É possível estruturar seu cluster com diferentes tipos de sistema, provedores de nuvem e camadas de cluster para atender às necessidades de um ambiente de pré-produção ou produção. Use essas recomendações para selecionar o tipo de sistema, provedor de nuvem e região, e cluster e níveis de pesquisa para executar a pesquisa vetorial.
ambiente | Tipo de implementação | Camada do cluster | Região do provedor de nuvem | Arquitetura de nó |
|---|---|---|---|---|
Testando queries | Flex cluster, dedicated cluster Local deployment | Free cluster or higher tier N/A | All N/A | Processos do MongoDB e Atlas Search executados no mesmo nó |
Aplicativos de protótipos | Cluster dedicado | Cluster flexível, | Todos | Processos do MongoDB e Atlas Search executados no mesmo nó |
Produção | Cluster dedicado com nós de pesquisa separados |
| Amazon Web Services e Azure em algumas regiões do ou Google Cloud Platform em todas as regiões | Processos do MongoDB e Atlas Search executados em nós diferentes |
Para saber mais sobre esses modelos de sistema, revise as seguintes seções:
Uso de recursos
Requisitos de memória para a indexação de vetores
O MongoDB Vector Search mantém o índice inteiro na memória, portanto, você precisa garantir que haja memória suficiente para o índice do MongoDB Vector Search e o JVM se o seu conjunto de dados incluir vetores de precisão total. Cada índice é uma combinação dos vetores que estão sendo indexados e metadados adicionais. O tamanho do índice é determinado principalmente pelo tamanho dos vetores que você está indexando, com o espaço de metadados normalmente sendo relativamente temporal.
Quando não estiver usando a quantização, o MongoDB Vector Search armazena todos os vetores de fidelidade na memória. Se você ativar a quantização automática, o MongoDB Vector Search armazenará os vetores quantizados, que exigem significativamente menos recursos, na memória e os vetores de fidelidade total no disco. Você pode visualizar a diferença entre os requisitos de disco e memória para índices de vetor visualizando as colunas Size e Required Memory na página de pesquisa do MongoDB da interface do usuário do Atlas .
Considere os seguintes requisitos para um único vetor:
Modelo de incorporação | Dimensão vetorial | Requisitos de espaço |
|---|---|---|
Voyage AI | 2048 | 8kb (for float)2.14kb (for int8)0.334kb (for int1) |
OpenAI | 1536 | 6kb |
Google | 768 | 3kb |
Cohere | 1024 | 4kb (for float)1.07kb (for int8)0.167kb (for int1) |
Vetores quantizados BinData. Para saber mais,consulte Ingestão de vetores quantizados.
O espaço necessário é dimensionado linearmente com o número de vetores que você está indexando e com a dimensionalidade do vetor. Você também pode usar a métrica Search Index Size para determinar a quantidade de espaço e memória necessária em seus nós de pesquisa.
Requisitos de armazenamento para vetores
Se você usar BinData ou vetores quantizados, você reduzirá significativamente os requisitos de recursos em comparação com não usar binData ou vetores quantizados. Você perceberá:
O armazenamento em disco de vetores em
mongodé reduzido em 66% ao usar vetoresbinData.O uso de RAM por vetores em
mongoté reduzido em 3.75x (escalar) ou 24x (binário) devido à compactação vetorial ao usar quantização automática de vetores ou ingestão de vetores quantizados.
Quando você usa a quantização automática, o Atlas armazena os vetores de precisão total para reclassificação ou pesquisa exata no disco, com uso mínimo de RAM e cache para reclassificação.
Se você habilitar a quantização automática em sua definição de índice do MongoDB Vector Search, também deverá considerar o espaço em disco ao dimensionar o cluster. Isso ocorre porque o MongoDB Vector Search armazena vetores de precisão total também no disco para pesquisa ENN e para reclassificação se você tiver configurado a quantização automática. Portanto, certifique-se de que haja uma proporção apropriada de disco para RAM no hardware que você usa. Considere a possibilidade de configurar nós de pesquisa que possam acomodar aproximadamente uma proporção de 4:1 de armazenamento para RAM para quantização escalar ou uma proporção 24:1 de armazenamento para RAM para quantização binária.
Exemplo
Este exemplo demonstra como configurar a quantização binária para 10 milhões de incorporações de 1024 dimensões da Voyage AI armazenadas no campo chamado my-embeddings:
{ "fields":[ { "type": "vector", "path": "my-embeddings", "numDimensions": 1024, "similarity": "euclidean", "quantization": "binary" } ] }
Use a fórmula a seguir para calcular aproximadamente o espaço em disco para o seu índice habilitado para quantização binária com reclassificação:
Original index size * (25/24)
Aqui, o 24 no denominador representa o tamanho do índice original divisão em 24 partes para facilitar a representação da fração. O 25 no numerador contabiliza uma alocação de espaço adicional, que é de aproximadamente 1/24 do tamanho original do índice, para dados adicionais necessários para armazenar vetores binários. Tanto o índice original quanto o gráfico Hierarchical Navigable Small Worlds ainda estão armazenados no disco. O fator de tamanho grande é 1/24 em vez de 1/32 porque o gráfico HNSW não é compactado.
Exemplo
Suponha que o tamanho do índice original seja 1 GB. Você pode calcular o tamanho do índice quantizado binário com reavaliação, conforme mostrado abaixo:
1 GB * (25/24) = 1.042 GB
Importante
Na UI do Atlas , o Atlas exibe todo o tamanho do índice, que pode ser grande, pois o Atlas não mostra um detalhamento das estruturas de dados dentro de um índice que são armazenadas na RAM e no disco. As métricas de pesquisa do MongoDB mostram um índice muito menor que é mantido na memória quando você ativa a quantização automática.
Para vetores para os quais você configurou a quantização automática, recomendamos alocar espaço livre em disco igual a 125% do tamanho estimado do índice.
Ambientes de teste e protótipos
Para testar suas queries de pesquisa vetorial e prototipar seu aplicativo, recomendamos a configuração a seguir.
Tipo de implementação
Para testar queries do MongoDB Vector Search , você pode implantar um cluster Flex, um cluster dedicado ou usar um sistema local do Atlas .
Cluster Tiers
Os clusters gratuitos (anteriormente conhecidos como M0) são uma camada grátis de cluster. Os clusters flexíveis são tipos de cluster de baixo custo adequados para equipes que estão aprendendo MongoDB ou desenvolvendo pequenos aplicativos de prova de conceito. Você pode iniciar seu projeto com um cluster Atlas Flex e atualizar para um nível do cluster dedicado pronta para produção em um momento futuro.
Esses tipos de cluster de baixo custo estão disponíveis para testar suas queries do MongoDB Vector Search . No entanto, você pode enfrentar contenção de recursos e latência de query em clusters Flex. Se você iniciar seu projeto com um cluster Flex, recomendamos a atualização para um nível superior quando o aplicação estiver pronto para produção.
Os clusters dedicados incluem M10 e níveis superiores. Os níveis M10 e M20 são adequados para a criação de protótipos do seu aplicativo. Você pode dimensionar para níveis superiores para lidar com grandes conjuntos de dados ou implantar nós de pesquisa dedicados para isolamento da carga de trabalho quando o aplicativo estiver pronto para a produção.
Provedor de nuvem e região
O provedor de nuvem e a região escolhidos afetam as opções de configuração disponíveis para as camadas do cluster e o custo de execução do cluster.
Todas as camadas de cluster estão disponíveis em todas as regiões de provedor de nuvem compatíveis
Se você preferir testar as queries do MongoDB Vector Search localmente, poderá usar o Atlas CLI para implementar um conjunto de réplicas de nó único hospedado em seu computador local. Para começar, conclua o Início Rápido da Vector Search do MongoDB e selecione a guia para implantações locais.
Quando seu aplicativo estiver pronto para produção, migre sua implantação local do Atlas para um ambiente de produção usando o Migração em produção. As implantações locais são limitadas pelos recursos de CPU, memória e armazenamento de seu computador local.
Arquitetura de nó
Para ambientes de teste e criação de protótipos, recomendamos uma arquitetura de nó na qual os processos do MongoDB e o MongoDB Search sejam executados no mesmo nó. No diagrama a seguir deste modelo de implantação, o processo mongot do MongoDB Search é executado ao lado de mongod em cada nó no Atlas cluster e eles compartilham os mesmos recursos.

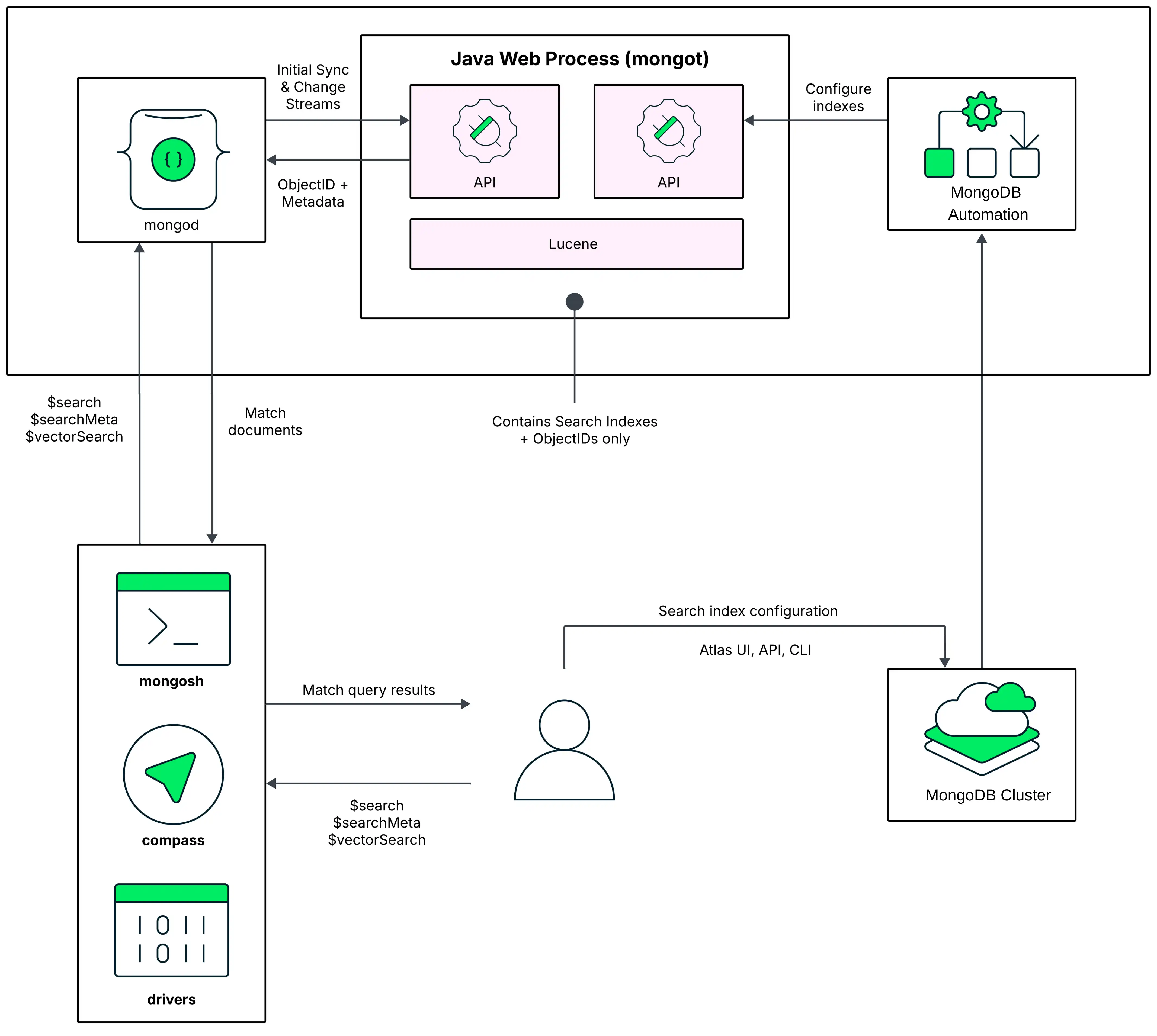
Por padrão, o Atlas habilita o processo mongot do MongoDB Search no mesmo nó que executa o processo mongod quando você cria seu primeiro índice do MongoDB Vector Search .
Quando você executa uma query, o MongoDB Search usa a preferência de leitura configurada para identificar o nó no qual executar a query. A query primeiro vai para o processo do MongoDB, que é mongod para um cluster de conjunto de réplicas ou mongos para um cluster fragmentado.
Para um cluster de conjunto de réplicas, o processo mongod roteia a query para mongot no mesmo nó. Para clusters fragmentados, os dados do cluster são particionados em instâncias mongod (shards) e cada processo mongot só pode acessar os dados na instância mongod no mesmo nó. Portanto, você não pode executar queries no MongoDB Search que tenham como alvo um shard específico. mongos roteia a query para todos os shards, fazendo estas dispersar e reunir queries. Se você usar zonas para distribuir uma collection fragmentada em um subconjunto dos shards no cluster, o MongoDB Search roteará a query para a zona que contém os shards da collection que você está consultando e executará suas $search queries apenas nos shards onde a coleção está localizada.
Depois que a query é roteada para um processo mongot do MongoDB Search, o processo mongot executa a pesquisa e a pontuação e retorna os IDs dos documento e outros metadados da pesquisa dos resultados correspondentes para o processo mongod correspondente. O processo mongod então realiza uma pesquisa completa do documento implicitamente para os resultados correspondentes e retorna os resultados ao cliente. Se você usar a opção $search concurrent em sua query, o MongoDB Search ativará o paralelismo intraquery. Para saber mais, consulte Parallelize Query Execution Across Segments.
Para saber mais sobre o processo mongot, consulte Processamento de query.
Dimensionando seu Cluster para Prototipagem do seu Aplicativo
Quando o Atlas executa seu banco de dados e pesquisa cargas de trabalho no mesmo nó, o armazenamento do MongoDB ocupa uma determinada porcentagem da memória disponível do nó (RAM), deixando o restante para o índice do MongoDB Vector Search e o processo mongot.
Nível | Memória Total (GB) | Memória disponível para o MongoDB Vector Search Index (GB) |
|---|---|---|
| 2 | 1 |
| 4 | 2 |
| 8 | 4 |
Para as camadas do cluster M10, M20 e M30, 25% é reservado para o MongoDB , e o 75% restante é para outras operações, incluindo seu índice do MongoDB Vector Search . Para camadas de cluster M40+, 50% é reservado para o MongoDB e o restante é para outras operações, incluindo seu índice do MongoDB Vector Search .
Limitações
Você pode experimentar a contenção de recursos entre o mongod do banco de dados e os processos de mongot pesquisa. Isso pode afetar negativamente o desempenho de seu índice e a latência de suas queries. Recomendamos este modelo de implantação apenas para ambientes de teste e prototipagem. Para aplicativos prontos para produção e cargas de trabalho de pesquisa associadas, recomendamos a migração para nós de pesquisa dedicados.
Ambiente de produção
Para seu aplicativo pronto para produção, recomendamos a seguinte configuração de cluster.
Tipo de implementação
Para aplicativos prontos para produção, é necessário um cluster dedicado com nós de pesquisa separados para isolamento de carga de trabalho.
Cluster Tiers
Os clusters dedicados incluem M10 e níveis superiores. As camadas M10 e M20 são adequadas para ambientes de desenvolvimento e produção. No entanto, os níveis mais altos podem lidar com grandes conjuntos de dados e cargas de trabalho de produção. Recomendamos que você também implante nós de pesquisa dedicados para sua carga de trabalho de pesquisa. Isso permite que você dimensione sua implementação de pesquisa de forma independente e adequada.
Provedor de nuvem e região
Os nós de pesquisa estão disponíveis em todas as regiões da Google Cloud Platform, mas estão disponíveis apenas em um subconjunto de regiões da Amazon Web Services e do Azure . Você deve selecionar um provedor de nuvem e uma região onde os nós de pesquisa estejam disponíveis para sua implementação.
Todas as camadas de cluster estão disponíveis em regiões de provedores de nuvem com suporte. O provedor de nuvem e a região que você escolher afetam as opções de configuração e as camadas de pesquisa disponíveis para o cluster e o custo de execução do cluster.
Arquitetura de nó
Para ambientes de produção, recomendamos uma arquitetura de nó na qual os processos do MongoDB e os processos do MongoDB Search são executados em nós separados. Para implantar nós de pesquisa separados, consulte Migrar para nós de pesquisa dedicados.
No diagrama a seguir deste modelo de sistema, o processo mongot do MongoDB Search é executado em nós de pesquisa dedicados, que são separados dos nós do cluster nos quais o processo mongod é executado.

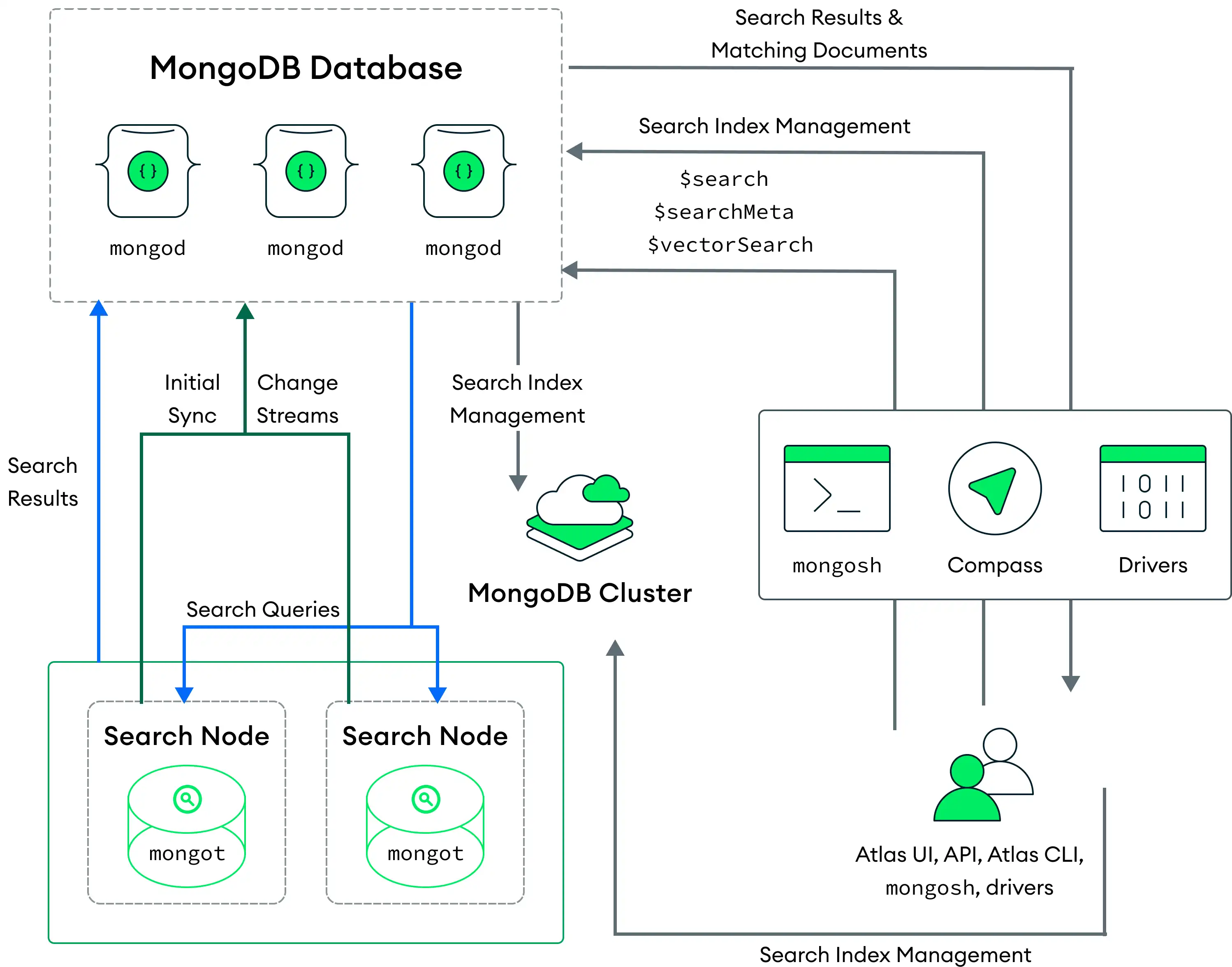
O Atlas implanta nós de pesquisa com cada cluster ou com cada fragmento no cluster. Por exemplo, se você implantar dois nós de pesquisa para um cluster com três shards, o Atlas implantará seis nós de pesquisa (dois por shard). Você também pode configurar o número de nós de pesquisa e a quantidade de recursos provisionados para cada nó de pesquisa.
Ao implantar nós de pesquisa separados, o Atlas atribui automaticamente um mongod para cada mongot para indexação. O mongot comunica com o mongod para ouvir e sincronizar as alterações de índice para os índices que armazena. O MongoDB Vector Search indexa e processa suas queries de forma semelhante a um sistema em que os processos mongod e mongot são executados no mesmo nó. Para saber mais, consulte Como indexar campos para o Vector Search e Executar queries do Vector Search. Para saber mais sobre como implantar nós de pesquisa separadamente, consulte Nós de pesquisa para isolamento de volume de trabalho.
Quando você migra para os Nós de Pesquisa, o Atlas implanta os Nós de Pesquisa, mas não atende a queries nos nós até que ele crie com êxito todos os índices no cluster nos Nós de Pesquisa. Enquanto o Atlas cria os índices nos novos nós, ele continua a atender queries usando os índices nos nós do cluster. O Atlas começa a atender queries dos nós de pesquisa somente depois de criar com êxito os índices nos nós de pesquisa e remover os índices nos nós do cluster.
Observação
O dimensionamento de seu cluster com a adição de nós de pesquisa ou com a alteração do nível de pesquisa aciona uma reconstrução de todo o índice do MongoDB Search. No entanto, se seu cluster na AWS ou Azure tiver nós de pesquisa dedicados para os quais você não habilitou a criptografia em descanso usando o gerenciamento de chaves do cliente, o Atlas oferece as seguintes otimizações:
Quando você dimensionar seus nós de pesquisa, o Atlas usará uma cópia recente do seu índice em S3 ou no armazenamento do Azure Blob, em vez de reconstruir o índice inteiro do MongoDB Search no novo nó.
Para os nós existentes, o Atlas periodicamente obtém e carrega uma nova lista incremental de arquivos de índice. O Atlas mantém arquivos de índice por até quatorze (14) dias.
Isso ainda não está disponível para clusters com nós de pesquisa dedicados no Google Cloud.
Quando você executa uma query, a query é roteada para mongod com base na preferência de leitura configurada. O processo mongod encaminha a query de pesquisa por meio de um balanceador de carga no mesmo nó, que distribui as solicitações entre todos os processos mongot.
O processo mongot do MongoDB Search executa a pesquisa e a pontuação e retorna os IDs dos documento e os metadados dos resultados correspondentes para mongod. O mongod então realiza uma pesquisa completa do documento para os resultados correspondentes e retorna os resultados ao cliente. Se você usar a opção $search concurrent em sua query, o MongoDB Search ativará o paralelismo intraquery. Para saber mais, consulte Parallelize Query Execution Across Segments.
Se você excluir todos os nós de pesquisa em seu cluster, haverá uma interrupção no processamento dos resultados da query de pesquisa . Para saber mais, consulte Modificar um Cluster. Se você excluir seu agrupamento do Atlas , o Atlas pausará e então excluirá todos os sistemas de Vector Search MongoDB associados (mongot processos).
Benefícios
Esse modelo de implantação oferece os seguintes benefícios:
Utilize seus recursos com eficiência e, ao mesmo tempo, garantindo alta disponibilidade de seus recursos para volumes de trabalho de Atlas Search .
Dimensione e expanda seu sistema do Atlas Search independentemente do sistema do banco de dados.
Processe automaticamente queries do MongoDB Vector Search simultaneamente, melhorando o tempo de resposta, especialmente em grandes conjuntos de dados. Para saber mais, consulte Execução paralela de consultas entre segmentos.
Dimensione seus nós de pesquisa para
A Vector Search do MongoDB mantém todo o índice na memória, então você precisa garantir que haja memória suficiente para o índice da Vector Search do MongoDB e JVM. Os nós de pesquisa permitem o isolamento do volume de trabalho sem o isolamento de dados, e quase 90% de sua alocação de RAM pode ser usada para armazenar os dados e índices vetoriais na memória, com o restante sendo usado para a JVM.
Cada índice é uma combinação dos vetores que estão sendo indexados e metadados adicionais. O tamanho do índice é determinado principalmente pelo tamanho dos vetores que você está indexando, com o espaço de metadados normalmente sendo relativamente nominal. Para aprender mais, consulte Requisitos de memória para indexação de vetores.
Ao implantar nós de pesquisa dedicados, você pode escolher entre diferentes níveis de pesquisa. Cada nível de pesquisa tem uma capacidade de RAM, uma capacidade de armazenamento e uma CPU padrão. Isso permite que você meça e dimensione seu cluster independentemente da implantação de banco de dados. Para dimensionar sua implantação de pesquisa separadamente, você pode fazer as seguintes alterações na configuração do cluster a qualquer momento:
Ajuste o número de nós de pesquisa no seu cluster.
Ajuste a CPU, a RAM e o armazenamento do nó alterando os níveis do Atlas Search .
Observação
Para saber mais sobre o custo dos nós de pesquisa e das camadas de pesquisa, expanda View all plan features e clique em Atlas Vector Search na página de preços do MongoDB.
Recomendamos que seu nó tenha RAM pelo menos 10% maior que o tamanho total de seus índices do MongoDB Vector Search . Também recomendamos que você verifique se tem CPUs disponíveis suficientes. A latência da query depende do número de CPUs disponíveis, o que pode impacto significativamente o nível de simultaneidade interna que acelera o desempenho da query.
Exemplo
Suponha que você tenha 1M 768 vetores de dimensão de aproximadamente 3GB de tamanho. Os níveis de pesquisa S30 (Low-CPU) e S20 (High-CPU) têm RAM suficiente para suportar o índice. Em vez de fazer a implantação no nível de pesquisa S30 (Low-CPU), recomendamos a implantação no nível de pesquisa S20 (High-CPU), pois o nível de pesquisa S20 (High-CPU) tem mais CPUs disponíveis para executar consultas simultaneamente.
Habilitar Encryption at rest
Por padrão, os processos de pesquisa e MongoDB são executados nos mesmos nós. Com essa arquitetura, a criptografia gerenciada pelo cliente se aplica aos dados do seu banco de dados , mas não se aplica aos índices de pesquisa.
Quando você habilita nós de pesquisa dedicados, os processos de pesquisa são executados em nós separados. Isso permite que você ative a criptografia de dados do nó de pesquisa, para que possa criptografar os dados do banco de dados e os índices de pesquisa com as mesmas chaves gerenciadas pelo cliente para uma cobertura abrangente de criptografia.
Observação
Os nós de banco de dados e os nós de pesquisa usam métodos de criptografia diferentes com as mesmas chaves gerenciadas pelo cliente. Os nós de banco de dados usam o WiredTiger Mecanismo de armazenamento criptografado, enquanto os nós de pesquisa usam criptografia no nível do disco.
Para aprender mais, consulte Habilitar o gerenciamento de chaves do cliente para nós de pesquisa.
Importante
Este recurso está disponível em todos os provedores de KMS, mas os nós de pesquisa devem estar na AWS.
Migrar para nós dedicados do Atlas Search
Os nós de pesquisa dedicados permitem que você meça e dimensione sua implantação de pesquisa separadamente do cluster. Eles também eliminam qualquer contenção de recursos que possa ocorrer em um cluster que executa o banco de dados e os processos de pesquisa no mesmo nó.
Para migrar para nós de pesquisa dedicados, faça as seguintes alterações na sua implantação:
Se sua implantação estiver usando um cluster de camada grátis ou um cluster Flex, faça upgrade do seu cluster para uma camada superior. Nós de pesquisa dedicados são suportados apenas para
M10e camadas de cluster superiores. Para saber mais sobre como migrar para outra camada do cluster, consulte Modificar o Cluster Tier.Os nós de pesquisa dedicados estão disponíveis em um subconjunto das regiões da Amazon Web Services e do Azure, e em todas as regiões do Google Cloud Platform compatíveis. Certifique-se de implementar seu cluster em regiões onde os nós de pesquisa também estão disponíveis. Se o cluster existente estiver em regiões onde os nós de pesquisa não estão disponíveis, migre-o para regiões onde os nós de pesquisa estão disponíveis. Para saber mais, consulte Regiões do fornecedor de nuvem.
Habilite Search Nodes for workload isolation e configure nós de pesquisa. Para saber mais, consulte Adicionar nós de pesquisa.