caso de uso: Personalización, IA Gen
Industrias: Medios de comunicación, Telecomunicaciones
Productos y Herramientas: MongoDB Atlas, MongoDB Vector Search, MongoDB Atlas Stream Processing
emparejar: Voyage AI, Azure OpenAI
Descripción general de la solución
Cuando un nuevo usuario llega al sitio de noticias, tienes solo unos segundos para entender qué está buscando antes de que pierda el interés y se vaya. Esto plantea el problema del arranque en frío: ¿cómo recomendar contenido a usuarios sin tener datos previos sobre ellos?
Considera un usuario anónimo que llega al sitio y hace clic en tres artículos:
"NVIDIA crea un nuevo chip de IA"
"TSMC expande la producción en Arizona"
"Las acciones de Intel caen por los retrasos"
Una simple búsqueda de palabras clave solo recomendaría otros artículos sobre Intel o Arizona. Sin embargo, un sistema inteligente reconoce que los tres clics están relacionados con cadenas de suministro de semiconductores. Esto permite recomendar artículos relevantes como "El futuro de Silicon Valley", incluso cuando no comparten palabras clave con el historial de navegación del usuario.
La solución en este artículo desarrolla un sistema inteligente de personalización de medios que ingiere y procesa datos de flujo de clics para generar un resumen en lenguaje natural de los intereses del usuario y recomendar artículos relevantes con los que es más probable que interactúe.
Esta solución combina:
Atlas Stream Processing para la ingesta de datos en tiempo real, el enriquecimiento y la integración de LLM para resumir la intención del usuario a partir de los datos del flujo de clics
Búsqueda vectorial de Atlas con incrustaciones automatizadas de Voyage IA para recuperación semántica y recomendaciones
Arquitectura de referencia
Esta arquitectura muestra cómo construir un motor de recomendación de medios impulsado por IA que ingiere, procesa y reacciona al comportamiento de los usuarios en tiempo real utilizando MongoDB Atlas.
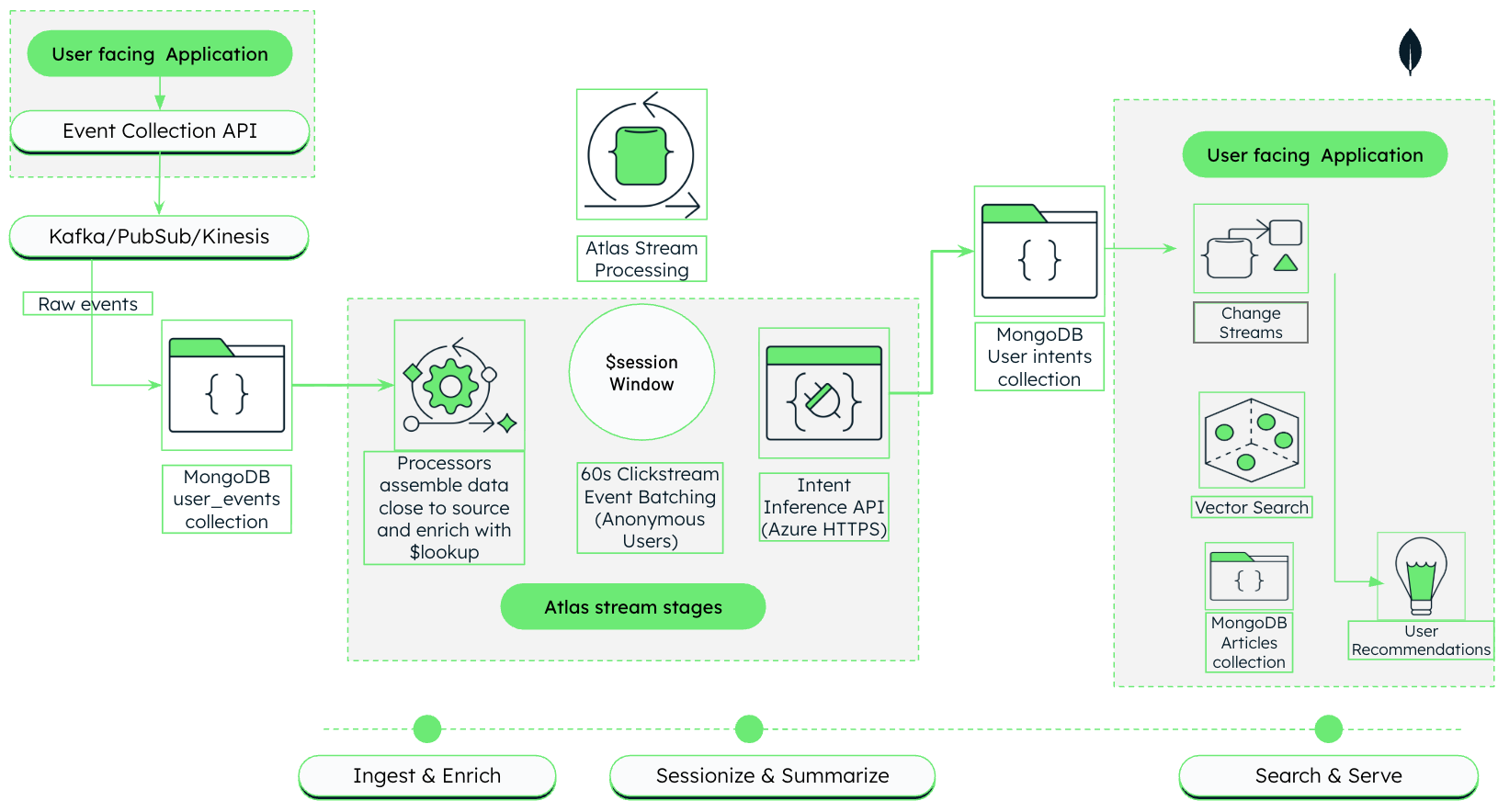
Figura 1. Arquitectura de personalización de medios impulsada por IA con Atlas Stream Processing y MongoDB Vector Search
Esta arquitectura funciona en tres fases, que se describen en detalle en las siguientes secciones:
Ingesta y enriquecimiento: Captura eventos de flujo de clics sin procesar de la aplicación orientada al usuario y combínalos con los metadatos de los artículos en tiempo real mediante Atlas Stream Processing.
Sesiones y resúmenes: Agrupa los clics relacionados en sesiones y utiliza un LLM para generar resúmenes en lenguaje natural de los intereses de los usuarios.
Búsqueda y devolución: Utiliza los resúmenes generados para impulsar la búsqueda vectorial semántica y devolver recomendaciones personalizadas.
Fase 1: Ingesta y enriquecimiento de datos del flujo de clics
En la primera fase, la arquitectura de esta solución utiliza Atlas Stream Processing para ingerir datos de flujo de clics sin procesar de tu plataforma de medios y enriquecerlos con metadatos de los artículos de tu base de datos.
Configura las fuentes de datos.
Esta solución utiliza las siguientes dos colecciones en la base de datos news del mismo clúster de MongoDB:
La colección articles contiene metadatos sobre los artículos de tu catálogo. En este ejemplo, la colección está en la base de datos news del clúster ClickstreamCluster.
Cada documento de la colección representa un artículo y contiene metadatos relevantes. Por ejemplo:
{ "_id": { "$oid": "696493bfbc1084032ac0adfe" }, "title": "Ukraine updates, Day 6: ‘We are sacrificing our lives for freedom,’ Zelenskyy gets standing ovation after speech to European parliament", "link": "https://nationalpost.com/news/world/ukraine-updates-day-6-russia-kyiv", "keywords": null, "creator": [ "National Post Wire Services" ], "video_url": null, "description": "Russia escalated shelling overnight of key cities in Ukraine as its troops on the ground move slowly in a large convoy toward the capital, Kyiv", "content": "8:20 a.m. EST — Ukraine's Zelenskyy tells EU: 'Prove that you are with us\" Read More", "pubDate": "2022-03-01 13:45:04", "expire_at": "Wed, 07 Sep 2022 13:45:04 GMT", "image_url": null, "source_id": "nationalpost", "country": [ "canada" ], "category": [ "top" ], "language": "english" }
La colección user_events contiene eventos de flujo de clics en bruto ingeridos desde tu aplicación orientada al usuario. En este ejemplo, la colección está en la base de datos news del clúster ClickstreamCluster.
Puedes configurar una fuente de datos de flujo de clics utilizando tu sistema de colección de eventos preferido. Para recrear el método que se muestra en el diagrama de arquitectura de referencia, implemente una API de recopilación de eventos en tu aplicación orientada al usuario para enviar eventos de clic a un tema Apache Kafka. Luego, usa el Kafka Sink Connector de MongoDB para leer el tema del flujo de clics y guardar en la colección user_events de tu clúster de MongoDB.
Cada clic en el artículo genera un documento de evento con campos como session_id, article_idy timestamp. Por ejemplo:
{ "_id": { "$oid": "696a1ecd66a51be18fffb8fa" }, "user_id": "user-2", "session_id": "sess-6a0d8837-a5f9-4ef5-8b00-78e9bf7a825c", "timestamp": { "$date": "2026-01-16T16:49:41.208Z" }, "event_type": "read", "article_id": { "$oid": "696493e6bc1084032ac116ed" }, "device": "desktop", "metadata": { "time_on_page": 54, "referral": "https://guzman.com/main/search/listmain.jsp" } }
Cree un espacio de trabajo de Stream Processing.
En Atlas, se debe ir a la página Stream Processing del proyecto.
Si aún no se muestra, seleccione la organización que contiene su proyecto en el menú Organizaciones de la barra de navegación.
Si aún no se muestra, seleccione su proyecto en el menú Projects de la barra de navegación.
En la barra lateral, haz clic en Stream Processing en la sección Streaming Data.
Se muestra la página Stream Processing.
Haga clic en Create a workspace.
En la página Create a stream processing workspace, configura tu espacio de trabajo de la siguiente manera:
Tier:
SP30Provider:
AWSRegion:
us-east-1Workspace Name:
article-personalization
Agrega una conexión para tu datos de flujo de clics y de artículos.
El procesador de flujo necesita conexiones tanto a los datos de flujo de clics como a los metadatos de los artículos para realizar el enriquecimiento. Ambas fuentes de datos deben estar en el mismo clúster de Atlas.
En el panel de tu espacio de trabajo de procesamiento de flujos, haz clic en Manage.
En la pestaña Connection Registry, haz clic en + Add Connection en la parte superior derecha.
En la página Edit Connection, configura tu conexión de la siguiente manera:
Tipo de conexión:
Atlas DatabaseNombre de la conexión:
usereventsClúster de Atlas: El nombre del clúster en el que se encuentran los datos del artículo y del flujo de clics (por ejemplo,
ClickstreamCluster)Ejecutar como:
Read and write to any database
Haz clic en Save changes para crear la conexión.
Crea un procesador de flujo persistente.
Cree un procesador de streaming llamado userIntentSummarizer con etapas que lean los eventos de flujo de clics sin procesar de la colección user_events y enriquezcan los eventos con los metadatos de los artículos.
En la página Stream Processing de tu proyecto de Atlas, haz clic en Manage en el panel del espacio de trabajo de Stream Processing.
En el JSON editor, copia y pega la siguiente definición JSON en el cuadro de texto del editor JSON para definir un procesador de flujo llamado
userIntentSummarizercon estas etapas:$source: Lee eventos de flujo de clics sin procesar de la colecciónuser_eventsde la base de datosnewsde tu clúster de flujo de clics conectado (conexiónuserevents).$lookup: Une los eventos de secuencia de clics sin procesar con la colecciónarticlesbasándose en el campoarticle_id, incorporando metadatos relevantes del artículo de los camposdescription,keywordsytitle.$addFields: Proyecta los camposdescription,keywordsytitledesde el campoarticle_detailsal nivel superior del flujo de eventos para que sean fácilmente accesibles para las etapas posteriores.$project: Proyecta los campos pertinentes para el procesamiento posterior.
{ "$source": { "connectionName": "userevents", "db": "news", "collection": "user_events" } }, { "$lookup": { "from": { "connectionName": "userevents", "db": "news", "coll": "articles" }, "localField": "article_id", "foreignField": "_id", "as": "article_details", "pipeline": [ { "$project": { "_id": 0, "description": 1, "keywords": 1, "title": 1 } } ] } }, { "$addFields": { "description": { "$arrayElemAt": [ "$article_details.description", 0 ] }, "keywords": { "$arrayElemAt": [ "$article_details.keywords", 0 ] }, "title": { "$arrayElemAt": [ "$article_details.title", 0 ] } } }, { "$project": { "userId": 1, "article_id": 1, "eventTime": 1, "event_type": 1, "device": 1, "session_id": 1, "description": 1, "keywords": 1, "title": 1 } }, Haz clic en Update stream processor para guardar tus cambios.
Fase 2: Agrupar y resumir el comportamiento de los usuarios
En esta fase, ampliamos el pipeline del procesador de flujo para agrupar clics relacionados en sesiones y utilizamos un LLM para generar un resumen en lenguaje natural de cada sesión que describa los intereses del usuario.
Conecta tu proveedor de LLM a tu espacio de trabajo de Stream Processing.
Agrega una conexión HTTPS externa a tu proveedor de LLM (por ejemplo, Azure OpenAI) para permitir que el procesador de flujo llame al LLM directamente desde el pipeline para enriquecer tus datos:
En el panel de tu espacio de trabajo de procesamiento de flujos, haz clic en Manage.
En la pestaña Connection Registry, haz clic en + Add Connection en la parte superior derecha.
Configura la conexión de la siguiente manera:
Tipo de conexión:
HTTPSNombre de la conexión:
azureopenaiURL: La URL del endpoint para la instancia de Azure OpenAI.
Encabezados: Añade estos pares clave-valor a los encabezados:
Clave:
Content-Type, Valor:application/jsonClave:
api-key, Valor: Tu clave de API de Azure OpenAI
Separe los datos de flujo de clics utilizando la $sessionWindow etapa.
Agrega una etapa $sessionWindow al pipeline del procesador de flujos para agrupar eventos relacionados en sesiones en función de un intervalo de sesión especificado. Esta solución define una sesión como una secuencia de eventos del mismo session_id sin un intervalo de inactividad superior a 60 segundos.
Agrega esta etapa a tu pipeline userIntentSummarizer después de las etapas de enriquecimiento:
{ "$sessionWindow": { "partitionBy": "$session_id", "gap": { "unit": "second", "size": 60 }, "pipeline": [{ "$group": { "_id": "$session_id", "titles": { "$push": "$title" } } }] } }
Resuma las sesiones de usuario utilizando la $https etapa.
Agrega una etapa $https para llamar directamente a tu proveedor de LLM desde tu pipeline de Stream Processing. Esta solución llama a Azure OpenAI para generar un resumen en lenguaje natural de cada sesión que describe los intereses del usuario basándose en los títulos de los artículos de la sesión.
Agrega esta etapa al pipeline después de la etapa $sessionWindow:
{ "$https": { "connectionName": "azureopenai", "method": "POST", "as": "apiResults", "config": { "parseJsonStrings": true }, "payload": [ { "$project": { "_id": 0, "model": "gpt-4o-mini", "response_format": { "type": "json_object" }, "messages": [ { "role": "system", "content": "You are an analytical assistant that specializes in behavioral summarization. You analyze short-term reading activity and infer user interests without making personal or sensitive assumptions the create a special field called summary. Summary must be a special field in the response. Respond only in JSON format.Return a JSON object with the following keys in this order: \n reasoning: (Internal scratchpad, briefly explain your analysis) \n user_interests: (The list of inferred interests) \n summary: (A concise summary based on the interests above)" }, { "role": "user", "content": { "$toString": "$titles" } } ] } } ] } }
Nota
El procesador de flujo en sí es "inteligente". Transforma una lista de títulos en un resumen semántico (por ejemplo, "El usuario está investigando la logística de fabricación de semiconductores") antes de que los datos lleguen al disco. Esto difiere fundamentalmente de los pipelines de procesamiento por lotes tradicionales, que normalmente guardan datos de sesión sin procesar en una base de datos y luego llaman a una API externa desde un servidor de aplicaciones.
Guarda los resúmenes de sesión en una nueva colección.
Agrega las siguientes etapas al pipeline para extraer el resumen de la salida del LLM y guardarlo en una nueva colección:
$match: Filtra las sesiones en las que la llamada al LLM falló y devolvió un error para evitar escribir datos incompletos en la base de datos.$addFields: Extrae el camposummaryde la salida del LLM y lo agrega al nivel superior del documento.$project: Remueve la salida LLM sin procesar del documento para reducir el ruido y los costos de almacenamiento.$merge: Guarda los documentos resultantes en una nueva colección llamadauser_intenten la base de datosnewsdel clúster de flujo de clics (conexiónuserevents). Cada documento de esta colección representa una sesión de usuario y contiene un resumen de los intereses del usuario.
{ "$match": { "titles": { "$exists": true }, "apiResults": { "$exists": true } } }, { "$addFields": { "summary": { "$arrayElemAt": [ "$apiResults.choices.message.content.summary", 0 ] } } }, { "$project": { "apiResults": 0 } }, { "$merge": { "into": { "coll": "user_intent", "connectionName": "userevents", "db": "news" } } }
Inicia el procesador de flujos.
Cuando estés listo para empezar a resumir los datos de flujo de clics, haz clic en el icono Start del procesador userIntentSummarizer en la lista de procesadores de streaming del espacio de trabajo de Stream Processing.
Este pipeline debe guardar documentos para la colección de user_intent que contengan resúmenes de sesión que capturen los intereses del usuario. Por ejemplo:
{ "_id": "sess-6a0d8837-a5f9-4ef5-8b00-78e9bf7a825c", "summary": "The user seems interested in geopolitical developments, especially in the Middle East, US political strategies involving Trump, and legal aspects of government operations.", "titles": [ "Israel and Hamas agree to part of Trump's Gaza peace plan, will free hostages and prisoners", "Top officials from US and Qatar join talks aimed at brokering peace in Gaza", "How Trump secured a Gaza breakthrough", "Ontario's anti-tariff ad is clever, effective and legally sound, experts say", "Shutdown? Trump's been dismantling the government all year", "AP News Summary at 7:58 p.m. EDT" ] }
A continuación, se presenta la definición completa de JSON para el procesador de flujo userIntentSummarizer que realiza todas las operaciones descritas en las Fases 1 y 2, incluida la ingesta de datos de clickstream, su enriquecimiento con metadatos de artículos, la sesión del comportamiento del usuario, la llamada a un LLM para resumir la intención del usuario y la escritura de los resúmenes en una nueva colección.
{ "name": "userIntentSummarizer", "pipeline": [ { "$source": { "connectionName": "userevents", "db": "news", "collection": "user_events" } }, { "$lookup": { "from": { "connectionName": "userevents", "db": "news", "coll": "articles" }, "localField": "article_id", "foreignField": "_id", "as": "article_details", "pipeline": [ { "$project": { "_id": 0, "description": 1, "keywords": 1, "title": 1 } } ] } }, { "$addFields": { "description": { "$arrayElemAt": [ "$article_details.description", 0 ] }, "keywords": { "$arrayElemAt": [ "$article_details.keywords", 0 ] }, "title": { "$arrayElemAt": [ "$article_details.title", 0 ] } } }, { "$project": { "userId": 1, "article_id": 1, "eventTime": 1, "event_type": 1, "device": 1, "session_id": 1, "description": 1, "keywords": 1, "title": 1 } }, { "$sessionWindow": { "partitionBy": "$session_id", "gap": { "unit": "second", "size": 60 }, "pipeline": [{ "$group": { "_id": "$session_id", "titles": { "$push": "$title" } } }] } }, { "$https": { "connectionName": "azureopenai", "method": "POST", "as": "apiResults", "config": { "parseJsonStrings": true }, "payload": [ { "$project": { "_id": 0, "model": "gpt-4o-mini", "response_format": { "type": "json_object" }, "messages": [ { "role": "system", "content": "You are an analytical assistant that specializes in behavioral summarization. You analyze short-term reading activity and infer user interests without making personal or sensitive assumptions then create a special field called summary. Summary must be a special field in the response. Respond only in JSON format.Return a JSON object with the following keys in this order: \n reasoning: (Internal scratchpad, briefly explain your analysis) \n user_interests: (The list of inferred interests) \n summary: (A concise summary based on the interests above)" }, { "role": "user", "content": { "$toString": "$titles" } } ] } } ] } }, { "$match": { "titles": { "$exists": true }, "apiResults": { "$exists": true } } }, { "$addFields": { "summary": { "$arrayElemAt": [ "$apiResults.choices.message.content.summary", 0 ] } } }, { "$project": { "apiResults": 0 } }, { "$merge": { "into": { "coll": "user_intent", "connectionName": "userevents", "db": "news" } } } ] }
Fase 3: Búsqueda semántica y devolución de recomendaciones personalizadas
Finalmente, utilizamos MongoDB Vector Search para realizar una búsqueda semántica en el catálogo de artículos utilizando los resúmenes de sesión generados en la fase anterior para impulsar recomendaciones de contenido personalizadas.
Prepara los datos del artículo para la recuperación semántica.
Antes de poder realizar búsquedas semánticas, debes generar incrustaciones vectoriales para los datos de artículos. Para ello, crea un índice de MongoDB Vector Search denominado vector_index que indexe el campo description de la colección articles como el tipo autoEmbed. Esto indica a MongoDB Vector Search que utilice incrustaciones automatizadas para generar automáticamente incrustaciones vectoriales para el campo description cada vez que se insertan o actualizan documentos en la colección.
Importante
La incrustación automatizada está disponible como funcionalidad de Vista Previa sólo para MongoDB Community Edition v8.2 y versiones posteriores. La funcionalidad y la documentación correspondiente pueden cambiar en cualquier momento durante el periodo de vista previa. Para obtener más información, consulte Funcionalidades de vista previa.
Atlas admite la incrustación manual en todas las ediciones de MongoDB.
Utiliza esta definición JSON para crear un índice vectorial en estos campos:
El campo
descriptioncon el tipoautoEmbedpara instruir a MongoDB Vector Search que genere automáticamente incrustaciones vectoriales para el campodescriptionutilizando el modelo de incrustaciónvoyage-4-largecada vez que se inserten o actualicen documentos en la colección.El campo
titlecomo el tipofilterpara prefiltrar los datos para la búsqueda semántica utilizando el valor de string en el campo. Esto te permite excluir artículos que el usuario ya ha leído de los resultados de búsqueda.
{ "fields": [ { "type": "autoEmbed", "modalitytype": "text", "path": "description", "model": "voyage-4-large" }, { "type": "filter", "path": "title" } ] }
Ejecuta queries de búsqueda semántica para servir recomendaciones personalizadas.
Cuando un usuario visita tu sitio, toma el resumen de su sesión actual y lo usa como la query para una búsqueda vectorial contra tu catálogo de artículos. Como se habilitó la incrustación automatizada en el índice, MongoDB Vector Search genera automáticamente la incrustación para el resumen en el momento de la query y la usa como el vector de query efectivo.
Este ejemplo muestra una query de búsqueda vectorial simplificada que utiliza la sesión summary como vector de query y excluye los artículos que el usuario ya ha leído en función del campo titles:
[{ "$vectorSearch": { "index": "vector_index", // Vector index with autoEmbed on article descriptions "path": "description", "query": { "text": "<session-summary>" // Session summary from user_intent document }, "numCandidates": 100, "filter": { "title": { "$nin": [<read-titles>] } // Exclude articles the array of titles in the user_intent document } } }]
Lecciones clave
Esta arquitectura demuestra varios avances importantes en la creación de productos de datos modernos:
Latencia reducida: La incrustación de llamadas LLM directamente dentro del procesador de flujo elimina múltiples saltos de red y capas intermedias de persistencia. El sistema transforma los clics sin procesar en intenciones procesables casi en tiempo real.
Experiencia para desarrolladores mejorada: Define pipelines con MQL basado en JSON, lo que permite a los equipos que ya conocen las consultas de MongoDB crear cargas de trabajo avanzadas de streaming y basadas en IA sin aprender nuevos DSL ni aprovisionar infraestructura adicional.
Personalización semántica: Ve más allá de las coincidencias de palabras clave y las tareas nocturnas de agrupamiento para compilar sistemas que escuchen, piensen y respondan al instante al comportamiento del usuario.
Autores
- Vinod Krishnan, Arquitecto de soluciones, MongoDB
Obtén más información
Para comprender cómo Atlas búsqueda vectorial impulsa la búsqueda semántica y permite el análisis en tiempo real, visita la página Atlas búsqueda vectorial.
Para aprender cómo MongoDB está transformando las operaciones de medios, lea el Artículo sobre personalización de medios impulsada por IA: MongoDB y búsqueda vectorial.
Para descubrir cómo MongoDB soporta los modernos flujos de trabajo de los medios de comunicación, ir a la página MongoDB para medios de comunicación y entretenimiento.
Para aprender más sobre Atlas Stream Processing, visita la documentación de Atlas Stream Processing.