Esta página explora los resultados de nuestro benchmark de rendimiento de MongoDB Vector Search.
Resumen de resultados
Con 15.3M de vectores que utilizan
voyage-3-largeincrustaciones en 2048 dimensiones, MongoDB Vector Search con la cuantificación configurada mantiene una precisión del 90-95% con una latencia de query inferior a 50ms.La cuantización binaria es más lenta cuando el número de candidatos solicitados se cuenta por cientos, debido al costo adicional de volver a puntuar con vectores de fidelidad completa. Sin embargo, a ~1/4 del precio de servir el índice, podría ser una opción preferible para muchas cargas de trabajo a gran escala.
Recomendamos más de 1024 dimensiones al ejecutar cargas de trabajo más grandes con cuantización.
Los filtros selectivos pueden mejorar o empeorar el rendimiento dependiendo del valor seleccionado para
numCandidates.El costo adicional de recalificación para la cuantización binaria se manifiesta en un rendimiento reducido al ejecutar cargas de trabajo altamente concurrentes.
El particionamiento mejora ligeramente el rendimiento, pero seguimos recomendando escalar la cantidad de Nodos de Búsqueda o el número de núcleos disponibles en un Nodo de Búsqueda para mejorar el rendimiento.
Recuperación y análisis de latencia en referencia a un benchmark multidimensional
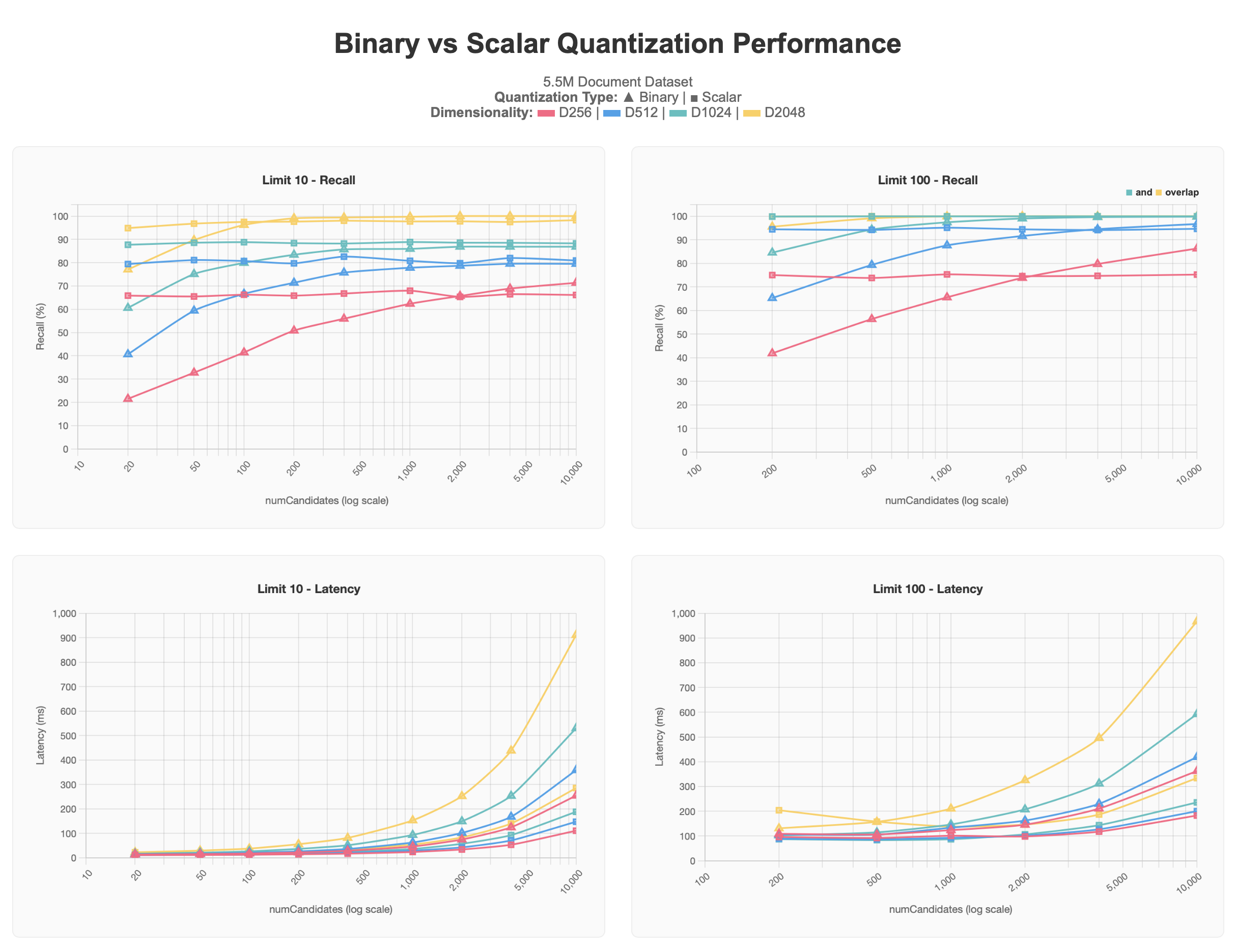
El primer conjunto de resultados muestra las pruebas que ejecutamos contra un conjunto de datos de documentos 5.5M que contiene múltiples dimensionalidades de vectores (256, 512, 1024, 2048), todos producidos utilizando voyage-3-large, dentro de cada documento.
Para ver la gráfica completa, consulta Artefacto Claude.
Los resultados de cuantificación escalar comienzan todos en niveles más altos que los resultados de cuantificación binaria, pero se mantienen en su nivel asintótico incluso cuando numCandidates aumenta. Por el contrario, las consultas de cuantificación binaria producen resultados más precisos a medida que se solicitan más numCandidates, acercándose a la asíntota de la cuantificación escalar y, en algunos casos, superándola, a costa de una mayor latencia, especialmente por encima de numCandidates de 1000.
Generalmente, los valores más bajos de limit son más difíciles de acercar a una precisión del 100%, ya que los mejores resultados son más difíciles de localizar y, a menudo, podría requerirse un numCandidates más alto para lograr mejores resultados. Esto es especialmente observable en el gráfico de cuantización binaria. También podemos observar que los vectores de baja dimensionalidad 256d y 512d sufren especialmente a gran escala con cualquier forma de cuantización. 256d nunca supera el 70% de recuerdo y 512d nunca supera el 80% de recuerdo en el límite de 10 pruebas, siendo necesario que el límite de 100 requiera valores más altos numCandidates para alcanzar la zona objetivo del 90-95%.
Dada esta información, determinamos que cuando se trabaja con un gran conjunto de datos, recomendamos tener una dimensionalidad de al menos 1024d y aplicar cuantización para escalar en lugar de tener menor dimensionalidad y no usar cuantización, y la cantidad de vectores solicitados para el caso de uso también juega un papel.
Resultados de benchmark más grandes
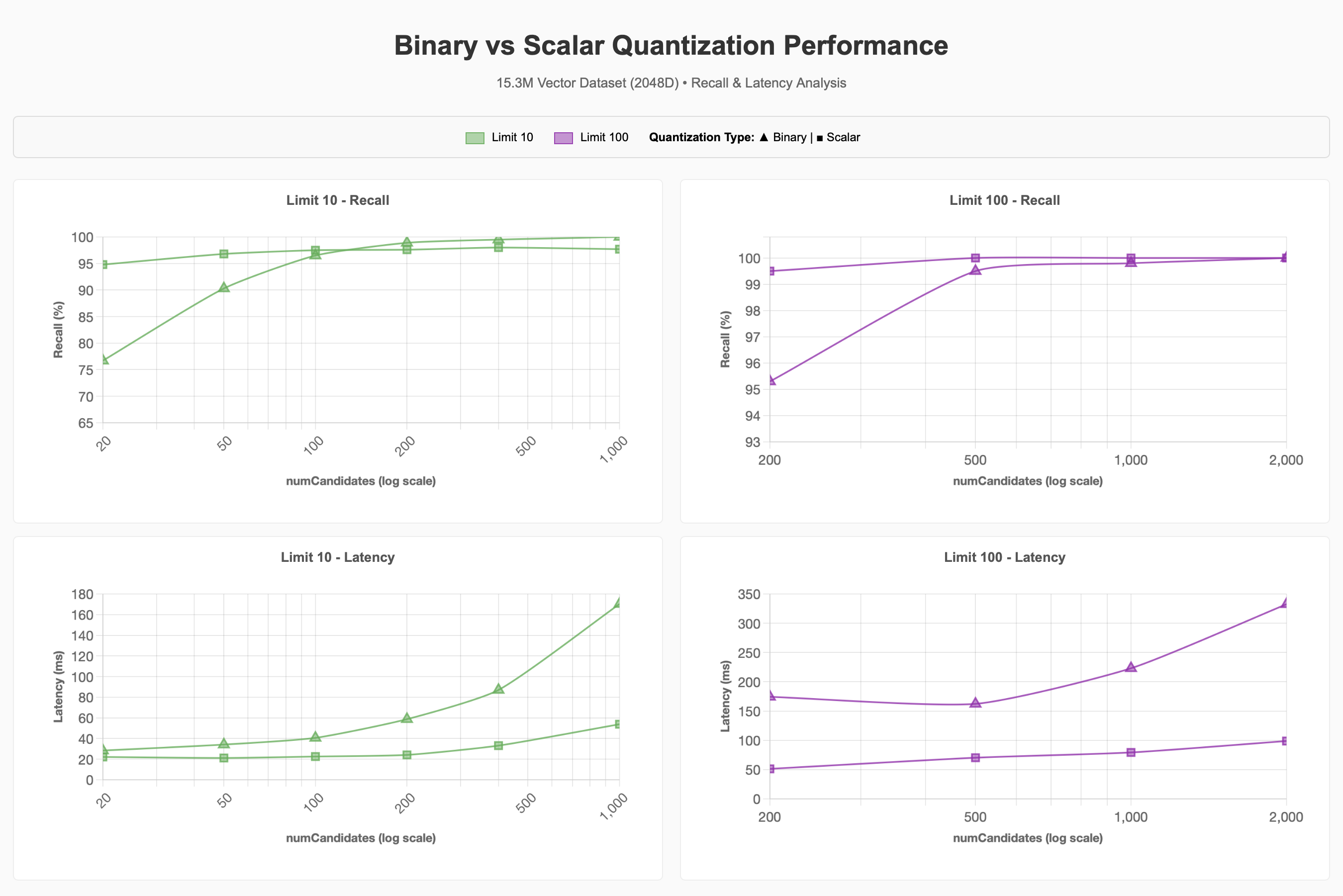
Para el conjunto de datos vectoriales 15.3M más grande, fijamos la dimensionalidad a 2048d y examinamos el impacto de la cuantización, el filtrado y la concurrencia en el rendimiento. Elegimos usar 2048d basándonos en los resultados de la prueba anterior, que mostraban que dimensiones superiores mantenían el recall de manera más favorable, aunque 1024d probablemente habría servido igual de bien para alcanzar el objetivo de recall del 90-95%.
Análisis de recuperación de datos y latencia
Observamos que se necesita significativamente más numCandidates al utilizar cuantificación binaria para alcanzar el objetivo de recall del 90-95% en comparación con la línea base. Una mayor numCandidates generalmente significa una mayor latencia, pero esto puede variar.
Para ver la gráfica completa, consulta Artefacto Claude.
Filtrado
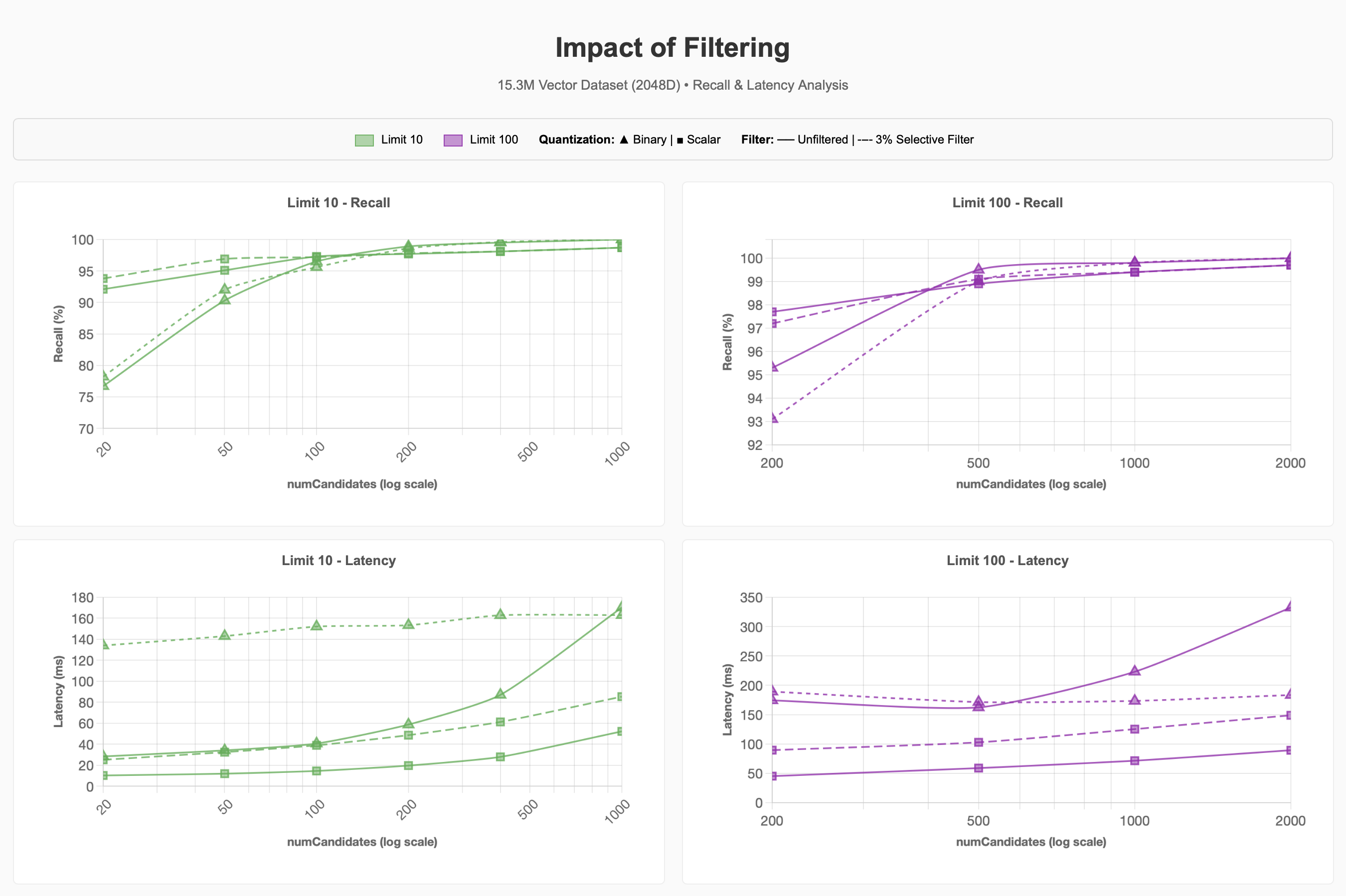
Observamos lo que sucede con la recuperación y la latencia al usar un filtro selectivo en el conjunto de datos para aproximadamente500mil elementos de los 15.3M de elementos que se encuentran en la Categoría de Suministros para mascotas (aproximadamente3% del corpus):
Para ver la gráfica completa, consulta Artefacto Claude.
Podemos ver que el filtro selectivo 3% puede hacer que las queries sean significativamente más costosas. Para la cuantificación binaria con valores limit más bajos, esto fue aproximadamente 4 veces más costoso para lograr un recall de 90-95% en comparación con las consultas sin filtro.
Las mejoras futuras en Lucene 10, que admitan estrategias de búsqueda Acorn-1 para Mundos pequeños jerárquicamente navegables, podrían mejorar este proceso. Sin embargo, realizar ENN cuando el número de candidatos solicitados supera el número de vectores que coinciden con el filtro de metadatos en un segmento demuestra que la selectividad del filtro desempeña un papel importante en el rendimiento de la query, independientemente del régimen de cuantificación seleccionado.
Simultaneidad
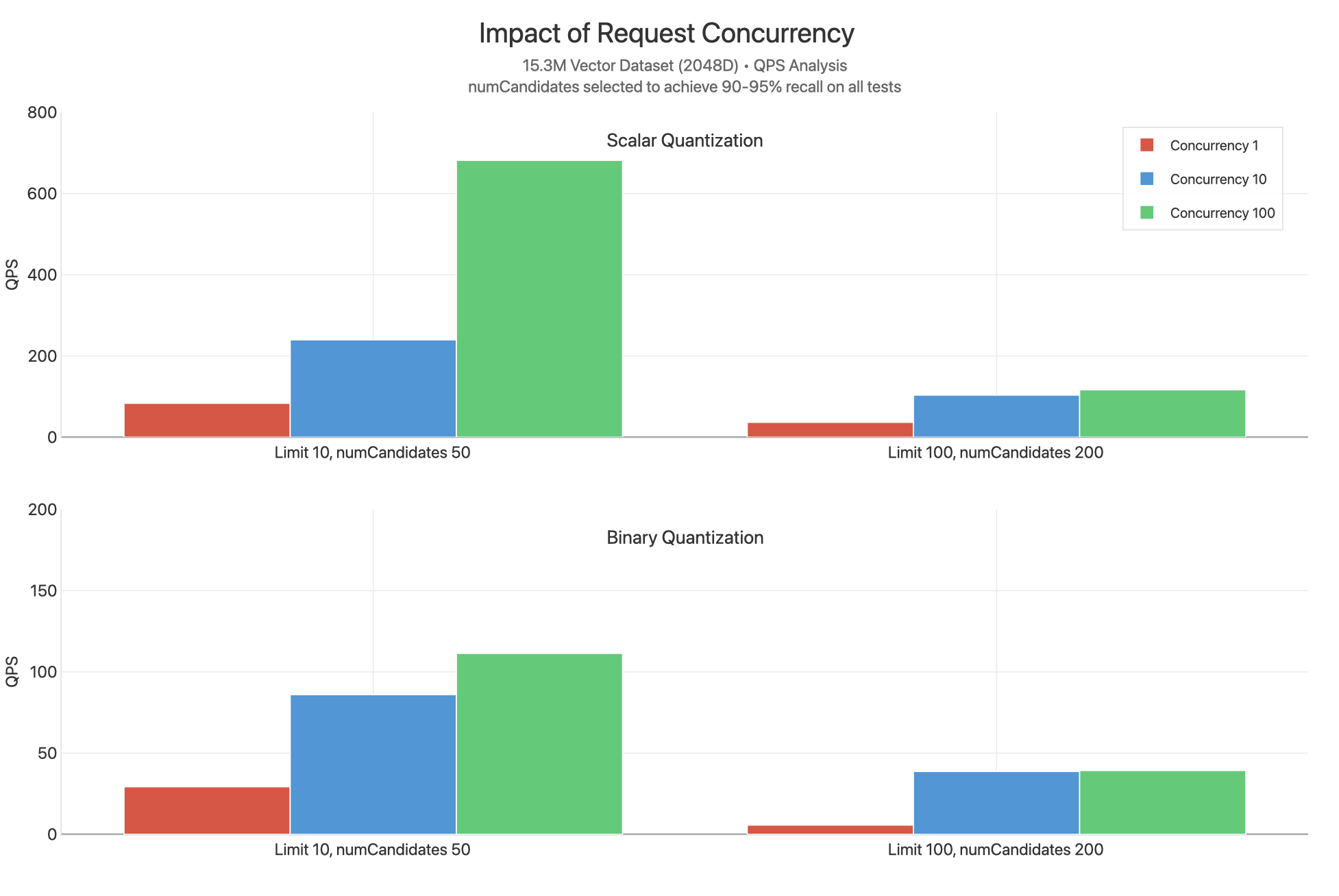
Estas pruebas escalan las solicitudes simultáneas entre 1, 10 y 100 en los diversos valores limit al usar cuantización escalar y binaria. numCandidates se seleccionan eligiendo valores que permiten alcanzar un 90-95% de recall:
Para ver la gráfica completa, consulta Artefacto Claude.
Observamos que la cuantización escalar logra sustancialmente mayor QPS en todos los valores del límite, probablemente porque se realiza menos trabajo por consulta con menor numCandidates y porque no se realiza la revalorización. Observamos cuellos de botella sustanciales en la CPU, como lo indica que los gráficos de concurrencia 10 y concurrencia 100 suelen estar muy cerca el uno del otro, lo que indica que se observaría una mayor latencia.
Un punto de datos excepcional es el límite 10, concurrencia 100 para la cuantización escalar que produce un QPS significativamente mayor. Esto se debe probablemente a la falta de re-evaluación y a que valores bajos de limit significa que se realizan menos comparaciones para esta query, lo que permite que cada solicitud se devuelva más rápidamente y que los núcleos estén disponibles para servir otras queries.
Escalar el número de vCPU disponibles para servir solicitudes, ya sea escalando el nivel de nodo de búsqueda o escalando el número de nodos de búsqueda desde el mínimo de 2 hasta 32 nodos, podría ayudar a resolver los cuellos de botella de la simultaneidad y permitir escalar hasta miles de QPS.
particionado
También observamos lo que sucedería si el clúster y la colección se particionaran (en _id) y se emitieran queries sin filtrar sobre un índice cuantificado binario.
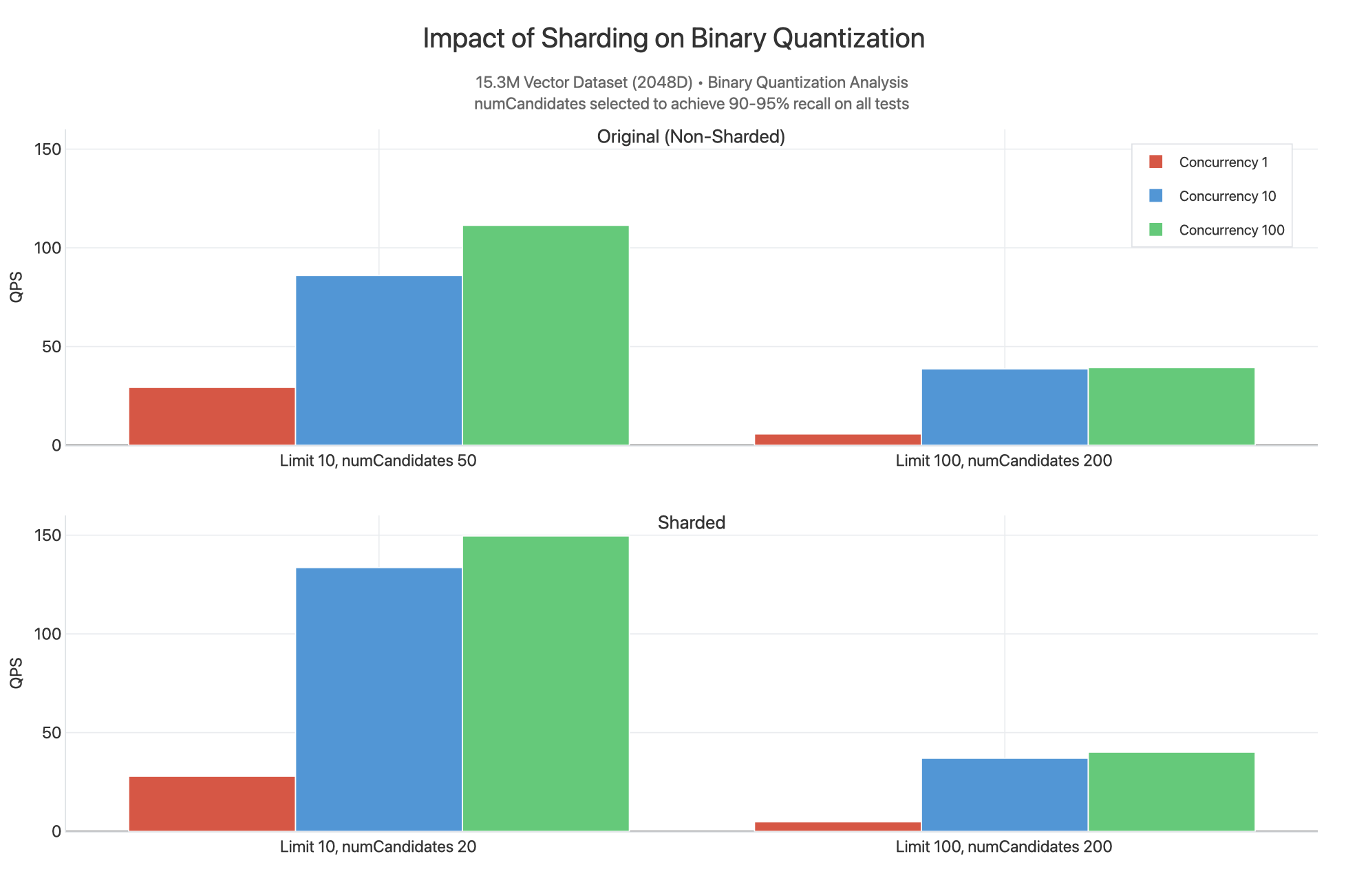
Para ver la gráfica completa, consulta Artefacto Claude.
Aquí, vemos que los resultados particionado tienen un mayor QPS en el límite 10 ya que se puede proporcionar un valor inferior de numCandidates para obtener resultados en el rango de recuerdo 90-95%. Esto se debe a que el conjunto de datos 15.3M está repartido en tres particiones, cada uno de los cuales tiene sus propios índices llenos de 5.1M vectores repartidos en segmentos que contienen grafos HNSW. Funcionalmente estamos realizando una búsqueda menos avanzada donde es más probable que cada consulta dispersa y recopilada a través de 3 particiones simultáneamente pueda hallar los n vectores más cercanos. Por esta razón, el QPS es ligeramente superior cuando se particiona, ya que se puede reducir numCandidates y tener más núcleos disponibles para servir queries, pero la diferencia no es lo suficientemente significativa como para justificar el aumento del costo de particionar el clúster. La mayoría de las veces deberías particionar tu clúster por razones relacionadas con tu carga de trabajo operativa, no porque necesites escalar el rendimiento para la búsqueda vectorial.
Nota
Los valores son similares para limit 100, numCandidates 200. Podríamos esperar que esto funcione mejor para queries filtradas con una coincidencia de clave de partición inteligente utilizada como filtro.