检索增强生成 (RAG) 是一种架构,用于使用额外数据增强大型语言模型 (LLM),以便生成更准确的响应。您可以将LLM与由MongoDB Vector Search 提供支持的检索系统相结合,在生成式人工智能应用程序中实现RAG。
开始体验
要快速尝试将 RAG 与 MongoDB Vector Search 结合使用,请使用 MongoDB Search Playground 中的聊天机器人演示构建器。要学习;了解更多信息,请参阅 Search Playground 中的聊天机器人演示生成器。
要使用MongoDB Vector Search实现自己的 RAG 系统,请参阅本页上的教程。
为何使用 RAG?
在使用 LLM 时,您可能会遇到以下限制:
过时数据:LLM 是在特定时间点之前的静态数据集上训练的。这意味着他们的知识库有限,并且可能会使用过时的数据。
无权访问其他数据:LLM 无权访问本地、个性化或特定领域的数据。因此,他们可能缺乏有关特定领域的知识。
幻觉:当基于不完整或过时的数据时,LLM 可能会生成不准确的响应。
您可以按以下步骤实现 RAG 来解决这些限制:
摄取:将自定义数据作为vector embeddings存储在矢量数据库(例如MongoDB)中。这样,您就可以创建最新的个性化数据知识库。
检索:使用搜索解决方案(例如MongoDB Vector Search)根据用户的问题从数据库中检索语义相似的文档。这些文档通过额外的相关数据丰富了法学硕士课程。
生成:提示 LLM。LLM 使用检索到的文档作为上下文来生成更准确和更相关的响应,从而减少幻觉。
RAG 是一种构建 AI 聊天机器人的有效架构,因为它使 AI 系统能够提供个性化、领域特定的响应。要创建可用于生产的聊天机器人,请配置服务器来路由请求并在 RAG 实现的基础上构建用户界面。
带有MongoDB Vector Search 的 RAG
要使用MongoDB Vector Search实现RAG,您需要将数据提取到MongoDB中,使用MongoDB Vector Search检索文档,并使用 LLM 生成响应。本节介绍使用MongoDB Vector Search 进行基本或幼稚的RAG实施的组件。有关分步说明,请参阅教程。
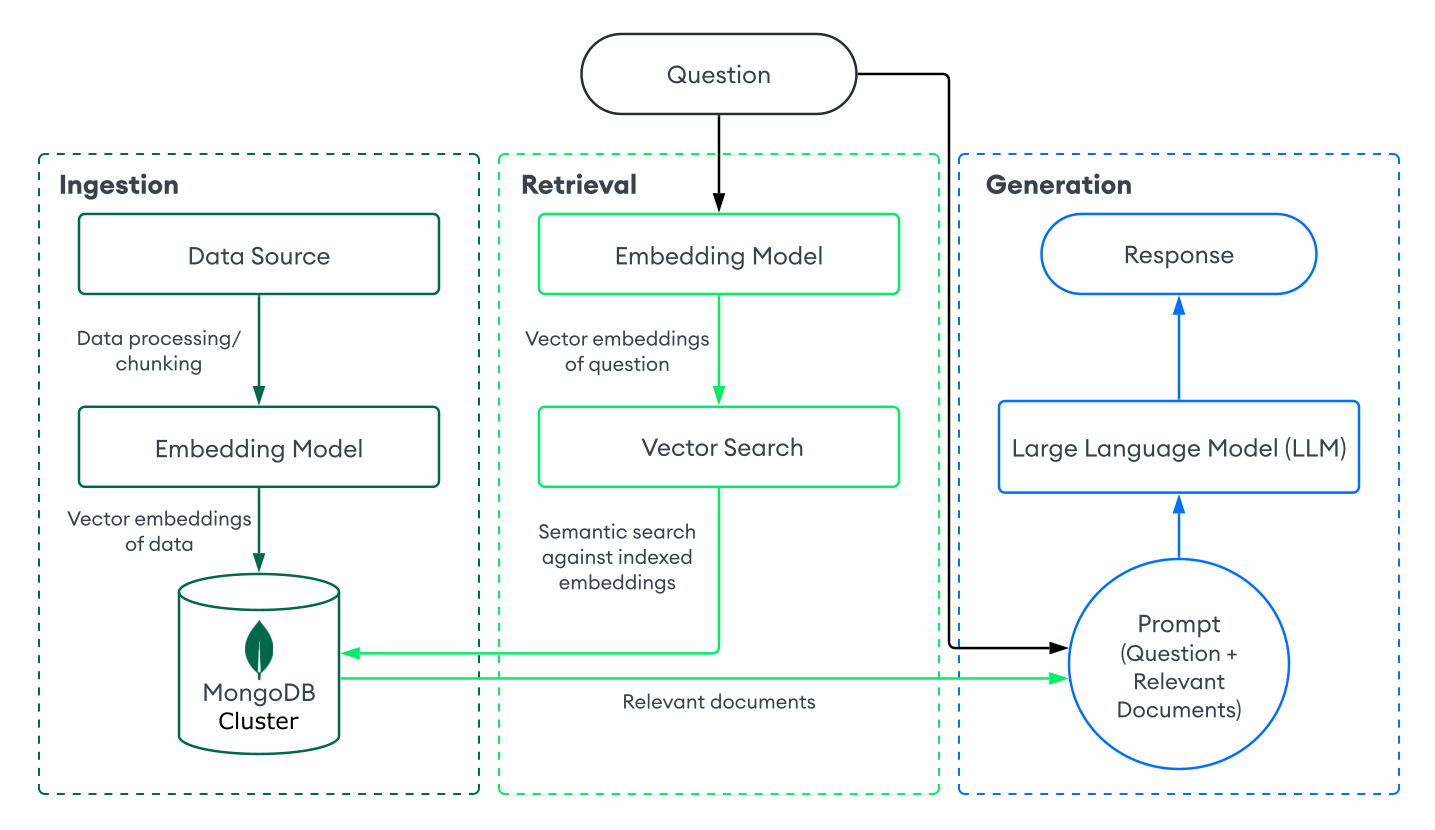
接收
RAG 的数据摄取涉及处理自定义数据并将其存储在向量数据库中以准备检索。要使用MongoDB作为向量数据库创建基本摄取管道,请执行以下操作:
准备您的数据。
加载、处理并对数据进行 分块,以便为您的 RAG 应用做好准备。数据块涉及将您的数据分成较小的部分,以便优化检索。
将数据转换为向量嵌入。
使用embedding model将数据转换为vector embeddings。要学习;了解更多信息,请参阅如何手动创建Vector Embeddings。
将数据和嵌入存储在MongoDB中。
将这些嵌入存储在集群中。您可以将嵌入作为一个字段与其他数据一起存储在集合中。
Retrieval
构建检索系统涉及从向量数据库中搜索并返回最相关的文档,以增强法学硕士学位。 要使用MongoDB Vector Search检索相关文档,您可以将用户的问题转换为向量嵌入,并对MongoDB集合中的数据运行向量搜索查询,以查找嵌入最相似的文档。
要使用MongoDB Vector Search 执行基本检索,请执行以下操作:
在包含向量嵌入的集合上定义MongoDB Vector Search索引。
根据用户的问题选择以下方法之一来检索文档:
使用MongoDB 向量搜索 集成与常用框架或服务。这些集成包括内置库和工具,启用您能够使用MongoDB 向量搜索 轻松构建检索系统。
构建自己的检索系统。您可以定义自己的函数和管道来运行特定于您使用案例的MongoDB Vector Search 查询。
要学习;了解如何使用MongoDB Vector Search构建基本检索系统,请参阅教程。
生成
要生成响应,请将您的检索系统与 LLM 相结合。在执行向量搜索以检索相关文档后,可以将用户的问题和相关文档作为上下文提供给 LLM,这样它就可以生成更准确的答案。
选择以下方法之一连接到 LLM:
使用MongoDB 向量搜索 集成与常用框架或服务。这些集成包括内置库和工具,可帮助您以最少的设置连接到法学硕士。
调用 LLM 的 API。大多数 AI 提供商为其生成模型提供 API,您可以使用这些 API 来生成响应。
加载开源 LLM。如果您没有API密钥或信用额度,您可以通过从应用程序本地加载开源 LLM 来使用。有关实施示例,请参阅使用MongoDB Vector Search 构建本地 RAG 实现教程。
Tutorial
以下示例演示如何使用由 MongoDB Vector Search 提供支持的检索系统来实现 RAG。选择您首选的嵌入模型、LLM 和编程语言以开始:
后续步骤
有关其他 RAG 教程,请参阅以下资源:
要学习;了解如何使用流行的 LLM 框架和AI服务实现RAG,请参阅MongoDB AI集成。
要学习了解如何使用本地Atlas部署和本地模型实现RAG,请参阅使用MongoDB Vector Search 构建本地 RAG 实施。
For use-case based tutorials and interactive Python notebooks, see Docs Notebooks Repository and Generative AI Use Cases Repository.
要构建AI助手并实现代理 RAG,请参阅使用MongoDB构建AI助手。
Improve Your Results
要优化 RAG 应用进程,请确保使用强大的嵌入模型(如 Voyage AI)来生成高质量的矢量嵌入。
此外, MongoDB 向量搜索 支持高级检索系统。您可以无缝地将向量数据与集群中的其他数据一起索引。这样,您就可以通过预筛选集合中的其他字段或执行混合搜索来改进结果。
数据块策略
数据块在生成嵌入之前将大型文档分解为较小的片段。正确的分块策略可以显着提高 RAG 应用程序的检索质量。
数据块策略由以下关键部分组成:
拆分技术:确定放置数据块边界的位置,例如段落边界、特定于编程语言的分隔符、词元或语义边界。
数据块大小:每个数据块的最大字符数或词元数。
数据块重叠:相邻数据块之间重叠字符或词元的数量。重叠有助于跨数据块边界保留上下文。
常见的数据块划分策略包括:
策略 | 最适合 |
|---|---|
固定令牌 | 具有统一内容结构的简单用例。 |
修复存在重叠的词元 | 上下文跨越数据数据块边界的通用分块。 |
递归 | 要保留段落和句子边界的文本文档。 |
特定于语言的递归 | 带有编程语言片段的代码或技术文档。 |
semantic | 没有明确结构边界的文档,例如论文或叙述性内容。 |
要试验数据块策略,请使用MongoDB Search Playground 中的聊天机器人演示生成器,它允许您尝试递归数据块和具有重叠的固定词元数据块。
有关使用 Ragas框架评估不同分块策略的实践教程,请参阅 GenAI-Showcase存储库中的分块策略笔记本。
您还可以使用以下资源: