検索拡張生成(RAG)は、大規模言語モデル(llm)を追加のデータで強化して、より正確な応答を生成できるようにするために使用されるアーキテクチャです。MongoDB ベクトル検索を基盤とした検索システムと LLM を組み合わせて、生成系AIアプリケーションに RAG を実装できます。
はじめる
MongoDB ベクトル検索で RAG をすばやく試すには、 MongoDB Search Playground で チャットボット Demo Builder を使用します。詳しくは、検索プレイグラウンドのチャットボット デモ ビルダ を参照してください。
MongoDB Vector Search を使用して独自の RAG システムを実装するには、このページのチュートリアルを参照してください。
RAG を使用する理由
LLM を使用する際、以下の制限事項に直面する可能性があります。
古いデータ: LLM は特定の時点まで静的なデータセットで訓練されます。これは、その知識ベースが限られており、古いデータを使用する可能性があることを意味します。
追加データへのアクセスなし:LLM は、ローカルデータ、パーソナライズされたデータ、またはドメイン固有のデータにアクセスできません。したがって、特定の領域に関する知識が不足している可能性があります。
ハルシネーション:基礎となるデータが不完全または古い場合、LLMは不正確な応答を生成する可能性があります。
RAGを実装するには次の手順を持つことで、これらの制限に対処できます。
取り込み: MongoDBなどのベクトルデータベースにカスタム データをvector embeddingsとして保存します。これにより、最新のパーソナライズされたデータの知識ベースを作成できます。
検索: MongoDB ベクトル検索などの検索ソリューションを使用して、ユーザーの質問に基づいてデータベースからセマンティックに類似したドキュメントを検索します。これらのドキュメントは、TLM に関連するデータを追加します。
生成: LLM にプロンプトを出します。LLM は取得されたドキュメントをコンテキストとして使用し、より正確で関連性の高い応答を生成して、ハルシネーションを減らします。
RAG は、 AI システムがパーソナライズされたドメイン固有の応答を提供できるようにするため、 AI チャットボットを構築するための効果的なアーキテクチャです。本番環境のチャットボットを作成するには、リクエストをルーティングするサーバーを設定し、RAG 実装の上にユーザーインターフェースをビルドします。
MongoDB ベクトル検索と MongoDB Vector Search
MongoDB ベクトル検索で RG を実装するには、 MongoDBにデータを取り込み 、 MongoDB ベクトル検索を使用してドキュメントを検索し、 LM を使用して応答を生成します。このセクションでは、 MongoDB ベクトル検索を使用した基本的な、またはネイティブの RAG実装のコンポーネントについて説明します。段階的な手順については、「 チュートリアル 」を参照してください。
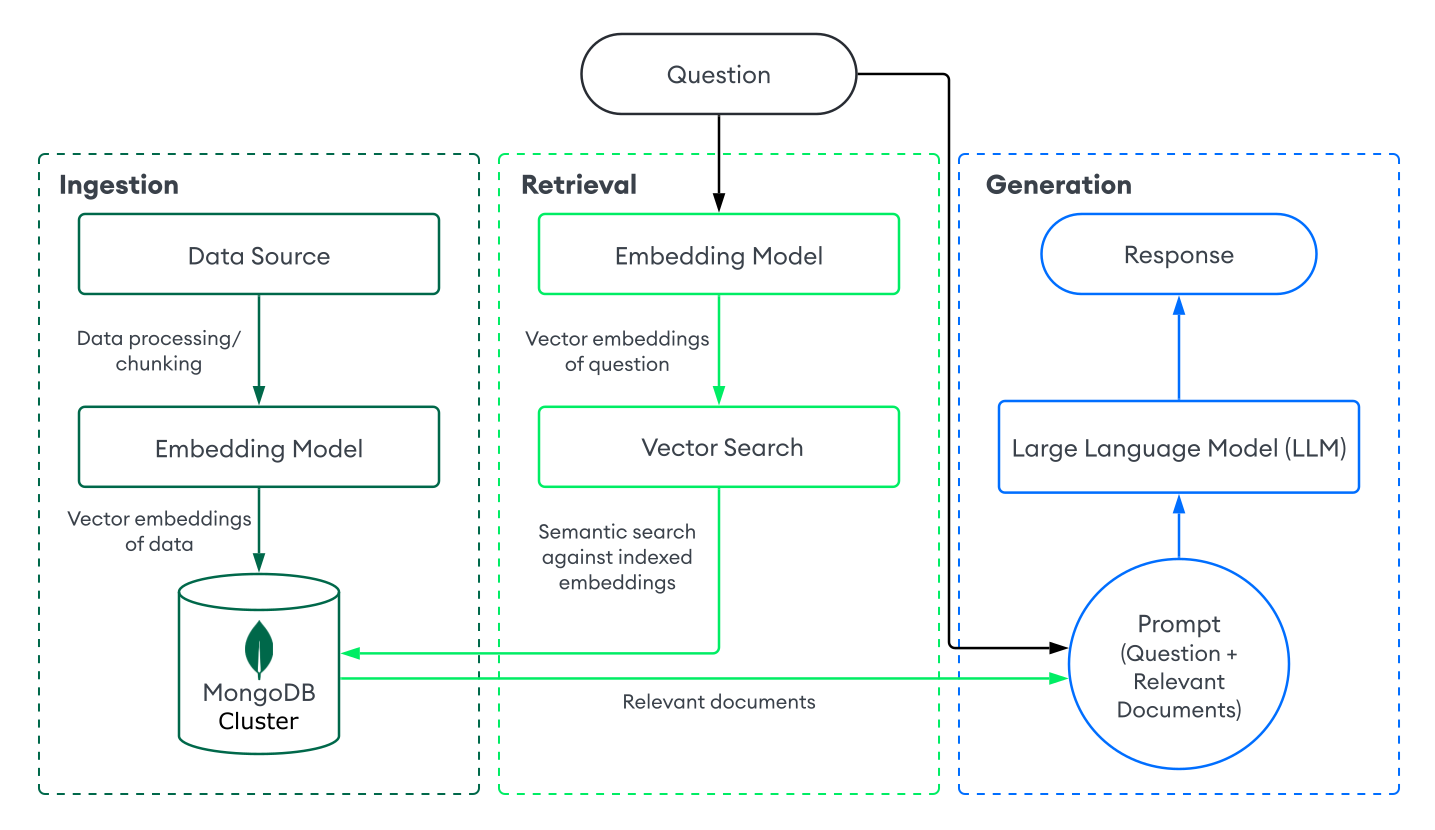
取り込み
RG のデータ取り込みには、カスタム データを処理し、ベクトルデータベースに保存して取得に準備する方法が含まれます。MongoDBをベクトルデータベースとして基本的な取り込みパイプラインを作成するには、次の手順を実行します。
データを準備します。
データをロードし、処理し、チャンク化して、RAG アプリケーション用に準備します。チャンク処理とは、最適な検索のためにデータを小さな単位に分割する処理です。
データをベクトル埋め込みに変換します。
embedding modelを使用してデータをvector embeddingsに変換します。詳細については、 「How to Create vector embeddings Manually」 を参照してください。
データと埋め込みをMongoDBに保存します。
これらの埋め込みをクラスターに保存します。埋め込みは、コレクション内の他のデータと一緒にフィールドとして保存します。
Retrieval
取得システムを構築するには、ベクトルデータベースから最も関連するドキュメントを検索して返すことが含まれ、TLM で増加します。 MongoDB ベクトル検索で関連するドキュメントを検索するには、ユーザーの質問をベクトル埋め込みに変換し、MongoDBコレクション内のデータに対してベクトル検索クエリーを実行し、最も類似した埋め込みを持つドキュメントを検索します。
MongoDB ベクトル検索を使用して基本的な検索を実行するには、次の手順を実行します。
ベクトル埋め込みを含むコレクションにMongoDB ベクトル検索インデックスを定義します。
ユーザーの質問に基づいてドキュメントを取得するには、次のいずれかの方法を選択します。
MongoDB ベクトル検索 を一般的なフレームワークまたはサービスと統合して使用します。これらの統合には、 MongoDB ベクトル検索で検索システムを簡単に構築できる組み込みのライブラリとツールが含まれています。
独自の検索システムをビルドします。独自の関数とパイプラインを定義して、ユースケースに固有のMongoDB ベクトル検索クエリを実行できます。
MongoDB Vector Search を使用して基本的な検索システムを構築する方法については、チュートリアルを参照してください。
生成
応答を生成するには、検索システムを LLM と組み合わせます。ベクトル検索を実行して関連するドキュメントを取得した後、ユーザーの質問と関連するドキュメントをコンテキストとして LLM に提供し、LLM がより正確な応答を生成できるようにします。
LLM に接続するには、次のいずれかの方法を選択します。
MongoDB ベクトル検索 を一般的なフレームワークまたはサービスと統合して使用します。これらの統合には組み込みのライブラリとツールが含まれており、最小限の設定で LM に接続するのに役立ちます。
LLM の API を呼び出します。ほとんどの AI プロバイダーは、応答を生成するために使用できる生成モデルへの API を提供しています。
オープンソース LVM をロードします。 APIキーまたはクレジットがない場合は、アプリケーションからローカルにロードすることで、オープンソースの LVM を使用できます。 実装例については、「 MongoDB ベクトル検索を使用してローカル RAG 実装を構築する 」チュートリアルを参照してください。
Tutorial
次の例は、MongoDB Vector Search を基盤とした検索システムで RAG を実装する方法を示しています。開始するには、ご希望の埋め込みモデル、LLM、およびプログラミング言語を選択します。
次のステップ
その他の RAG チュートリアルについては、次のリソースを参照してください。
一般的な LLM フレームワークとAIサービスを使用して RAG を実装する方法については、 MongoDB AI統合 を参照してください。
Atlas のローカル配置とローカル モデルを使用して RG を実装する方法については、 「 MongoDB ベクトル検索を使用してローカル RAG 実装を構築する 」を参照してください。
ユースケースベースのチュートリアルとインタラクティブPythonノートについては、Docs Notesbook リポジトリ および ジェネレーティブAIユースケースのリポジトリ を参照してください。
AIエージェントを構築し、エージェント RG を実装するには、MongoDBでAIエージェントを構築を参照してください。
結果を向上させる
RG アプリケーションを最適化するには、Voyage AIなどの強力な埋め込みモデルを使用して高品質のベクトル埋め込みを生成していることを確認してください。
さらに、 MongoDB ベクトル検索 は高度な検索システムをサポートします。ベクトルデータをクラスター内の他のデータとシームレスにインデックスできます。これにより、コレクション内の他のフィールドを事前にフィルタリングしたり、セマンティック検索と全文検索結果を組み合わせたハイブリッド検索を実行したりすることで、結果を向上させることができます。
チャンク戦略
チャンクは、埋め込みを生成する前に大きなドキュメントを小さなセグメントに分割します。適切なチャンク戦略により、RAGアプリケーションの取得品質を大幅に向上させることができます。
チャンク戦略は、次の重要な要素で構成されています。
分割手法: 記事の境界、プログラミング言語固有の区切り文字、トークン、セマンティック境界など、チャンクの境界を配置する場所を決定します。
チャンク サイズ: チャンクあたりの文字またはトークンの最大数。
チャンクの重複: 隣接するチャンク間で重複する文字またはトークンの数。オーバーラップは、チャンク境界間でコンテキストを保持するのに役立ちます。
一般的なチャンク戦略には、次のようなものがあります。
戦略 | に最適 |
|---|---|
固定トークン | 統一されたコンテンツ構造を持つシンプルなユースケース。 |
重複のある修正トークン | コンテキストがチャンクの境界にまたがる汎用チャンク。 |
Recursive | 句と文章の境界を保持するテキストドキュメント。 |
言語固有の再帰 | プログラミング言語スニペットを含むコードまたは技術ドキュメント。 |
セマンティック | エッセイや語幹的なコンテンツなど、明確な構造境界がないドキュメント。 |
チャンク戦略を試すには、 MongoDB Search Playground で チャットボット Demo Builder を使用します。これにより、 再帰チャンク と 重複のある固定トークンチャンク が試行できます。
Rhasフレームワークを使用してさまざまなチャンク戦略を評価する実践的なチュートリアルについては、生成AI- 表示リポジトリの チャンク戦略 のドキュメントを参照してください。
次のリソースを使用することもできます。