Las organizaciones, los Proyectos y los clústeres son los cimientos de tu patrimonio empresarial Atlas:
A nivel de la organización, puedes implementar controles de seguridad y crear usuarios que trabajen en uno o más proyectos.
Los proyectos ofrecen un aislamiento de seguridad más detallado y un límite de autorización más preciso.
Los clústeres son sus bases de datos en la nube en Atlas.
Utiliza la orientación fundamental de esta página para diseñar la disposición de tus organizaciones, proyectos y clústeres según la jerarquía de tu empresa y el número esperado de clústeres y proyectos. Esta orientación te ayuda a optimizar tu seguridad y rendimiento desde el principio, alineándose con las necesidades de facturación y acceso de tus empresas.
Nota
El Modelo de Responsabilidad Compartida de MongoDB Atlas define los deberes complementarios de MongoDB y sus clientes en el mantenimiento de un entorno de datos seguro y resiliente. Bajo este marco, MongoDB gestiona la seguridad y la integridad operativa de la plataforma subyacente, mientras que los clientes son responsables de la configuración, gestión y políticas de datos de sus implementaciones específicas. Para obtener un desglose detallado de la propiedad en materia de seguridad y excelencia operativa, consulta el Modelo de Responsabilidad Compartida.
Funcionalidades para Atlas Orgs, Proyectos y clústeres
Puede utilizar los siguientes niveles de jerarquía para definir la configuración de seguridad y gobierno de su patrimonio empresarial de Atlas:
Nivel de jerarquía de Atlas | Descripción |
|---|---|
(Opcional) Organización pagadora | Una organización puede ser la organización pagadora de otra(s). Una organización pagadora te permite configurar facturación entre organizaciones para compartir una suscripción de facturación entre varias organizaciones. Para aprender más sobre cómo configurar la organización pagadora al establecer la suscripción de Atlas, consulta Administrar facturación. Para habilitar la facturación cruzada entre organizaciones, el usuario que realiza la acción debe tener un rol de Propietario de la Organización o Administrador de Facturación en ambas organizaciones que desea vincular. Para obtener más información, consulta Roles de usuario. Una organización pagadora es común en grandes empresas con muchos BUs o departamentos que operan de manera independiente, pero donde el contrato o la factura pertenece a una autoridad central. |
Una organización puede contener muchos proyectos, y proporciona un contenedor para aplicar configuraciones compartidas de integración y seguridad a esos proyectos y los clústeres que contiene. Si gestionas varias organizaciones de Atlas, la Consola de Gestión de Federación de Atlas permite a los usuarios con rol de Propietario de la Organización gestionar IdPs para SSO, y luego vincularlos a varias organizaciones. Una organización a menudo se vincula a una UB o departamento dentro de una empresa. El explorador de costos Atlas con funcionalidad incorporada agrega el gasto en la nube a nivel organizacional y desglosa los elementos individuales a nivel de Proyecto y de clúster, debajo de él. Puedes personalizar aún más aprovechando la API de facturación. | |
La configuración de seguridad para el plano de datos (incluidos los clústeres de la base de datos, la seguridad de la red y otros servicios de datos) se realiza a nivel de proyecto. Un Proyecto a menudo se asigna a una aplicación y entorno (por ejemplo: Portal del cliente - entorno de producción). Para cada proyecto, según el proveedor de nube seleccionado, hay una VPC o VNet dedicada por región en AWS y Azure. | |
Atlas aprovisiona cada clúster dentro de una o más VPC/VNet dedicadas para un proyecto. La configuración de seguridad se comparte entre los clústeres del Proyecto, excepto los roles de usuario de base de datos y la autorización, que pueden aplicarse a acciones en nivel de clúster, base de datos y colección. |
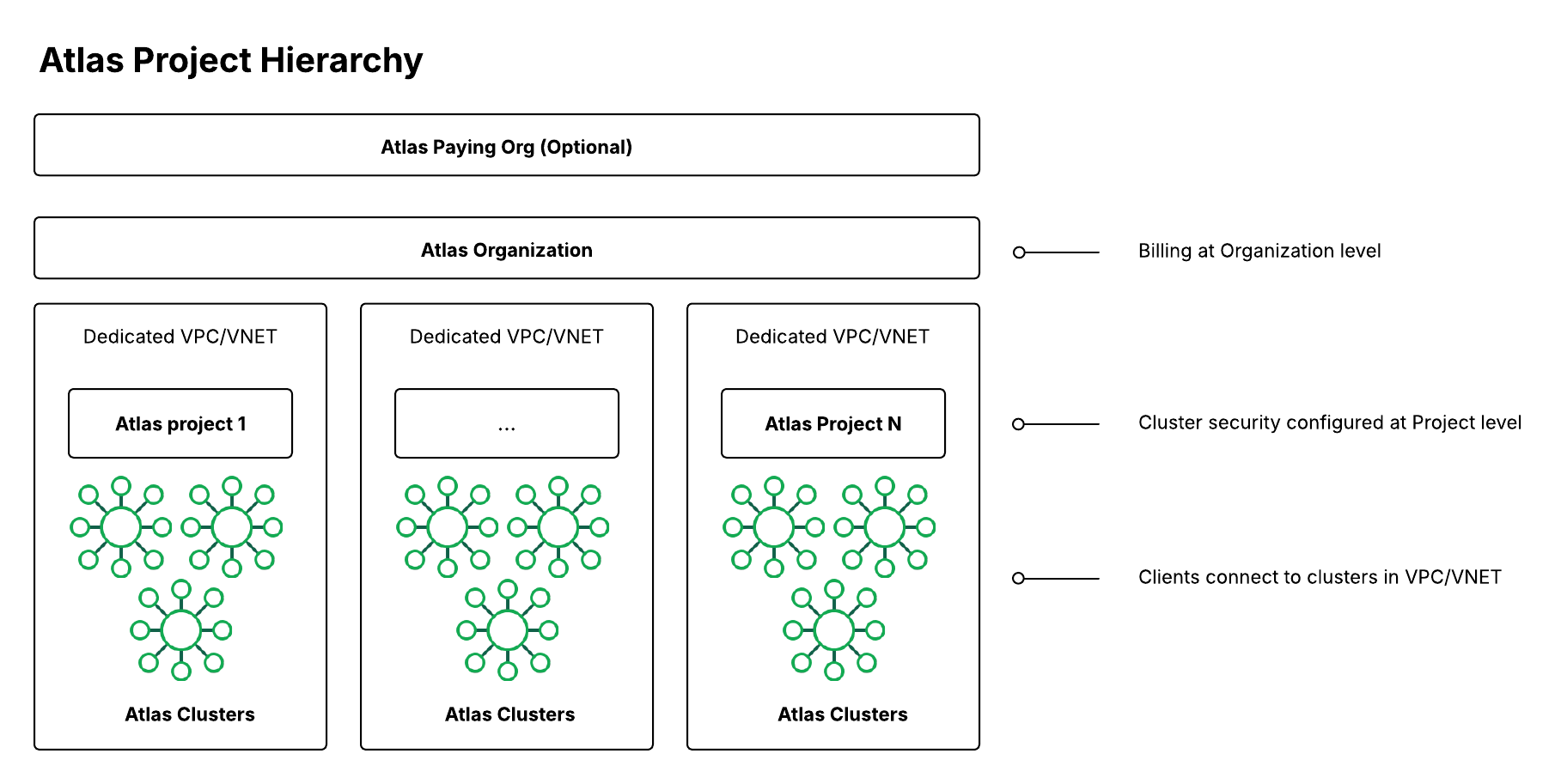
Recomendaciones para Atlas Org, Proyectos y Clústeres
Recomendaciones de implementación multiregión y multi-nube
Para implementaciones multiregión y multi-nube, considera las siguientes recomendaciones adicionales para optimizar el rendimiento, la seguridad y el cumplimiento en diferentes fronteras geográficas:
Arquitectura de red y latencia
Implementa clústeres en las regiones más cercanas a los usuarios de tu aplicación para minimizar la latencia.
Use VPC/VNets dedicados por región dentro de cada proyecto para mantener el aislamiento de la red.
Configure nodos privados en cada región donde implementes clústeres para garantizar conexiones seguras y de baja latencia.
Localización y cumplimiento de datos
Cree proyectos separados para diferentes jurisdicciones regulatorias (por ejemplo, proyecto de la UE conforme al GDPR, proyecto de EEUU conforme a SOX) para garantizar el cumplimiento de los requisitos de residencia de datos.
Utilizar clústeres globales con partición por zonas para enrutar automáticamente las lecturas y escrituras a la región geográfica adecuada según los valores de las claves de partición.
Etiqueta proyectos y clústeres con requisitos de clasificación de datos y cumplimiento regional para propósitos de auditoría y gobernanza.
Recuperación ante desastres entre regiones
Implemente clústeres con réplicas de lectura en varias regiones para habilitar capacidades de conmutación por error.
Mantén cronogramas de copia de seguridad coherentes en todas las regiones dentro del mismo entorno de aplicación.
Prueba los procedimientos de recuperación ante desastres regularmente en las regiones para garantizar la continuidad del negocio.
Consideraciones multi-nube
Utilice convenciones de nomenclatura coherentes en todos los proveedores de nube para simplificar la gestión y la supervisión.
Estandariza las configuraciones de seguridad en todos los entornos de nube dentro del mismo proyecto.
Considere funcionalidades y limitaciones específicas del proveedor de nube al planificar la replicación de datos y la conectividad de red entre nubes.
Todas las recomendaciones paradigmáticas de implementación
Las siguientes recomendaciones se aplican a todos los paradigmas de implementación.
Entornos de desarrollo, prueba, ensayo y producción
Recomendamos que utilice los siguientes cuatro entornos para aislar su sandbox y probar proyectos y clústeres de sus proyectos y clústeres de aplicaciones:
Entorno | Descripción |
|---|---|
Desarrollo (Dev) | Permita a los desarrolladores probar libremente cosas nuevas en un entorno de prueba seguro. |
Prueba (Test) | Prueba componentes o funciones específicas creados en el entorno de desarrollo. |
Staging | Se deben poner en escena todos los componentes y las funciones juntos para asegurarse de que toda la aplicación funciona como se espera antes de su implementación en producción. La integración es similar al entorno de prueba, pero garantiza que los nuevos componentes funcionen bien con los componentes existentes. |
Producción (Producción) | El back end de tu aplicación que está en vivo para tus usuarios finales. |
implementaciones locales de Atlas
Para fines de desarrollo y prueba, los desarrolladores pueden usar la Atlas CLI para crear una implementación local de Atlas. Al trabajar localmente desde sus máquinas, los desarrolladores pueden reducir los costos para entornos externos de desarrollo y pruebas.
Los desarrolladores también pueden ejecutar comandos de Atlas CLI con Docker para compilar, ejecutar y administrar implementaciones locales de Atlas utilizando contenedores. Los contenedores son unidades estandarizadas que contienen todo el software necesario para ejecutar una aplicación. La contenerización permite a los desarrolladores construir implementaciones locales de Atlas en entornos de prueba seguros, confiables y portátiles. Para obtener más información, consulte Crea una implementación local de Atlas con Docker.
Jerarquías de organización y proyecto
Por lo general, recomendamos una organización pagadora que se gestione de forma centralizada y una organización para cada unidad de negocio o departamento que esté vinculada a la organización pagadora. Luego, se crea un proyecto con un clúster para cada uno de los entornos inferior (desarrollo o prueba) y superior; se pueden crear clústeres en estos proyectos. Para aprender más, se puede consultar la jerarquía recomendada.
Si planeas alcanzar fácilmente el límite de 250 proyectos por organización, se recomienda crear una organización por entorno, como una para entornos inferiores y otra para entornos superiores, o una para desarrollo, prueba, puesta en escena y producción. Esta configuración tiene el beneficio de un aislamiento adicional. También puedes aumentar los límites. Para obtener más información, consulta Límites de servicio de Atlas.
Las configuraciones de red y seguridad, como las IP permitidas y las claves API, se comparten a nivel de proyecto, por lo que si necesitas controles de acceso a nivel detallado para equipos que trabajen en diferentes aplicaciones, recomendamos crear proyectos separados para cada aplicación.
Jerarquía recomendada
Considera la siguiente jerarquía, que crea menos organizaciones en Atlas, si tienes equipos y permisos comunes en el BU y menos que el límite aumentable de 250 proyectos por organización.

Jerarquía recomendada 2: Unidades/Departamentos de Negocio Descentralizados
Considera la siguiente jerarquía si tu organización está altamente descentralizada y carece de una función centralizada que sirva como propietaria de contratos y facturación. En esta jerarquía, cada BU, departamento o equipo tiene su propia organización Atlas. Esta jerarquía es útil si cada uno de sus equipos es bastante independiente, no comparten personas ni permisos dentro de la empresa, o si desean adquirir créditos ellos mismos a través del marketplace del proveedor de nube o directamente con su propio contrato. No hay una organización pagadora en esta jerarquía.

Cluster Hierarchy
Para mantener el aislamiento entre entornos, recomendamos que implementes cada clúster dentro de su propio proyecto, como se muestra en el siguiente diagrama. Esto permite a los administradores mantener diferentes configuraciones de Proyectos entre entornos y cumplir con el principio del mínimo privilegio, que establece que a los usuarios solo se les debe conceder el nivel mínimo de acceso necesario para su rol.
En particular, en entornos de producción, recomendamos que cree proyectos separados para cada par de aplicaciones y entornos. Como estas configuraciones se administran a nivel de proyecto, este enfoque reduce la posibilidad de que necesites transferir datos manualmente entre clústeres de entornos de producción en caso de que estos requisitos cambien para una aplicación determinada.
Puedes compartir configuraciones a nivel de proyecto, como nodos privados y CMKs, entre clústeres utilizando herramientas de automatización, como Terraform, al crear el clúster. Además, la automatización de la creación de clústeres puede generar ahorros de costos al estandarizar la creación de entornos superiores e inferiores paralelos para entornos de producción y desarrollo, respectivamente.
Para obtener más información, consulta Cuándo considerar múltiples clústeres por proyecto.

Cuándo considerar múltiples clústeres por proyecto
El siguiente diagrama muestra una organización cuyos proyectos contienen a su vez varios clústeres de Atlas, agrupados por entorno. El despliegue de múltiples clústeres dentro del mismo proyecto simplifica la administración cuando una aplicación utiliza múltiples clústeres de respaldo, o el mismo equipo es responsable de múltiples aplicaciones en diferentes entornos. Esto facilita el costo de configuración de funcionalidades como nodos privados y claves gestionadas por el cliente, porque todos los clústeres en el mismo Proyecto comparten la misma configuración de Proyecto.
Sin embargo, esta jerarquía de clúster podría violar el principio de mínimo privilegio.
Implementa varios clústeres dentro del mismo Proyecto solo si ambos de los siguientes son verdaderos:
Cada miembro del equipo con acceso al proyecto está trabajando en todas las demás aplicaciones y clústeres del proyecto.
Estás creando clústeres para entornos de desarrollo y prueba. En los entornos de staging y producción, recomendamos que los clústeres en el mismo proyecto pertenezcan a la misma aplicación y sean administrados por el mismo equipo.

Etiquetado de recursos
Recomendamos que etiquetes los clústeres o proyectos con los siguientes detalles para facilitar el análisis de reportes e integraciones:
BU o Departamento
Nombre del equipo
Nombre de la aplicación
Entorno
Versión
Contacto por correo electrónico
Criticidad (indica el nivel de los datos almacenados en el clúster, incluyendo cualquier clasificación sensible como PII o PHI)
Para obtener más información sobre el análisis de datos de facturación utilizando etiquetas, consulta Funcionalidades de datos de facturación de Atlas.
Guía sobre el tamaño del clúster Atlas
En una implementación dedicada (tamaño del clúster M10+), Atlas asigna recursos de forma exclusiva. Recomendamos implementaciones dedicadas para casos de uso en producción porque ofrecen mayor seguridad y rendimiento que los clústeres compartidos.
La siguiente guía de tamaño de clúster utiliza "talla de camiseta", una analogía común utilizada en el desarrollo de software e infraestructura para describir la planificación de capacidad de manera simplificada. Utiliza las recomendaciones de tallas de camisetas únicamente como puntos de partida aproximados en tu análisis de tallas. La dimensionamiento de un clúster es un proceso iterativo basado en las necesidades cambiantes de recursos, los requisitos de rendimiento, las características de la carga de trabajo y las expectativas de crecimiento.
Importante
Esta orientación excluye las aplicaciones de misión crítica, las cargas de trabajo de alta memoria y las cargas de trabajo de alto uso de CPU. Para estos casos de uso, ponte en contacto con MongoDB Support para recibir orientación personalizada.
Puedes estimar los recursos de clúster que requiere tu implementación utilizando el tamaño aproximado de los datos y la carga de trabajo de tu organización:
Almacenamiento total requerido: 50% del tamaño total de datos en bruto
RAM total requerida: 10% del tamaño total de los datos en bruto
Total de Núcleos de CPU Requeridos: operaciones de lectura/escritura de base de datos pico esperadas por segundo ÷ 4000
IOPS de almacenamiento total requeridos: operaciones de base de datos de lectura/escritura máxima esperadas por segundo (IOPS mín. = 5%, IOPS máx. = 95%)
Utiliza la siguiente guía sobre el tamaño de clúster para seleccionar un nivel de clúster que garantice el rendimiento sin una sobreaprovisionamiento. Esta tabla muestra las capacidades de almacenamiento y rendimiento por defecto para cada nivel de clúster, así como si el nivel de clúster es adecuado para entornos de ensayo y producción.
La guía de tamaños de clúster también incluye valores esperados para el tamaño total de datos de un clúster y el IOPS por defecto, que puedes aumentar con configuraciones adicionales. Ten en cuenta que las siguientes recomendaciones de almacenamiento son por fragmento o partición, no para todo el clúster. Para obtener más información, consulta Orientación para la escalabilidad de Atlas.
Talla de camiseta | Nivel de clúster | Rango de almacenamiento: AWS/Google Cloud/Azure | CPUs (#) | RAM por defecto | IOPS por defecto | Tamaño de datos mediana esperado | Lecturas/guardados máximos esperados | Adecuado para |
|---|---|---|---|---|---|---|---|---|
Pequeño |
| 2 GB a 128 GB | 2 | 2 GB | 1000 | 1 GB a 10 GB | 200 | Sólo desarrollo/pruebas |
Med |
| 8 GB a 512 GB | 2 | 8 GB | 3000 | 20 GB a 50 GB | 3000 | Prod |
Grande |
| 8 GB a 4 TB | 16 | 32 GB | 3000 | 360 GB a 420 GB | 11000 | Prod |
XL |
| 8 GB a 4 TB | 32 | 128 GB | 3000 | 1200 GB a 1750 GB | 39000 | Prod |
| [1] | M10 es un nivel de CPU compartida. Para industrias altamente reguladas o datos confidenciales, tu nivel mínimo y más pequeño de inicio debe ser M30. |
Por ejemplo, considere una empresa de tecnología financiera ficticia, MongoFinance, que debe almacenar un total de 400 GB de datos procesados. En el pico de actividad, los empleados y clientes de MongoFinance realizan hasta 3000 lecturas o escrituras en las bases de datos de MongoFinance por segundo. Los requisitos de almacenamiento y rendimiento de MongoFinance se satisfacen mejor con un nivel de clúster grande, o M50.
Para obtener más información sobre los niveles de clúster y las regiones que los admiten, consulta la documentación de Atlas para cada proveedor de nube:
Ejemplos de automatización: Atlas Orgs, proyectos y clústeres
Tip
Para ejemplos de Terraform que aplican nuestras recomendaciones en todos los pilares, consulta uno de los siguientes ejemplos en GitHub:
Los siguientes ejemplos crean organizaciones, proyectos y clústeres utilizando las herramientas de Atlas para la automatización.
Estos ejemplos también aplican otras configuraciones recomendadas, entre ellas:
Nivel de clúster configurado para
M10para un entorno de desarrollo/prueba. Usa la guía de tamaño de clúster para aprender cuál es el nivel de clúster recomendado para el tamaño de la aplicación.Topología de implementación de un solo set de réplicas/región con 3nodos y partición.
Nuestros ejemplos usan AWS, Azure y Google Cloud de manera intercambiable. Puede utilizar cualquiera de estos tres proveedores de servicios en la nube, pero debe cambiar el nombre de región para que coincida con el proveedor de nube. Para obtener más información sobre los proveedores de nube y sus regiones, consulte Proveedores de nube.
El nivel del clúster se establece en
M30para una aplicación de tamaño medio. Utilice la guía de tamaños de clúster para conocer el nivel de clúster recomendado para el tamaño de su aplicación.Topología de implementación de un solo set de réplicas/región con 3nodos y partición.
Nuestros ejemplos usan AWS, Azure y Google Cloud de manera intercambiable. Puede utilizar cualquiera de estos tres proveedores de servicios en la nube, pero debe cambiar el nombre de región para que coincida con el proveedor de nube. Para obtener más información sobre los proveedores de nube y sus regiones, consulte Proveedores de nube.
Nota
Antes de poder crear recursos con la CLI de Atlas, debes:
Crea tu organización pagadora y crea una clave de API para la organización pagadora.
Conéctese desde la Atlas CLI utilizando los pasos para Programmatic Use.
Crear las organizaciones
Ejecuta el siguiente comando para cada BU. Cambia los IDs y los nombres para usar tus valores reales:
atlas organizations create ConsumerProducts --ownerId 508bb8f5f11b8e3488a0e99e --apiKeyRole ORG_OWNER --apiKeyDescription consumer-products-key
Para obtener más opciones de configuración e información sobre este ejemplo, se puede consultar atlas organizations create.
Puede crear una organización y vincularla con su organización de pago automáticamente utilizando la API de administración de Atlas. Para ello, envíe una POST solicitud al endpoint https://cloud.mongodb.com/api/atlas/v2/orgs e indique el Identificador de la Organización de pago en el federationSettingsId campo. La cuenta de servicio o la clave de API que realice la solicitud debe tener el rol "Propietario de la organización" y la organización solicitante debe ser una organización de pago.
El siguiente ejemplo usa cURL para enviar la solicitud:
curl --location '/api/atlas/v2/orgs?envelope=false&pretty=false' \ --header 'Content-Type: application/vnd.atlas.2023-01-01+json' \ --header 'Accept: application/vnd.atlas.2023-01-01+json' \ --data '{ "name": "<organization name>", "apiKey": { "desc": "<organization description>", "roles": [ "ORG_MEMBER" ] }, "federationSettingsId": "<ID of org to link to>", "orgOwnerId": "<organization owners ID>", "skipDefaultAlertsSettings": false }'
Para obtener más información sobre la llamada a la API anterior, consulta la documentación de la API atlas organizations create.
Para obtener los ID de usuarios e Identificadores de la Organización, consulta los siguientes comandos:
Crea los proyectos
Ejecuta el siguiente comando para cada aplicación y par de entornos. Cambia los IDs y nombres para usar tus valores:
atlas projects create "Customer Portal - Prod" --tag environment=production --orgId 32b6e34b3d91647abb20e7b8
Para más opciones de configuración e información sobre este ejemplo, consulta atlas projects create.
Para obtener los ID del grupo, consulta el siguiente comando:
Configurar el cifrado con gestión de claves del cliente
Para los entornos de staging y producción, recomendamos que active el cifrado con gestión de claves del cliente al aprovisionar sus clústeres. Para desarrollo y pruebas, considera omitir el cifrado con gestión de claves del cliente para ahorrar costos, a menos que estés en una industria altamente regulada o almacenando datos confidenciales. Para obtener más información, consulte Recomendaciones para Atlas Orgs, Proyectos y Clústeres.
No puedes usar la Atlas CLI para gestionar el cifrado con la gestión de claves del cliente. En su lugar, utiliza los siguientes métodos:
Crear un clúster por proyecto
Para crear un clúster de una sola región para tus entornos de desarrollo y prueba, ejecuta el siguiente comando para cada proyecto que hayas creado. Cambia los IDs y nombres para usar tus valores:
Nota
También puedes usar la Atlas Admin API de clústeres para crear un clúster.
Este ejemplo no activa el escalado automático para ayudar a controlar los costos en entornos de desarrollo y pruebas. Para los entornos de preparación y producción, se debe habilitar el escalado automático.
atlas clusters create CustomerPortalDev \ --projectId 56fd11f25f23b33ef4c2a331 \ --region EASTERN_US \ --members 3 \ --tier M10 \ --provider GCP \ --mdbVersion 8.0 \ --diskSizeGB 30 \ --tag bu=ConsumerProducts \ --tag teamName=TeamA \ --tag appName=ProductManagementApp \ --tag env=Production \ --tag version=8.0 \ --tag email=marissa@example.com \ --watch
Para configurar un clúster multiregional, crea el siguiente archivo cluster.json para cada proyecto que creaste. Cambia las IDs y nombres para usar tus valores.
{ "name": "CustomerPortalDev", "projectId": "56fd11f25f23b33ef4c2a331", "clusterType": "REPLICASET", "diskSizeGB": 30, "mongoDBMajorVersion": "8.0", "backupEnabled": true, "replicationSpecs": [ { "numShards": 1, "regionConfigs": [ { "providerName": "GCP", "regionName": "EASTERN_US", "members": 3, "priority": 7, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } } }, { "providerName": "GCP", "regionName": "CENTRAL_US", "members": 2, "priority": 5, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } } }, { "providerName": "GCP", "regionName": "WESTERN_US", "members": 2, "priority": 4, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } } } ] } ], "tags": [ { "key": "bu", "value": "ConsumerProducts" }, { "key": "teamName", "value": "TeamA" }, { "key": "appName", "value": "ProductManagementApp" }, { "key": "env", "value": "Production" }, { "key": "version", "value": "8.0" }, { "key": "email", "value": "marissa@example.com" } ] }
Después de crear el archivo de configuración anterior, ejecuta el siguiente comando para crear el clúster:
atlas clusters create --file <path to your configuration file>
Para crear un clúster de una sola región para sus entornos de preparación y producción, cree el siguiente archivo cluster.json para cada proyecto que haya creado. Cambia los IDs y nombres para usar tus valores:
{ "clusterType": "REPLICASET", "links": [], "name": "CustomerPortalProd", "mongoDBMajorVersion": "8.0", "replicationSpecs": [ { "numShards": 1, "regionConfigs": [ { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 7, "providerName": "GCP", "regionName": "EASTERN_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } } ], "zoneName": "Zone 1" } ], "tag" : [{ "bu": "ConsumerProducts", "teamName": "TeamA", "appName": "ProductManagementApp", "env": "Production", "version": "8.0", "email": "marissa@example.com" }] }
Después de crear el archivo cluster.json, se ejecutar el siguiente comando para cada proyecto que se haya creado. El comando utiliza el archivo cluster.json para crear un clúster.
atlas cluster create --projectId 5e2211c17a3e5a48f5497de3 --file cluster.json
Para configurar un clúster multiregional, modifica el arreglo replicationSpecs en el archivo cluster.json anterior para especificar varias regiones, como se muestra en el siguiente ejemplo:
{ … "replicationSpecs": [ { "numShards": 1, "regionConfigs": [ { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 7, "providerName": "GCP", "regionName": "EASTERN_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } }, { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 5, "providerName": "GCP", "regionName": "CENTRAL_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } }, { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 6, "providerName": "GCP", "regionName": "WESTERN_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } } ], "zoneName": "Zone 1" } ], … }
Después de crear el archivo de configuración anterior, ejecuta el siguiente comando para crear el clúster:
atlas clusters create --file <path to your configuration file>
Para obtener más opciones de configuración e información sobre estos ejemplos, se puede consultar atlas clusters create.
Nota
Antes de poder crear recursos con Terraform, debe:
Crea tu organización pagadora y crea una clave de API para la organización pagadora. Guarde su clave API como variables de entorno ejecutando el siguiente comando en el terminal:
export MONGODB_ATLAS_PUBLIC_KEY="<insert your public key here>" export MONGODB_ATLAS_PRIVATE_KEY="<insert your private key here>"
Importante
Los siguientes ejemplos utilizan MongoDB Atlas Terraform proveedor versión 2.x (~> 2.2). Si estás actualizando desde la versión 1.x del proveedor, consulta la 2.0.0 Guía de actualización para cambios disruptivos y pasos de migración. Los ejemplos utilizan el recurso mongodbatlas_advanced_cluster con la versión v2.x sintaxis.
Crear los Proyectos y implementaciones
Para tus entornos de desarrollo y prueba, crea los archivos siguientes para cada aplicación y par de entornos. Coloca los archivos de cada aplicación y par de entornos en su propio directorio. Cambia las IDs y los nombres para usar tus valores:
main.tf
# Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalDev" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version # MongoDB recommends enabling auto-scaling # When auto-scaling is enabled, Atlas may change the instance size, and this use_effective_fields # block prevents Terraform from reverting Atlas auto-scaling changes use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Test" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.0.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
Nota
Para crear un clúster multiregional, especifique cada región en su propio objeto region_configs y anídelos en el objeto replication_specs. Los campos de priority deben definirse en orden descendente y deben consistir en valores entre 7 y 1, como se muestra en el siguiente ejemplo:
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Dev" environment = "dev" cluster_instance_size_name = "M10" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
Para tus entornos de pruebas y producción, crea los siguientes archivos para cada pareja de aplicación y entorno. Coloque los archivos para cada par de aplicación y entorno en su propio directorio. Cambia las ID y los nombres para usar tus valores:
main.tf
# Create a Group to Assign to Project resource "mongodbatlas_team" "project_group" { org_id = var.atlas_org_id name = var.atlas_group_name usernames = [ "user1@example.com", "user2@example.com" ] } # Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Assign the team to project with specific roles resource "mongodbatlas_team_project_assignment" "project_team" { project_id = mongodbatlas_project.atlas-project.id team_id = mongodbatlas_team.project_group.team_id role_names = ["GROUP_READ_ONLY", "GROUP_CLUSTER_MANAGER"] } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalProd" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 disk_size_gb = var.disk_size_gb } auto_scaling = { disk_gb_enabled = var.auto_scaling_disk_gb_enabled compute_enabled = var.auto_scaling_compute_enabled compute_max_instance_size = var.compute_max_instance_size } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Production" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
Nota
Para crear un clúster multiregional, especifique cada región en su propio objeto region_configs y anídelos en el objeto replication_specs, como se muestra en el siguiente ejemplo:
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" environment = "prod" cluster_instance_size_name = "M30" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0" atlas_group_name = "Atlas Group"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
Para obtener más opciones de configuración e información sobre este ejemplo, consulta MongoDB & HashiCorp Terraform.
Después de crear los archivos, navega hasta el directorio correspondiente al par de aplicación y entorno de cada uno y ejecuta el siguiente comando para inicializar Terraform:
terraform init
Ejecute el siguiente comando para ver el plan de Terraform:
terraform plan
Ejecuta el siguiente comando para crear un proyecto y una implementación para el par de aplicación y entorno. El comando usa los archivos y MongoDB & HashiCorp Terraform para crear los proyectos y los clústeres:
terraform apply
Cuando se le indique, escriba yes y presione Enter para aplicar la configuración.
Próximos pasos
Una vez que planifique la jerarquía y el tamaño de sus organizaciones, proyectos y clústeres, consulte los siguientes recursos sugeridos o utilice la navegación izquierda para encontrar funcionalidades y mejores prácticas para cada pilar del Marco Bien Arquitectado.