고가용성은 인프라 장애, 시스템 유지보수 및 기타 중단 시 지속적인 작업을 보장하고 가동 중단 시간을 최소화하는 애플리케이션의 기능입니다. MongoDB의 기본값 배포서버 아키텍처는 고가용성을 위해 설계되었으며, 데이터 중복성과 자동 페일오버를 위한 내장 기능을 갖추고 있습니다.
고가용성은 재해 복구와 다릅니다. 고가용성은 데이터 손실(RPO = 0) 및 몇 초 이내의 RTO 없이 정확한 장애 시점으로 복구하는 자동 페일오버 통해 노드, 구역, 리전 또는 클라우드 공급자 장애와 같은 인프라 장애로부터 보호합니다. 재해 복구는 백업에서 복원해야 하는 손상이나 실수로 인한 삭제와 같은 데이터 무결성 문제로부터 보호합니다. 재해 복구에 대해 자세히 학습하려면 Atlas 재해 복구를 위한 지침을 참조하세요.
이 페이지에서는 중단을 방지하고 구역, 리전 및 클라우드 공급자 장애에 대한 강력한 페일오버 메커니즘을 지원하기 위해 선택할 수 있는 추가 구성 옵션 및 배포서버 아키텍처 개선 사항에 대해 설명합니다.
고가용성을 위한 Atlas의 기능
데이터베이스 복제
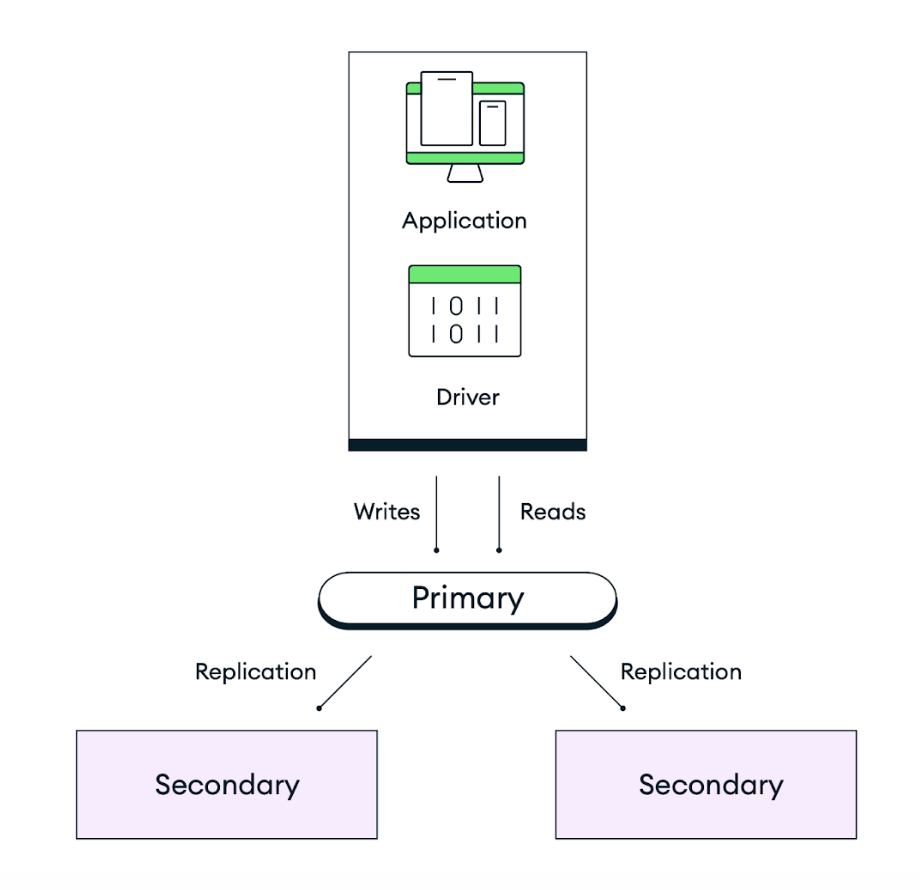
MongoDB의 기본값 배포서버 아키텍처는 중복성을 위해 설계되었습니다. Atlas 각 클러스터는 선택한 cloud 제공자 리전 내의 별도 가용영역에 분산된 최소 3개의 데이터베이스 인스턴스(노드 또는 복제본 세트 멤버라고도 함)가 있는 복제본 세트 로 배포합니다. 애플리케이션이 복제본 세트의 프라이머리 노드에 데이터를 쓰기 (write) 다음, Atlas 클러스터 내의 모든 노드에 해당 데이터를 복제하고 저장합니다. 데이터 저장 의 내구성 을 제어 하려면 특정 수의 보조 노드 가 쓰기 (write) 커밋한 후에만 쓰기 (write) 완료 하도록 애플리케이션 코드 의 쓰기 고려 (write concern) 조정할 수 있습니다 . 기본값 동작은 조치 확인하기 전에 데이터가 대다수의 투표 선택 가능 노드에 유지되는 것입니다.
다음 다이어그램에서 기본값 3노드 복제본 세트의 복제 작동 방식을 확인하실 수 있습니다.
자동 페일오버
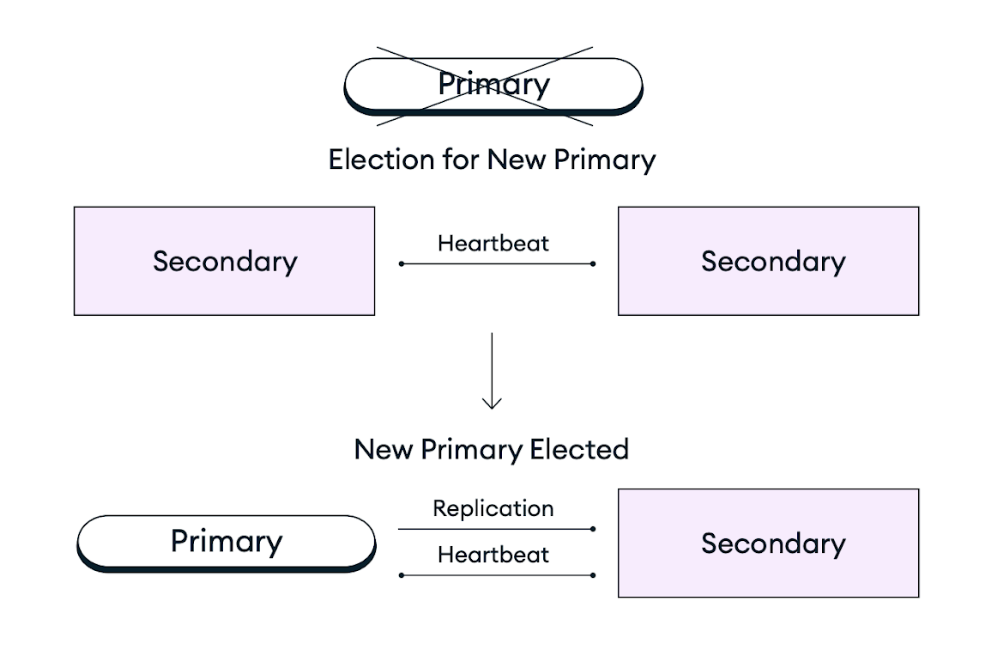
인프라 중단, 예정된 유지 관리 또는 기타 중단으로 인해 복제본 세트의 프라이머리 노드를 사용할 수 없게 되는 이벤트가 발생하면, Atlas 클러스터는 복제본 세트 투표에서 기존 세컨더리 노드를 프라이머리 노드 역할로 승격시켜 자가 복구됩니다. 이 페일오버 프로세스 완전 자동이며 몇 초 만에 데이터 손실(RPO = 0) 없이 정확한 실패 시점으로 복구됩니다. 재시도 가능 쓰기 가 활성화된 경우 실패 당시에 진행 중이던 작업이 실패 후에 재시도됩니다. 복제본 세트 투표 후, Atlas 실패한 멤버를 복원하거나 교체하여 클러스터 가능한 한 빨리 대상 구성으로 돌아갈 수 있도록 합니다. 또한 MongoDB 클라이언트 드라이버 실패 중과 실패 후에 모든 클라이언트 연결을 자동으로 전환합니다.
다음 다이어그램은 복제본 세트 투표 과정을 보여줍니다.
가장 중요한 애플리케이션의 가용성을 개선하기 위해 노드, 리전 또는 클라우드 공급자를 추가하여 각각 구역, 리전 또는 제공자 장애를 견딜 수 있도록 배포서버를 확장할 수 있습니다. 자세한 내용은 아래의 내결함성을 위한 배포서버 패러다임 확장 권장사항을 참조하세요.
Atlas 고가용성 권장 사항
다음 권장사항은 배포서버의 가용성을 높이기 위해 수행할 수 있는 추가 구성 옵션 및 배포서버 아키텍처 개선 사항을 설명합니다.
배포서버 목표에 맞는 클러스터 계층 선택
Dedicated, Flex 또는 무료 배포서버 유형에서 사용할 수 있는 범위 클러스터 계층 중에서 선택할 수 있습니다. MongoDB Atlas 의 클러스터 계층 클러스터 의 각 노드 에 사용할 수 있는 리소스(메모리, 저장 , vCPU, IOPS)를 지정합니다. 상위 계층 으로 확장하면 클러스터가 트래픽 급증을 처리하다 기능 향상되고 높은 워크로드에 더 빠르게 응답하여 시스템 안정성이 향상됩니다. 애플리케이션 크기에 권장되는 클러스터 계층 결정하려면 Atlas 클러스터 크기 가이드를 참조하세요.
Atlas는 또한 자동 확장 을 지원하여 클러스터가 수요 급증에 자동으로 조정할 수 있도록 합니다. Atlas 현재 리소스 사용량을 기반으로 트리거하는 반응형 자동 확장 과 예측된 주기적인 수요 급증이 발생하기 전에 적격 클러스터를 사전에 확장하는 예측 자동 확장 모두 사용합니다. 확장 작업을 자동화하면 리소스 제약으로 인한 장애 위험이 줄어듭니다. 자세한 학습 은 Atlas 자동 인프라 프로비저닝 지침을 참조하세요.
내결함성을 위한 배포서버 패러다임 확장
An Atlas 배포의 내결함성은 복제본 세트 멤버의 배포서버 계속 작동하는 동안 사용할 수 없게 될 수 있는 수입니다. 가용영역, 리전 또는 클라우드 공급자 장애 이벤트, Atlas 클러스터는 복제본 세트 투표에서 기존 세컨더리 노드 프라이머리 노드 역할 로 승격하여 자가 복구됩니다. 프라이머리 노드 중단될 때 복제본 세트 투표 실행 하려면 복제본 세트 에 있는 투표 노드의 과반수가 작동 가능해야 합니다.
부분적인 지역 장애가 발생할 경우 복제본 세트가 프라이머리를 선택할 수 있게 하려면 가용영역이 최소 3개인 리전에 클러스터를 배포해야 합니다. 가용영역은 단일 클라우드 공급자 리전 내에 있는 분리된 데이터 센터 그룹으로, 각 그룹은 자체 전력, 냉각 및 네트워킹 인프라를 갖추고 있습니다. 선택한 클라우드 공급자 리전에서 가용영역을 지원하는 경우, Atlas는 클러스터를 가용영역에 자동으로 분산하여 어느 가용영역에 장애가 발생하더라도 클러스터의 나머지 노드가 여전히 리전 서비스를 지원할 수 있도록 합니다. 대부분의 Atlas가 지원하는 클라우드 공급자 리전에는 최소 3개의 가용영역이 있습니다. 이러한 리전은 Atlas UI에 별 아이콘으로 표시됩니다.
각 클라우드 공급자 가용영역 내에서 기본값 데이터 중복성을 제공합니다.
AWS 는 AWS 리전 내 최소 3개의 가용영역에 걸쳐 있는 여러 디바이스에 데이터를 저장합니다.
Microsoft Azure 선택한 리전 의 단일 데이터 센터 내에서 데이터를 세 번 복제하는 로컬 중복 저장 (LRS)를 사용합니다.
Google Cloud는 리전 의 여러 영역에 데이터를 분산합니다.
권장 리전에 대한 추가 정보는 클라우드 공급자 및 리전을 참조하세요.
가장 중요한 애플리케이션의 내결함성을 더욱 개선하려면 가용영역, 리전 또는 공급자의 장애를 견딜 수 있도록 노드, 리전 또는 클라우드 공급자를 추가하여 배포서버를 확장할 수 있습니다. 투표 선택 가능 노드 최대 7개 및 총 노드 50개까지 홀수로 노드 수를 늘릴 수 있습니다. 또한 클러스터를 여러 리전에 배포하면 더 넓은 지역에 걸쳐 가용성을 향상하고, 전체 리전 장애가 발생하여 프라이머리 리전 내의 모든 가용영역이 비활성화되는 경우 자동 페일오버를 사용할 수 있습니다. 클라우드 공급자의 전체 장애를 견디기 위해 클러스터를 여러 클라우드 공급자에 배포하는 경우에도 동일한 패턴이 적용됩니다.
고가용성, 낮은 지연 시간, 컴플라이언스 및 비용 요구 사항을 균형 있게 충족하는 배포서버를 선택하는 방법은 Atlas 배포서버 패러다임 문서를 참조하세요.
배포 패러다임 RTO/RPO 절충안
다음 표에서는 다양한 배포서버 패러다임의 RTO 및 RPO 특성을 비교합니다. majority 쓰기 고려 (write concern) 사용하면 이러한 모든 접근 방식을 통해 RPO = 0 (데이터 손실 없음) 및 RTO를 몇 초 만에 달성할 수 있습니다. 단점은 배포서버 복잡성과 클러스터 비용 에 있습니다.
배포 패러다임 | 실패 시나리오 포함 | 일반 RTO | RPO(과반수 쓰기 고려 (write concern) 포함) | 상대적 복잡성 | 상대적 클러스터 비용 |
|---|---|---|---|---|---|
단일 리전 배포서버 (1 리전 의 3 노드) | 단일 리전 내의 노드 또는 AZ 장애 | 초(자동 페일오버) | 0 (데이터 손실 없음) | 낮은 | $ |
멀티 리전, 단일 클라우드 | 한 지역의 AZ 또는 리전 장애 | 초(자동 페일오버) | 0 (데이터 손실 없음) | 중간 | $$ |
멀티 리전, 다중 지역 | 여러 지역에 걸친 리전 또는 지리적 장애 | 초(자동 페일오버) | 0 (데이터 손실 없음) | 중간-높음 | $$–$$$ |
멀티 클라우드(2-3 제공자) | 한 제공자 에게 영향을 미치는 클라우드 공급자 또는 멀티 리전 장애 | 초(자동 페일오버) | 0 (데이터 손실 없음) | 높음 | $$$ |
실수로 인한 클러스터 삭제 방지
종료 방지 기능을 활성화해 클러스터가 실수로 종료되지 않도록 하고, 백업에서 복원할 때 가동 중단 시간이 발생하지 않도록 할 수 있습니다. 종료 보호가 활성화된 클러스터를 삭제하려면 먼저 종료 보호를 비활성화해야 합니다. 기본적으로 Atlas는 모든 클러스터에 대해 종료 보호를 비활성화합니다.
종료 방지는 IaC 도구를 사용하여 재배포로 인해 새 인프라가 프로비저닝되지 않도록 할 때 특히 중요합니다.
자동 페일오버 테스트
애플리케이션 프로덕션에 배포 전에 자동 노드 페일오버가 필요한 다양한 시나리오를 시뮬레이션하여 이러한 이벤트에 대한 대비를 측정하는 것이 좋습니다. With Atlas, you can 복제본 세트에 대한 프라이머리 노드 페일오버 테스트 하고 멀티 리전 배포서버 위한 리전 중단을 시뮬레이션 할 수 있습니다.
majority 쓰기 고려 사용
MongoDB에서는 쓰기 고려를 사용하여 쓰기 작업에 대해 요청되는 확인 수준을 지정할 수 있습니다. Atlas의 기본 쓰기 고려는 majority입니다. 이는 Atlas가 성공을 보고하기 전에 클러스터의 절반 이상의 노드에 데이터가 복제되어야 함을 의미합니다. 2와 같은 명확한 숫자 값 대신 majority를 사용하면 일시적인 노드 장애가 발생할 때 Atlas가 자동으로 더 적은 수의 노드에 복제를 요구하도록 조정하여 자동 페일오버 후에도 쓰기를 계속할 수 있습니다. 또한 모든 환경에서 일관적인 설정을 제공하므로, 테스트 환경에 노드가 3개 있든 운영 환경에 노드가 여러 개 있든 관계없이 연결 문자열이 동일하게 유지됩니다.
재시도 가능 데이터베이스 읽기 및 쓰기 구성
Atlas는 재시도 가능 읽기 및 재시도 가능 쓰기 작업을 지원합니다. 이 기능을 활성화하면 Atlas는 애플리케이션이 일시적으로 정상적인 기본 노드를 찾을 수 없는 일시적인 네트워크 오류와 복제본 세트 투표를 처리하기 위한 보호 장치로 읽기 및 쓰기 작업을 한 번 재시도합니다. 재시도 가능 쓰기에는 승인된 쓰기 고려가 필요하며, 쓰기 고려는{w: 0}일 수 없습니다.
리소스 사용률 모니터링 및 계획
리소스 용량 문제를 방지하려면 리소스 사용률을 모니터링하고 정기적인 용량 계획 세션을 갖는 것이 좋습니다. MongoDB의 Professional Services에서 이러한 세션을 제공합니다. 리소스 용량 문제를 복구하는 방법에 대한 권장사항은 리소스 용량 재해 복구 계획을 참조하세요.
리소스 사용률에 대한 경고 및 모니터링 모범 사례는 Atlas 모니터링 및 경고 지침을 참조하세요.
MongoDB 버전 변경 계획
새로운 기능과 향상된 보안 보장을 활용하려면 최신 MongoDB 버전을 실행하는 것이 좋습니다. 현재 사용 중인 버전이 지원 종료에 도달하기 전에 항상 최신 MongoDB 주요 버전으로 업그레이드해야 합니다.
MongoDB Atlas UI를 사용하는 MongoDB 버전은 다운그레이드할 수 없습니다. 따라서 주요 버전 업그레이드를 계획하고 실행할 때, 업그레이드 과정에서 발생할 수 있는 문제를 방지하기 위해 MongoDB의 Professional Services 또는 기술 서비스에 문의하는 것이 좋습니다.
유지 관리 기간 구성
Atlas는 예정된 유지 관리 동안 한 번에 하나의 노드에 롤링 방식으로 업데이트를 적용하여 가동 시간을 유지합니다. 이 프로세스가 진행되는 동안 유지 관리를 위해 현재 프라이머리가 오프라인으로 전환될 때마다 Atlas는 자동 복제본 세트 투표를 통해 새로운 프라이머리를 선택합니다. 이는 계획되지 않은 프라이머리 노드 장애에 대한 응답으로 자동 페일오버 중에 진행되는 것과 동일한 프로세스입니다.
업무 상 중요한 시간 중에 유지 관리 관련 복제본 세트 투표가 진행되는 것을 방지하려면 프로젝트에 대해 사용자 지정 유지 관리 기간을 구성하는 것이 좋습니다. 유지 관리 기간 설정에서 보호 시간을 설정하여 표준 업데이트가 시작되지 않는 일일 시간 구간을 정의할 수도 있습니다. 표준 업데이트는 클러스터 재시작이나 재동기화를 포함하지 않습니다.
자동화 예시: Atlas 고가용성
다음 예제에서는 자동화3 위한 Atlas 도구를 사용하여 단일 리전, 노드 복제본 세트/샤드 배포서버 토폴로지 구성합니다.
이러한 예시는 다음을 포함한 다른 권장 구성에도 적용됩니다.
개발/테스트 환경을 위해 클러스터 계층을
M10으로 설정합니다. 애플리케이션 크기에 맞는 권장 클러스터 계층을 알아보려면 클러스터 크기 가이드를 참조하세요.단일 리전, 3-노드 복제본 세트/샤드 배포 토폴로지
이 예제에서는 Amazon Web Services, Azure 및 Google Cloud Platform 서로 바꿔서 사용합니다. 이 세 가지 cloud 제공자 중 하나를 사용할 수 있지만 cloud 제공자 와 일치하도록 리전 이름을 변경해야 합니다. cloud 제공자 및 해당 리전에 대해 학습 클라우드 제공자를 참조하세요.
중간 규모 애플리케이션을 위해 클러스터 계층을
M30으로 설정합니다. 애플리케이션 크기에 맞는 권장 클러스터 계층을 알아보려면 클러스터 크기 가이드를 참조하세요.단일 리전, 3-노드 복제본 세트/샤드 배포 토폴로지
이 예제에서는 Amazon Web Services, Azure 및 Google Cloud Platform 서로 바꿔서 사용합니다. 이 세 가지 cloud 제공자 중 하나를 사용할 수 있지만 cloud 제공자 와 일치하도록 리전 이름을 변경해야 합니다. cloud 제공자 및 해당 리전에 대해 학습 클라우드 제공자를 참조하세요.
참고
Atlas CLI로 리소스를 생성하기 전에 다음을 수행해야 합니다.
의단계에 따라 Atlas CLI Programmatic Use 에서 연결합니다.
프로젝트당 하나의 배포 생성
개발 및 테스트 환경에서 각 프로젝트에 대해 다음 명령을 실행합니다. 다음 예시에서는 ID와 이름을 사용자의 값으로 변경합니다.
참고
다음 예시에서는 개발 및 테스트 환경에서 비용을 관리하는 데 도움이 되는 자동 확장을 사용하지 않습니다. 스테이징 및 프로덕션 환경에서는 자동 확장을 활성화해야 합니다. 자동 확장을 활성화하는 예시는 '스테이징 및 프로덕션 환경' 탭을 참조하세요.
atlas clusters create CustomerPortalDev \ --projectId 56fd11f25f23b33ef4c2a331 \ --region EASTERN_US \ --members 3 \ --tier M10 \ --provider GCP \ --mdbVersion 8.0 \ --diskSizeGB 30 \ --tag bu=ConsumerProducts \ --tag teamName=TeamA \ --tag appName=ProductManagementApp \ --tag env=dev \ --tag version=8.0 \ --tag email=marissa@example.com \ --watch
스테이징 및 프로덕션 환경의 경우 각 프로젝트에 대해 다음 cluster.json 파일을 생성합니다. ID와 이름을 사용자의 값으로 변경하세요.
{ "clusterType": "REPLICASET", "links": [], "name": "CustomerPortalProd", "mongoDBMajorVersion": "8.0", "replicationSpecs": [ { "numShards": 1, "regionConfigs": [ { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 7, "providerName": "GCP", "regionName": "EASTERN_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } } ], "zoneName": "Zone 1" } ], "tag" : [{ "bu": "ConsumerProducts", "teamName": "TeamA", "appName": "ProductManagementApp", "env": "Production", "version": "8.0", "email": "marissa@example.com" }] }
cluster.json 파일을 생성한 후 각 프로젝트에 대해 다음 명령을 실행합니다. 이 명령은 cluster.json 파일을 사용하여 클러스터를 생성합니다.
atlas cluster create --projectId 5e2211c17a3e5a48f5497de3 --file cluster.json
이 예시에 대한 추가 구성 옵션과 정보는 Atlas 클러스터 생성 명령을 참조하세요.
참고
Terraform으로 리소스를 생성하기 전에 다음을 수행해야 합니다.
중요
다음 예시에서는 MongoDB Atlas Terraform 제공자 버전 2.x(~> 2.2)를 사용합니다. 제공자 버전 1.x에서 업그레이드하는 경우 2.0.0 업그레이드 가이드에서 호환성이 손상되는 변경 및 마이그레이션 단계를 참조하세요. 이 예시에서는 mongodbatlas_advanced_cluster 리소스를 v2.x 구문과 함께 사용합니다.
프로젝트 및 배포 생성
개발 및 테스트 환경의 경우 각 애플리케이션 및 환경 쌍에 대해 다음 파일을 생성합니다. 각 애플리케이션 및 환경 쌍에 대한 파일을 자체 디렉토리 에 배치합니다. 값을 사용하도록 ID와 이름을 변경합니다.
main.tf
# Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalDev" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version # MongoDB recommends enabling auto-scaling # When auto-scaling is enabled, Atlas may change the instance size, and this use_effective_fields # block prevents Terraform from reverting Atlas auto-scaling changes use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Test" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.0.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
참고
멀티 리전 클러스터를 생성하려면 각 리전을 자체 region_configs 객체로 지정하고 이를 replication_specs 객체에 중첩합니다. priority 필드는 내림차순으로 정의되어야 하며 다음 예시와 같이 7과 1 사이의 값으로 구성되어야 합니다.
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Dev" environment = "dev" cluster_instance_size_name = "M10" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
파일을 생성한 후 각 애플리케이션과 환경 쌍의 디렉토리로 이동하여 다음 명령을 실행하여 Terraform을 초기화합니다.
terraform init
Terraform 계획을 보려면 다음 명령을 실행합니다.
terraform plan
애플리케이션 및 환경 쌍에 대해 하나의 프로젝트와 하나의 배포를 생성하려면 다음 명령을 실행합니다. 명령은 파일과 MongoDB & HashiCorp Terraform을 사용하여 프로젝트와 클러스터를 생성합니다.
terraform apply
메시지가 표시되면 yes를 입력하고 Enter 키를 눌러 구성을 적용합니다.
스테이징 및 프로덕션 환경의 경우 각 애플리케이션과 환경 쌍에 대해 다음 파일을 생성하세요. 각 애플리케이션과 환경 쌍의 파일은 별도의 디렉토리에 배치하세요. ID와 이름을 사용자의 값으로 변경하세요.
main.tf
# Create a Group to Assign to Project resource "mongodbatlas_team" "project_group" { org_id = var.atlas_org_id name = var.atlas_group_name usernames = [ "user1@example.com", "user2@example.com" ] } # Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Assign the team to project with specific roles resource "mongodbatlas_team_project_assignment" "project_team" { project_id = mongodbatlas_project.atlas-project.id team_id = mongodbatlas_team.project_group.team_id role_names = ["GROUP_READ_ONLY", "GROUP_CLUSTER_MANAGER"] } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalProd" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 disk_size_gb = var.disk_size_gb } auto_scaling = { disk_gb_enabled = var.auto_scaling_disk_gb_enabled compute_enabled = var.auto_scaling_compute_enabled compute_max_instance_size = var.compute_max_instance_size } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Production" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
참고
멀티 리전 클러스터를 생성하려면 각 리전을 고유한 region_configs 객체에 지정하고, 이를 replication_specs 객체에 중첩시킵니다. 다음 예시를 참조하세요.
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" environment = "prod" cluster_instance_size_name = "M30" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0" atlas_group_name = "Atlas Group"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
파일을 생성한 후 각 애플리케이션과 환경 쌍의 디렉토리로 이동하여 다음 명령을 실행하여 Terraform을 초기화합니다.
terraform init
Terraform 계획을 보려면 다음 명령을 실행합니다.
terraform plan
애플리케이션 및 환경 쌍에 대해 하나의 프로젝트와 하나의 배포를 생성하려면 다음 명령을 실행합니다. 명령은 파일과 MongoDB & HashiCorp Terraform을 사용하여 프로젝트와 클러스터를 생성합니다.
terraform apply
메시지가 표시되면 yes를 입력하고 Enter 키를 눌러 구성을 적용합니다.
이 예시에 대한 더 많은 구성 옵션 및 정보는 MongoDB & HashiCorp Terraform을 참조하세요.