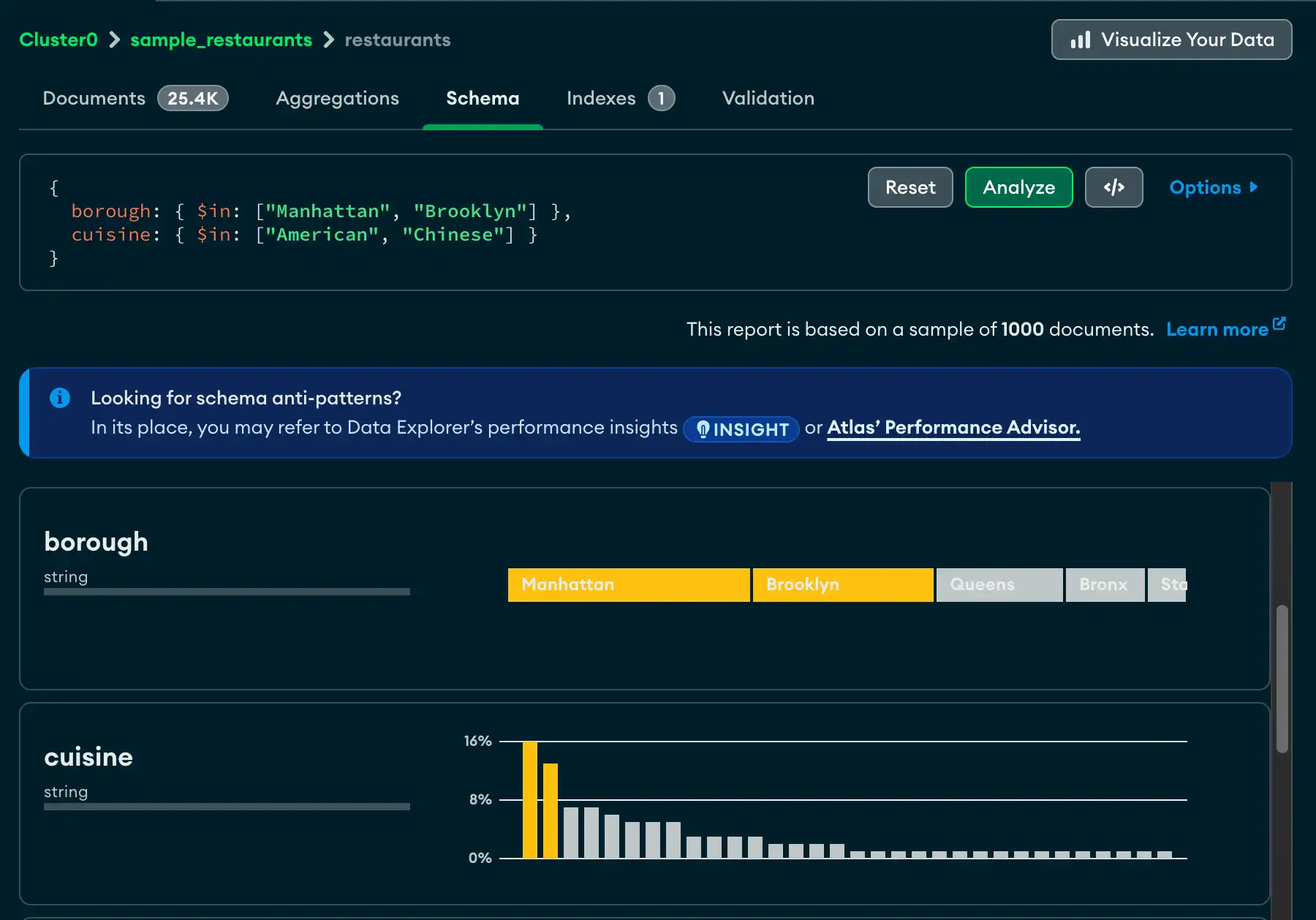
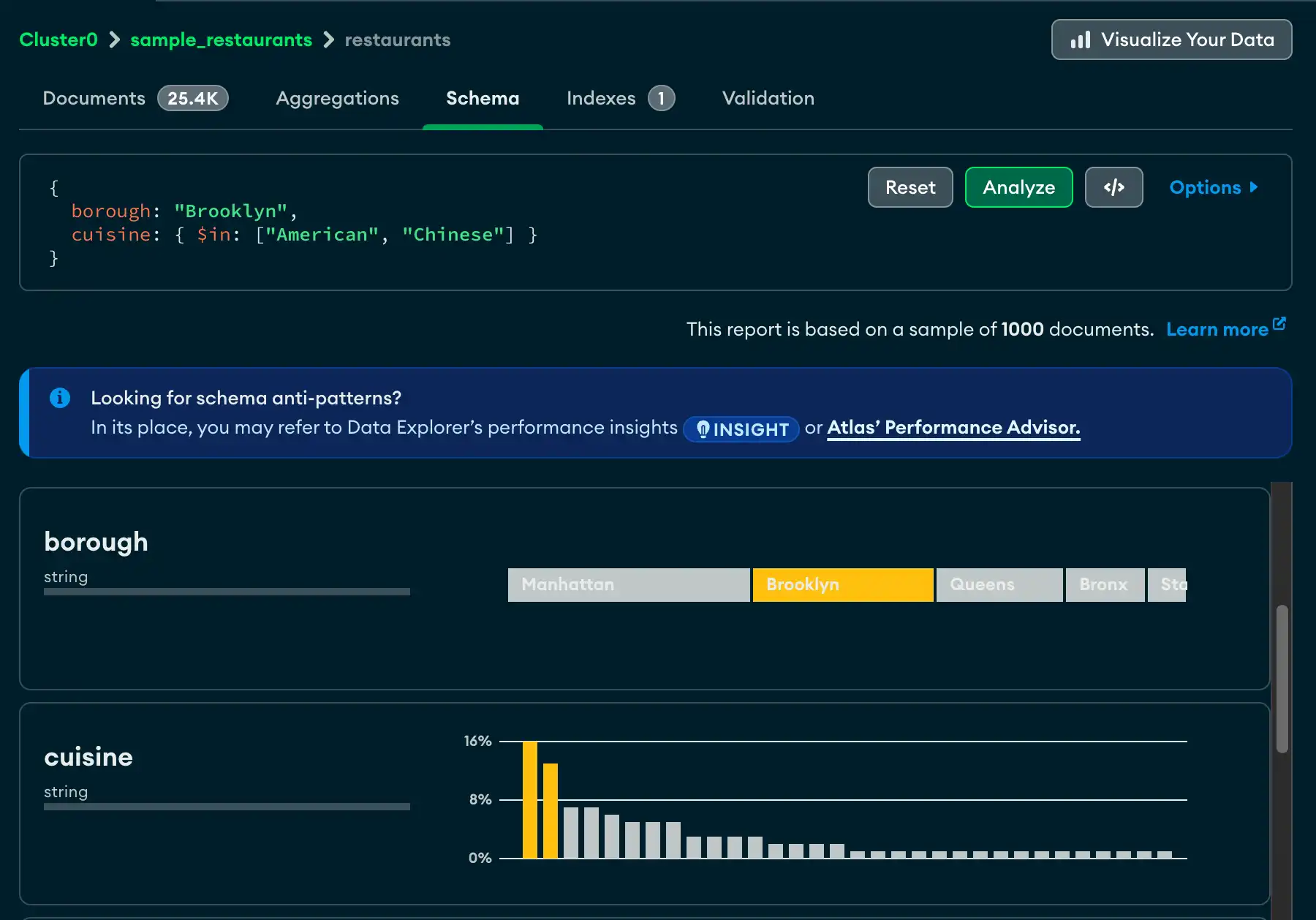
Schema タブには、特定のコレクション内のフィールドのデータ型と形状の概要が表示されます。データベースとコレクションは左側のナビゲーションに表示されます。
概要は、コレクション内のドキュメントをサンプリングしたに基づいています。 スキーマの概要には、日付や整数の最小値と最大値、特定の値の発生頻度、データのカーディナリティなど、フィールドの内容に関する追加データが含まれる場合があります。
MongoDB には 柔軟なスキーマ モデルがあり、一部のフィールドにはドキュメントごとに異なる型のデータが含まれる場合があります。例として、 address という名前のフィールドには、一部のドキュメントでは文字列と整数、他のドキュメントではオブジェクト、またはこれら 3 つすべての組み合わせが含まれる場合があります。
異種フィールドの場合、Schema タブには、フィールド内に含まれるさまざまなデータ型の内訳と、各データ型の割合が表示されます。
例
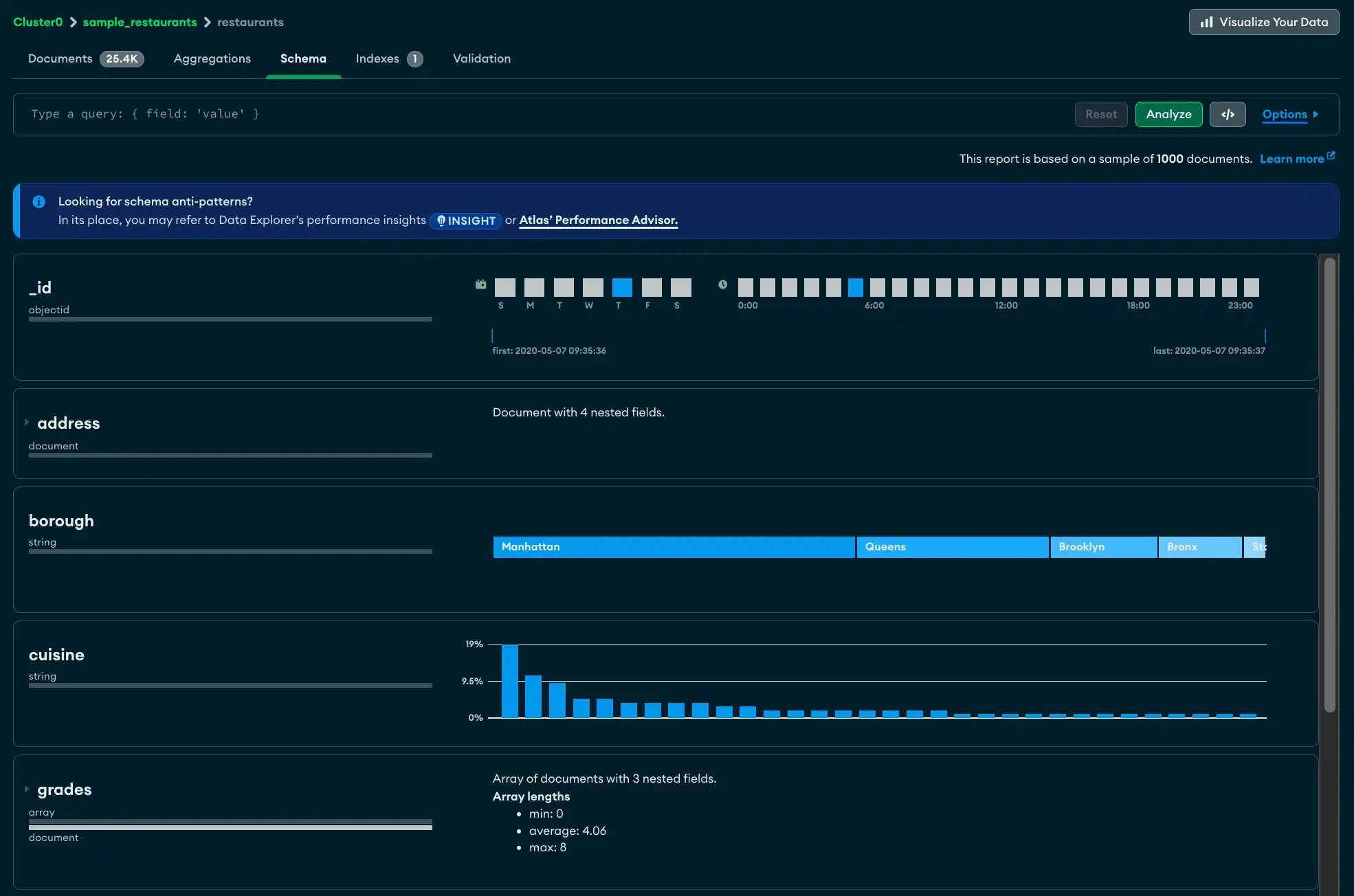
Schema タブの上部には、コレクション内のドキュメントの合計数、ドキュメントの平均サイズ、コレクションが占有するディスク容量の合計など、test.restaurants コレクションのサイズ情報が表示されます。
次のフィールドに詳細が表示されます。
_idフィールドはObjectIdです。各 ObjectId にはタイムスタンプが含まれているため、Atlas にはサンプリングされたドキュメントの作成時間の範囲が表示されます。addressフィールドには 4 つのネストされたフィールドが含まれています。フィールド パネルを展開すると、ネストされた各フィールドの分析が表示されます。boroughフィールドには、レストランが位置する地区を示す string が含まれています。濃度は十分に低いので、Atlas ではフィールドの内容を段階的に示し、最も頻繁に出現する string を左に表示できます。gradesフィールドには、文字列の配列が含まれています。分析は、アレイの長さの最小値、最大値、平均値を示しています。
Schema タブを表示
Atlas で、プロジェクトの Data Explorer ページに移動します。
まだ表示されていない場合は、プロジェクトを含む組織をナビゲーション バーの Organizations メニューで選択します。
まだ表示されていない場合は、ナビゲーション バーの Projects メニューからプロジェクトを選択します。
サイドバーで、 Database見出しの下のData Explorerをクリックします。
Data Explorerが表示されます。
クエリ バー
Schema タブの クエリ バー を使用すると、クエリフィルターを作成して結果セットを制限できます。Options ボタンをクリックして、表示する特定のフィールドや返される結果の数などのクエリ オプションを指定します。
注意
クエリ結果セットが 1000 ドキュメントを超える場合、Atlas では結果のサブセットが表示されます。それ以外の場合、Atlas では結果セット全体が表示されます。
サンプリングの詳細についてはサンプリングを参照してください。


Tip
Schema タブでは、クエリ ビルダを使用してクエリ バーにクエリを入力することもできます。
フィールドの説明
各フィールドについて、Atlas はフィールドに含まれるデータ型と値の範囲に関する概要情報を表示します。データ型と濃度のレベルに応じて、Atlas はヒストグラム、段階的なバー、地図、サンプルデータを表示し、各フィールドに含まれるデータの形状と範囲を把握できるようにします。
1 つのデータ型のフィールド
以下は、date 型のデータを含む last_login というフィールドのデータ型の概要の例です。


複数のデータ型を持つフィールド
複数のデータ型を含むフィールドの場合、Atlas はドキュメント全体のさまざまなデータ型の割合の内訳を表示します。以下の例では、チャートには phone_no というフィールドの内容が表示されており、ドキュメントの 20% が int32 型で、残りの 80% が型 string です。


欠落しているフィールド
コレクションに、すべてのフィールドに値が含まれていないドキュメントが含まれている場合、欠落している値は undefined として表示されます。以下の例では、サンプル文書の 40% で age フィールドに値が記録されていません。


文字列
文字列は 3 つの異なる方法で表示されます。フィールドに完全に一意の string がある場合、Atlas は指定されたフィールドからランダムに選択された string 値を表示します。円形のアップデート アイコンをクリックすると、フィールドからランダムに選択された新しい値のセットが表示されます。


異なる string 値が少ない場合、Atlas は string 値を 1 つのグラデーション バーに表示し、string 値の母集団の割合を示します。


重複する string 値が複数ある場合、Atlas はフィールド内で見つかった各 string の頻度を示すヒストグラムを表示します。


注意
各バーの上にマウスを移動させると、文字列値を示すツールチップが表示される。
数値
数値の表現方法は文字列に似ています。ユニークな番号は、次のように表示されます。


重複番号は、その頻度を示すヒストグラムで表示されます。

日付とオブジェクト ID
日付を表すフィールド(およびタイムスタンプを含む ObjectID データ型を含むフィールド)は、複数の棒グラフに表示されます。上段の 2 つのチャートは、タイムスタンプ値の曜日と時間帯を表している。
下部の単一のグラフには、最初と最後のタイムスタンプの値が表示されます。また、垂直線は最初から最後までの範囲にわたるタイムスタンプの分布を表しています。

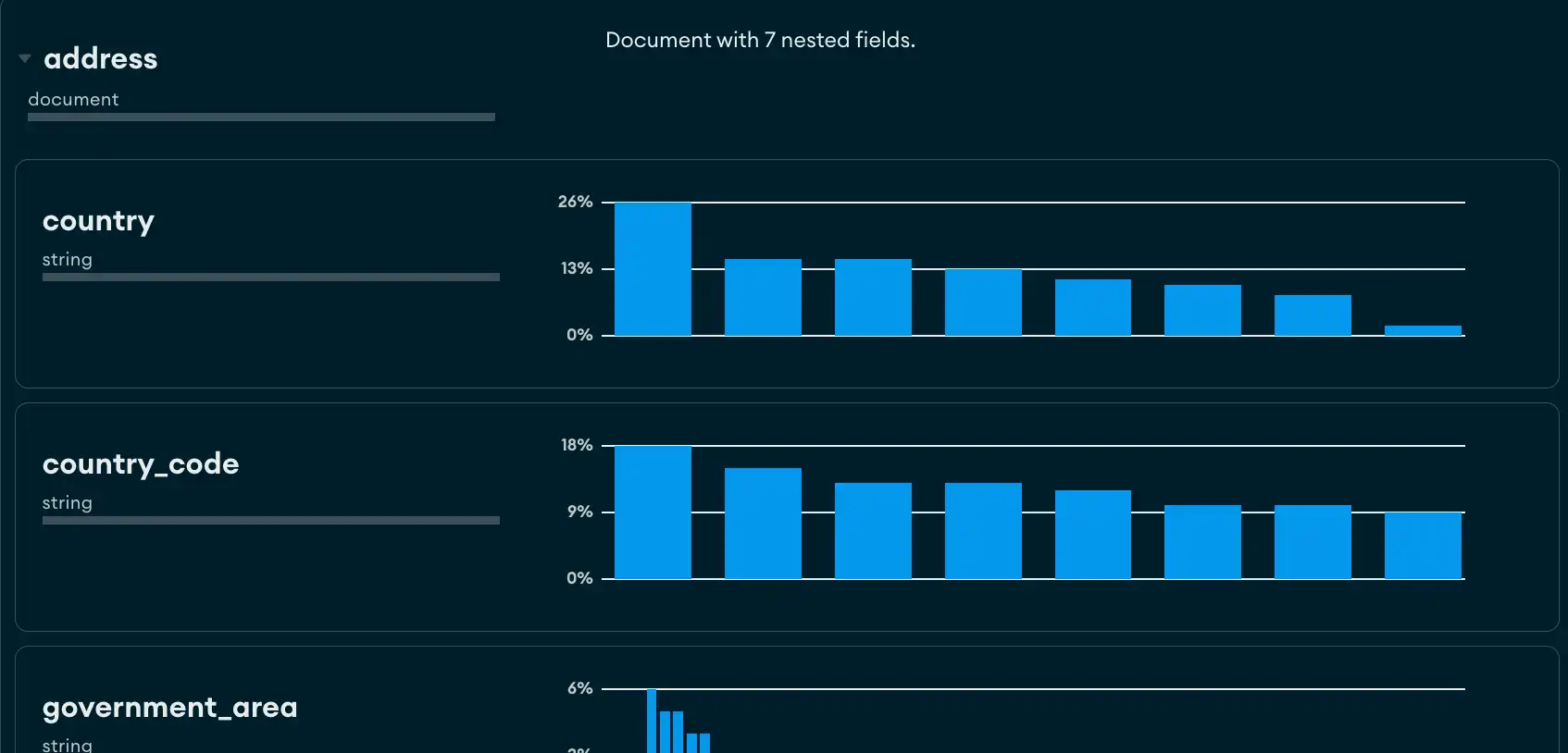
埋め込みドキュメントと配列
サブドキュメントまたは配列を含むフィールドには、その横に小さな三角形が表示され、サブドキュメントまたは配列内に含まれるデータが視覚的に表現されます。


三角形をクリックするとフィールドが展開され、埋め込まれたドキュメントが表示されます。

混合型のチャートを表示
フィールドに型が混在している場合は、type フィールドをクリックすると、各型の異なるグラフを表示できます。以下の例では、age フィールドに文字列値が表示されます。


int32 型をクリックすると、グラフに数値データが表示されます。

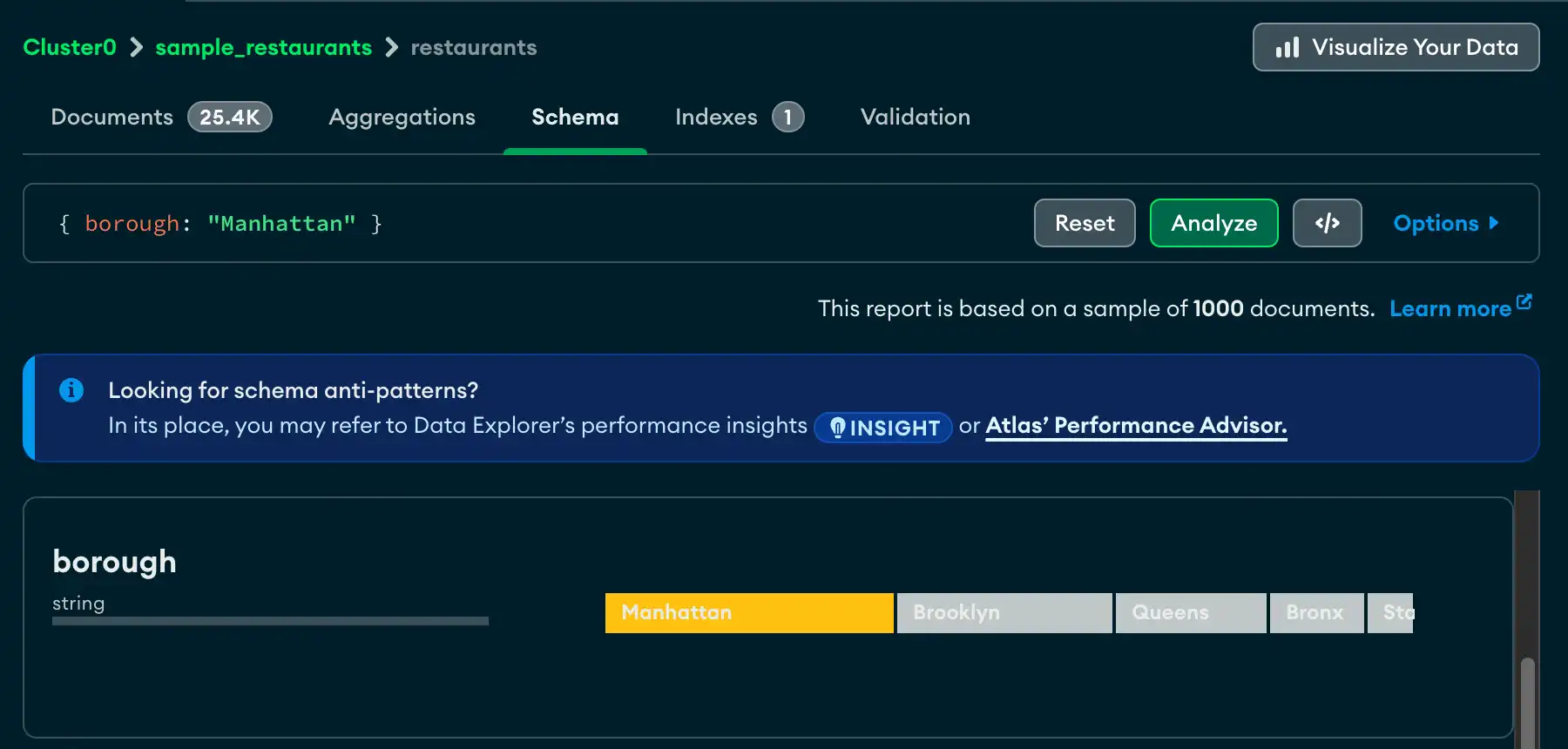
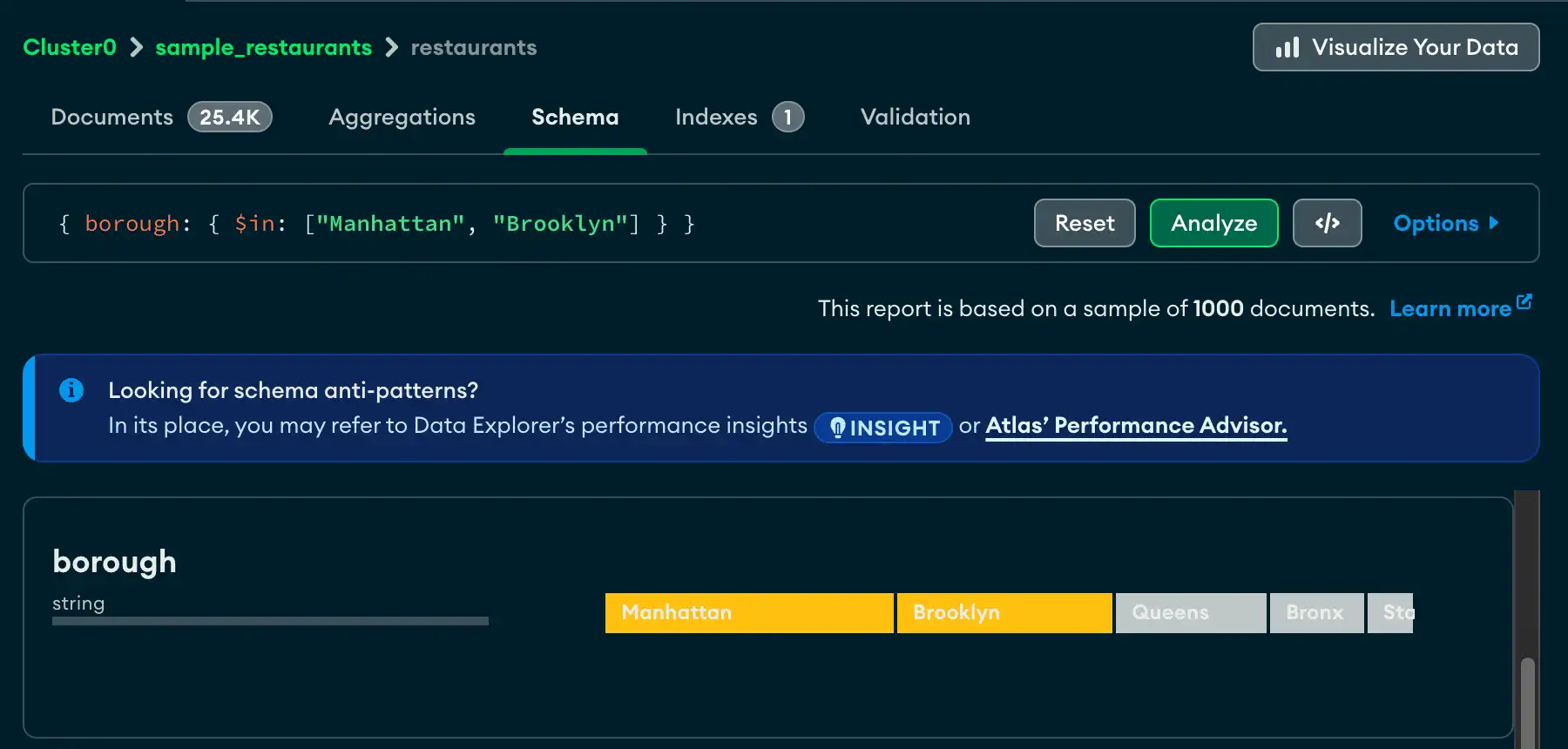
クエリ ビルダ
Schemaタブでは、クエリ バーにフィルターを手動で入力するか、Atlas クエリ ビルダを使用してフィルターを生成できます。クエリ ビルダを使用すると、スキーマ内の 1 つ以上のフィールドからデータ要素を選択し、選択した要素に一致するクエリを作成できます。
Tip
クリック可能なクエリ ビルダを使用して最初のクエリフィルターを作成し、生成されたフィルターを正確な要件に合わせて手動で編集できます。
次の手順では、クエリ バーを使用して複雑なクエリを作成する手順について説明します。


トラブルシューティング
スキーマの分析がタイムアウトする場合は、分析対象のコレクションが非常に大きいために、分析が完了する前に MongoDB が操作を停止している可能性があります。操作時間が完了するまで、MAX TIME MS の値を増やしてください。
MAX TIME MSの値を増やすには、次の手順に従います。
クエリバーで、Options を展開します。
![[オプション] ボタンは、クエリ バーの右側、[分析] ボタンの横にあります。]()
コレクションに合わせて MAX TIME MS の値を増やします。MAX TIME MS のデフォルトは 60000 ミリ秒、つまり 60 秒ですが、大規模なコレクションの分析には数十秒かかる場合があります。

![[オプション] ボタンは、クエリ バーの右側、[分析] ボタンの横にあります。](/ja-jp/docs/atlas/static/e3aece520d0a3cbb8d4a8869ea514a55/43e41/max-time-ms.webp)
MAX TIME MS の値を増やしたら、[Analyze] をクリックしてスキーマ分析を再試行します。