重要
$rankFusion MongoDB 8.0 以上を使用する配置でのみ使用できます。
定義
$rankFusion$rankFusion最初にすべての入力パイプラインを個別に実行し、次に重複を除外して、入力パイプラインの結果を最終的にランク付けされた結果セットに結合します。$rankFusionは、入力ドキュメントが入力パイプラインに現れるランクとパイプラインの重み に基づいて、ランク付けされたドキュメントのセットを出力します。このステージでは、レプリカ ランク統合アルゴリズムを使用して、入力パイプラインの合計結果をランク付けします。$rankFusionを使用して、複数の条件に基づいて単一のコレクション内のドキュメントを検索し、指定されたすべての条件で要素が一致する最終順位結果セットを取得します。
構文
このステージの構文は、次のとおりです。
{ $rankFusion: { input: { pipelines: { <myPipeline1>: <expression>, <myPipeline2>: <expression>, ... } }, combination: { weights: { <myPipeline1>: <numeric expression>, <myPipeline2>: <numeric expression>, ... } }, scoreDetails: <bool> } }
コマンドフィールド
$rankFusion は、次のフィールドがあります。
フィールド | タイプ | 説明 |
|---|---|---|
| オブジェクト |
|
input.pipelines | オブジェクト | |
| オブジェクト | 任意。 |
combination.weights | オブジェクト | 任意。 重みを指定しない場合、デフォルト値は 1 です。 |
| ブール値 | デフォルトは false です。 |
動作
コレクション
$rankFusion は 1 つのコレクションでのみ使用できます。この集計ステージは、データベーススコープでは使用できません。
De-Duplication
$rankFusion は、最終出力の複数の入力パイプラインにわたる結果の重複を排除します。一意の各入力ドキュメントは、ドキュメントが入力パイプライン出力に表示される回数に関係なく、$rankFusion 出力に最大 1 回表示されます。
入力パイプライン
各 inputパイプラインは、選択パイプラインとランク付けパイプラインの両方である必要があります。
選択パイプライン
選択パイプラインは、検索後に変更を実行せずにコレクションからドキュメントのセットを検索します。$rankFusion は異なる入力パイプライン間でドキュメントを比較します。このため、すべての入力パイプラインが同じ変更されていないドキュメントを出力する必要があります。
注意
$rankFusion を使用して検索するドキュメントを変更する場合は、$rankFusion ステージの後にそれらの変更を行います。
選択パイプラインには、次のステージのみを含める必要があります。
ランク付けされたパイプライン
ランク付けされたパイプラインはドキュメントをソートまたは順序付けします。$rankFusion は、ランク付けされたパイプライン結果の順序を使用して出力ランキングに影響します。ランク付けされたパイプラインは、次のいずれかの条件を満たす必要があります。
次の順序付けられたステージのいずれかから始まります。
明示的な
$sortステージが含まれています。
入力パイプライン名
input のパイプライン名は次の制限を満たす必要があります。
空の文字列ではない
で開始しないでください
$string のどこにも ASCII null 文字区切り文字
\0を含めることはできません次を含めることはできません:
.
整数ランク統合(RRF)計算式
$rankFusion は、 先数ランク統合(RLF)式 に従って結果を並べ替えます。このステージでは、各ドキュメントの SRF スコアが 出力結果の scoreメタデータフィールドに配置されます。SRF 式では、次の要因を組み合わせてドキュメントをランク付けします。
入力パイプラインへのドキュメントの配置の結果
ドキュメントが異なる入力パイプラインに表示される回数
入力パイプラインの
weights。
例、ドキュメントが複数のパイプライン結果セットでランキングの高い場合、そのドキュメントの SRF スコアは、そのドキュメントが一部の入力パイプラインで同じランキングを使用しているが存在しない(またはランキングが低い場合)よりも高い値になります。他のパイプラインでは
整数ランク統合(SRF)式は、次の 算術操作と同等です。

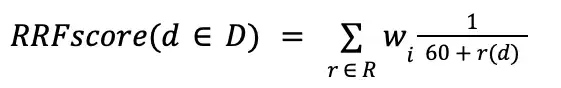
注意
この式では、60 はMongoDBによって決定された区別値パラメーターです。
以下の表には、ARF 式が使用する変数が含まれています。
変数 | 説明 |
|---|---|
D | 操作全体の結果ドキュメントのセット。 |
d | SRF スコアが計算されるドキュメント。 |
R |
|
r(d) | この入力パイプライン内のドキュメント |
w |
|
合計内の各タームは、input パイプラインのいずれかにおけるドキュメントd の出現を表します。d の合計 RTF スコアは、d が表示されるすべての入力パイプラインにおけるこれらの各タームの合計です。
SRF 計算の例
1 つの $search と 1 つの $vectorSearch 入力パイプラインを持つ $rankFusionパイプラインステージを考えてみましょう。
すべての入力パイプラインは同じ 3 ドキュメントを出力します(Document1、Document2、Document3)。
$searchパイプラインは、ドキュメントを次の順序でランク付けします。
Document3Document2Document1
$vectorSearchパイプラインは、ドキュメントを次の順序でランク付けします。
Document1Document2Document3.
rankFusion は、次の操作を通じて Document1 の SRF スコアを計算します。
RRFscore(Document1) = 1/(60 + search_rank_of_Document1) + (1/(60 + vectorSearch_rank_of_Document1)) RRFscore(Document1) = 1/63 + 1/61 RRFscore(Document1) = 0.0322664585
Document1 の scoreメタデータフィールドは0.0322664585 です。
スコア詳細
scoreDetails を true に設定すると、$rankFusion は各ドキュメントに対して scoreDetailsメタデータフィールドを作成します。scoreDetailsフィールドには最終ランキングに関する情報が含まれています。
注意
scoreDetails を true に設定すると、$rankFusion は各ドキュメントの scoreDetailsメタデータフィールドを設定しますが、scoreDetails メタフィールドは自動的に出力しません。
scoreDetailsメタデータフィールドを表示するには、次のいずれかを行う必要があります。
$rankFusionの後に$projectステージを使用してscoreDetailsフィールドをプロジェクト$rankFusionの後に$addFieldsステージを使用して、パイプライン出力にscoreDetailsフィールドを追加する
scoreDetailsフィールドには次のサブフィールドが含まれています。
フィールド | 説明 |
|---|---|
| このドキュメントの RTF スコアの数値。 |
|
|
| このドキュメントを出力する入力パイプラインに関する情報が各配列エントリに含まれている配列。 |
detailsフィールド内の各配列エントリには、次のサブフィールドが含まれています。
フィールド | 説明 |
|---|---|
| このドキュメントを出力する入力パイプラインの名前。 |
| 入力パイプラインにおけるこのドキュメントのランク。他のパイプラインパイプラインステージ出力で返されるドキュメントがこのパイプラインステージの出力に存在しない場合、ランクは |
| 入力パイプラインの重み。 |
| 任意。入力パイプラインがこのドキュメントに対して |
| 任意。入力パイプラインがこのドキュメントの |
| 入力パイプラインの |
警告
MongoDB、scoreDetails の特定の出力形式は保証されません。
例、次のコード ブロックは、$search、$vectorSearch、$match 入力パイプラインを使用した $rankFusion操作の scoreDetailsフィールドを示しています。
{ value: 0.030621785881252923, description: "value output by reciprocal rank fusion algorithm, computed as sum of weight * (1 / (60 + rank)) across input pipelines from which this document is output, from:" details: [ { inputPipelineName: 'search', rank: 2, weight: 1, value: 0.3876491287, description: "sum of:", details: [... omitted for brevity in this example ...] }, { inputPipelineName: 'vector', rank: 9, weight: 3, value: 0.7793490886688232, details: [ ] }, { inputPipelineName: 'match', rank: 10, weight: 1, details: [] } ] }
explain の結果
MongoDB は、$rankFusion 操作を既存の集計ステージのセットに変換し、クエリの実行前に出力結果を計算します。$rankFusion操作の説明結果には、$rankFusion が最終結果を作成するために使用する基礎となる集計ステージの完全な実行が示されています。
例
この例では、埋め込みとテキスト フィールドを持つコレクションを使用しています。コレクションに search と vectorSearch 型のインデックスを作成します。
次のインデックス定義は、インデックス フィールドに対して$search クエリを実行中ために、コレクション内のすべての動的にインデックス可能なフィールドを自動的にインデックス化します。
db.embedded_movies.createSearchIndex( "search_index", { mappings: { dynamic: true } } )
次のインデックス定義は、そのフィールドに対して クエリを実行中ためのコレクション内の$vectorSearch を含むフィールドをインデックスします。
db.embedded_movies.createSearchIndex( "vector_index", "vectorSearch", { "fields": [ { "type": "vector", "path": "<FIELD_NAME>", "numDimensions": <NUMBER_OF_DIMENSIONS>, "similarity": "dotProduct" } ] } );
次の集計パイプラインでは、次の入力パイプラインで $rankFusion を使用します。
パイプライン | 返されたドキュメントの数 | 説明 |
|---|---|---|
| 20 | 埋め込みとして指定されたタームの |
| 20 | 同じタームの全文検索を実行し、結果を 20 ドキュメントに制限します。 |
1 db.embedded_movies.aggregate( [ 2 { 3 $rankFusion: { 4 input: { 5 pipelines: { 6 searchOne: [ 7 { 8 "$vectorSearch": { 9 "index": "<INDEX_NAME>", 10 "path": "<FIELD_NAME>", 11 "queryVector": <QUERY_EMBEDDINGS>, 12 "numCandidates": 500, 13 "limit": 20 14 } 15 } 16 ], 17 searchTwo: [ 18 { 19 "$search": { 20 "index": "<INDEX_NAME>", 21 "text": { 22 "query": "<QUERY_TERM>", 23 "path": "<FIELD_NAME>" 24 } 25 } 26 }, 27 { "$limit": 20 } 28 ], 29 } 30 } 31 } 32 }, 33 { $limit: 20 } 34 ] )
この操作は、次のアクションを実行します。
inputパイプラインを実行します返された結果を組み合わせます
$rankFusionパイプラインの上位 20 結果である最初の 20 ドキュメントを出力します
このページのC#の例では、Atlasサンプルデータセット の sample_mflixデータベースを使用します。MongoDB Atlasクラスターを無料で作成して、サンプルデータセットをロードする方法については、 MongoDB .NET/ C#ドライバーのドキュメントの「 開始 」を参照してください。
次の Movie クラスは、sample_mflix.movies コレクション内のドキュメントをモデル化します。
public class Movie { public ObjectId Id { get; set; } public int Runtime { get; set; } public string Title { get; set; } public string Rated { get; set; } public List<string> Genres { get; set; } public string Plot { get; set; } public ImdbData Imdb { get; set; } public int Year { get; set; } public int Index { get; set; } public string[] Comments { get; set; } [] public DateTime LastUpdated { get; set; } }
注意
パスカルケースの ConventionPack
このページのC# クラスはプロパティ名にパスカルケースを使用していますが、MongoDB コレクションのフィールド名はキャメルケースを使用しています。この違いを考慮するために、アプリケーションが起動する際に次のコードを使用してConventionPackを登録してください。
var camelCaseConvention = new ConventionPack { new CamelCaseElementNameConvention() }; ConventionRegistry.Register("CamelCase", camelCaseConvention, type => true);
MongoDB .NET/ C#ドライバーを使用して $rankFusion ステージを集計パイプラインに追加するには、RankFusion() メソッドを PipelineDefinitionオブジェクトで呼び出します。
次の例を実行中前に、default という名前のMongoDB Searchインデックスを作成する必要があります。アプリケーションに次のコードを含めて、moviesコレクションに検索インデックスを作成します。
var collection = client.GetDatabase("sample_mflix").GetCollection<Movie>("movies"); var index = new BsonDocument { { "mappings", new BsonDocument { { "dynamic", true } } } }; collection.SearchIndexes.CreateOne(index, "default");
次の例では、2 つのパイプライン(searchPlot と searchGenre)を実行し、default検索インデックスを使用して $search 操作を実行するパイプラインステージを作成します。次に、$rankFusion ステージは各 $search パイプラインに割り当てられた重みに基づいて検索結果をランク付けし、順序付けられた結果を返します。パイプラインは、RankFusion() メソッドに渡される RankFusionOptionsインスタンスで ScoreDetails オプションを有効にすることで、返される document に scoreDetailsフィールドを含めます。
var searchPipelines = new Dictionary<string, PipelineDefinition<Movie, Movie>> { { "searchPlot", new EmptyPipelineDefinition<Movie>() .Search( Builders<Movie>.Search.Text(Builders<Movie>.SearchPath.Single(m => m.Plot), "space")) }, { "searchGenre", new EmptyPipelineDefinition<Movie>() .Search( Builders<Movie>.Search.Text(Builders<Movie>.SearchPath.Single(m => m.Genres), "adventure")) } }; var weights = new Dictionary<string, double> { { "searchPlot", 0.4 }, { "searchGenre", 0.6 } }; var pipeline = new EmptyPipelineDefinition<Movie>() .RankFusion(searchPipelines, weights, new RankFusionOptions<Movie> { ScoreDetails = true });
このページのNode.js の例では、Atlasサンプルデータセット の sample_mflixデータベースを使用します。無料のMongoDB Atlas cluster を作成し、サンプルデータセットをロードする方法については、 MongoDB Node.jsドライバーのドキュメントの開始を参照してください。
MongoDB Node.jsドライバーを使用して $rankFusion ステージを集計パイプラインに追加するには、パイプラインオブジェクトで $rankFusion 演算子を使用します。
次の例を実行中前に、default という名前のMongoDB Searchインデックスを作成する必要があります。アプリケーションに次のコードを含めて、moviesコレクションに検索インデックスを作成します。
const index = { name: "default", definition: { mappings: { dynamic: true } } } const result = collection.createSearchIndex(index);
次の例では、2 つのパイプライン(searchPlot とsearchGenre $searchを実行し、default 検索インデックスを使用して 操作を実行するパイプラインステージを作成します。次に、$rankFusion ステージは各 $search パイプラインに割り当てられた重みに基づいて検索結果をランク付けし、順序付けられた結果を返します。$addFields ステージでは、返されるドキュメントに scoreDetailsフィールドが含まれます。次に、この例では集計パイプラインを実行します。
const pipeline = [ { $rankFusion: { input: { pipelines: { searchPlot: [ { $search: { index: "default", text: { query: "space", path: "plot"} } } ], searchGenre: [ { $search: { index: "default", text: { query: "adventure", path: "genres" } } } ] } }, combination: { weights: {searchPlot: 0.6, searchGenre: 0.4} }, scoreDetails: true } }, { $addFields: { scoreDetails: { $meta: "searchScoreDetails" } } } ]; const cursor = collection.aggregate(pipeline); return cursor;