You can structure your cluster with different deployment types, cloud providers, and cluster tiers to meet the needs of a pre-production or production environment. Use these recommendations to select the deployment type, cloud provider and region, and cluster and search tiers for performing vector search.
Environment | Deployment Type | Cluster Tier | Cloud Provider Region | Node Architecture |
|---|---|---|---|---|
Testing Queries | Flex cluster, dedicated cluster Local deployment | Free cluster or higher tier N/A | All N/A | MongoDB and Search processes run on the same node |
Prototyping Applications | Dedicated cluster | Flex cluster, | All | MongoDB and Search processes run on the same node |
Production | Dedicated cluster with separate Search Nodes |
| AWS and Azure in some regions or Google Cloud in all regions | MongoDB and Search processes run on different nodes |
To learn more about these deployment models, review the following sections:
Resource Usage
Memory Requirements for Indexing Vectors
MongoDB Vector Search holds the entire index in memory, so you need to ensure there's enough memory for the MongoDB Vector Search index and JVM if your dataset includes full precision vectors. Each index is a combination of the vectors being indexed and additional metadata. The index size is primarily determined by the size of the vectors that you are indexing, with metadata space typically being relatively nominal.
When not using quantization, MongoDB Vector Search stores the full fidelity vectors in memory. If you enable automatic quantization, MongoDB Vector Search stores the quantized vectors, which require significantly less resources, in memory and the full fidelity vectors on disk. You can view the difference between disk and memory requirements for vector indexes by viewing the Size and Required Memory columns in the Atlas UI MongoDB Search page.
Consider the following requirements for a single vector:
Embedding Model | Vector Dimension | Space Requirement |
|---|---|---|
Voyage AI | 2048 | 8kb (for float)2.14kb (for int8)0.334kb (for int1) |
OpenAI | 1536 | 6kb |
Google | 768 | 3kb |
Cohere | 1024 | 4kb (for float)1.07kb (for int8)0.167kb (for int1) |
BinData quantized vectors. To learn more, see Ingest Quantized Vectors.
The required space scales linearly with the number of vectors that you are indexing and with the vector dimensionality. You can also use the Search Index Size metric to determine the amount of space and memory you need on your Search Nodes.
Storage Requirements for Vectors
If you use BinData or quantized
vectors, you significantly reduce resource requirements compared to not
using binData or quantized vectors. You will notice:
Disk storage of vectors on
mongodreduce by 66% when usingbinDatavectors.RAM usage of vectors on
mongotreduce by 3.75x (scalar) or 24x (binary) due to vector compression when using either automatic vector quantization or quantized vector ingestion.
When you use automatic quantization, Atlas stores the full-precision vectors for rescoring or exact search on disk, with minimal RAM and cache usage for rescoring.
If you enable automatic quantization in your MongoDB Vector Search index definition, you must consider disk space also when sizing your cluster. This is because MongoDB Vector Search stores full-precision vectors also on disk for ENN search and for rescoring if you configured automatic quantization. Therefore, ensure that there is an appropriate disk to RAM ratio on the hardware that you use. Consider configuring search nodes that can accommodate roughly a 4:1 ratio of storage to RAM for scalar quantization or a 24:1 ratio of storage to RAM for binary quantization.
Example
This example demonstrates how to configure binary quantization for 10
million 1024-dimension embeddings from Voyage AI stored in the field
named my-embeddings:
{ "fields":[ { "type": "vector", "path": "my-embeddings", "numDimensions": 1024, "similarity": "euclidean", "quantization": "binary" } ] }
Use the following formula to roughly calculate the disk space for your binary quantization-enabled index with rescoring:
Original index size * (25/24)
Here, the 24 in the denominator represents the original index size
split into 24 parts for easier fraction representation. The 25
in the numerator accounts for an additional space allocation, which is
approximately 1/24 of the original index size, for additional data
needed to store binary vectors. Both the original index and the Hierarchical Navigable Small Worlds
graph are still stored on disk. The oversize factor is 1/24 rather than
1/32 because the HNSW graph is not compressed.
Example
Suppose your original index size is 1 GB. You can calculate the binary quantized index size with rescoring as shown below:
1 GB * (25/24) = 1.042 GB
Important
In the Atlas UI, Atlas displays the entire index size, which might be large as Atlas doesn't show a break down of the data structures within an index that are stored in RAM and on disk. The MongoDB Search metrics show a much smaller index that is held in memory when you enable automatic quantization.
For vectors for which you configured automatic quantization, we recommend allocating free disk space equal to 125% of the estimated index size.
Testing and Prototyping Environments
For testing your vector search queries and prototyping your application, we recommend the following configuration.
Deployment Type
For testing MongoDB Vector Search queries, you can deploy a Flex cluster, a dedicated cluster, or use a local Atlas deployment.
Cluster Tiers
Free clusters (formerly known as M0) are a free tier of cluster.
Flex clusters are low-cost cluster types suitable for teams that are
learning MongoDB or developing small proof-of-concept applications.
You can begin your project with an Atlas Flex cluster and upgrade to
a production-ready Dedicated cluster tier at a future time.
These low-cost cluster types are available for testing your MongoDB Vector Search queries. However, you might experience resource contention and query latency on Flex clusters. If you begin your project with a Flex cluster, we recommend upgrading to a higher tier when your application is ready for production.
Dedicated clusters include M10 and higher tiers. The M10 and
M20 tiers are suitable for prototyping your application. You can
scale to higher tiers to handle large datasets or deploy
dedicated Search Nodes for workload
isolation when your application is ready for production.
Cloud Provider and Region
The cloud provider and region that you choose affects the configuration options available for the cluster tiers and the cost of running the cluster.
All the cluster tiers are available in all the supported cloud provider regions
If you prefer to test MongoDB Vector Search queries locally, you can use the Atlas CLI to deploy a single-node replica set hosted on your local computer. To get started, complete the MongoDB Vector Search Quick Start and select the tab for local deployments.
When your application is ready for production, migrate your local Atlas deployment to a production environment by using Live Migration. Local deployments are limited by the CPU, memory, and storage resources of your local machine.
Node Architecture
For testing and prototyping environments, we recommend a node
architecture in which MongoDB processes and MongoDB Search processes run on the
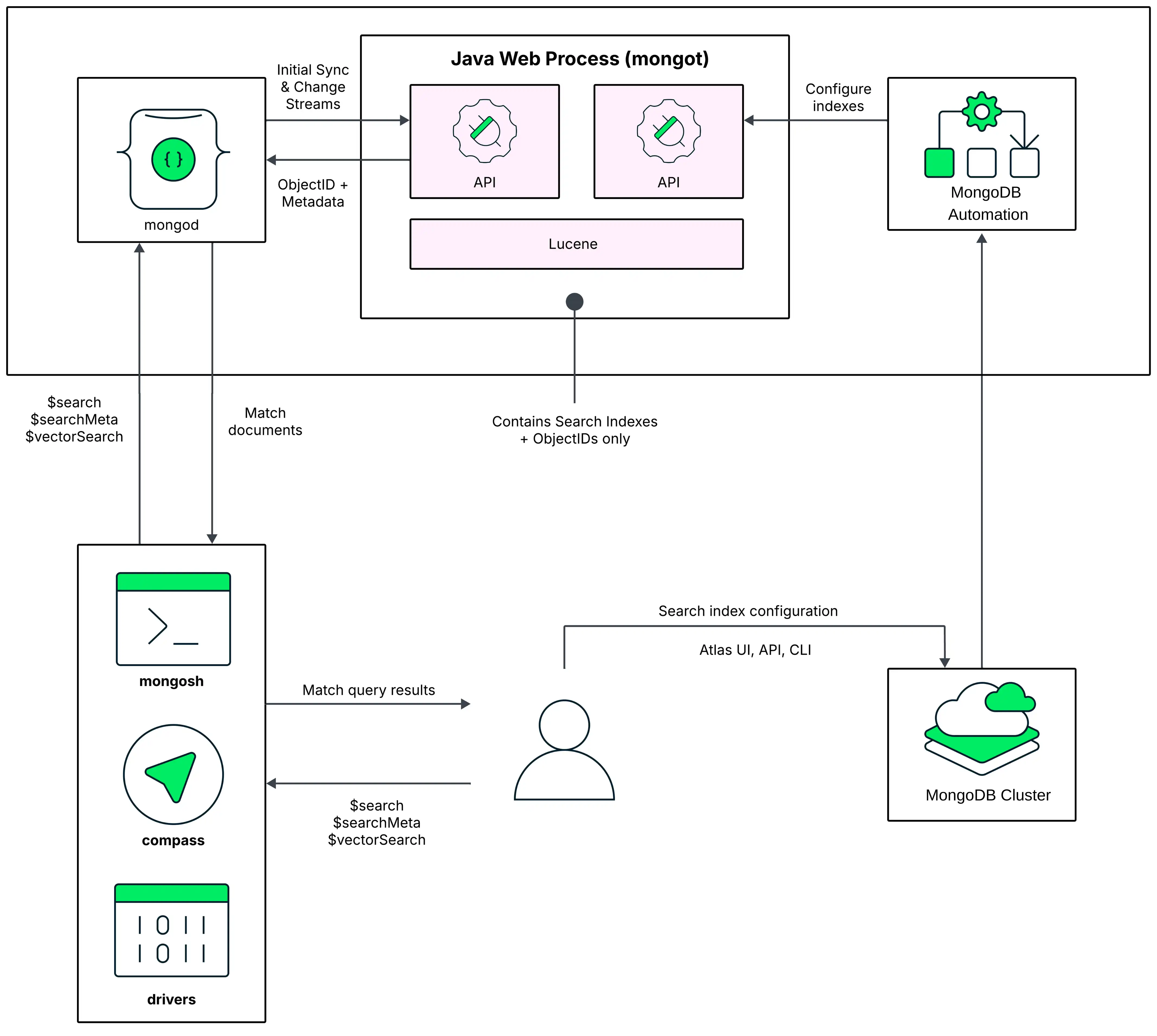
same node. In the following diagram of this deployment model, the MongoDB Search
mongot process runs alongside mongod on each node in the
Atlas cluster and they share the same resources.

By default, Atlas enables the MongoDB Search mongot process on the same
node that runs the mongod process when you create your first
MongoDB Vector Search index.
When you run a query, MongoDB Search uses the configured read preference to identify the node on which to run the query. The
query first goes to the MongoDB process, which is mongod for a
replica set cluster or mongos for a sharded cluster.
For a replica set cluster, the mongod process routes the query
to the mongot on the same node. For sharded clusters, your cluster
data is partitioned across mongod instances (shards) and each
mongot process can only access the data on the mongod instance
on the same node. Therefore, you can't run MongoDB Search queries that target a
particular shard. mongos routes the query to all shards, making
these scatter gather queries. If you use zones to distribute a sharded collection over a
subset of the shards in the cluster, MongoDB Search routes the query to the
zone that contains the shards for the collection that you are querying
and runs your $search queries on just the shards where the
collection is located.
After the query is routed to a MongoDB Search mongot process, the mongot
process performs the search and scoring and returns the document IDs and
other search metadata for the matching results to its corresponding
mongod process. The mongod process then performs a full document
lookup implicitly for the matching results and returns the results to
the client. If you use the $search concurrent option in your query, MongoDB Search enables intra-query
parallelism. To learn more, see Parallelize Query Execution Across
Segments.
To learn more about the mongot process, see Query Processing.
Size Your Cluster for Prototyping Your Application
When Atlas runs your database and search workloads on the same node,
the MongoDB storage takes a certain percentage of the node's available
memory (RAM), leaving the remaining for the MongoDB Vector Search index and the
mongot process.
Tier | Total Memory (GB) | Memory Available for MongoDB Vector Search Index (GB) |
|---|---|---|
| 2 | 1 |
| 4 | 2 |
| 8 | 4 |
For M10, M20, and M30 cluster tiers, 25% is reserved for
MongoDB and the remaining 75% is for other operations, including your
MongoDB Vector Search index. For M40+ cluster tiers, 50% is reserved for MongoDB
and the remaining is for other operations, including your MongoDB Vector Search
index.
Limitations
You might experience resource contention between the database mongod
and the search mongot processes. This could negatively impact the
performance of your index and latency of your queries. We recommend this
deployment model for only testing and prototyping environments. For
production-ready applications and associated search workloads, we
recommend migrating to dedicated Search Nodes.
Production Environment
For your production-ready application, we recommend the following cluster configuration.
Deployment Type
For production-ready applications, you need a dedicated cluster with separate Search Nodes for Workload Isolation.
Cluster Tiers
Dedicated clusters include M10 and higher tiers. The M10 and
M20 tiers are suitable for development and for production
environments. However, the higher tiers can handle large datasets and
production workloads. We recommend that you also deploy dedicated
Search Nodes for your search workload. This
allows you to scale your search deployment independently and
appropriately.
Cloud Provider and Region
Search Nodes are available in all the regions for Google Cloud but are only available in a subset of AWS and Azure regions. You must select a cloud provider and region where Search Nodes are available for your deployment.
All cluster tiers are available in supported cloud provider regions. The cloud provider and region that you choose affects the configuration options and search tiers available for the cluster and the cost of running the cluster.
Node Architecture
For production environments, we recommend a node architecture in which MongoDB processes and MongoDB Search processes run on separate nodes. To deploy separate Search Nodes, see Migrate to Dedicated Search Nodes.
In the following diagram of this deployment model, the MongoDB Search mongot
process runs on dedicated Search Nodes, which are separate from the
cluster nodes on which the mongod process runs.

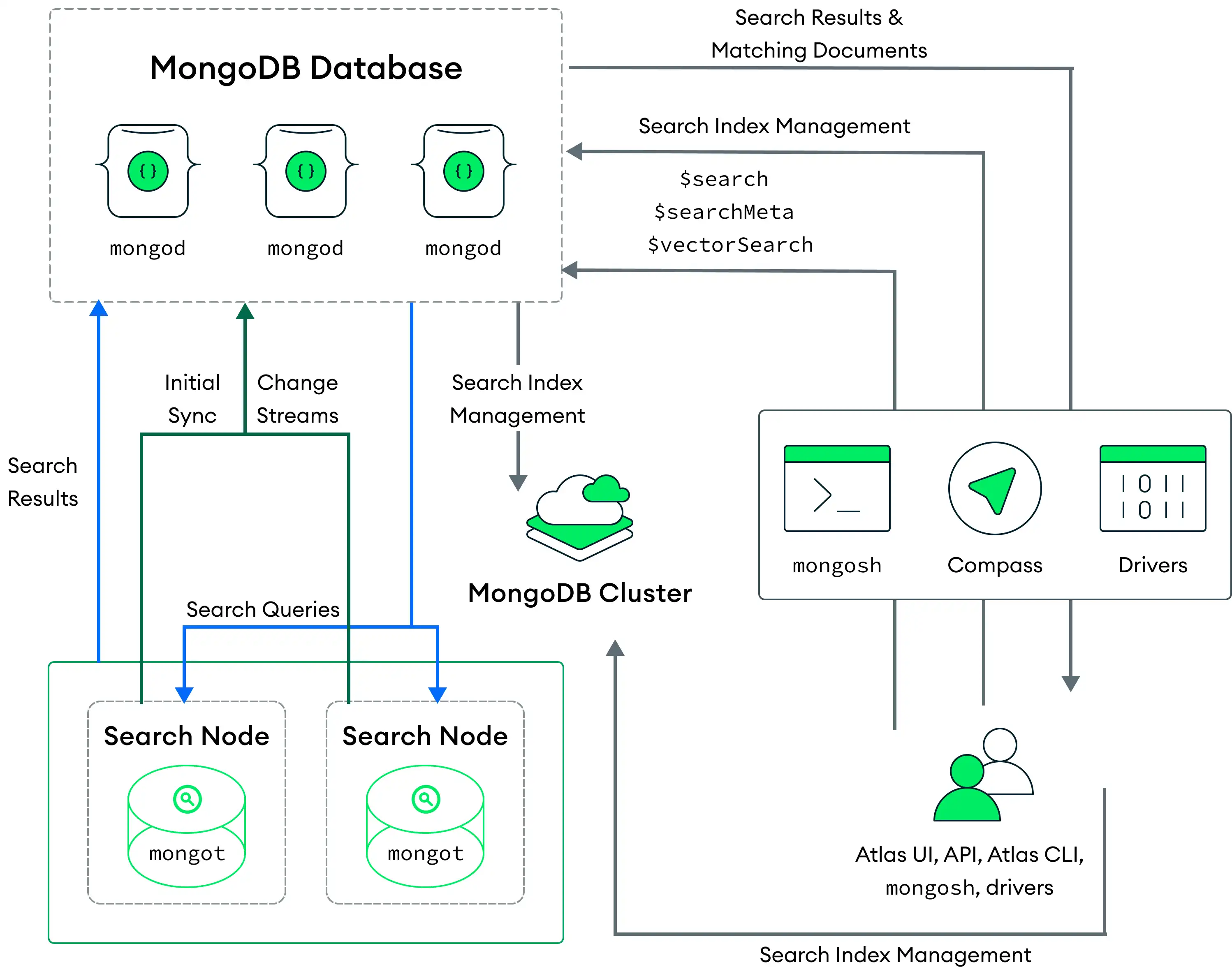
Atlas deploys Search Nodes with each cluster or with each shard on the cluster. For example, if you deploy two Search Nodes for a cluster with three shards, Atlas deploys six Search Nodes (two per shard). You can also configure the number of Search Nodes and the amount of resources provisioned for each search node.
When you deploy separate Search Nodes, Atlas automatically assigns a
mongod for each mongot for indexing. The mongot communicates
with the mongod to listen for and sync index changes for the indexes
that it stores. MongoDB Vector Search indexes and processes your queries
similar to a deployment where both the mongod and mongot
processes run on the same node. To learn more, see How to Index Fields for Vector Search and
Run Vector Search Queries. To learn more about deploying Search Nodes separately, see
Search Nodes for Workload Isolation.
When you migrate to Search Nodes, Atlas deploys the Search Nodes, but doesn't serve queries on the nodes until it successfully builds all the indexes on the cluster on the Search Nodes. While Atlas builds the indexes on the new nodes, it continues to serve queries using the indexes on the cluster nodes. Atlas starts serving queries from the Search Nodes only after it successfully builds the indexes on the Search Nodes and removes the indexes on the cluster nodes.
Note
Scaling your cluster by adding search nodes or by changing the search tier triggers a rebuild of the full MongoDB Search index. However, if your cluster on AWS or Azure has dedicated search nodes for which you haven't enabled Encryption at Rest using Customer Key Management, Atlas provides the following optimizations:
When you scale your search nodes, Atlas uses a recent copy of your index in S3 or Azure Blob Storage instead of rebuilding the entire MongoDB Search index on the new node.
For existing nodes, Atlas periodically takes and uploads a new incremental list of index files. Atlas retains index files for up to fourteen (14) days.
This is not yet available for clusters with dedicated search nodes on Google Cloud.
When you run a query, the query routes to the mongod based on the
configured read preference. The mongod
process routes the search query through a load balancer on the same
node, which distributes the requests across all of the mongot
processes.
The MongoDB Search mongot process performs the search and scoring and returns
the document IDs and metadata for the matching results to mongod.
The mongod then performs a full document lookup for the matching
results and returns the results to the client. If you use the
$search concurrent option in your
query, MongoDB Search enables intra-query parallelism. To learn more, see
Parallelize Query Execution Across Segments.
If you delete all the Search Nodes on your cluster, there will be an
interruption in processing your search query results. To learn more, see
Modify a Cluster. If you delete
your Atlas cluster, Atlas pauses and then deletes all
associated MongoDB Vector Search deployments (mongot processes).
Benefits
This deployment model provides the following benefits:
Efficiently utilize your resources while ensuring high availability of your resources for search workloads.
Size and scale your search deployment independently from your database deployment.
Automatically process MongoDB Vector Search queries concurrently, improving the response time especially on large datasets. To learn more, see Parallel Query Execution Across Segments.
Size Your Search Nodes for Production
MongoDB Vector Search holds the entire index in memory, so you need to ensure there's enough memory for the MongoDB Vector Search index and JVM. Search nodes allow for workload isolation without data isolation, and almost 90% of their RAM allocation can be used to store the vector data and indexes in memory, with the leftover being used for the JVM.
Each index is a combination of the vectors being indexed and additional metadata. The index size is primarily determined by the size of the vectors that you are indexing, with metadata space typically being relatively nominal. To learn more, see Memory Requirements for Indexing Vectors.
When you deploy dedicated Search Nodes, you can choose from different search tiers. Each search tier has a default RAM capacity, storage capacity, and CPU. This allows you to size and scale your cluster independently from your database deployment. To scale your search deployment separately, you can make the following changes to your cluster configuration at any time:
Adjust the number of Search Nodes on your cluster.
Adjust the CPU, RAM, and storage of the node by changing search tiers.
Note
To learn more about the cost of Search Nodes and search tiers, expand View all plan features and click MongoDB Vector Search in the the MongoDB Pricing page.
We recommend that your node has RAM that is at least 10% larger than the total size of your MongoDB Vector Search indexes. We also recommend that you ensure you have enough available CPUs. Query latency depends on the number of available CPUs, which can significantly impact the level of internal concurrency that accelerates query performance.
Example
Suppose you have 1M 768 dimensions vectors of roughly 3GB in size. Both the S30 (Low-CPU) and S20 (High-CPU) search tiers have enough RAM to support the index. Instead of deploying on the S30 (Low-CPU) search tier, we recommend deploying on the S20 (High-CPU) search tier because the S20 (High-CPU) search tier has more available CPUs to run queries concurrently.
Enable Encryption at Rest
By default, MongoDB and search processes run on the same nodes. With this architecture, customer-managed encryption applies to your database data, but it does not apply to search indexes.
When you enable dedicated Search Nodes, search processes run on separate nodes. This allows you to enable Search Node Data Encryption, so you can encrypt both database data and search indexes with the same customer-managed keys for comprehensive encryption coverage.
Note
Database nodes and Search Nodes use different encryption methods with the same customer-managed keys. Database nodes use the WiredTiger Encrypted Storage Engine, while Search Nodes use encryption at the disk level.
To learn more, see Enable Customer Key Management for Search Nodes.
Important
This feature is available across KMS providers, but the Search Nodes must be on AWS.
Migrate to Dedicated Search Nodes
Dedicated Search Nodes allow you to both size and scale your search deployment separately from your cluster. It also eliminates any resource contention that you might experience on a cluster that runs both the database and search processes on the same node.
To migrate to dedicated Search Nodes, make the following changes to your deployment:
If your deployment is currently using a free tier cluster or a Flex cluster, upgrade your cluster to a higher tier. Dedicated Search Nodes are supported only for
M10and higher cluster tiers. To learn more about migrating to a different cluster tier, see Modify the Cluster Tier.Dedicated Search Nodes are available on a subset of the AWS and Azure regions and in all supported Google Cloud regions. Make sure to deploy your cluster in regions where Search Nodes are also available. If your existing cluster is in regions where Search Nodes are not available, migrate your cluster to regions where Search Nodes are available. To learn more, see Cloud Provider Regions.
Enable Search Nodes for workload isolation and configure Search Nodes. To learn more, see Add Search Nodes.