La alta disponibilidad es la capacidad de tu aplicación para garantizar un funcionamiento continuo y minimizar el tiempo de inactividad durante las interrupciones del servicio de infraestructura, el mantenimiento del sistema y otras interrupciones. La arquitectura de implementación por defecto de MongoDB está diseñada para una alta disponibilidad, con funcionalidades incorporadas para la redundancia de datos y la conmutación por error automática.
La alta disponibilidad es diferente de la recuperación ante desastres. La alta disponibilidad protege contra fallas de infraestructura, como caídas de nodos, zonas, regiones o proveedores de nube, mediante la conmutación por error automática que recupera el sistema al momento exacto de la falla sin pérdida de datos (RPO = 0) y RTO en segundos. La recuperación ante desastres protege contra problemas de integridad de datos como la corrupción o la eliminación accidental, que requieren la restauración a partir de copias de seguridad. Para obtener más información sobre recuperación ante desastres, consulta Guía para la recuperación ante desastres en Atlas.
Esta página describe opciones de configuración adicionales y mejoras en la arquitectura de implementación que se pueden elegir para evitar interrupciones y admitir mecanismos de conmutación por error robustos para interrupciones del servicio de zona, región y proveedor de nube.
Funciones de Atlas para alta disponibilidad
Replicación de base de datos
La arquitectura de implementación por defecto de MongoDB está diseñada para redundancia. Atlas implementa cada clúster como un conjunto de réplicas con un mínimo de tres instancias de bases de datos (también llamadas nodos o miembros del conjunto de réplicas), distribuidas en zonas de disponibilidad independientes dentro de las regiones de su proveedor de nube seleccionado. Las aplicaciones escriben datos en el nodo principal del set de réplicas y luego Atlas replica y almacena esos datos en todos los nodos de su clúster. Para controlar la durabilidad de tu almacenamiento de datos, puedes ajustar el nivel de confirmación de escritura (write concern) de tu código de aplicación para completar la escritura solo una vez que cierto número de secundarios hayan confirmado la escritura. El comportamiento por defecto es que los datos se guarden en la mayoría de los nodos elegibles antes de confirmar la acción.
El siguiente diagrama representa cómo funciona la replicación para un conjunto de réplicas predeterminado de tres nodos:

Conmutación por error automática
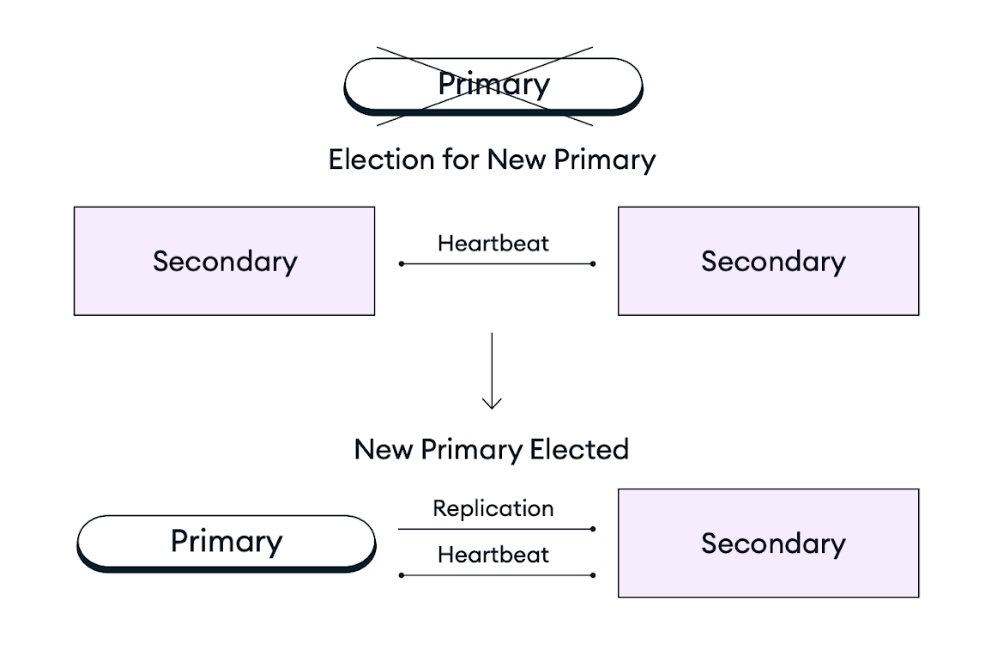
En caso de que un nodo primario en un set de réplicas se vuelva inaccesible debido a una interrupción del servicio de la infraestructura, mantenimiento programado o cualquier otra interrupción, los clústeres de Atlas se autorreparan promoviendo a un nodo secundario existente al rol de nodo primario en una elección de set de réplicas. Este proceso de conmutación por error es completamente automático y recupera al momento exacto de la falla sin pérdida de datos (RPO = 0) en segundos. Las operaciones que estaban en curso en el momento de la falla se vuelven a intentar tras el fallo si las escrituras repetibles están habilitadas. Después de una elección del set de réplicas, Atlas restaura o reemplaza al nodo que falla para garantizar que el clúster retorne a su configuración objetivo lo antes posible. El controlador cliente de MongoDB también cambia automáticamente todas las conexiones del cliente durante y después de la falla.
El siguiente diagrama representa el proceso de elección del set de réplicas:
Para mejorar la disponibilidad de tus aplicaciones más críticas, puedes escalar tu implementación agregando nodos, regiones o proveedores de nube para soportar las interrupciones del servicio de la zona, región o proveedor, respectivamente. Para obtener más información, consulta la Recomendación para Escalar el Paradigma de implementación para Tolerancia a Fallos a continuación.
Recomendaciones para la Alta Disponibilidad de Atlas
Las siguientes recomendaciones describen opciones de configuración adicionales y mejoras en la arquitectura de implementación que puede realizar para aumentar la disponibilidad de su implementación.
Selecciona un nivel de clúster que se ajuste a tus objetivos de implementación
Puedes elegir entre un rango de niveles de clúster disponibles en los tipos de implementación Dedicated, Flex o Free. El nivel del clúster en MongoDB Atlas especifica los recursos (memoria, almacenamiento, vCPU e IOPS) disponibles para cada nodo en tu clúster. El escalado a un nivel superior mejora la capacidad del clúster para gestionar picos de tráfico e incrementa la fiabilidad del sistema gracias a una respuesta más rápida ante altas cargas de trabajo. Para determinar el nivel de clúster recomendado para el tamaño de tu aplicación, consulta la Guía de tamaño del clúster Atlas.
Atlas también admite escalado automático para permitir que el clúster se adapte automáticamente a picos de demanda. Atlas utiliza tanto el escalado automático reactivo, que se activa en función del uso actual de los recursos, como el escalado automático predictivo, que escala proactivamente los clústeres elegibles antes de que ocurran picos cíclicos de demanda pronosticados. Automatizar las acciones de escalado reduce el riesgo de interrupciones del servicio debido a restricciones de recursos. Para obtener más información, consulta Orientación para el provisionamineto automatizado de infraestructura Atlas.
Escala tu paradigma de implementación para tolerancia a fallos
La tolerancia a fallos de una implementación de Atlas es el número de miembros del conjunto de réplicas que pueden dejar de estar disponibles mientras tu implementación sigue funcionando. En caso de una zona de disponibilidad, una región o un proveedor de nube, los clústeres de Atlas se autorreparan promoviendo un nodo secundario existente al rol de nodo principal en una elección de conjunto de réplicas. La mayoría de los nodos con derecho a voto en un set de réplicas debe estar operativa para llevar a cabo una elección de set de réplicas cuando el nodo primario experimente una interrupción del servicio.
Para garantizar que un set de réplicas pueda elegir un primario en caso de una Interrupción del servicio parcial de la región, se deben implementar clústeres en regiones con al menos tres zonas de disponibilidad. Las zonas de disponibilidad son grupos separados de centros de datos dentro de una sola región de un proveedor de nube, cada uno con su propia infraestructura de energía, refrigeración y red. Atlas distribuye automáticamente tu clúster entre las zonas de disponibilidad cuando son compatibles con la región del proveedor de la nube seleccionada, de modo que, si una zona experimenta una Interrupción del servicio, los nodos restantes de tu clúster siguen admitiendo los servicios regionales. La mayoría de las regiones de proveedores en la nube de Atlas cuentan con al menos tres zonas de disponibilidad. Estas regiones están marcadas con un ícono de estrella en la interfaz de usuario de Atlas.
Cada proveedor de nube proporciona redundancia de datos por defecto dentro de las zonas de disponibilidad:
AWS almacena datos en varios dispositivos en un mínimo de tres zonas de disponibilidad en una Región de AWS.
Microsoft Azure utiliza almacenamiento localmente redundante (LRS) que replica los datos tres veces dentro de un solo centro de datos en la región seleccionada.
Google Cloud distribuye los datos en varias zonas dentro de la región.
Para más información sobre las regiones recomendadas, consulta Proveedores de nube y regiones.
Para mejorar aún más la tolerancia a fallas de tus aplicaciones más críticas, puedes escalar tu implementación añadiendo nodos, regiones o proveedores de la nube para resistir interrupciones de zona de disponibilidad, región o proveedor, respectivamente. Puedes aumentar el número de nodos a cualquier número impar, con un máximo de 7 nodos elegibles y 50 nodos en total. También puedes implementar un clúster en múltiples regiones para mejorar la disponibilidad en una geografía más amplia y permitir la conmutación por error automática en caso de una Interrupción del servicio total de la región que desactive todas las zonas de disponibilidad dentro de tu región principal. El mismo patrón se aplica cuando se implementa tu clúster en múltiples proveedores de nube para resistir una Interrupción del servicio total del proveedor de nube.
Para obtener orientación sobre cómo elegir una implementación que equilibre tus necesidades de alta disponibilidad, baja latencia, cumplimiento y costo, consulta nuestra documentación de Paradigmas de implementación de Atlas.
Compromisos del paradigma de implementación de RTO/RPO
La siguiente tabla compara las características de RTO y RPO de diferentes paradigmas de implementación. Con majority nivel de confirmación de escritura (write concern), todos estos enfoques logran un RPO = 0 (sin pérdida de datos) y un RTO en segundos. Las compensaciones están en la complejidad de la implementación y el costo del clúster.
Paradigma de implementación | Escenarios de falla abarcados | RTO típico | RPO (con mayoría de nivel de confirmación de escritura (write concern)) | Complejidad relativa | Costo relativo del clúster |
|---|---|---|---|---|---|
Implementación en una sola región (3 nodos en la región 1) | Fallo de nodo o AZ dentro de una sola región | Segundos (conmutación por error automática) | 0 (sin pérdida de datos) | Bajo | $ |
Multiregión, nube única | Interrupción del servicio de AZ o región en una geografía | Segundos (conmutación por error automática) | 0 (sin pérdida de datos) | Intermedio | $$ |
Multiregión, multi-geo | Interrupción del servicio regional o geográfica en múltiples geografías | Segundos (conmutación por error automática) | 0 (sin pérdida de datos) | Medio-Alto | $$–$$$ |
Multi-nube (2–3 proveedores) | Interrupción del servicio del proveedor de nube o multiregión que afecta a un proveedor | Segundos (conmutación por error automática) | 0 (sin pérdida de datos) | Alto | $$$ |
Prevenir la eliminación accidental del clúster
Puedes habilitar la protección contra terminación para garantizar que un clúster no se termine accidentalmente y requiera tiempo de inactividad para la restauración desde una copia de seguridad. Para borrar un clúster que tiene habilitada la protección contra terminación, primero debes desactivar la protección contra terminación. Por defecto, Atlas desactiva la protección contra la terminación para todos los clústeres.
La protección contra terminación es especialmente importante cuando se utilizan herramientas de Infraestructura como Código (IaC) como Terraform para garantizar que una nueva implementación no suministre nueva infraestructura.
Pruebe las conmutaciones automáticas por error
Recomendamos encarecidamente que simule diversos escenarios que requieran conmutación por error automática de nodos para medir su grado de preparación para dichos eventos antes de implementar una aplicación en producción. Con Atlas, puedes probar la conmutación por error del nodo principal para un set de réplicas y simular interrupciones del servicio regionales para una implementación multiregión.
majority Utilice Escriba una inquietud
MongoDB permite especificar el nivel de confirmación solicitado para las operaciones de escritura mediante nivel de confirmación de escritura (write concern). Atlas tiene un nivel de confirmación de escritura (write concern) por defecto de majority, lo que significa que los datos deben replicarse en más de la mitad de los nodos de tu clúster antes de que Atlas informe éxito. Usar majority en lugar de un valor numérico definido como 2 permite que Atlas se ajuste automáticamente a requerir replicación en menos nodos si se experimenta una Interrupción del servicio temporal de nodos, permitiendo que las escrituras continúen después de una conmutación por error automática. Esto también provee un ajuste coherente en todos los entornos, por lo que tu cadena de conexión permanece igual tanto si tienes tres nodos en un entorno de prueba como si tienes un mayor número de nodos en producción.
Configura operaciones de lectura y escritura en base de datos con reintentos
Atlas admite lectura reintentable y escritura reintentable. Cuando está habilitado, Atlas vuelve a intentar las operaciones de lectura y escritura una vez como protección contra interrupciones intermitentes de la red y elecciones de set de réplicas en las que la aplicación no puede encontrar temporalmente un nodo primario saludable. Las escrituras reintentables requieren un nivel de confirmación de escritura (write concern) reconocido, lo que significa que tu nivel de confirmación de escritura (write concern) no puede ser {w: 0}.
Supervise y planifique su utilización de recursos
Para evitar problemas de capacidad de recursos, te recomendamos que supervises el uso de recursos y realices sesiones regulares de planificación de capacidad. Los Professional Services de MongoDB ofrecen estas sesiones. Consulta nuestro Plan de recuperación ante desastres por capacidad de recursos para conocer nuestras recomendaciones sobre cómo recuperarse de problemas de capacidad de recursos.
Para aprender las mejores prácticas para alertas y supervisión de la utilización de recursos, consulte Orientación para la supervisión y las alertas de Atlas.
Planifica tus cambios de versión de MongoDB
Recomendamos la ejecución de la última versión de MongoDB para aprovechar las nuevas funcionalidades y las garantías de seguridad mejoradas. Debes asegurarte siempre de actualizar a la última versión principal de MongoDB antes de que tu versión actual llegue al final de su vida útil.
No puedes degradar tu versión de MongoDB usando la interfaz de usuario de Atlas. Por ello, recomendamos trabajar directamente con los Professional Services o los Servicios técnicos de MongoDB al planificar y ejecutar una actualización de versión importante, para ayudarte a evitar cualquier problema que pueda surgir durante el proceso de actualización.
Configure las Windows de mantenimiento
Atlas mantiene el tiempo de actividad durante el mantenimiento programado aplicando actualizaciones de manera progresiva a un nodo a la vez. Siempre que el primario actual se apague para mantenimiento durante este proceso, Atlas elige un nuevo primario mediante una elección de set de réplicas automática. Este es el mismo proceso que ocurre durante la conmutación por error automática en respuesta a una Interrupción del servicio imprevista del nodo primario.
Recomendamos que configurar un periodo de mantenimiento personalizado para su Proyecto para evitar elecciones de sets de réplicas relacionadas con el mantenimiento durante las horas críticas para el negocio. También puedes establecer horas protegidas en la configuración de tu periodo de mantenimiento para definir un intervalo diario en el que no pueden comenzar las actualizaciones estándar. Las actualizaciones estándar no implican reinicio ni resincronización del clúster.
Ejemplos de automatización: Alta disponibilidad de Atlas
Los siguientes ejemplos configuran la topología de implementación de set de réplicas / partición de región única, 3 nodo utilizando las herramientas de Atlas para la automatización.
Estos ejemplos también aplican otras configuraciones recomendadas, entre ellas:
El nivel de clúster se establece en
M10para un entorno de desarrollo/pruebas. Utilice la guía de tamaños de clúster para conocer el nivel de clúster recomendado para el tamaño de su aplicación.Topología de implementación de un solo set de réplicas/región con 3nodos y partición.
Nuestros ejemplos utilizan AWS, Azure y Google Cloud indistintamente. Puedes usar cualquiera de estos tres proveedores de nube, pero debes cambiar el nombre de la región para que coincida con el proveedor de nube. Para obtener información sobre los proveedores de nube y sus regiones, consulte Proveedores de nube.
Nivel de clúster establecido en
M30para una aplicación de tamaño mediano. Utiliza la guía de tamaños de clúster para conocer el nivel de clúster recomendado para el tamaño de tu aplicación.Topología de implementación de un solo set de réplicas/región con 3nodos y partición.
Nuestros ejemplos utilizan AWS, Azure y Google Cloud indistintamente. Puedes usar cualquiera de estos tres proveedores de nube, pero debes cambiar el nombre de la región para que coincida con el proveedor de nube. Para obtener información sobre los proveedores de nube y sus regiones, consulte Proveedores de nube.
Nota
Antes de poder crear recursos con la CLI de Atlas, debes:
Crea tu organización pagadora y crea una clave de API para la organización pagadora.
Conéctese desde la Atlas CLI utilizando los pasos para Programmatic Use.
Crea una implementación por proyecto
Para sus entornos de desarrollo y pruebas, ejecute el siguiente comando para cada proyecto. En el siguiente ejemplo, cambia los IDs y los nombres para usar tus valores.
Nota
El siguiente ejemplo no habilita el escalado automático para ayudar a controlar los costos en los entornos de desarrollo y prueba. Para los entornos de staging y producción, el escalado automático debe estar habilitado. Consulta la pestaña "Entornos de staging y producción" para ver ejemplos que permiten el escalado automático.
atlas clusters create CustomerPortalDev \ --projectId 56fd11f25f23b33ef4c2a331 \ --region EASTERN_US \ --members 3 \ --tier M10 \ --provider GCP \ --mdbVersion 8.0 \ --diskSizeGB 30 \ --tag bu=ConsumerProducts \ --tag teamName=TeamA \ --tag appName=ProductManagementApp \ --tag env=dev \ --tag version=8.0 \ --tag email=marissa@example.com \ --watch
Para tus entornos de preproducción y producción, crea el siguiente archivo de cluster.json para cada proyecto. Cambia los ID y los nombres para usar tus valores:
{ "clusterType": "REPLICASET", "links": [], "name": "CustomerPortalProd", "mongoDBMajorVersion": "8.0", "replicationSpecs": [ { "numShards": 1, "regionConfigs": [ { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 7, "providerName": "GCP", "regionName": "EASTERN_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } } ], "zoneName": "Zone 1" } ], "tag" : [{ "bu": "ConsumerProducts", "teamName": "TeamA", "appName": "ProductManagementApp", "env": "Production", "version": "8.0", "email": "marissa@example.com" }] }
Después de crear el archivo cluster.json, ejecutar el siguiente comando para cada proyecto. El comando usa el archivo cluster.json para crear un clúster.
atlas cluster create --projectId 5e2211c17a3e5a48f5497de3 --file cluster.json
Para obtener más opciones de configuración e información sobre este ejemplo, consulta el comando atlas clústeres create.
Nota
Antes de poder crear recursos con Terraform, debe:
Crea tu organización pagadora y crea una clave de API para la organización pagadora. Guarde su clave API como variables de entorno ejecutando el siguiente comando en el terminal:
export MONGODB_ATLAS_PUBLIC_KEY="<insert your public key here>" export MONGODB_ATLAS_PRIVATE_KEY="<insert your private key here>"
Importante
Los siguientes ejemplos utilizan MongoDB Atlas Terraform proveedor versión 2.x (~> 2.2). Si estás actualizando desde la versión 1.x del proveedor, consulta la 2.0.0 Guía de actualización para cambios disruptivos y pasos de migración. Los ejemplos utilizan el recurso mongodbatlas_advanced_cluster con la versión v2.x sintaxis.
Crear los Proyectos y implementaciones
Para tus entornos de desarrollo y prueba, crea los archivos siguientes para cada aplicación y par de entornos. Coloca los archivos de cada aplicación y par de entornos en su propio directorio. Cambia las IDs y los nombres para usar tus valores:
main.tf
# Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalDev" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version # MongoDB recommends enabling auto-scaling # When auto-scaling is enabled, Atlas may change the instance size, and this use_effective_fields # block prevents Terraform from reverting Atlas auto-scaling changes use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Test" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.0.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
Nota
Para crear un clúster multiregional, especifique cada región en su propio objeto region_configs y anídelos en el objeto replication_specs. Los campos de priority deben definirse en orden descendente y deben consistir en valores entre 7 y 1, como se muestra en el siguiente ejemplo:
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Dev" environment = "dev" cluster_instance_size_name = "M10" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
Después de crear los archivos, navega hasta el directorio correspondiente al par de aplicación y entorno de cada uno y ejecuta el siguiente comando para inicializar Terraform:
terraform init
Ejecute el siguiente comando para ver el plan de Terraform:
terraform plan
Ejecuta el siguiente comando para crear un proyecto y una implementación para el par de aplicación y entorno. El comando usa los archivos y MongoDB & HashiCorp Terraform para crear los proyectos y los clústeres:
terraform apply
Cuando se le indique, escriba yes y presione Enter para aplicar la configuración.
Para tus entornos de pruebas y producción, crea los siguientes archivos para cada pareja de aplicación y entorno. Coloque los archivos para cada par de aplicación y entorno en su propio directorio. Cambia las ID y los nombres para usar tus valores:
main.tf
# Create a Group to Assign to Project resource "mongodbatlas_team" "project_group" { org_id = var.atlas_org_id name = var.atlas_group_name usernames = [ "user1@example.com", "user2@example.com" ] } # Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Assign the team to project with specific roles resource "mongodbatlas_team_project_assignment" "project_team" { project_id = mongodbatlas_project.atlas-project.id team_id = mongodbatlas_team.project_group.team_id role_names = ["GROUP_READ_ONLY", "GROUP_CLUSTER_MANAGER"] } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalProd" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 disk_size_gb = var.disk_size_gb } auto_scaling = { disk_gb_enabled = var.auto_scaling_disk_gb_enabled compute_enabled = var.auto_scaling_compute_enabled compute_max_instance_size = var.compute_max_instance_size } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Production" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
Nota
Para crear un clúster multiregional, especifique cada región en su propio objeto region_configs y anídelos en el objeto replication_specs, como se muestra en el siguiente ejemplo:
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" environment = "prod" cluster_instance_size_name = "M30" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0" atlas_group_name = "Atlas Group"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
Después de crear los archivos, navega hasta el directorio correspondiente al par de aplicación y entorno de cada uno y ejecuta el siguiente comando para inicializar Terraform:
terraform init
Ejecute el siguiente comando para ver el plan de Terraform:
terraform plan
Ejecuta el siguiente comando para crear un proyecto y una implementación para el par de aplicación y entorno. El comando usa los archivos y MongoDB & HashiCorp Terraform para crear los proyectos y los clústeres:
terraform apply
Cuando se le indique, escriba yes y presione Enter para aplicar la configuración.
Para obtener más opciones de configuración e información sobre este ejemplo, consulta MongoDB y HashiCorp Terraform y la Entrada de Blog de MongoDB Terraform.