重要
$rankFusion 仅适用于使用MongoDB 8.0 或更高版本的部署。
定义
$rankFusion$rankFusion首先独立执行所有输入管道,然后去重并将输入管道结果组合成最终的排名结果设立。$rankFusion根据输入文档在其输入管道中出现的排名以及管道权重,输出一设立经过排名的文档。此阶段使用倒数排名融合算法对输入管道的组合结果进行排名。使用
$rankFusion根据多个条件在单个集合中搜索文档,并检索了所有指定条件的最终排名结果设立。
语法
该阶段采用以下语法:
{ $rankFusion: { input: { pipelines: { <myPipeline1>: <expression>, <myPipeline2>: <expression>, ... } }, combination: { weights: { <myPipeline1>: <numeric expression>, <myPipeline2>: <numeric expression>, ... } }, scoreDetails: <bool> } }
命令字段
$rankFusion 采用以下字段:
字段 | 类型 | 说明 |
|---|---|---|
| 对象 | 定义 |
input.pipelines | 对象 | |
| 对象 | 可选。定义如何合并 |
combination.weights | 对象 | 可选。包含从 如果未指定权重,默认值为 1。 |
| 布尔 | 默认为 false。指定 |
行为
集合
您只能将 $rankFusion 与单个集合一起使用。您不能在数据库范围内使用此聚合阶段。
De-Duplication
$rankFusion 对最终输出中多个输入管道的结果去重。每个唯一的输入文档在 $rankFusion 输出中最多出现一次,无论该文档在输入管道输出中出现多少次。
输入管道
每个 input管道必须既是选择管道又是排名管道。
选择管道
选择管道从集合中检索一设立文档,并且在检索后不执行任何修改。$rankFusion 比较不同输入管道中的文档,这要求所有输入管道输出相同的未经修改的文档。
注意
如果要修改使用 $rankFusion搜索的文档,请在 $rankFusion 阶段之后执行这些修改。
选择管道必须仅包含以下阶段:
排名管道
排名管道对文档进行排序或排序。$rankFusion 使用排名管道结果的顺序来影响输出排名。排名管道必须满足以下条件之一:
从以下有序阶段之一开始:
包含显式
$sort阶段。
输入管道名称
input 中的管道名称必须符合以下限制:
不得为空字符串
不得以
$不得在字符串中的任何位置包含 ASCII 空字符分隔符
\0不得包含
.
倒数排名融合 (RRF) 公式
$rankFusion 根据倒数排名融合 (RRF) 公式对结果进行排序。此阶段将每个文档的 RRF 分数放入输出结果的 score元数据字段中。RRF 公式结合以下因素对文档进行排名:
文档在输入管道结果中的放置
文档在不同输入管道中出现的次数
输入管道的
weights。
示例,如果某一文档在多个管道结果集中排名较高,则该文档的 RRF 分数将高于该文档在某些输入管道中排名相同但不存在(或排名较低)的情况。在其他管道中
倒数排名融合 (RRF) 公式等效于以下代数运算:

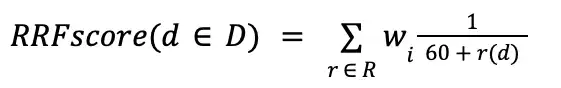
注意
在此公式中,60 是MongoDB确定的敏感度参数。
下表包含 RRF 公式使用的变量:
变量 | 说明 |
|---|---|
D | 整个操作的结果文档设立。 |
d | 正在计算 RRF 分数的文档。 |
R |
|
r(d) | 文档 |
w |
|
总和中的每术语代表文档d 在 input 管道之一中的出现情况。d 的 RRF 总分数是 d 出现的所有输入管道中每个词的总和。
RRF 计算示例
考虑具有一个 $search 和一个 $vectorSearch 输入管道的 $rankFusion管道阶段。
所有输入管道均输出相同的 3 文档:Document1、Document2 和 Document3。
$search管道按以下顺序对文档进行排名:
Document3Document2Document1
$vectorSearch管道按以下顺序对文档进行排名:
Document1Document2Document3.
rankFusion 通过以下操作计算 Document1 的 RRF 分数:
RRFscore(Document1) = 1/(60 + search_rank_of_Document1) + (1/(60 + vectorSearch_rank_of_Document1)) RRFscore(Document1) = 1/63 + 1/61 RRFscore(Document1) = 0.0322664585
Document1 的 score 元元数据字段为 0.0322664585。
分数详情
如果将 scoreDetails设立为 true,$rankFusion 则会为每个文档创建一个 scoreDetails 元元数据字段。scoreDetails字段包含有关最终排名的信息。
注意
当您将 scoreDetails设立为 true 时,$rankFusion 会为每个文档设置 scoreDetails 元元数据字段,但不会自动输出 scoreDetails 元字段。
要查看 scoreDetails元数据字段,您必须:
在
$rankFusion之后使用$project阶段项目scoreDetails字段在
$rankFusion之后使用$addFields阶段将scoreDetails字段添加到管道输出
scoreDetails字段包含以下子字段:
字段 | 说明 |
|---|---|
| 此文档的 RRF 分数的数值。 |
|
|
| 一个大量,其中每个大量条目都包含有关输出此文档的输入管道的信息。 |
details字段中的每个大量条目都包含以下子字段:
字段 | 说明 |
|---|---|
| 输出此文档的输入管道的名称。 |
| 此文档在输入管道中的排名。如果其他管道阶段输出中返回的文档不存在于此管道阶段的输出中,则该管道阶段输出中的排名为 |
| 输入管道的权重。 |
| 可选。如果输入管道输出此文档的 |
| 可选。如果输入管道输出 |
| 输入管道的 |
警告
MongoDB不保证 scoreDetails 的任何特定输出格式。
示例,以下代码块显示具有 $search、$vectorSearch 和 $match 输入管道的 $rankFusion 操作的 scoreDetails字段:
{ value: 0.030621785881252923, description: "value output by reciprocal rank fusion algorithm, computed as sum of weight * (1 / (60 + rank)) across input pipelines from which this document is output, from:" details: [ { inputPipelineName: 'search', rank: 2, weight: 1, value: 0.3876491287, description: "sum of:", details: [... omitted for brevity in this example ...] }, { inputPipelineName: 'vector', rank: 9, weight: 3, value: 0.7793490886688232, details: [ ] }, { inputPipelineName: 'match', rank: 10, weight: 1, details: [] } ] }
解释结果
MongoDB将 $rankFusion 操作转换为一设立现有的聚合阶段,这些阶段在查询执行之前结合起来计算输出结果。$rankFusion 操作的“解释结果”显示了 $rankFusion 用于构成最终结果的根本的聚合阶段的完整执行情况。
示例
此示例使用具有嵌入和文本字段的集合。在集合上创建 search 和 vectorSearch 类型索引。
以下索引定义自动为集合中的所有动态可索引字段编制索引,以便对索引字段运行$search 查询。
db.embedded_movies.createSearchIndex( "search_index", { mappings: { dynamic: true } } )
以下索引定义使用集合中的嵌入对该字段进行索引,以便对该字段运行$vectorSearch 查询。
db.embedded_movies.createSearchIndex( "vector_index", "vectorSearch", { "fields": [ { "type": "vector", "path": "<FIELD_NAME>", "numDimensions": <NUMBER_OF_DIMENSIONS>, "similarity": "dotProduct" } ] } );
以下聚合管道将 $rankFusion 与以下输入管道结合使用:
管道 | 返回的文档数量 | 说明 |
|---|---|---|
| 20 | 在索引为 |
| 20 | 对同一术语运行全文搜索,并将结果限制为 20 个文档。 |
1 db.embedded_movies.aggregate( [ 2 { 3 $rankFusion: { 4 input: { 5 pipelines: { 6 searchOne: [ 7 { 8 "$vectorSearch": { 9 "index": "<INDEX_NAME>", 10 "path": "<FIELD_NAME>", 11 "queryVector": <QUERY_EMBEDDINGS>, 12 "numCandidates": 500, 13 "limit": 20 14 } 15 } 16 ], 17 searchTwo: [ 18 { 19 "$search": { 20 "index": "<INDEX_NAME>", 21 "text": { 22 "query": "<QUERY_TERM>", 23 "path": "<FIELD_NAME>" 24 } 25 } 26 }, 27 { "$limit": 20 } 28 ], 29 } 30 } 31 } 32 }, 33 { $limit: 20 } 34 ] )
此操作执行以下操作:
执行
input管道合并返回的结果
输出前 20 个文档,即
$rankFusion管道中排名前 20 的结果
本页上的 Node.js 示例使用 Atlas 示例数据集中的 sample_mflix数据库。要学习如何创建免费的MongoDB Atlas 集群并加载示例数据集,请参阅MongoDB Node.js驱动程序文档中的入门。
要使用MongoDB Node.js驱动程序将 $rankFusion 阶段添加到聚合管道,请在管道对象中使用 $rankFusion操作符。
在运行以下示例之前,您必须创建一个名为 default 的Atlas Search索引。在应用程序中包含以下代码,以在 movies集合上创建搜索索引:
const index = { name: "default", definition: { mappings: { dynamic: true } } } const result = collection.createSearchIndex(index);
以下示例创建了一个管道阶段,用于执行两个管道(searchPlot 和 searchGenre),这两个管道使用 default 搜索索引执行$search操作。然后,$rankFusion 阶段根据每个 $search 管道分配的权重对搜索结果进行排名,并返回排序后的结果。$addFields 阶段在返回文档中包含 scoreDetails字段。然后,该示例运行聚合管道:
const pipeline = [ { $rankFusion: { input: { pipelines: { searchPlot: [ { $search: { index: "default", text: { query: "space", path: "plot"} } } ], searchGenre: [ { $search: { index: "default", text: { query: "adventure", path: "genres" } } } ] } }, combination: { weights: {searchPlot: 0.6, searchGenre: 0.4} }, scoreDetails: true } }, { $addFields: { scoreDetails: { $meta: "searchScoreDetails" } } } ]; const cursor = collection.aggregate(pipeline); return cursor;