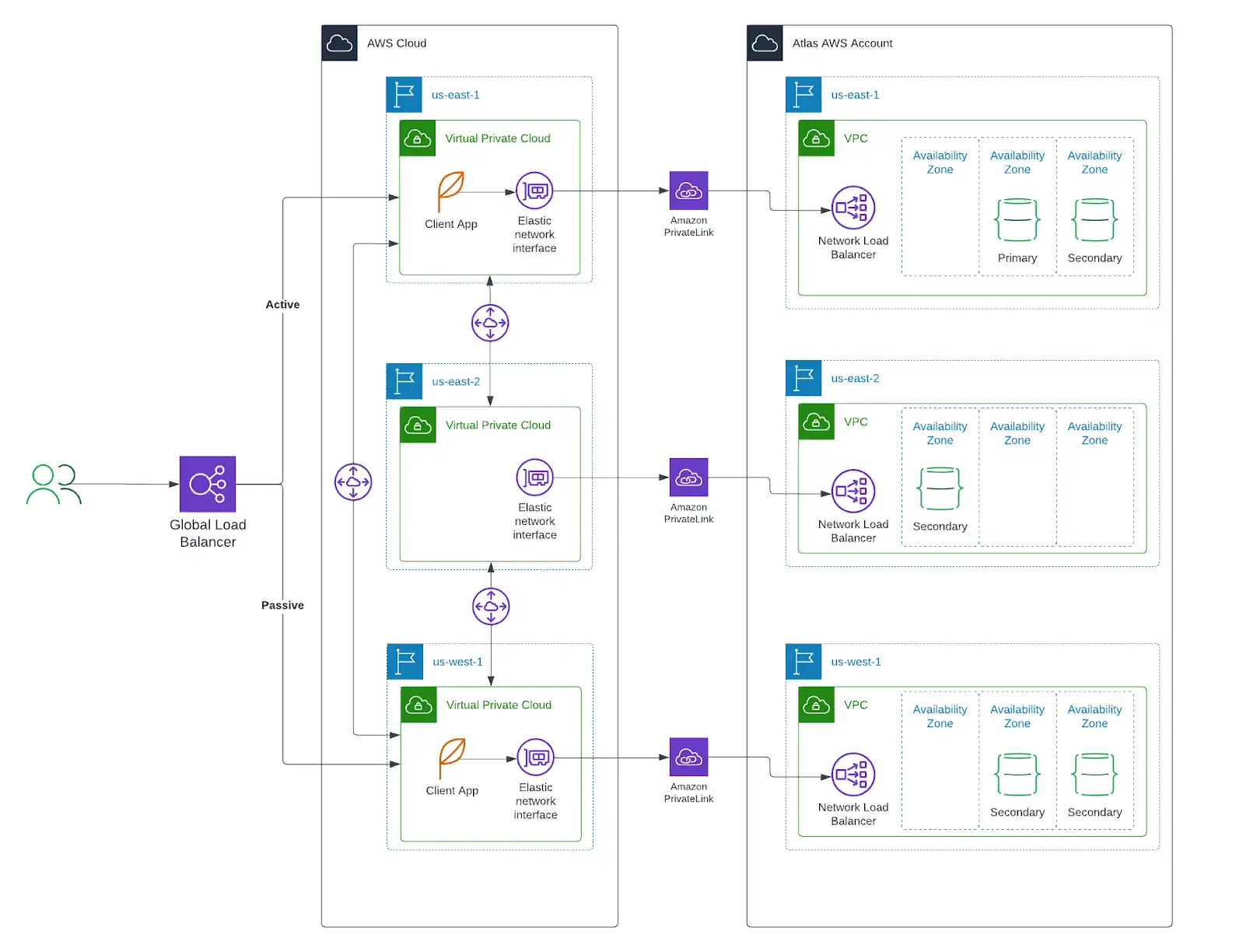
Considerations
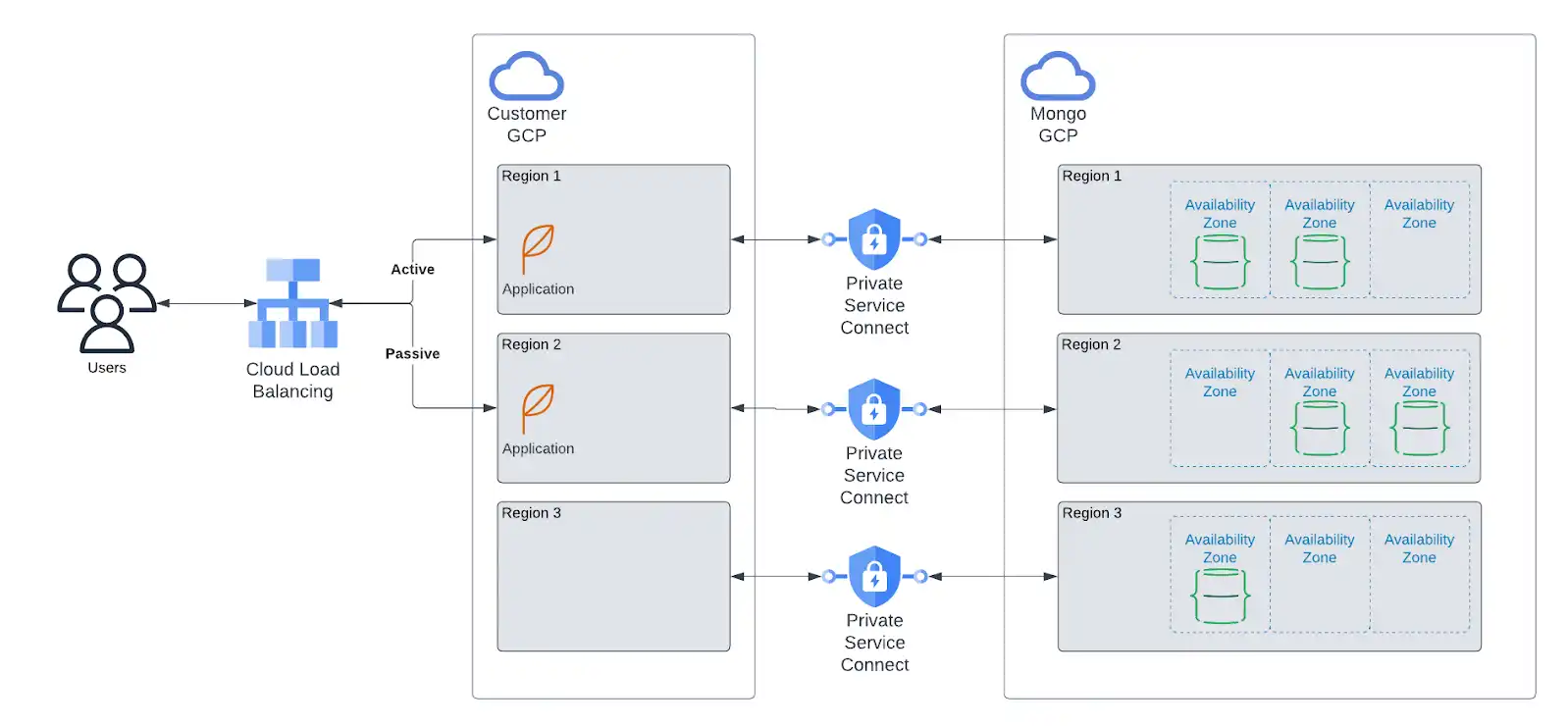
Azure admite vínculos privados entre regiones.
Puedes crear un enlace entre varias regiones sin necesidad de recursos de red adicionales que, de otro modo, serían necesarios.
Por ejemplo, si tu aplicación se implementa en
central-usywest-us-3, y tu clúster de Atlas se implementa enwest-us-3yeast-us-2, puedes crear un nodo privado encentral-usque esté enlazado al enlace privado enwest-us-3.

Para encontrar recomendaciones para tus implementaciones en la nube de Atlas, consulta los siguientes recursos:
Recomendaciones para organizaciones, proyectos y clústeres de Atlas
Operational Efficiency
Seguridad
Confiabilidad
Rendimiento
Cost Optimization