Os aplicativos de AI podem começar devagar em termos de exigências de computação, dados e finanças. À medida que os aplicativos de produção crescem devido ao aumento do engajamento dos usuários, fatores-chave como o custo associado ao armazenar e recuperar grandes volumes de dados se tornam oportunidades críticas de otimização. Esses desafios podem ser resolvidos com foco em:
Algoritmos eficientes de pesquisa vetorial
Processos de quantização automatizados
Estratégias de incorporação otimizadas
Tanto a geração aumentada de recuperação (RAG) quanto os sistemas baseados em agentes dependem de dados vetoriais – representações numéricas de objetos de dados como imagens, vídeos e texto – para realizar buscas por similaridade semântica. Sistemas que utilizam RAG ou fluxos de trabalho orientados por agentes devem lidar eficientemente com conjuntos de dados massivos e de alta dimensão para manter tempos de resposta rápidos, minimizar a latência e controlar os custos de infraestrutura.
Sobre o tutorial
Este tutorial ensina as técnicas necessárias para projetar, implantar e gerenciar cargas de trabalho avançadas de IA em grande escala, garantindo desempenho ótimo e eficiência de custos.
Especificamente, neste tutorial, você aprenderá como:
Gerar incorporações usando o
voyage-3-largeda Voyage AI, um modelo de incorporações multilíngue de uso geral sensível à quantização, e inseri-las em um banco de dados do MongoDB.Quantize automaticamente as incorporações para tipos de dados de menor precisão, otimizando tanto o uso de memória quanto a latência da query.
Execute uma consulta que compare incorporações float32, int8 e binários ao ponderar a precisão do tipo de dados em relação à eficiência e precisão de recuperação.
Medir o recall (também chamado de retenção) das incorporações quantizadas, que avalia a eficácia com que a pesquisa quantizada ANN recupera os mesmos documentos que uma pesquisa ENN de precisão total.
Observação
A quantização binária é ideal para cenários que exigem consumo reduzido de recursos, mas talvez exija um passo de reavaliação para corrigir possíveis perdas de precisão.
A quantização escalar oferece um meio termo prático, adequado para a maioria dos casos de uso que precisam equilibrar desempenho e precisão.
O Float32 garante a máxima fidelidade, mas apresenta a maior sobrecarga de desempenho e memória, tornando-o menos ideal para sistemas de grande escala ou sensíveis à latência.
Pré-requisitos
Para concluir este tutorial, você deve ter o seguinte:
Procedimento
Importe as bibliotecas necessárias e defina as variáveis de ambiente.
Crie um notebook Python interativo salvando um arquivo com a extensão
.ipynb.Instale as bibliotecas.
Para este tutorial, você deve importar as seguintes bibliotecas:
pymongo
Driver MongoDB Python para se conectar ao seu cluster, criar índices e executar query.
voyageai
Cliente Python da Voyage AI para gerar as incorporações para os dados.
pandas
Ferramenta de manipulação e análise de dados para carregar os dados e prepará-los para a pesquisa vetorial.
conjuntos de dados
Biblioteca Hugging Face, que fornece acesso a conjuntos de dados prontos.
matplotlib
Biblioteca de plotagem e visualização para visualizar os dados.
Para instalar as bibliotecas, execute o seguinte:
pip install --quiet -U pymongo voyageai pandas datasets matplotlib Obtenha e defina variáveis de ambiente com segurança.
A seguinte função assistente do
set_env_securelyobtém e define variáveis de ambiente com segurança. Copie, cole e execute o código a seguir e, quando solicitado, defina valores secretos, como sua chave de API do Voyage AI e sua string de conexão do cluster.1 import getpass 2 import os 3 import voyageai 4 5 # Function to securely get and set environment variables 6 def set_env_securely(var_name, prompt): 7 value = getpass.getpass(prompt) 8 os.environ[var_name] = value 9 10 # Environment Variables 11 set_env_securely("VOYAGE_API_KEY", "Enter your Voyage API Key: ") 12 set_env_securely("MONGO_URI", "Enter your MongoDB URI: ") 13 MONGO_URI = os.environ.get("MONGO_URI") 14 if not MONGO_URI: 15 raise ValueError("MONGO_URI not set in environment variables.") 16 17 # Voyage Client 18 voyage_client = voyageai.Client()
Faça a ingestão dos dados em seu cluster.
Nesta etapa, você carrega até 250000 documentos dos seguintes conjuntos de dados:
O conjunto de dados wikipedia-22-12-en-voyage-embed contém fragmentos de artigos da Wikipedia com incorporações float32 de 1024 dimensões pré-gerados a partir do modelo voyage-3-large da Voyage AI. Essa é a coleção primária de documentos com metadados. Essa conjunto de dados servirá como um corpus vetorial diversificado para testar os efeitos da quantização vetorial na pesquisa semântica. Cada documento desse conjunto de dados contém os seguintes campos:
| O ObjectId ( |
| O identificador exclusivo do documento. |
| O título do documento. |
| O texto do documento. |
| O URL do documento. |
| O ID da Wikipedia do documento. |
| O número de visualizações do documento. |
| O ID do parágrafo no documento. |
| O número de idiomas no documento. |
| As 1024 incorporações vetoriais dimensionais do documento. |
O conjunto de dados wikipedia-22-12-en-annotation contém os dados de referência anotados para a função de medição de recall. Esses dados são usados como conjunto de dados de referência para validação de precisão e para avaliar o impacto da quantização na qualidade da recuperação. Cada documento desse conjunto de dados contém os seguintes campos, que são a referência usada para avaliar o desempenho da pesquisa vetorial:
| O ObjectId ( |
| O identificador exclusivo do documento. |
| O ID da Wikipedia do documento. |
| As queries que contêm as frases-chave, perguntas, informações parciais e sentenças para o documento. |
| O array de frases-chave utilizadas para avaliar o desempenho da pesquisa vetorial do documento. |
| O array de informações parciais usado para avaliar o desempenho da pesquisa vetorial do documento. |
| O array de perguntas usadas para avaliar o desempenho da pesquisa vetorial do documento. |
| O array de frases que são usadas para avaliar o desempenho da pesquisa vetorial para o documento. |
Defina as funções para carregar os dados em seu cluster.
Copie, cole e execute o seguinte código no seu notebook. O código de exemplo define as seguintes funções:
generate_bson_vectorpara converter as incorporações no conjunto de dados em vetores binários BSON para armazenamento e processamento eficientes de seus vetores.get_mongo_clientpara obter a string de conexão do cluster.insert_dataframe_into_collectionpara consumir dados no cluster.
1 import pandas as pd 2 from datasets import load_dataset 3 from bson.binary import Binary, BinaryVectorDtype 4 import pymongo 5 6 # Connect to Cluster 7 def get_mongo_client(uri): 8 """Connect to MongoDB and confirm the connection.""" 9 client = pymongo.MongoClient(uri) 10 if client.admin.command("ping").get("ok") == 1.0: 11 print("Connected to MongoDB successfully.") 12 return client 13 print("Failed to connect to MongoDB.") 14 return None 15 16 # Generate BSON Vector 17 def generate_bson_vector(array, data_type): 18 """Convert an array to BSON vector format.""" 19 array = [float(val) for val in eval(array)] 20 return Binary.from_vector(array, BinaryVectorDtype(data_type)) 21 22 # Load Datasets 23 def load_and_prepare_data(dataset_name, amount): 24 """Load and prepare streaming datasets for DataFrame.""" 25 data = load_dataset(dataset_name, streaming=True, split="train").take(amount) 26 return pd.DataFrame(data) 27 28 # Insert datasets into MongoDB Collection 29 def insert_dataframe_into_collection(df, collection): 30 """Insert Dataset records into MongoDB collection.""" 31 collection.insert_many(df.to_dict("records")) 32 print(f"Inserted {len(df)} records into '{collection.name}' collection.") Carregue os dados em seu cluster.
Copie, cole e execute o seguinte código em seu bloco de anotações para carregar o conjunto de dados em seu cluster. Este código executa as seguintes ações:
Busca os conjuntos de dados.
Converte as incorporações para o formato BSON.
Cria coleções em seu cluster e insere os dados.
1 import pandas as pd 2 from bson.binary import Binary, BinaryVectorDtype 3 from pymongo.errors import CollectionInvalid 4 5 wikipedia_data_df = load_and_prepare_data("MongoDB/wikipedia-22-12-en-voyage-embed", amount=250000) 6 wikipedia_annotation_data_df = load_and_prepare_data("MongoDB/wikipedia-22-12-en-annotation", amount=250000) 7 wikipedia_annotation_data_df.drop(columns=["_id"], inplace=True) 8 9 # Convert embeddings to BSON format 10 wikipedia_data_df["embedding"] = wikipedia_data_df["embedding"].apply( 11 lambda x: generate_bson_vector(x, BinaryVectorDtype.FLOAT32) 12 ) 13 14 # MongoDB Setup 15 mongo_client = get_mongo_client(MONGO_URI) 16 DB_NAME = "testing_datasets" 17 db = mongo_client[DB_NAME] 18 19 collections = { 20 "wikipedia-22-12-en": wikipedia_data_df, 21 "wikipedia-22-12-en-annotation": wikipedia_annotation_data_df, 22 } 23 24 # Create Collections and Insert Data 25 for collection_name, df in collections.items(): 26 if collection_name not in db.list_collection_names(): 27 try: 28 db.create_collection(collection_name) 29 print(f"Collection '{collection_name}' created successfully.") 30 except CollectionInvalid: 31 print(f"Error creating collection '{collection_name}'.") 32 else: 33 print(f"Collection '{collection_name}' already exists.") 34 35 # Clear collection and insert fresh data 36 collection = db[collection_name] 37 collection.delete_many({}) 38 insert_dataframe_into_collection(df, collection) Connected to MongoDB successfully. Collection 'wikipedia-22-12-en' created successfully. Inserted 250000 records into 'wikipedia-22-12-en' collection. Collection 'wikipedia-22-12-en-annotation' created successfully. Inserted 87200 records into 'wikipedia-22-12-en-annotation' collection. IMPORTANTE: pode levar algum tempo para converter incorporações em vetores BSON e consumir os conjuntos de dados em seu cluster.
Verifique se os conjuntos de dados foram carregados com êxito fazendo login em seu cluster e inspecionando visualmente as collections no Data Explorer.
Criar índices de Vector Search do MongoDB na collection.
Nesta etapa, você cria os seguintes três índices no campo embedding:
Índice Quantizado Escalar | Para utilizar o método de quantização escalar para quantizar incorporações. |
Índice quantizado binário | Para utilizar o método de quantização binária para quantizar as incorporações. |
Float32 ANN Index | Para usar o método float32 ANN para quantizar as incorporações. |
Defina a função para criar o índice do MongoDB Vector Search .
Copie, cole e execute o seguinte no seu notebook:
1 import time 2 from pymongo.operations import SearchIndexModel 3 4 def setup_vector_search_index(collection, index_definition, index_name="vector_index"): 5 new_vector_search_index_model = SearchIndexModel( 6 definition=index_definition, name=index_name, type="vectorSearch" 7 ) 8 9 # Create the new index 10 try: 11 result = collection.create_search_index(model=new_vector_search_index_model) 12 print(f"Creating index '{index_name}'...") 13 14 # Wait for initial sync to complete 15 print("Polling to check if the index is ready. This may take a couple of minutes.") 16 predicate=None 17 if predicate is None: 18 predicate = lambda index: index.get("queryable") is True 19 while True: 20 indices = list(collection.list_search_indexes(result)) 21 if len(indices) and predicate(indices[0]): 22 break 23 time.sleep(5) 24 print(f"Index '{index_name}' is ready for querying.") 25 return result 26 27 except Exception as e: 28 print(f"Error creating new vector search index '{index_name}': {e!s}") 29 return None Defina os índices.
As seguintes configurações de índice implementam uma estratégia de quantização diferente:
vector_index_definition_scalar_quantizedEsta configuração utiliza quantização escalar (int8), que:
Reduz cada dimensão de vetor float de 32 bits para um inteiro de 8 bits
Mantém um bom equilíbrio entre precisão e eficiência de memória
É adequado para a maioria dos casos de uso em produção em que a otimização de memória é necessária.
vector_index_definition_binary_quantizedEssa configuração usa quantização binária (int1), que:
Reduz cada dimensão do vetor a um único bit
Oferece a máxima eficiência de memória
É ideal para implantações em larga escala em que as restrições de memória são críticas
A quantização automática acontece de forma transparente quando esses índices são criados, com o MongoDB Vector Search lidando com a conversão de float32 para o formato quantizado especificado durante a criação do índice e as operações de pesquisa.
A configuração do índice
vector_index_definition_float32_annindexa vetores de alta fidelidade de1024dimensões usando a função de similaridadecosine.1 # Scalar Quantization 2 vector_index_definition_scalar_quantized = { 3 "fields": [ 4 { 5 "type": "vector", 6 "path": "embedding", 7 "quantization": "scalar", 8 "numDimensions": 1024, 9 "similarity": "cosine", 10 } 11 ] 12 } 13 # Binary Quantization 14 vector_index_definition_binary_quantized = { 15 "fields": [ 16 { 17 "type": "vector", 18 "path": "embedding", 19 "quantization": "binary", 20 "numDimensions": 1024, 21 "similarity": "cosine", 22 } 23 ] 24 } 25 # Float32 Embeddings 26 vector_index_definition_float32_ann = { 27 "fields": [ 28 { 29 "type": "vector", 30 "path": "embedding", 31 "numDimensions": 1024, 32 "similarity": "cosine", 33 } 34 ] 35 } Crie os índices escalares, binários e float32 usando a função
setup_vector_search_index.Defina os nomes da coleção e dos índices para os índices.
wiki_data_collection = db["wikipedia-22-12-en"] wiki_annotation_data_collection = db["wikipedia-22-12-en-annotation"] vector_search_scalar_quantized_index_name = "vector_index_scalar_quantized" vector_search_binary_quantized_index_name = "vector_index_binary_quantized" vector_search_float32_ann_index_name = "vector_index_float32_ann" Crie os índices do MongoDB Vector Search .
1 setup_vector_search_index( 2 wiki_data_collection, 3 vector_index_definition_scalar_quantized, 4 vector_search_scalar_quantized_index_name, 5 ) 6 setup_vector_search_index( 7 wiki_data_collection, 8 vector_index_definition_binary_quantized, 9 vector_search_binary_quantized_index_name, 10 ) 11 setup_vector_search_index( 12 wiki_data_collection, 13 vector_index_definition_float32_ann, 14 vector_search_float32_ann_index_name, 15 ) Creating index 'vector_index_scalar_quantized'... Polling to check if the index is ready. This may take a couple of minutes. Index 'vector_index_scalar_quantized' is ready for querying. Creating index 'vector_index_binary_quantized'... Polling to check if the index is ready. This may take a couple of minutes. Index 'vector_index_binary_quantized' is ready for querying. Creating index 'vector_index_float32_ann'... Polling to check if the index is ready. This may take a couple of minutes. Index 'vector_index_float32_ann' is ready for querying. vector_index_float32_ann' IMPORTANTE: a operação pode levar alguns minutos para ser concluída. Os índices devem estar no estado Ready para serem utilizados em queries.
Verifique se a criação do índice foi bem-sucedida fazendo login em seu cluster e inspecionando visualmente os índices no Atlas Search.
Defina as funções para gerar embeddings e consultar uma collection usando os índices do MongoDB Vector Search .
Este código define as seguintes funções:
A função
get_embedding()gera 1024 incorporações de dimensão para o texto fornecido usando o modelo de incorporaçãovoyage-3-largeda Voyage AI.A função
custom_vector_searchrecebe os seguintes parâmetros de entrada e retorna os resultados da operação de pesquisa vetorial.user_queryConsulte a string de texto para a qual gerar incorporações.
collectionColeção MongoDB a ser pesquisada.
embedding_pathCampo na coleção que contém as incorporações.
vector_search_index_nameNome do índice a ser utilizado na query.
top_kNúmero de documentos principais nos resultados a serem retornados.
num_candidatesNúmero de candidatos a considerar.
use_full_precisionSinalizador para executar pesquisa ANN, se
False, ou ENN, seTrue.O valor
use_full_precisioné configurado comoFalsepor padrão para uma pesquisa ANN. Defina o valoruse_full_precisioncomoTruepara executar uma pesquisa ENN.Especificamente, esta função executa as seguintes ações:
Gera as incorporações para o texto da query
Constrói o estágio
$vectorSearchConfigura o tipo de pesquisa
Especifica os campos na coleção a serem retornados
Executa o pipeline após coletar estatísticas de desempenho
Retorna os resultados
1 def get_embedding(text, task_prefix="document"): 2 """Fetch embedding for a given text using Voyage AI.""" 3 if not text.strip(): 4 print("Empty text provided for embedding.") 5 return [] 6 result = voyage_client.embed([text], model="voyage-3-large", input_type=task_prefix) 7 return result.embeddings[0] 8 9 def custom_vector_search( 10 user_query, 11 collection, 12 embedding_path, 13 vector_search_index_name="vector_index", 14 top_k=5, 15 num_candidates=25, 16 use_full_precision=False, 17 ): 18 19 # Generate embedding for the user query 20 query_embedding = get_embedding(user_query, task_prefix="query") 21 22 if query_embedding is None: 23 return "Invalid query or embedding generation failed." 24 25 # Define the vector search stage 26 vector_search_stage = { 27 "$vectorSearch": { 28 "index": vector_search_index_name, 29 "queryVector": query_embedding, 30 "path": embedding_path, 31 "limit": top_k, 32 } 33 } 34 35 # Add numCandidates only for approximate search 36 if not use_full_precision: 37 vector_search_stage["$vectorSearch"]["numCandidates"] = num_candidates 38 else: 39 # Set exact to true for exact search using full precision float32 vectors and running exact search 40 vector_search_stage["$vectorSearch"]["exact"] = True 41 42 project_stage = { 43 "$project": { 44 "_id": 0, 45 "title": 1, 46 "text": 1, 47 "wiki_id": 1, 48 "url": 1, 49 "score": { 50 "$meta": "vectorSearchScore" 51 }, 52 } 53 } 54 55 # Define the aggregate pipeline with the vector search stage and additional stages 56 pipeline = [vector_search_stage, project_stage] 57 58 # Execute the explain command 59 explain_result = collection.database.command( 60 "explain", 61 {"aggregate": collection.name, "pipeline": pipeline, "cursor": {}}, 62 verbosity="executionStats", 63 ) 64 65 # Extract the execution time 66 vector_search_explain = explain_result["stages"][0]["$vectorSearch"] 67 execution_time_ms = vector_search_explain["explain"]["query"]["stats"]["context"][ 68 "millisElapsed" 69 ] 70 71 # Execute the actual query 72 results = list(collection.aggregate(pipeline)) 73 74 return {"results": results, "execution_time_ms": execution_time_ms}
Execute uma query do MongoDB Vector Search para avaliar o desempenho da pesquisa.
A seguinte query realiza pesquisas vetoriais em diferentes estratégias de quantização, avaliando métricas de desempenho para vetores quantizados escalares, quantizados binários e de precisão total (float32), enquanto registra medições de latência em cada nível de precisão e padroniza o formato dos resultados para comparação analítica. Ela usa incorporações geradas pela Voyage AI para a string da query "Como posso aumentar minha produtividade para obter o máximo de rendimento".
A query armazena indicadores-chave de desempenho essenciais na variável results, incluindo nível de precisão (escalar, binário, float32), tamanho do conjunto de resultados (top_k), latência da consulta em milissegundos e conteúdo do documento recuperado, fornecendo métricas abrangentes para avaliar o desempenho da pesquisa em diferentes estratégias de quantização.
1 vector_search_indices = [ 2 vector_search_float32_ann_index_name, 3 vector_search_scalar_quantized_index_name, 4 vector_search_binary_quantized_index_name, 5 ] 6 7 # Random query 8 user_query = "How do I increase my productivity for maximum output" 9 test_top_k = 5 10 test_num_candidates = 25 11 12 # Result is a list of dictionaries with the following headings: precision, top_k, latency_ms, results 13 results = [] 14 15 for vector_search_index in vector_search_indices: 16 # Conduct a vector search operation using scalar quantized 17 vector_search_results = custom_vector_search( 18 user_query, 19 wiki_data_collection, 20 embedding_path="embedding", 21 vector_search_index_name=vector_search_index, 22 top_k=test_top_k, 23 num_candidates=test_num_candidates, 24 use_full_precision=False, 25 ) 26 # Include the precision in the results 27 precision = vector_search_index.split("vector_index")[1] 28 precision = precision.replace("quantized", "").capitalize() 29 30 results.append( 31 { 32 "precision": precision, 33 "top_k": test_top_k, 34 "num_candidates": test_num_candidates, 35 "latency_ms": vector_search_results["execution_time_ms"], 36 "results": vector_search_results["results"][0], # Just taking the first result, modify this to include more results if needed 37 } 38 ) 39 40 # Conduct a vector search operation using full precision 41 precision = "Float32_ENN" 42 vector_search_results = custom_vector_search( 43 user_query, 44 wiki_data_collection, 45 embedding_path="embedding", 46 vector_search_index_name="vector_index_scalar_quantized", 47 top_k=test_top_k, 48 num_candidates=test_num_candidates, 49 use_full_precision=True, 50 ) 51 52 results.append( 53 { 54 "precision": precision, 55 "top_k": test_top_k, 56 "num_candidates": test_num_candidates, 57 "latency_ms": vector_search_results["execution_time_ms"], 58 "results": vector_search_results["results"][0], # Just taking the first result, modify this to include more results if needed 59 } 60 ) 61 62 # Convert the results to a pandas DataFrame with the headings: precision, top_k, latency_ms 63 results_df = pd.DataFrame(results) 64 results_df.columns = ["precision", "top_k", "num_candidates", "latency_ms", "results"] 65 66 # To display the results: 67 results_df.head()
precision top_k num_candidates latency_ms results 0 _float32_ann 5 25 1659.498601 {'title': 'Henry Ford', 'text': 'Ford had deci... 1 _scalar_ 5 25 951.537687 {'title': 'Gross domestic product', 'text': 'F... 2 _binary_ 5 25 344.585193 {'title': 'Great Depression', 'text': 'The fir... 3 Float32_ENN 5 25 0.231693 {'title': 'Great Depression', 'text': 'The fir...
As métricas de desempenho nos resultados indicam diferenças de latência entre os níveis de precisão. Isso demonstra que, embora a quantização ofereça melhorias substanciais no desempenho, há uma compensação evidente entre precisão e velocidade de recuperação, com operações float32 de precisão total exigindo significativamente mais tempo computacional em comparação com suas contrapartes quantizadas.
Meça a latência variando os valores top-k e num_candidates.
A seguinte query introduz uma estrutura sistemática de medição de latência que avalia o desempenho da pesquisa vetorial em diferentes níveis de precisão e escalas de recuperação. O parâmetro top-k não apenas determina o número de resultados a serem retornados, mas também define o parâmetro numCandidates na pesquisa de grafo HNSW do MongoDB.
O valor do numCandidates influencia quantos nós no grafo HNSW o MongoDB Vector Search explora durante a pesquisa ANN. Aqui, um valor mais alto aumenta a probabilidade de encontrar os verdadeiros vizinhos mais próximos, mas requer mais tempo de computação.
Defina a função para formatar
latency_msem um formato legível por humanos.1 from datetime import timedelta 2 3 def format_time(ms): 4 """Convert milliseconds to a human-readable format""" 5 delta = timedelta(milliseconds=ms) 6 7 # Extract minutes, seconds, and milliseconds with more precision 8 minutes = delta.seconds // 60 9 seconds = delta.seconds % 60 10 milliseconds = round(ms % 1000, 3) # Keep 3 decimal places for milliseconds 11 12 # Format based on duration 13 if minutes > 0: 14 return f"{minutes}m {seconds}.{milliseconds:03.0f}s" 15 elif seconds > 0: 16 return f"{seconds}.{milliseconds:03.0f}s" 17 else: 18 return f"{milliseconds:.3f}ms" Defina a função para medir a latência da query de pesquisa vetorial.
A função a seguir recebe um
user_query, umcollection, umvector_search_index_name, um valoruse_full_precision, um valortop_k_valuese um valornum_candidates_valuescomo entrada e retorna os resultados da pesquisa vetorial. Aqui anote o seguinte:A latência aumenta conforme os valores
top_kenum_candidatesaumentam, porque a operação de pesquisa vetorial utiliza um número maior de documentos, o que faz com que a pesquisa demore mais.A latência é maior para a pesquisa de fidelidade total (
use_full_precision=True) do que para a pesquisa aproximada (use_full_precision=False) porque a pesquisa de fidelidade total leva mais tempo do que a pesquisa aproximada, já que examina todo o conjunto de dados usando vetores float32 de precisão total.A latência da pesquisa quantizada é inferior à da pesquisa com fidelidade total, pois a pesquisa quantizada utiliza a busca aproximada e os vetores quantizados.
1 def measure_latency_with_varying_topk( 2 user_query, 3 collection, 4 vector_search_index_name="vector_index_scalar_quantized", 5 use_full_precision=False, 6 top_k_values=[5, 10, 100], 7 num_candidates_values=[25, 50, 100, 200, 500, 1000, 2000, 5000, 10000], 8 ): 9 results_data = [] 10 11 # Conduct vector search operation for each (top_k, num_candidates) combination 12 for top_k in top_k_values: 13 for num_candidates in num_candidates_values: 14 # Skip scenarios where num_candidates < top_k 15 if num_candidates < top_k: 16 continue 17 18 # Construct the precision name 19 precision_name = vector_search_index_name.split("vector_index")[1] 20 precision_name = precision_name.replace("quantized", "").capitalize() 21 22 # If use_full_precision is true, then the precision name is "_float32_" 23 if use_full_precision: 24 precision_name = "_float32_ENN" 25 26 # Perform the vector search 27 vector_search_results = custom_vector_search( 28 user_query=user_query, 29 collection=collection, 30 embedding_path="embedding", 31 vector_search_index_name=vector_search_index_name, 32 top_k=top_k, 33 num_candidates=num_candidates, 34 use_full_precision=use_full_precision, 35 ) 36 37 # Extract the execution time (latency) 38 latency_ms = vector_search_results["execution_time_ms"] 39 40 # Store results 41 results_data.append( 42 { 43 "precision": precision_name, 44 "top_k": top_k, 45 "num_candidates": num_candidates, 46 "latency_ms": latency_ms, 47 } 48 ) 49 50 return results_data Execute a query do MongoDB Vector Search para medir a latência.
A operação de avaliação de latência realiza uma análise de desempenho abrangente executando pesquisas em todas as estratégias de quantização, testando vários tamanhos de conjunto de resultados, capturando métricas de desempenho padronizadas e agregando resultados para análise comparativa. Isso permite uma avaliação detalhada do comportamento da pesquisa vetorial em diferentes configurações e cargas de recuperação.
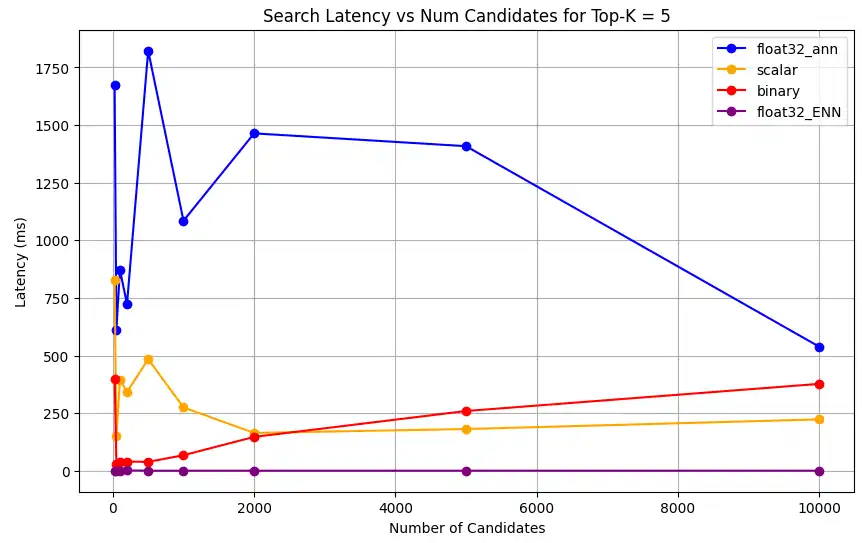
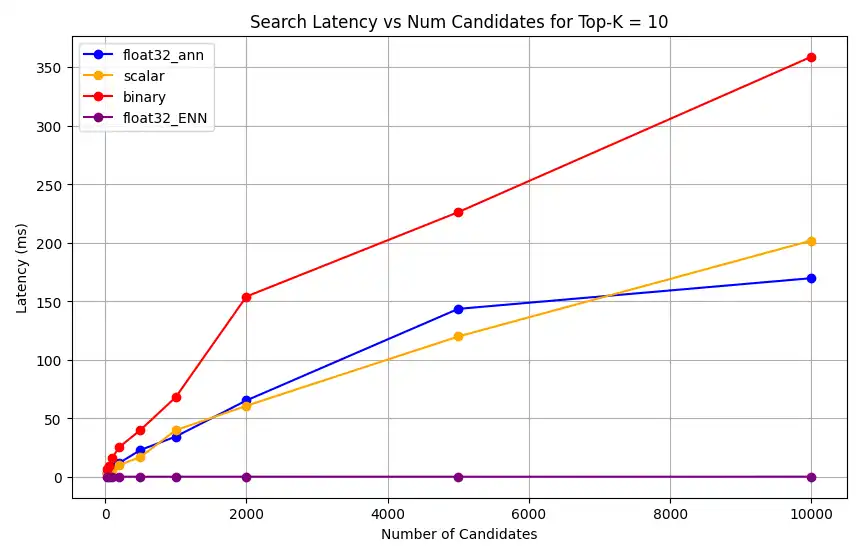
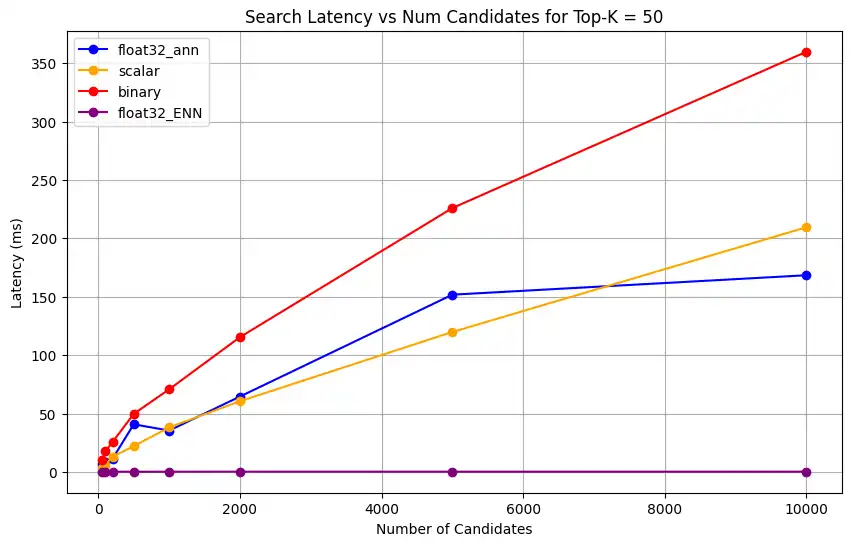
1 # Run the measurements 2 user_query = "How do I increase my productivity for maximum output" 3 top_k_values = [5, 10, 50, 100] 4 num_candidates_values = [25, 50, 100, 200, 500, 1000, 2000, 5000, 10000] 5 6 latency_results = [] 7 8 for vector_search_index in vector_search_indices: 9 latency_results.append( 10 measure_latency_with_varying_topk( 11 user_query, 12 wiki_data_collection, 13 vector_search_index_name=vector_search_index, 14 use_full_precision=False, 15 top_k_values=top_k_values, 16 num_candidates_values=num_candidates_values, 17 ) 18 ) 19 20 # Conduct vector search operation using full precision 21 latency_results.append( 22 measure_latency_with_varying_topk( 23 user_query, 24 wiki_data_collection, 25 vector_search_index_name="vector_index_scalar_quantized", 26 use_full_precision=True, 27 top_k_values=top_k_values, 28 num_candidates_values=num_candidates_values, 29 ) 30 ) 31 32 # Combine all results into a single DataFrame 33 all_latency_results = pd.concat([pd.DataFrame(latency_results)]) Top-K: 5, NumCandidates: 25, Latency: 1672.855906 ms, Precision: _float32_ann ... Top-K: 100, NumCandidates: 10000, Latency: 184.905389 ms, Precision: _float32_ann Top-K: 5, NumCandidates: 25, Latency: 828.45855 ms, Precision: _scalar_ ... Top-K: 100, NumCandidates: 10000, Latency: 214.199836 ms, Precision: _scalar_ Top-K: 5, NumCandidates: 25, Latency: 400.160243 ms, Precision: _binary_ ... Top-K: 100, NumCandidates: 10000, Latency: 360.908558 ms, Precision: _binary_ Top-K: 5, NumCandidates: 25, Latency: 0.239107 ms, Precision: _float32_ENN ... Top-K: 100, NumCandidates: 10000, Latency: 0.179203 ms, Precision: _float32_ENN As medições de latência revelam uma hierarquia clara de desempenho entre os tipos de precisão, onde a quantização binária demonstra os tempos de recuperação mais rápidos, seguida pela quantização escalar. As operações de precisão total float32 ANN apresentam latências significativamente maiores. A diferença de desempenho entre pesquisas quantizadas e de precisão total torna-se mais evidente à medida que os valores de Top-K aumentam. As operações float32 ENN são as mais lentas, mas fornecem os resultados de maior precisão.
Trace a latência de pesquisa em relação a vários valores de top-k.
1 import matplotlib.pyplot as plt 2 3 # Map your precision field to the labels and colors you want in the legend 4 precision_label_map = { 5 "_scalar_": "scalar", 6 "_binary_": "binary", 7 "_float32_ann": "float32_ann", 8 "_float32_ENN": "float32_ENN", 9 } 10 11 precision_color_map = { 12 "_scalar_": "orange", 13 "_binary_": "red", 14 "_float32_ann": "blue", 15 "_float32_ENN": "purple", 16 } 17 18 # Flatten all measurements and find the unique top_k values 19 all_measurements = [m for precision_list in latency_results for m in precision_list] 20 unique_topk = sorted(set(m["top_k"] for m in all_measurements)) 21 22 # For each top_k, create a separate plot 23 for k in unique_topk: 24 plt.figure(figsize=(10, 6)) 25 26 # For each precision type, filter out measurements for the current top_k value 27 for measurements in latency_results: 28 # Filter measurements with top_k equal to the current k 29 filtered = [m for m in measurements if m["top_k"] == k] 30 if not filtered: 31 continue 32 33 # Extract x (num_candidates) and y (latency) values 34 x = [m["num_candidates"] for m in filtered] 35 y = [m["latency_ms"] for m in filtered] 36 37 # Determine the precision, label, and color from the first measurement in this filtered list 38 precision = filtered[0]["precision"] 39 label = precision_label_map.get(precision, precision) 40 color = precision_color_map.get(precision, "blue") 41 42 # Plot the line for this precision type 43 plt.plot(x, y, marker="o", color=color, label=label) 44 45 # Label axes and add title including the top_k value 46 plt.xlabel("Number of Candidates") 47 plt.ylabel("Latency (ms)") 48 plt.title(f"Search Latency vs Num Candidates for Top-K = {k}") 49 50 # Add a legend and grid, then show the plot 51 plt.legend() 52 plt.grid(True) 53 plt.show() O código retorna os seguintes gráficos de latência, que ilustram como a pesquisa vetorial de recuperação de documentos se comporta com diferentes tipos de precisão de incorporação, binário, escalar e float32, à medida que o
top-k(o número de documentos recuperados) aumenta:![Captura de tela do gráfico mostrando latência de pesquisa versus número de candidatos para Top-K = 5]() clique para ampliar
clique para ampliar![Captura de tela do gráfico mostrando latência de pesquisa versus número de candidatos para Top-K = 10]() clique para ampliar
clique para ampliar![Captura de tela do gráfico mostrando latência de pesquisa versus número de candidatos para Top-K = 50]() clique para ampliar
clique para ampliar



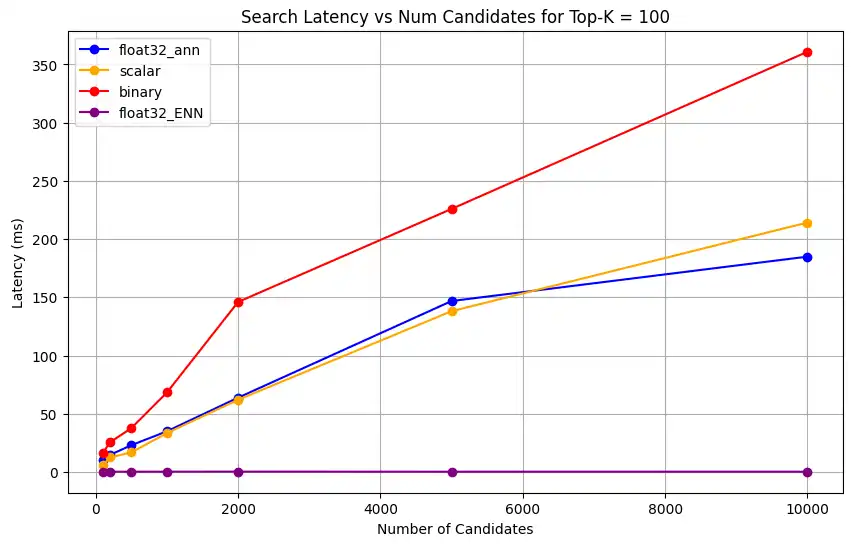
Meça a capacidade de representação e retenção.
A query a seguir mede a eficiência com que a Vector Search do MongoDB recupera documentos relevantes do conjunto de dados da verdade fundamental. É calculado como a proporção de documentos relevantes encontrados corretamente em relação ao número total de documentos relevantes na verdade do campo (Found/Total). Por exemplo, se uma query tiver 5 documentos relevantes na verdade fundamental e o MongoDB Vector Search encontrar 4 deles, a recuperação será 0.8 ou 80%.
Defina uma função para medir a capacidade de representação e a retenção da operação de pesquisa vetorial. Esta função faz o seguinte:
Cria a pesquisa de base usando os vetores float32 de precisão total e a pesquisa ENN.
Cria a pesquisa quantizada usando os vetores quantizados e a pesquisa ANN.
Calcula a retenção da pesquisa quantizada em comparação com a pesquisa de linha de base.
A retenção deve ser mantida dentro de uma faixa razoável para a pesquisa quantizada. Caso a capacidade representacional seja baixa, a operação de pesquisa vetorial não é capaz de capturar o significado semântico da query, e os resultados podem não ser precisos. Isso indica que a quantização não é eficaz e que o modelo de incorporação inicial usado não é eficaz para o processo de quantização. Recomendamos usar modelos de incorporação sensíveis à quantização, o que significa que, durante o processo de treinamento, o modelo é otimizado especificamente para produzir incorporações que mantenham suas propriedades semânticas mesmo após a quantização.
1 def measure_representational_capacity_retention_against_float_enn( 2 ground_truth_collection, 3 collection, 4 quantized_index_name, # This is used for both the quantized search and (with use_full_precision=True) for the baseline. 5 top_k_values, # List/array of top-k values to test. 6 num_candidates_values, # List/array of num_candidates values to test. 7 num_queries_to_test=1, 8 ): 9 retention_results = {"per_query_retention": {}} 10 overall_retention = {} # overall_retention[top_k][num_candidates] = [list of retention values] 11 12 # Initialize overall retention structure 13 for top_k in top_k_values: 14 overall_retention[top_k] = {} 15 for num_candidates in num_candidates_values: 16 if num_candidates < top_k: 17 continue 18 overall_retention[top_k][num_candidates] = [] 19 20 # Extract and store the precision name from the quantized index name. 21 precision_name = quantized_index_name.split("vector_index")[1] 22 precision_name = precision_name.replace("quantized", "").capitalize() 23 retention_results["precision_name"] = precision_name 24 retention_results["top_k_values"] = top_k_values 25 retention_results["num_candidates_values"] = num_candidates_values 26 27 # Load ground truth annotations 28 ground_truth_annotations = list( 29 ground_truth_collection.find().limit(num_queries_to_test) 30 ) 31 print(f"Loaded {len(ground_truth_annotations)} ground truth annotations") 32 33 # Process each ground truth annotation 34 for annotation in ground_truth_annotations: 35 # Use the ground truth wiki_id from the annotation. 36 ground_truth_wiki_id = annotation["wiki_id"] 37 38 # Process only queries that are questions. 39 for query_type, queries in annotation["queries"].items(): 40 if query_type.lower() not in ["question", "questions"]: 41 continue 42 43 for query in queries: 44 # Prepare nested dict for this query 45 if query not in retention_results["per_query_retention"]: 46 retention_results["per_query_retention"][query] = {} 47 48 # For each valid combination of top_k and num_candidates 49 for top_k in top_k_values: 50 if top_k not in retention_results["per_query_retention"][query]: 51 retention_results["per_query_retention"][query][top_k] = {} 52 for num_candidates in num_candidates_values: 53 if num_candidates < top_k: 54 continue 55 56 # Baseline search: full precision using ENN (Float32) 57 baseline_result = custom_vector_search( 58 user_query=query, 59 collection=collection, 60 embedding_path="embedding", 61 vector_search_index_name=quantized_index_name, 62 top_k=top_k, 63 num_candidates=num_candidates, 64 use_full_precision=True, 65 ) 66 baseline_ids = { 67 res["wiki_id"] for res in baseline_result["results"] 68 } 69 70 # Quantized search: 71 quantized_result = custom_vector_search( 72 user_query=query, 73 collection=collection, 74 embedding_path="embedding", 75 vector_search_index_name=quantized_index_name, 76 top_k=top_k, 77 num_candidates=num_candidates, 78 use_full_precision=False, 79 ) 80 quantized_ids = { 81 res["wiki_id"] for res in quantized_result["results"] 82 } 83 84 # Compute retention for this combination 85 if baseline_ids: 86 retention = len( 87 baseline_ids.intersection(quantized_ids) 88 ) / len(baseline_ids) 89 else: 90 retention = 0 91 92 # Store the results per query 93 retention_results["per_query_retention"][query].setdefault( 94 top_k, {} 95 )[num_candidates] = { 96 "ground_truth_wiki_id": ground_truth_wiki_id, 97 "baseline_ids": sorted(baseline_ids), 98 "quantized_ids": sorted(quantized_ids), 99 "retention": retention, 100 } 101 overall_retention[top_k][num_candidates].append(retention) 102 103 print( 104 f"Query: '{query}' | top_k: {top_k}, num_candidates: {num_candidates}" 105 ) 106 print(f" Ground Truth wiki_id: {ground_truth_wiki_id}") 107 print(f" Baseline IDs (Float32): {sorted(baseline_ids)}") 108 print( 109 f" Quantized IDs: {precision_name}: {sorted(quantized_ids)}" 110 ) 111 print(f" Retention: {retention:.4f}\n") 112 113 # Compute overall average retention per combination 114 avg_overall_retention = {} 115 for top_k, cand_dict in overall_retention.items(): 116 avg_overall_retention[top_k] = {} 117 for num_candidates, retentions in cand_dict.items(): 118 if retentions: 119 avg = sum(retentions) / len(retentions) 120 else: 121 avg = 0 122 avg_overall_retention[top_k][num_candidates] = avg 123 print( 124 f"Overall Average Retention for top_k {top_k}, num_candidates {num_candidates}: {avg:.4f}" 125 ) 126 127 retention_results["average_retention"] = avg_overall_retention 128 return retention_results Avalie e compare o desempenho dos seus índices do MongoDB Vector Search .
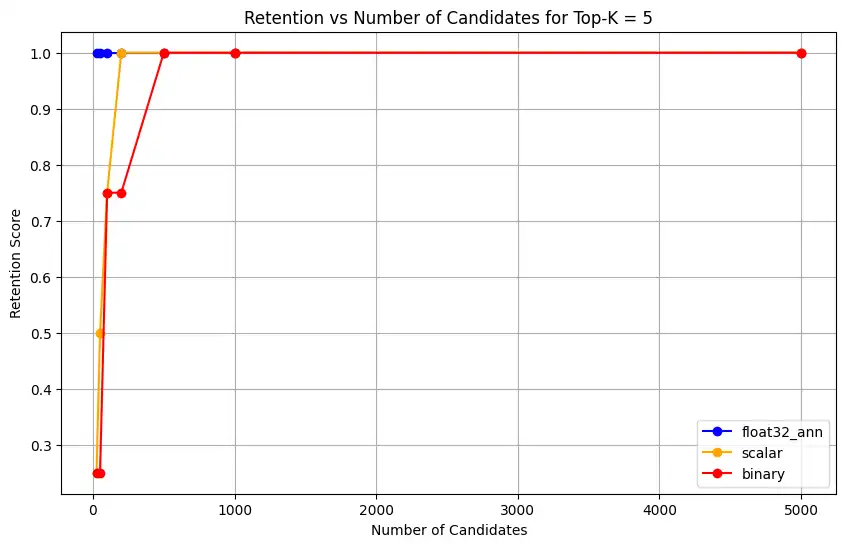
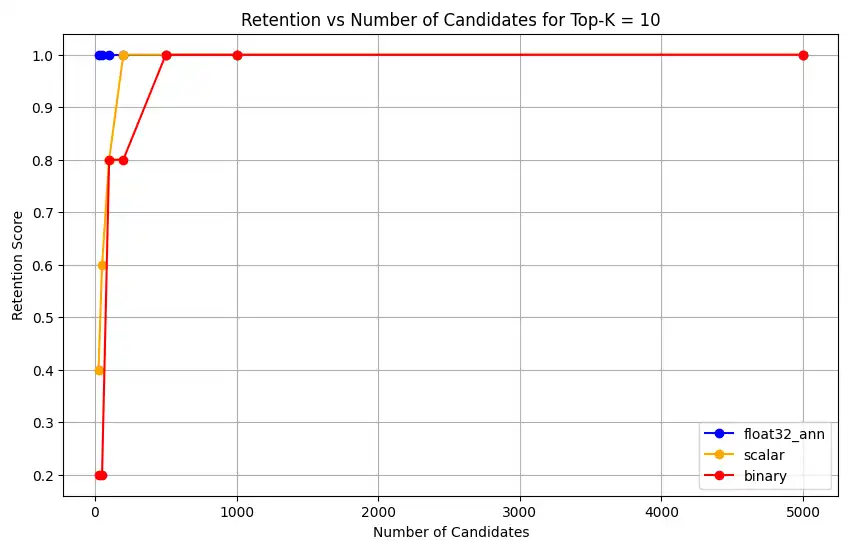
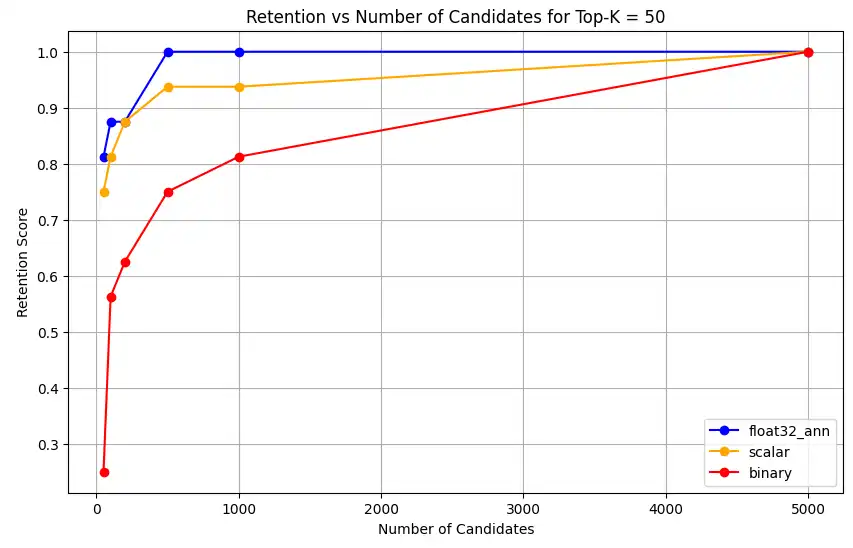
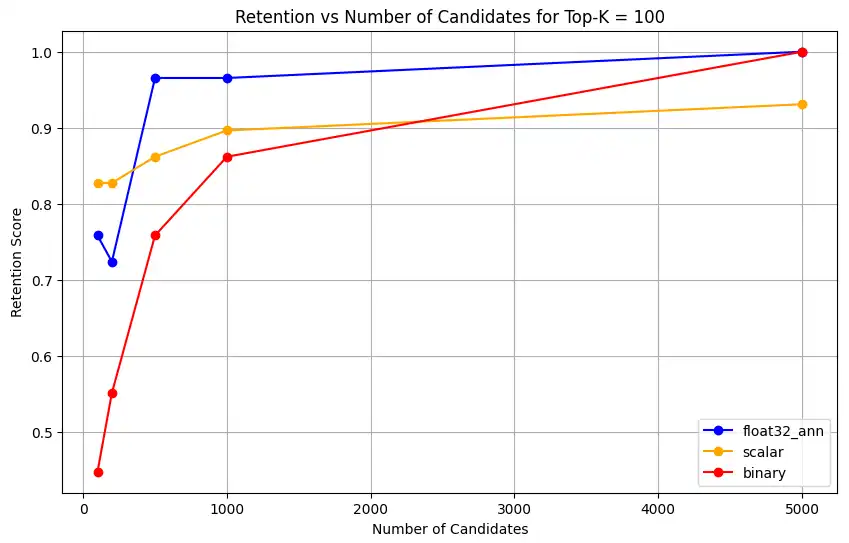
1 overall_recall_results = [] 2 top_k_values = [5, 10, 50, 100] 3 num_candidates_values = [25, 50, 100, 200, 500, 1000, 5000] 4 num_queries_to_test = 1 5 6 for vector_search_index in vector_search_indices: 7 overall_recall_results.append( 8 measure_representational_capacity_retention_against_float_enn( 9 ground_truth_collection=wiki_annotation_data_collection, 10 collection=wiki_data_collection, 11 quantized_index_name=vector_search_index, 12 top_k_values=top_k_values, 13 num_candidates_values=num_candidates_values, 14 num_queries_to_test=num_queries_to_test, 15 ) 16 ) Loaded 1 ground truth annotations Query: 'What happened in 2022?' | top_k: 5, num_candidates: 25 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871] Quantized IDs: _float32_ann: [60254944, 64483771, 69094871] Retention: 0.7500 ... Query: 'What happened in 2022?' | top_k: 5, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871] Quantized IDs: _float32_ann: [52251217, 60254944, 64483771, 69094871] Retention: 1.0000 Query: 'What happened in 2022?' | top_k: 10, num_candidates: 25 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871, 69265870] Quantized IDs: _float32_ann: [60254944, 64483771, 65225795, 69094871, 70149799] Retention: 1.0000 ... Query: 'What happened in 2022?' | top_k: 10, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [52251217, 60254944, 64483771, 69094871, 69265870] Quantized IDs: _float32_ann: [52251217, 60254944, 64483771, 69094871, 69265870] Retention: 1.0000 Query: 'What happened in 2022?' | top_k: 50, num_candidates: 50 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [25391, 832774, 8351234, 18426568, 29868391, 52241897, 52251217, 60254944, 63422045, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [25391, 8351234, 29868391, 40365067, 52241897, 52251217, 60254944, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 0.8125 ... Query: 'What happened in 2022?' | top_k: 50, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [25391, 832774, 8351234, 18426568, 29868391, 52241897, 52251217, 60254944, 63422045, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [25391, 832774, 8351234, 18426568, 29868391, 52241897, 52251217, 60254944, 63422045, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 1.0000 Query: 'What happened in 2022?' | top_k: 100, num_candidates: 100 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [16642, 22576, 25391, 547384, 737930, 751099, 832774, 8351234, 17742072, 18426568, 29868391, 40365067, 52241897, 52251217, 52851695, 53992315, 57798792, 60163783, 60254944, 62750956, 63422045, 64483771, 65225795, 65593860, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [22576, 25391, 243401, 547384, 751099, 8351234, 17742072, 18426568, 29868391, 40365067, 47747350, 52241897, 52251217, 52851695, 53992315, 57798792, 60254944, 64483771, 65225795, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 0.7586 ... Query: 'What happened in 2022?' | top_k: 100, num_candidates: 5000 Ground Truth wiki_id: 69407798 Baseline IDs (Float32): [16642, 22576, 25391, 547384, 737930, 751099, 832774, 8351234, 17742072, 18426568, 29868391, 40365067, 52241897, 52251217, 52851695, 53992315, 57798792, 60163783, 60254944, 62750956, 63422045, 64483771, 65225795, 65593860, 69094871, 69265859, 69265870, 70149799, 70157964] Quantized IDs: _float32_ann: [16642, 22576, 25391, 547384, 737930, 751099, 832774, 8351234, 17742072, 18426568, 29868391, 40365067, 52241897, 52251217, 52851695, 53992315, 57798792, 60163783, 60254944, 62750956, 63422045, 64483771, 65225795, 65593860, 69094871, 69265859, 69265870, 70149799, 70157964] Retention: 1.0000 Overall Average Retention for top_k 5, num_candidates 25: 0.7500 ... A saída mostra os resultados de retenção para cada query no conjunto de dados de referência. A retenção é expressa como um decimal entre 0 e 1, em que 1,0 significa que os IDs de referência são mantidos, e 0,25 significa que apenas 25% dos IDs de referência são mantidos.
Trace a capacidade de retenção dos diferentes tipos de precisão.
1 import matplotlib.pyplot as plt 2 3 # Define colors and labels for each precision type 4 precision_colors = {"_scalar_": "orange", "_binary_": "red", "_float32_": "green"} 5 6 if overall_recall_results: 7 # Determine unique top_k values from the first result's average_retention keys 8 unique_topk = sorted(list(overall_recall_results[0]["average_retention"].keys())) 9 10 for k in unique_topk: 11 plt.figure(figsize=(10, 6)) 12 # For each precision type, plot retention vs. number of candidates at this top_k 13 for result in overall_recall_results: 14 precision_name = result.get("precision_name", "unknown") 15 color = precision_colors.get(precision_name, "blue") 16 # Get candidate values from the average_retention dictionary for top_k k 17 candidate_values = sorted(result["average_retention"][k].keys()) 18 retention_values = [ 19 result["average_retention"][k][nc] for nc in candidate_values 20 ] 21 22 plt.plot( 23 candidate_values, 24 retention_values, 25 marker="o", 26 label=precision_name.strip("_"), 27 color=color, 28 ) 29 30 plt.xlabel("Number of Candidates") 31 plt.ylabel("Retention Score") 32 plt.title(f"Retention vs Number of Candidates for Top-K = {k}") 33 plt.legend() 34 plt.grid(True) 35 plt.show() 36 37 # Print detailed average retention results 38 print("\nDetailed Average Retention Results:") 39 for result in overall_recall_results: 40 precision_name = result.get("precision_name", "unknown") 41 print(f"\n{precision_name} Embedding:") 42 for k in sorted(result["average_retention"].keys()): 43 print(f"\nTop-K: {k}") 44 for nc in sorted(result["average_retention"][k].keys()): 45 ret = result["average_retention"][k][nc] 46 print(f" NumCandidates: {nc}, Retention: {ret:.4f}") O código retorna os gráficos de retenção para o seguinte:
![Captura de tela do gráfico mostrando retenção vs número de candidatos para Top-K = 5]() clique para ampliar
clique para ampliar![Captura de tela do gráfico mostrando retenção vs número de candidatos para Top-K = 10]() clique para ampliar
clique para ampliar![Captura de tela do gráfico mostrando retenção vs número de candidatos para Top-K = 50]() clique para ampliar
clique para ampliar![Captura de tela do gráfico mostrando retenção vs número de candidatos para Top-K = 100]() clique para ampliar
clique para ampliarPara
float32_ann,scalarebinaryembeddings, o código também retorna resultados médios detalhados de retenção semelhantes aos seguintes:Detailed Average Retention Results: _float32_ann Embedding: Top-K: 5 NumCandidates: 25, Retention: 1.0000 NumCandidates: 50, Retention: 1.0000 NumCandidates: 100, Retention: 1.0000 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 10 NumCandidates: 25, Retention: 1.0000 NumCandidates: 50, Retention: 1.0000 NumCandidates: 100, Retention: 1.0000 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 50 NumCandidates: 50, Retention: 0.8125 NumCandidates: 100, Retention: 0.8750 NumCandidates: 200, Retention: 0.8750 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 100 NumCandidates: 100, Retention: 0.7586 NumCandidates: 200, Retention: 0.7241 NumCandidates: 500, Retention: 0.9655 NumCandidates: 1000, Retention: 0.9655 NumCandidates: 5000, Retention: 1.0000 _scalar_ Embedding: Top-K: 5 NumCandidates: 25, Retention: 0.2500 NumCandidates: 50, Retention: 0.5000 NumCandidates: 100, Retention: 0.7500 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 10 NumCandidates: 25, Retention: 0.4000 NumCandidates: 50, Retention: 0.6000 NumCandidates: 100, Retention: 0.8000 NumCandidates: 200, Retention: 1.0000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 50 NumCandidates: 50, Retention: 0.7500 NumCandidates: 100, Retention: 0.8125 NumCandidates: 200, Retention: 0.8750 NumCandidates: 500, Retention: 0.9375 NumCandidates: 1000, Retention: 0.9375 NumCandidates: 5000, Retention: 1.0000 Top-K: 100 NumCandidates: 100, Retention: 0.8276 NumCandidates: 200, Retention: 0.8276 NumCandidates: 500, Retention: 0.8621 NumCandidates: 1000, Retention: 0.8966 NumCandidates: 5000, Retention: 0.9310 _binary_ Embedding: Top-K: 5 NumCandidates: 25, Retention: 0.2500 NumCandidates: 50, Retention: 0.2500 NumCandidates: 100, Retention: 0.7500 NumCandidates: 200, Retention: 0.7500 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 10 NumCandidates: 25, Retention: 0.2000 NumCandidates: 50, Retention: 0.2000 NumCandidates: 100, Retention: 0.8000 NumCandidates: 200, Retention: 0.8000 NumCandidates: 500, Retention: 1.0000 NumCandidates: 1000, Retention: 1.0000 NumCandidates: 5000, Retention: 1.0000 Top-K: 50 NumCandidates: 50, Retention: 0.2500 NumCandidates: 100, Retention: 0.5625 NumCandidates: 200, Retention: 0.6250 NumCandidates: 500, Retention: 0.7500 NumCandidates: 1000, Retention: 0.8125 NumCandidates: 5000, Retention: 1.0000 Top-K: 100 NumCandidates: 100, Retention: 0.4483 NumCandidates: 200, Retention: 0.5517 NumCandidates: 500, Retention: 0.7586 NumCandidates: 1000, Retention: 0.8621 NumCandidates: 5000, Retention: 1.0000 Os resultados do recall demonstram padrões de desempenho distintos entre os três tipos de incorporações.
A quantização escalar apresenta uma melhoria contínua, indicando alta precisão de recuperação em valores K mais altos. A quantização binária, embora comece mais baixa, melhora no Top-K 50 e 100, sugerindo um equilíbrio entre a eficiência computacional e o desempenho de recall. As incorporações float32 demonstram desempenho inicial mais forte e alcançam o mesmo recall máximo que a quantização escalar no Top-K 50 e 100.
Isso sugere que, apesar de o float32 oferecer melhor recuperação em valores Top-K mais baixos, a quantização escalar pode atingir desempenho equivalente em valores Top-K mais altos, oferecendo maior eficiência computacional. A quantização binária, apesar de seu limite máximo de recuperação mais baixo, ainda pode ser valiosa em cenários em que as restrições de memória e computação superam a necessidade de precisão máxima de recuperação.