本页探讨了MongoDB Vector Search 性能基准测试的结果。
结果总结
在 2048 维度使用
voyage-3-large个嵌入的 15.3M 个向量时,配置了量化的MongoDB Vector Search 保持了 90-95% 的精度,查询延迟< 50 毫秒。由于使用全保真向量重新评分需要额外的成本,因此当请求的候选向量数量达到数百个时,二进制量化的速度较慢。不过,以提供索引的 ~1/4 价格计算,它可能是许多大规模工作负载的首选。
在运行较大工作负载时进行量化时,我们建议使用超过 1024 个维度。
选择性过滤器可以提高或降低性能,具体取决于为
numCandidates选择的值。在运行高度并发的工作负载时,二进制量化重新评分的额外成本会导致吞吐量降低。
分片可略微提高吞吐量,但我们仍建议扩大搜索节点的数量或搜索节点上可用内核的数量,以提高吞吐量。
多维基准测试中的召回率和延迟分析
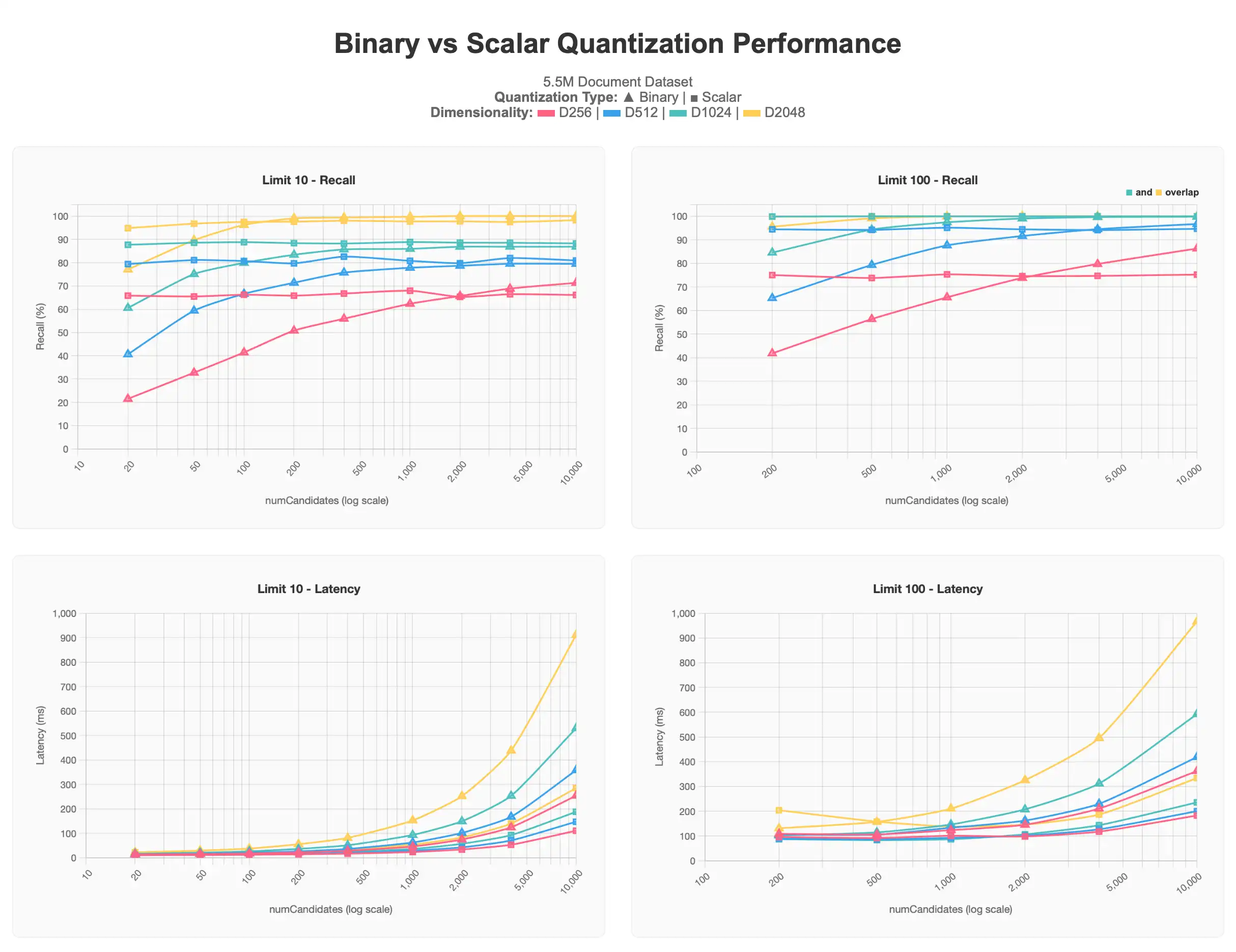
第一组结果显示的是我们对 5. 5 百万个文档数据集进行的测试,该数据集包含多个维度的向量(256、512、1024、2048),每个文档中的所有向量均使用 voyage-3-large 生成。

要查看完整图表,请参阅 Claude artifact。
标量量化结果的起始级别都高于二进制量化结果的级别,但即使 numCandidates 增加,仍会保持在渐近级别。相反,随着请求的 numCandidates 越多,二进制量化查询就会产生更准确的结果,接近标量量化的渐近线,并且在某些情况下超过标量量化的渐近线,但费用是更高的延迟,特别是在超过 1000 的 numCandidates 时。
通常,较低的 limit 值更难接近 100% 的准确率,因为顶级结果更难精确定位,并且通常可能需要更高的 numCandidates 才能获得更好的结果。这在二进制量化图中尤为明显。我们还可以观察到,低维向量 256 维和 512 维在进行任一种形式的量化时,其性能在大规模场景下都会显著下降。在极限 10 测试中,256 维从不超过 70% 召回率,512 维从不超过 80% 召回率,而极限 100 需要更高的值 numCandidates 才能达到 90-95% 的目标区域。
根据这些信息,我们认为,在处理大型数据集时,我们建议维度至少为 1024 维,并应用量化来扩展规模,而不是采用更低维度且不进行量化的方案,同时应用场景请求的向量数量也是考量因素之一。
更大规模的基准测试结果
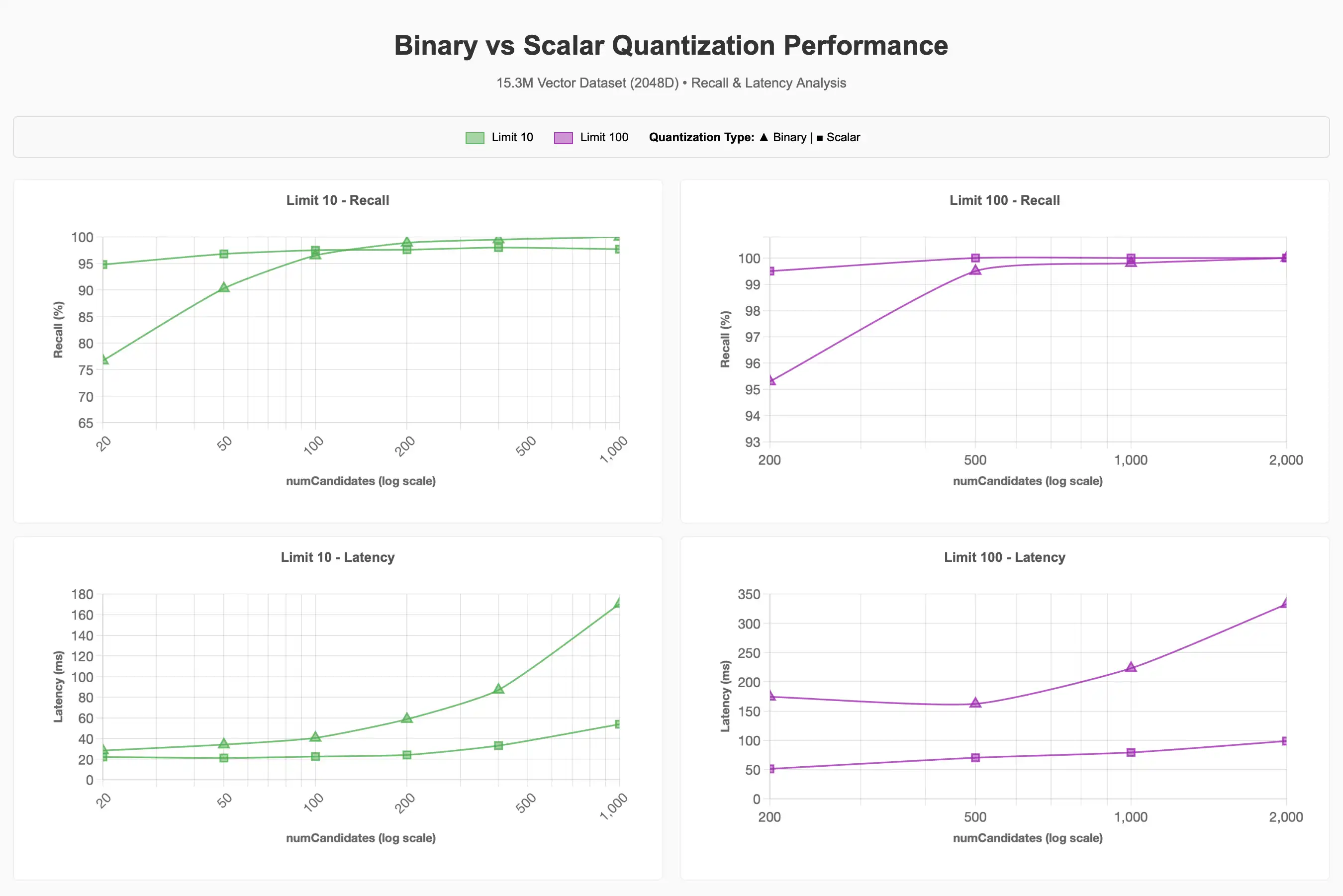
对于较大的 15.3M 向量数据集,我们将维度固定为 2048 维,并检查了量化、过滤和并发操作对性能的影响。我们最终选择将维度固定在 2048 维,这是因为前一组测试的结果显示,更高维度能更有效地保持召回率,不过,要达到 90-95% 的召回率目标,1024 维可能同样适用。
召回率和延迟分析
我们观察到,与基线相比,使用二进制量化要实现 90–95% 的召回率目标,需要花费更多的 numCandidates。较高的 numCandidates 通常意味着更高的延迟,但这可能会有所不同。

要查看完整图表,请参阅 Claude artifact。
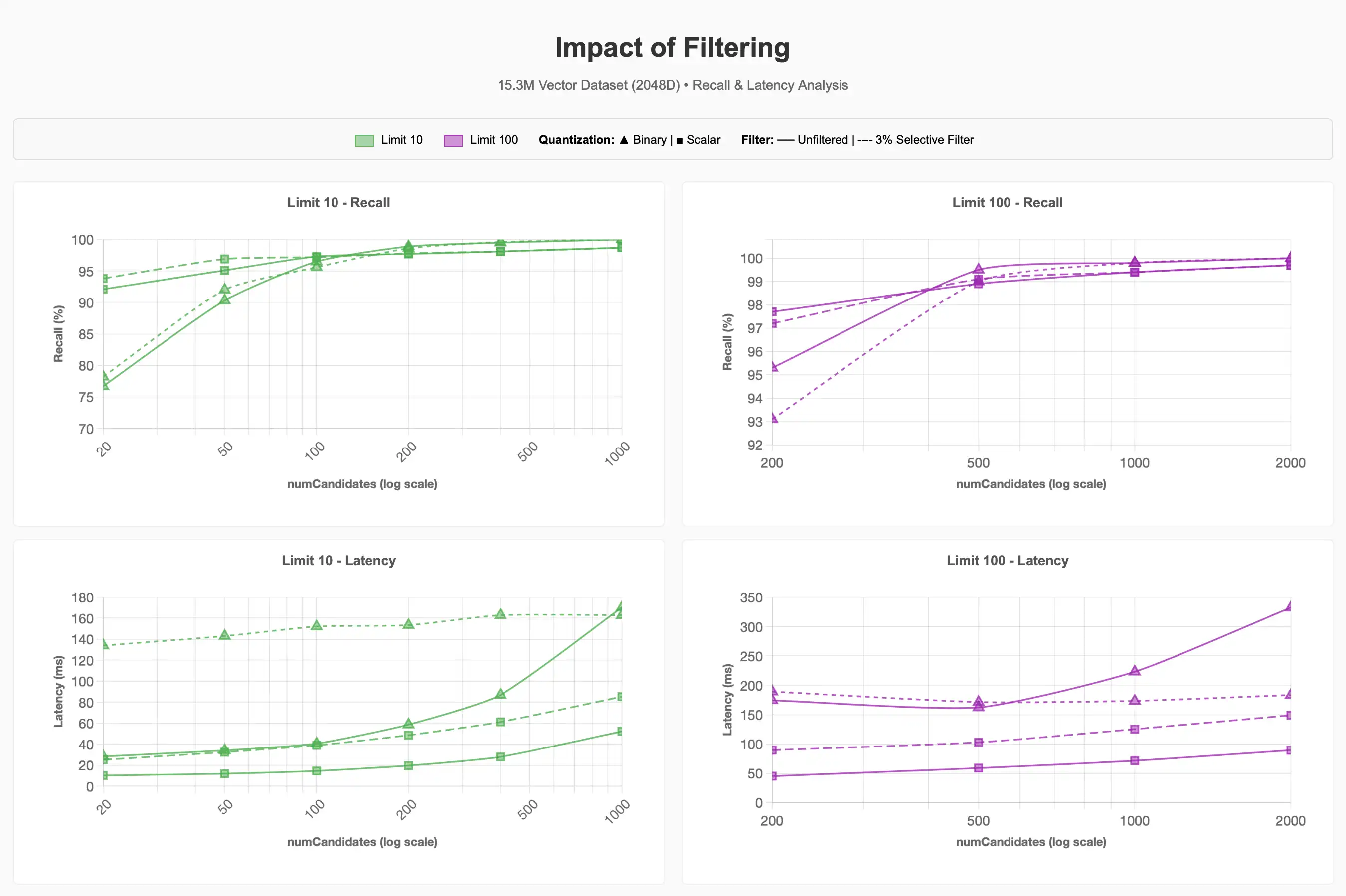
过滤
我们观察了在数据集上使用选择性过滤器时召回率与延迟的变化情况,当约 500 千条项目(占语料库的 ~3%)属于宠物用品类别(总项目数 15.3 百万条)时:

要查看完整图表,请参阅 Claude artifact。
我们可以看到,3% 选择性过滤器可能会导致查询成本显著增加。对于较低 limit 值的二进制量化,实现 90-95% 的召回率成本大约是未过滤查询的 4 倍。
未来对 Lucene 10 的改进,特别是支持 Acorn-1 搜索策略的分层可导航小世界,可能会改善这一过程。然而,当请求的候选数超过段内符合元数据过滤器的向量数时,执行 ENN 表明,过滤器的选择性在查询性能中起着重要作用,无论采用何种量化方案。
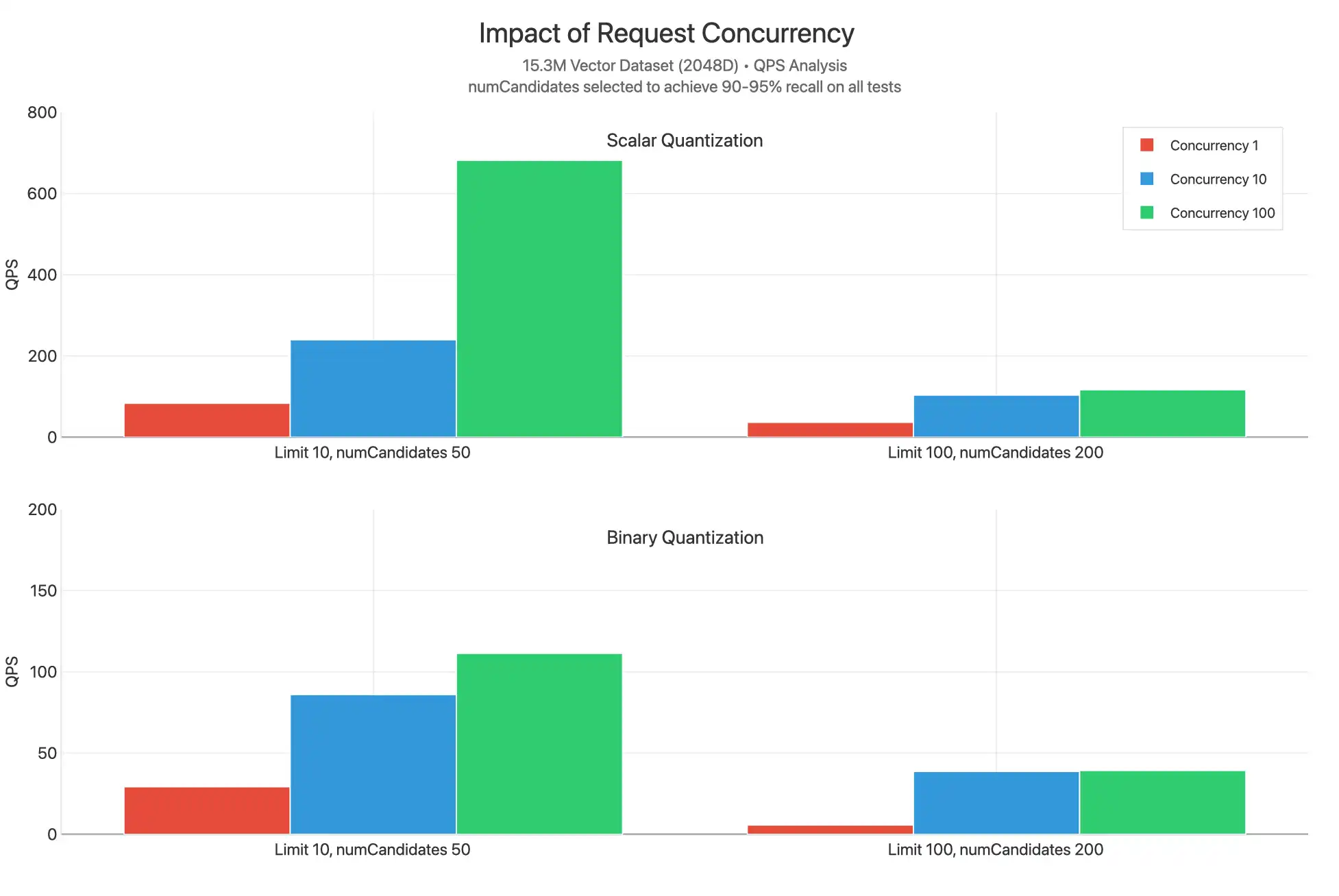
并发
在使用标量和二进制量化时,这些测试会根据不同的 limit 值在 1、 10 和 100 之间扩展并发请求。numCandidates 是通过选择能达到 90-95% 召回率的值来选定的:

要查看完整图表,请参阅 Claude artifact。
我们观察到,标量量化在所有限制值下均实现了显著更高的 QPS,这可能是因为在较低的 numCandidates 下,每个查询所需的工作量减少,并且未重新评分。我们观察到发生了大量的 CPU 瓶颈,如并发 10 和并发 100 图通常彼此非常接近所示,这表明将观察到更高的延迟。
一个特殊的数据点是极限 10,并发 100 的标量量化产生显著更高的 QPS。这可能是因为没有重新评分,较低的 limit 值意味着对此查询执行的比较较少,从而允许每个请求更快地返回,并使内核可用于服务其他查询。
通过扩展搜索节点层级或扩展搜索节点数量,从最小 2 个节点扩展到 32 个节点,增加可用 vCPU 的数量来提供服务请求,可能有助于解决并发瓶颈,并使 QPS 规模达到数千。
分片
我们还观察了当集群和集合基于 _id 进行分片,并且对二进制量化索引执行无过滤查询时会出现的情况。

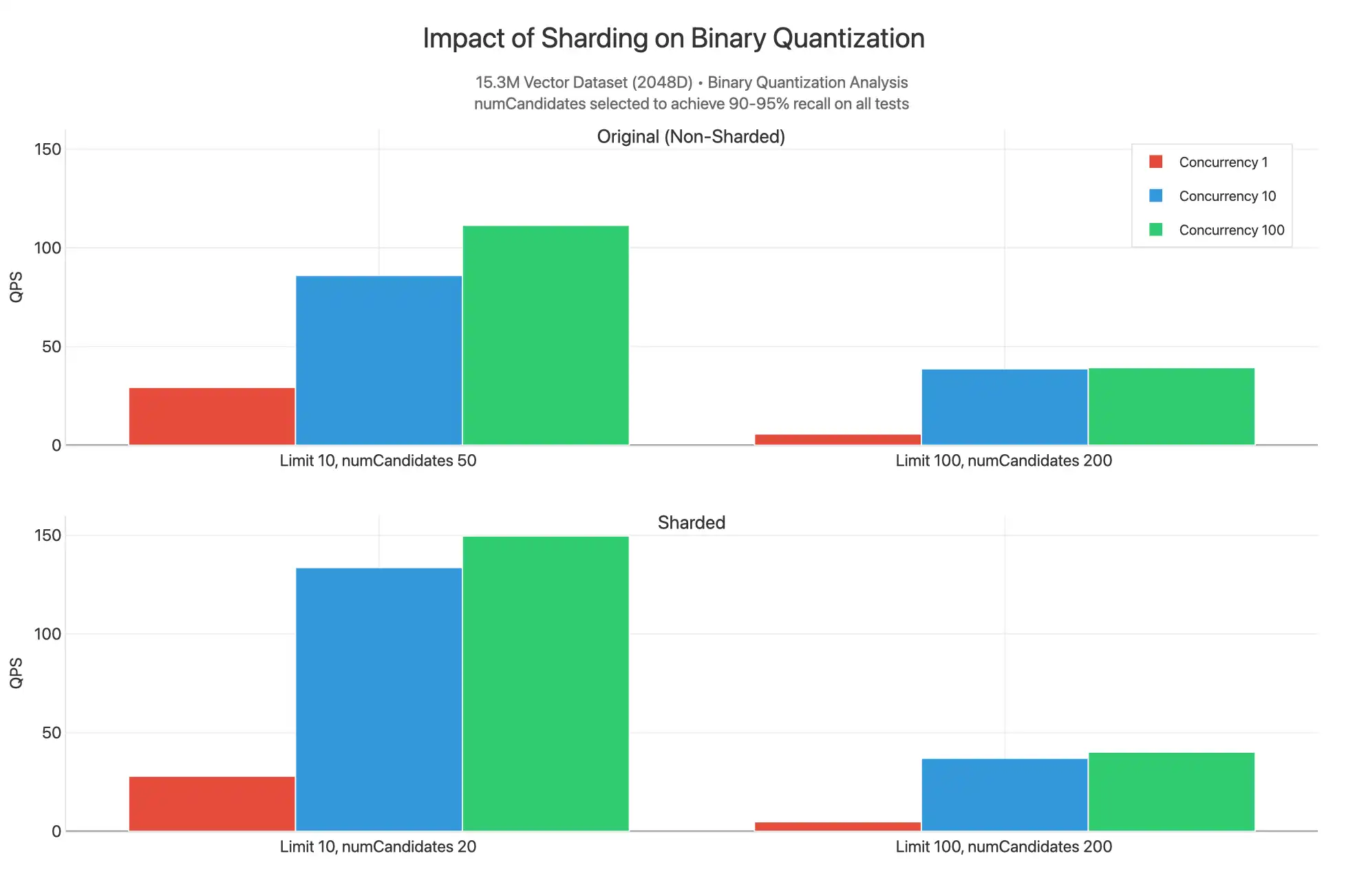
要查看完整图表,请参阅 Claude artifact。
在这里,我们看到分片的结果在限制 10 下具有更高的 QPS,因为可以提供较低的 numCandidates 值来生成 90-95% 召回范围内的结果。这是因为 15.3M 数据集被分割为三个分片,每个分片都有自己的索引,而这些索引填充了分布在包含 HNSW 图的线段上的 5.1M 个向量。我们在功能上进行了不太高级的搜索,同时在 3 分片中收集的每个分散查询更有可能找到最近的 n 向量。出于这个原因,分片QPS 会稍高,因为您可以减少 numCandidates 并有更多内核可用于为查询提供服务,但这种差异并没有那么显着,不足以证明对集群分片所增加的费用是合理的。大多数情况下,您应该出于与操作工作负载相关的原因对集群分片,而不是因为需要扩展向量搜索的吞吐量。
注意
当 limit 为 100、numCandidates 为 200 时,数值相近。我们可能希望使用智能分片键匹配作为过滤器,来处理过滤查询,从而获得更好的性能。