MongoDB Vector Search 쿼리는 첫 번째 단계로 $vectorSearch 을(를) 사용하는 집계 파이프라인 의 형태를 취합니다. 이 페이지에서는 $vectorSearch 단계의 구문, 옵션 및 동작에 대해 설명합니다.
지원되는 클라이언트
구문
필드
$vectorSearch 단계에서는 다음 필드가 있는 문서를 사용합니다.
벡터 검색 유형
$vectorSearch 단계를 정의할 때 exact 필드 사용하여 ANN 또는 ENN 검색 실행 할지 여부를 지정할 수 있습니다.
근사치 근접 이웃(ANN) 검색 의 경우, MongoDB Vector Search는 다차원 공간에서의 근접성과 고려하는 이웃 수를 기반으로 쿼리 의 벡터 임베딩에 가장 가까운 데이터의 벡터 임베딩을 찾습니다. Hierarchical Navigable Small Worlds 알고리즘 사용하여 모든 벡터를 스캔하지 않고도 쿼리 에서 벡터 임베딩과 가장 유사한 벡터 임베딩을 찾습니다. 따라서 근사 최근접 이웃 검색은 중요한 필터 없이 대규모 데이터 세트를 쿼리하는 데 이상적입니다.
참고
ANN검색 에 대한 최적의 재현율은 90일반적으로95 ENN 검색 과 결과에서 약 ~ %가 겹치지만 지연 시간 상당히 짧은 것으로 간주됩니다. 이를 통해 정확도와 성능 간에 적절한 균형을 맞출 수 있습니다. MongoDB Vector Search를 사용하여 이를 달성하려면 쿼리 시 numCandidates 매개변수를 조정 합니다.
numCandidates 선택
근사 최근접 이웃 검색 실행 하려면 numCandidates 필드 지정해야 합니다. 이 필드 MongoDB Vector Search가 검색 중에 고려하는 가장 가까운 이웃의 수를 결정합니다.
계층적 내비가능 작은 세계 인덱스 구조를 사용하여 벡터 검색을 수행할 때 MongoDB 벡터 검색은 우선 순위 큐를 채우면서 결과를 누적합니다. numCandidates 매개변수는 이 큐의 크기를 제어하며, 이 큐의 크기는 상위 limit 결과를 반환하기 전에 검색할 수 있는 시간을 결정합니다. 큐가 클 수록(numCandidates이 높을수록) 검색은 계층적 내비가능 작은 세계 그래프를 더 많이 탐색할 수 있어 쿼리 지연 시간 증가 비용이 드는 대신 더 나은 일치를 찾을 수 있습니다.
정확성을 높이고 등가 최근접 이웃 과 근사 최근접 이웃 쿼리 결과 간의 불일치를 줄이기 위해 반환할 문서 수(limit)보다 20 배 이상 많은 numCandidates 숫자를 지정하는 것이 좋습니다. 예시 를 들어 5 결과를 반환하도록 limit 을 설정하다 경우 점 으로 numCandidates 을 100 로 설정하는 것이 좋습니다. 자세히 학습하려면 쿼리 결과의 정확성을 측정하는 방법을 참조하세요.
이러한 과다 요청 패턴 ANN검색에서 지연 시간 과 리콜의 균형을 맞추는 데 권장되는 방법입니다. 그러나 특정 데이터 세트 크기와 쿼리 사항에 따라 numCandidates 매개 변수를 조정하는 것이 좋습니다. 정확한 결과를 얻으려면 다음 변수를 고려하세요.
고려 사항
$vectorSearch 표시되는 파이프라인의 첫 번째 단계에 있어야 합니다.
제한 사항
$vectorSearch는 보기 정의 및 다음 파이프라인 단계에서 사용할 수 없습니다.
$facet파이프라인 단계
| [1] | $vectorSearch 의 결과를 이 단계로 전달할 수 있습니다. |
MongoDB Vector Search 인덱싱
이러한 MongoDB 벡터 검색 필드 유형에 대해 자세히 학습하려면 벡터 검색을 위해 필드를 인덱싱하는 방법을 참조하세요.
MongoDB Vector Search 점수
MongoDB Vector Search는 반환하는 모든 문서 에 0 ~ 1 (여기서 0 는 낮은 유사성을 나타내고 1 은 높은 유사성을 나타냅니다)까지 고정된 범위 의 점수를 할당합니다.
참고
데이터를 사전 필터링해도 MongoDB Vector Search가 $vectorSearch 쿼리에 대해 vectorSearchScore 를 사용하여 반환하는 점수에는 영향을 주지 않습니다.
MongoDB 벡터 검색 필터
MongoDB Vector Search는 데이터 필터링을 지원합니다. 다음을 수행할 수 있습니다.
MongoDB 벡터 검색 쿼리에서
filter옵션을 사용하여 데이터를 사전 필터 합니다.필터 게시 를 사용하여 MongoDB 벡터 검색 쿼리 결과를 필터링하고
$match및 기타 지원되는 집계 파이프라인 단계를 사용합니다.
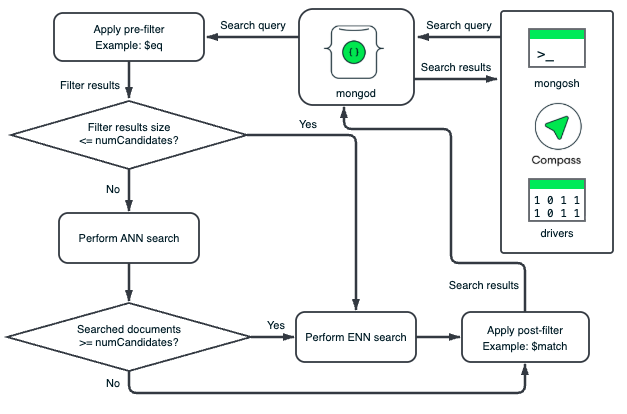
MongoDB 벡터 검색는 데이터 세그먼트에 대해 사전 필터 및 게시 필터 작업을 독립적으로 수행합니다. 각 세그먼트의 HNSW 그래프는 해당 세그먼트의 벡터에만 기반합니다. MongoDB Vector Search는 각 세그먼트의 문서에 필터를 적용하여 필터 기준을 충족하지 않는 문서를 제거합니다. 사전 필터링은 MongoDB Vector Search가 HNSW 그래프를 트래버스하기 전에 문서가 제거되도록 하고 게시 필터링은 문서에서 관련 없는 문서 또는 필드가 벡터 검색 결과에서 제거되도록 합니다.
검색 데이터 사전 필터
데이터를 사전 필터링하여 시맨틱 검색의 범위를 족피고 비교 대상으로 관련 벡터만 고려하도록 할 수 있습니다. filter 옵션을 사용하여 데이터를 사전 필터링하면 MongoDB 벡터 검색은 데이터의 하위 집합에서만 시맨틱 검색을 수행하여 MongoDB 벡터 검색 쿼리에 사용되는 계산 리소스를 줄이고 성능을 향상시킵니다.
사전 필터링은 사전 필터가 사전 필터와 정확히 일치하지 않지만 벡터 검색 동안 고려하려는 쿼리와 의미적으로 유사한 데이터를 제외할 수 있으므 너무 제한적일 수 있습니다. 이를 완화하려면 쿼리가 다음을 수행하도록 넓은 필터 기준을 설정하는 것이 좋습니다.
가능한 한 많은 개의 관련 결과를 포함합니다.
결과에서 무관한 데이터를 제외합니다.
결과에서 요청한 수의 문서를 반환합니다.
중요
필터링된 쿼리는 일반적으로 이에 상응하는 필터링되지 않은 쿼리 보다 느립니다.
검색 결과 게시 필터
인덱스 크기가 사전 필터에 최적화되지 않거나 넓은 사전 필터 기준을 설정한 경우 벡터 검색 결과를 게시 필터링하여 관련 데이터만 반환할 수 있습니다. 벡터 검색 결과를 필터링하려면 단계 다음에 단계와 $match $vectorSearch 같이 지원되는 집계 파이프라인 단계 를 사용할 수 있습니다. 자세한 내용은 추가 성능 권장 사항을 참조하세요.
결과에 모든 필드가 필요하지 않은 경우 $project 단계를 사용하여 결과에 반환할 필드를 선택합니다. 쿼리 성능을 향상시키려면 $project 단계에서 벡터 필드를 제외하는 것이 좋습니다.
예를 들어, $project 단계를 사용하여 vectorSearchScore 를 포함하고 $match 단계를 사용하여 일정 점수 임계값 이상의 문서만 반환할 수 있습니다.
필터 고려 사항
MongoDB Vector Search는
$eq의 짧은 형식을 지원합니다. 짧은 형식에서는 쿼리 에$eq을(를) 지정할 필요가 없습니다.예를 들어,
$eq가 포함된 다음 필터를 가정하겠습니다."filter": { "_id": { "$eq": ObjectId("5a9427648b0beebeb69537a5") } 이는
$eq의 짧은 형식을 사용하는 다음 필터와 동일합니다."filter": { "_id": ObjectId("5a9427648b0beebeb69537a5") } $andMQL 연산자 사용하여 단일 쿼리 에서 필터 배열 을 지정할 수 있습니다.예를 들어
genres필드가Action이고year필드가1999,2000또는2001인 문서에 대해 다음과 같은 사전 필터를 사용한다고 가정해 보겠습니다."filter": { "$and": [ { "genres": "Action" }, { "year": { "$in": [ 1999, 2000, 2001 ] } } ] } 퍼지 검색, 구문 일치, 위치 필터링 및 기타 분석된 텍스트와 같은 고급 필터링 기능의 경우 vectorSearch 연산자를
$search단계에서 사용합니다.
예시
전제 조건
이 예시를 실행하기 전에 다음 작업을 수행하세요.
쿼리에 사용된 샘플 데이터 세트 를 클러스터에 추가합니다.
컬렉션 에 대한 MongoDB Vector Search 인덱스를 생성합니다. 지침은 MongoDB 벡터 검색 인덱스 생성 절차 및 샘플 쿼리에 대한 구성을 원하는 언어로 복사하기를 참조하세요.