在本教程中,您学习;了解如何评估 RAG应用程序。评估可帮助您选择正确的模型,确保模型的性能从原型转化为生产,并捕获性能回归。
具体来说,您需要执行以下操作:
设置环境。
下载评估数据集。
创建文档段和嵌入。
将嵌入导入到 Atlas 中。
比较用于检索的嵌入模型。
比较生成的完成模型。
测量 RAG 的整体性能。
使用MongoDB Charts跟踪一段时间内的性能。
注意
本教程的重点是评估 LLM 应用程序,而不是 LLM 模型。评估 LLM 模型涉及测量给定模型在不同任务中的性能。 LLM应用程序评估涉及评估 LLM应用程序的不同组件(例如提示和检索器)以及整个系统。
使用本教程的可运行版本以作为 Python 笔记本。
背景
本教程使用 RAGAS 开源评估框架,通过以下指标衡量 RAG 性能:
检索指标:上下文精确度和上下文召回衡量检索器查找相关信息的能力。
生成指标:忠诚度和回答相关性衡量您的法学硕士生成准确、相关答案的程度。
总体指标:答案相似度和回答正确性将生成的答案与参考标准进行比较。
要学习;了解有关这些指标的更多信息,请参阅 RAGAS 文档中的 RAGAS 指标。
本教程使用 Huging Face 中的 ragas-wikiqa 数据集,其中包含大约230 个常识性问题以及真实答案。
先决条件
如要完成本教程,您必须具备以下条件:
运行MongoDB 或更高版本的MongoDB Atlas6.0.11 群集。确保您的IP解决在项目的访问权限列表中。
OpenAI API密钥,用于使用 OpenAI 的嵌入和聊天完成模型。
配置有以下内容的终端:
Python 3.10 或更高版本。
设置环境
下载评估数据集
从 Huugging Face 下载 ragas-wikiqa 数据集并将其转换为 Pandas DataFrame:
from datasets import load_dataset import pandas as pd data = load_dataset("explodinggradients/ragas-wikiqa", split="train") df = pd.DataFrame(data)
数据集包含以下列:
question:用户提问correct_answer:基本事实答案context:用于回答问题的参考文本列表
创建文档数据段
在嵌入之前将参考文本分割成较小的数据段:
from langchain.text_splitter import RecursiveCharacterTextSplitter # Split text by tokens using the tiktoken tokenizer text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( encoding_name="cl100k_base", keep_separator=False, chunk_size=200, chunk_overlap=30 ) def split_texts(texts): chunked_texts = [] for text in texts: chunks = text_splitter.create_documents([text]) chunked_texts.extend([chunk.page_content for chunk in chunks]) return chunked_texts # Split the context field into chunks df["chunks"] = df["context"].apply(lambda x: split_texts(x)) # Aggregate list of all chunks all_chunks = df["chunks"].tolist() docs = [item for chunk in all_chunks for item in chunk]
提示
在评估检索时,尝试不同的分块策略。本教程重点介绍如何评估嵌入模型。
创建嵌入并引入MongoDB Charts
嵌入分块文档并将其摄取到Atlas中。为要比较的每个嵌入模型创建单独的集合:
定义嵌入函数
创建一个函数以使用 OpenAI API生成嵌入:
from typing import List def get_embeddings(docs: List[str], model: str) -> List[List[float]]: """Generate embeddings using the OpenAI API.""" docs = [doc.replace("\n", " ") for doc in docs] response = openai_client.embeddings.create(input=docs, model=model) return [r.embedding for r in response.data]
将嵌入引入Atlas
将分块文档嵌入并摄取到Atlas集合中:
from pymongo import MongoClient from tqdm.auto import tqdm client = MongoClient(MONGODB_URI) DB_NAME = "ragas_evals" db = client[DB_NAME] batch_size = 128 EVAL_EMBEDDING_MODELS = ["text-embedding-ada-002", "text-embedding-3-small"] for model in EVAL_EMBEDDING_MODELS: embedded_docs = [] print(f"Getting embeddings for the {model} model") for i in tqdm(range(0, len(docs), batch_size)): end = min(len(docs), i + batch_size) batch = docs[i:end] batch_embeddings = get_embeddings(batch, model) batch_embedded_docs = [ {"text": batch[i], "embedding": batch_embeddings[i]} for i in range(len(batch)) ] embedded_docs.extend(batch_embedded_docs) collection = db[model] collection.delete_many({}) collection.insert_many(embedded_docs) print(f"Finished inserting embeddings for the {model} model")
创建向量搜索索引
为每个集合创建MongoDB Vector Search索引。使用以下索引定义,索引名称为 vector_index:
{ "fields": [ { "numDimensions": 1536, "path": "embedding", "similarity": "cosine", "type": "vector" } ] }
要学习;了解如何创建索引,请参阅 创建MongoDB Vector Search 索引。
提示
text-embedding-ada-002 和 text-embedding-3-small 都有 1536 维度,因此相同的索引定义适用于这两个集合。
比较嵌入模型
为确保您检索适合法学硕士的上下文,请比较不同的嵌入模型。本教程将比较text-embedding-ada-002 和text-embedding-3-small 。
创建检索器函数
创建一个函数以使用 LangChain 和MongoDB Atlas获取向量存储检索器:
from langchain_openai import OpenAIEmbeddings from langchain_mongodb import MongoDBAtlasVectorSearch from langchain_core.vectorstores import VectorStoreRetriever def get_retriever(model: str, k: int) -> VectorStoreRetriever: """ Get a vector store retriever for a given embedding model. Args: model (str): Embedding model to use k (int): Number of results to retrieve Returns: VectorStoreRetriever: A vector store retriever object """ embeddings = OpenAIEmbeddings(model=model) vector_store = MongoDBAtlasVectorSearch.from_connection_string( connection_string=MONGODB_URI, namespace=f"{DB_NAME}.{model}", embedding=embeddings, index_name="vector_index", text_key="text", ) retriever = vector_store.as_retriever( search_type="similarity", search_kwargs={"k": k} ) return retriever
评估检索器
使用 RAGAS 库中的 context_precision 和 context_recall指标评估每个嵌入模型:
from datasets import Dataset from ragas import evaluate, RunConfig from ragas.metrics import context_precision, context_recall import nest_asyncio # Allow nested use of asyncio (used by RAGAS) nest_asyncio.apply() for model in EVAL_EMBEDDING_MODELS: data = {"question": [], "ground_truth": [], "contexts": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH retriever = get_retriever(model, 2) # Get relevant documents for the evaluation dataset for i in tqdm(range(0, len(QUESTIONS))): data["contexts"].append( [doc.page_content for doc in retriever.invoke(QUESTIONS[i])] ) # RAGAS expects a Dataset object dataset = Dataset.from_dict(data) # RAGAS runtime settings to avoid hitting OpenAI rate limits run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[context_precision, context_recall], run_config=run_config, raise_exceptions=False, ) print(f"Result for the {model} model: {result}")
嵌入模型在示例数据集上的评估结果如下:
模型 | 上下文精度 | 上下文调用 |
|---|---|---|
text-embedding-ada-002 | 0.9310 | 0.8561 |
text-embedding-3-small | 0.9116 | 0.8826 |
根据这些结果,text-embedding-ada-002 会将最相关的结果排名靠前,但 text-embedding-3-small 会检索到更符合参考标准答案的上下文。在本教程中,使用 text-embedding-3-small 作为嵌入模型。
比较完井模型
现在您已经选择了最佳嵌入模型,请比较 RAG应用程序生成组件的完成模型。
创建 RAG 链
创建一个使用 LangChain 构建 RAG 链的函数:
from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_core.runnables.base import RunnableSequence from langchain_core.output_parsers import StrOutputParser def get_rag_chain(retriever: VectorStoreRetriever, model: str) -> RunnableSequence: """ Create a basic RAG chain. Args: retriever (VectorStoreRetriever): Vector store retriever object model (str): Chat completion model to use Returns: RunnableSequence: A RAG chain """ # Generate context using the retriever, and pass the user question through retrieve = { "context": retriever | (lambda docs: "\n\n".join([d.page_content for d in docs])), "question": RunnablePassthrough(), } template = """Answer the question based only on the following context: \ {context} Question: {question} """ # Define the chat prompt prompt = ChatPromptTemplate.from_template(template) # Define the model for chat completion llm = ChatOpenAI(temperature=0, model=model) # Parse output as a string parse_output = StrOutputParser() # RAG chain rag_chain = retrieve | prompt | llm | parse_output return rag_chain
评估完井模型
使用 faithfulness 和 answer_relevancy指标评估不同的完成模型:
from ragas.metrics import faithfulness, answer_relevancy for model in ["gpt-3.5-turbo-1106", "gpt-3.5-turbo"]: data = {"question": [], "ground_truth": [], "contexts": [], "answer": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH # Use the best embedding model from the retriever evaluation retriever = get_retriever("text-embedding-3-small", 2) rag_chain = get_rag_chain(retriever, model) for i in tqdm(range(0, len(QUESTIONS))): question = QUESTIONS[i] data["answer"].append(rag_chain.invoke(question)) data["contexts"].append( [doc.page_content for doc in retriever.invoke(question)] ) # RAGAS expects a Dataset object dataset = Dataset.from_dict(data) # RAGAS runtime settings to avoid hitting OpenAI rate limits run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[faithfulness, answer_relevancy], run_config=run_config, raise_exceptions=False, ) print(f"Result for the {model} model: {result}")
补全模型在示例数据集上的评估结果如下:
模型 | 忠诚度 | 答案相关性 |
|---|---|---|
gpt-3.5-turbo | 0.9714 | 0.9087 |
gpt-3.5-turbo-1106 | 0.9671 | 0.9105 |
根据这些结果,最新的 gpt-3.5-turbo 会生成更一致事实的结果,而旧版本会生成与给定提示更相关的答案。在本教程中,使用 gpt-3.5-turbo 作为补全模型。
衡量整体性能
使用性能最佳的模型评估 RAG应用程序的整体性能:
from ragas.metrics import answer_similarity, answer_correctness data = {"question": [], "ground_truth": [], "answer": []} data["question"] = QUESTIONS data["ground_truth"] = GROUND_TRUTH # Use the best embedding model from the retriever evaluation retriever = get_retriever("text-embedding-3-small", 2) # Use the best completion model from the generator evaluation rag_chain = get_rag_chain(retriever, "gpt-3.5-turbo") for question in tqdm(QUESTIONS): data["answer"].append(rag_chain.invoke(question)) dataset = Dataset.from_dict(data) run_config = RunConfig(max_workers=4, max_wait=180) result = evaluate( dataset=dataset, metrics=[answer_similarity, answer_correctness], run_config=run_config, raise_exceptions=False, ) print(f"Overall metrics: {result}")
此评估显示,RAG 链在示例数据集上产生的回答相似度为 ,回答正确性为0.8873 0.5922。
分析结果
要进一步调查结果,请将其转换为 Pandas 数据框并过滤低分答案:
result_df = result.to_pandas() result_df[result_df["answer_correctness"] < 0.7]
对于可视化分析,创建问题与指标的热图:
import seaborn as sns import matplotlib.pyplot as plt plt.figure(figsize=(10, 8)) sns.heatmap( result_df[1:10].set_index("question")[["answer_similarity", "answer_correctness"]], annot=True, cmap="flare", ) plt.show()
前面的代码输出以下热图:

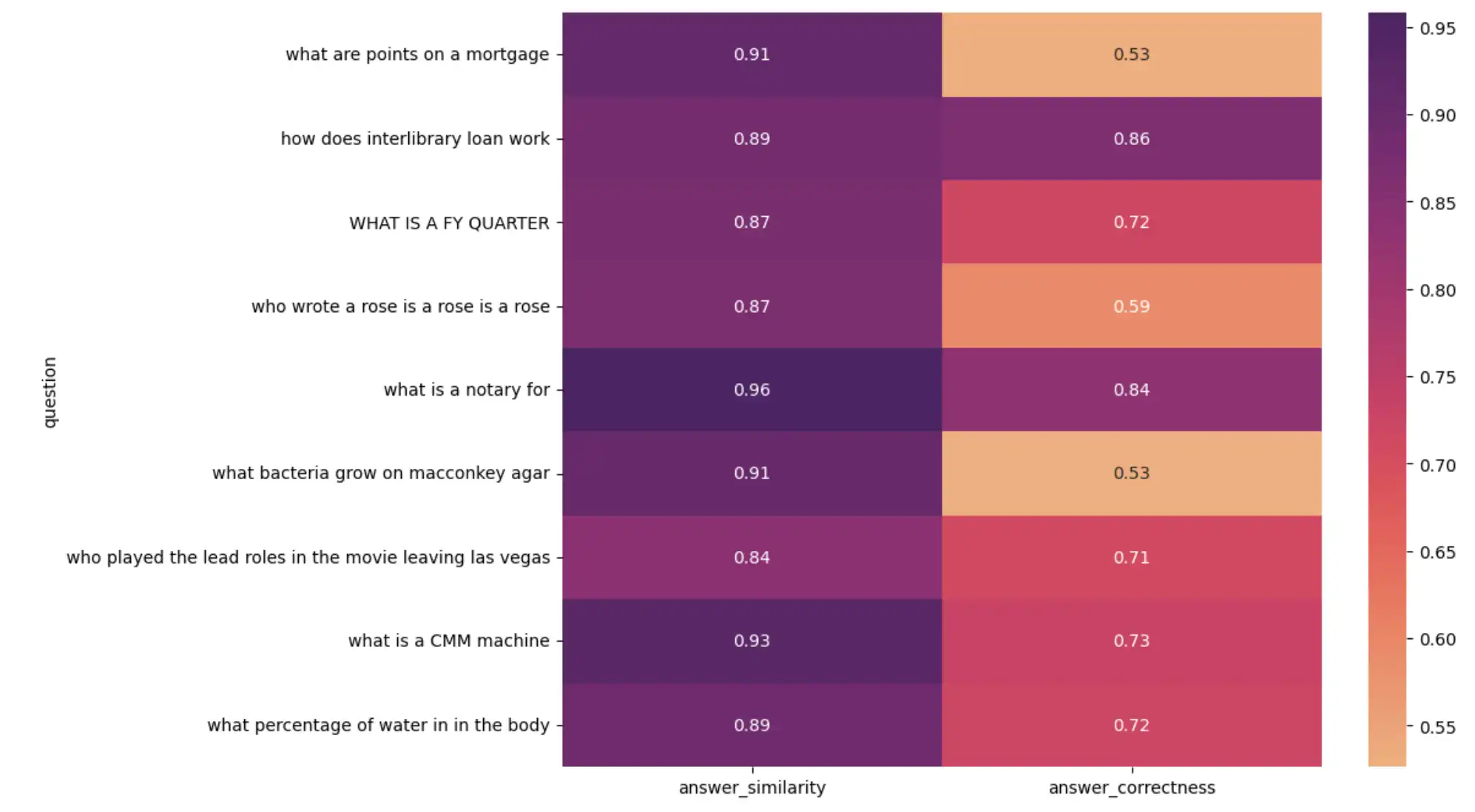
可视化 RAG应用程序性能的热图
在调查低分结果时,您可能会发现:
评估数据集中的某些参考标准答案不正确。尽管法学硕士生成的回答是正确的,但它与事实真相不符,导致分数较低。
一些真实答案是完整的句子,而法学硕士生成的回答是单个单词或数字。
这些发现强调了抽查法学硕士评估和整理准确评估数据集的重要性。
追踪一段时间内的表现
评估不应该是一次性事件。每次更改系统中的组件时,请评估这些更改以评估它们影响性能的影响。一旦您的应用程序投入生产,实时监控性能并检测更改。
使用Charts监控LLM应用程序的表现。将评估结果和要追踪的任何反馈指标写入Atlas集合:
from datetime import datetime result["timestamp"] = datetime.now() collection = db["metrics"] collection.insert_one(result)
此代码将 timestamp字段添加到评估结果中,并将其写入 ragas_evals数据库中的 metrics集合。 Atlas中的文档如下所示:
{ "answer_similarity": 0.8873, "answer_correctness": 0.5922, "timestamp": "2024-04-07T23:27:30.655+00:00" }
在MongoDB Charts中创建仪表盘,可视化您的指标随时间的变化。要学习;了解如何创建图表和仪表盘,请参阅构建Charts。
总结
在本教程中,您学习了如何使用 RAGAS框架和MongoDB Atlas评估 RAG应用程序。您比较了用于检索的嵌入模型、用于生成的完成模型,并测量了应用程序的整体性能。您还学习了如何使用MongoDB Charts追踪一段时间内的性能。
要学习;了解有关使用MongoDB构建 RAG 应用程序的更多信息,请参阅以下资源: