Künstliche Intelligenz (KI) kann definiert werden als die Fähigkeit von Maschinen, rational zu denken, Probleme zu lösen und Entscheidungen zu treffen, ohne von einem menschlichen Verstand überwacht zu werden.
Mit dem Aufkommen des maschinellen Lernens und der Deep-Learning-Technologien sind Maschinen in der Lage, auf der Grundlage der ihnen zugeführten Daten zu „denken“ und zu „lernen“ und Aufgaben auszuführen, die früher nur von Menschen erledigt werden konnten. In diesem Artikel erfahren Sie mehr über künstliche Intelligenz, generative KI und wie MongoDB das Erscheinungsbild der generativen KI verändert, indem es die KI-Verarbeitung vereinfacht, kontextbasierte Suchen ermöglicht und die Genauigkeit von Large Language Models (LLMs) verbessert.
Inhaltsverzeichnis
- Künstliche Intelligenz (KI) erklärt
- Wie KI der menschlichen Intelligenz ähnelt
- KI vs. maschinelles Lernen
- Deep learning
- Geschichte der künstlichen Intelligenz
- Arten von KI
- Foundation Models
- Generative KI
- Large Language Model (LLM)
- Vektorsuche
- MongoDB Atlas Vector Search
- Wie funktioniert die Atlas-Vektorsuche?
- Wichtige KI-Anwendungsfälle
- Ethische Nutzung von KI, KI-Governance und Vorschriften
- KI-Tools und -Dienste
- FAQs
Künstliche Intelligenz (KI) erklärt
Künstliche Intelligenz ist ein Teilgebiet der Informatik, das Maschinen in die Lage versetzt, logische Schlussfolgerungen zu ziehen, intelligente Entscheidungen zu treffen und Daten zu analysieren, und zwar in einem Umfang, der das menschliche Verständnis und die menschlichen Fähigkeiten zu übertreffen scheint.
KI umfasst Bereiche wie Datenwissenschaft, Statistik, Neurowissenschaften und maschinelles Lernen, zu dem auch Deep Learning gehört, auf dem unsere modernen Algorithmen basieren.
Diese Algorithmen sind die Grundlage dafür, dass KI menschenähnliche Entscheidungen treffen kann, indem sie Daten in Muster zerlegt und schwierige Aufgaben mit Leichtigkeit und Genauigkeit erledigt.
Einige populäre Beispiele für Systeme mit künstlicher Intelligenz sind ChatGPT, virtuelle Assistenten wie Alexa und Siri, selbstfahrende Autos und Empfehlungsmaschinen.
Wie die KI der menschlichen Intelligenz ähnelt
Das menschliche Gehirn arbeitet auf eine komplexe Weise. Wir denken, handeln und treffen Entscheidungen auf der Grundlage unserer vergangenen Erfahrungen und Erinnerungen und leiten daraus Muster ab, die auf unserer Umgebung und unseren Situationen basieren. Was wir über einen gewissen Zeitraum hinweg beobachten, ist das, was das Gehirn als wahr empfindet. Wenn wir beispielsweise ständig eine rote Rose sehen, erkennt unser Gehirn, dass eine Rose eine rote Farbe hat und eine bestimmte Form und Größe hat. Wenn wir lesen oder hören, dass Rosen auch gelb oder rosa sein können, stellen wir uns aufgrund unseres Vorwissens über eine rote Rose eine gelbe oder rosa Rose vor, die in gewisser Weise einer roten Rose ähnelt.
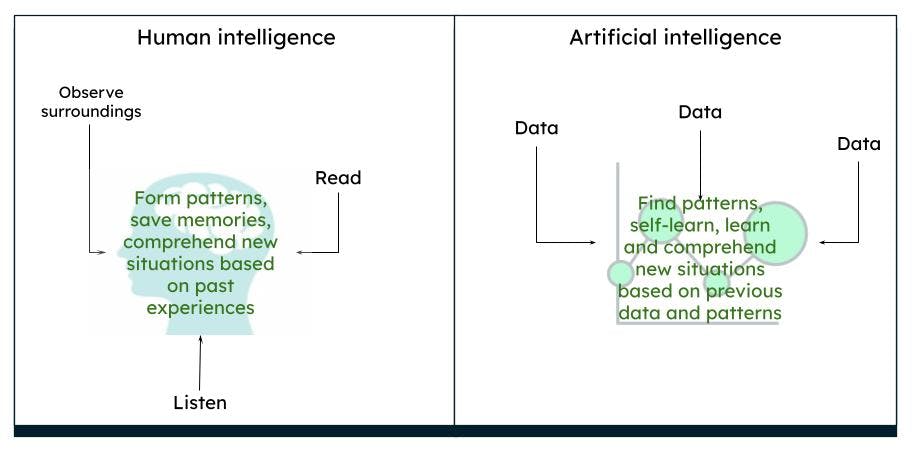 Darstellung der menschlichen Intelligenz im Vergleich zur künstlichen Intelligenz
Darstellung der menschlichen Intelligenz im Vergleich zur künstlichen Intelligenz
KI funktioniert auf die gleiche Weise. Wenn ein Computer mit genügend Daten gefüttert wird, sind Maschinen in der Lage, auf der Grundlage der Datenmuster durch Algorithmen bestimmte Ergebnisse abzuleiten. Wenn Sie zum Beispiel Daten über Rosen und Farben einspeisen, kann der Computer das nächste Mal, wenn er ein ähnliches Objekt sieht, dieses als Rose einer bestimmten Farbe identifizieren.
KI vs. maschinelles Lernen
KI ist ein weiter gefasster Begriff, der aus Theorien und Systemen besteht, mit denen Maschinen gebaut werden, die Aufgaben ausführen, die Intelligenz erfordern. Maschinelles Lernen ist ein Zweig der KI, der sich auf die Analyse von Daten konzentriert, um mit verschiedenen Algorithmen Muster zu finden und Entscheidungen zu treffen, ohne dass eine explizite Programmierung erforderlich ist. Zu den Techniken des maschinellen Lernens gehören überwachte, nicht überwachte und verstärkende Lernmethoden.
Deep Learning
Deep Learning ist ein Teilbereich des maschinellen Lernens, der der menschlichen Intelligenz ähnelt. Deep-Learning-Modelle bestehen aus künstlichen tiefen neuronalen Netzwerken – d. h. aus miteinander verbundenen Neuronen (oder Knoten) – und haben viele Schichten, wodurch sie komplexere Datenmuster als maschinelle Lernalgorithmen verarbeiten können. LLMs und generative KI sind Teilbereiche des Deep Learning. Es gibt viele künstliche neuronale Netze, die für bestimmte Aufgaben eingesetzt werden können.
Alle diese neuronalen Netze basieren auf einem „Perzeptron“, dem grundlegendsten neuronalen Netz, das für die binäre Klassifizierung verwendet wird. Das Perceptron besteht aus einer einzigen Schicht von Neuronen, die eine Eingabeschicht aufnimmt, mit Gewichten versieht und sie an die Ausgabeschicht weiterleitet.
Feedforward Neural Network (FNN)
Feedforward ist eines der ersten künstlichen neuronalen Netzwerke, das entwickelt wurde und aus einer Gruppe von mehreren Perceptrons in jeder Schicht besteht. Es ist auch als mehrschichtiges Perzeptron (Multi-Layer Perceptron, MLP) bekannt. Er gibt Informationen nur in eine Richtung weiter – nämlich in die Vorwärtsrichtung – und es gibt keine Schleifen. Feedforward Neural Networks haben eine Eingabe, eine Ausgabe und eine versteckte Schicht, die die Eingabe verarbeitet. FNNs werden für überwachtes Lernen verwendet, wenn die Daten nicht zeitabhängig oder sequentiell sind.
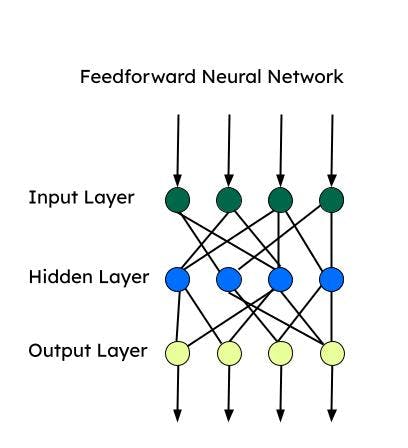
Convolutional Neural Networks (CNN)
CNNs sind eine Art von FNN und werden für komplexe Bildklassifizierungsaufgaben, Computer Vision, Bildanalyse und natürliche Sprachverarbeitung verwendet. Ein CNN betrachtet jeweils einen Bildausschnitt und geht mit einer geringeren Anzahl von Parametern vor, um die wichtigsten Merkmale zu lernen/extrahieren. Die Funktionsextraktion erfolgt mithilfe von Kerneln während einer Faltungsoperation.
Recurrent Neuronal Networks (RNN)
RNNs eignen sich eher für sequentielle Daten, bei denen die Reihenfolge der Eingabe entscheidend ist. Die sequenziellen Informationen werden über eine Schleife im Eingabe-Layer erfasst. RNNs sind besser für Zeitreihendaten und die Verarbeitung natürlicher Sprache geeignet. Langes Kurzzeitgedächtnis (LSTMs) sind Arten von RNN, die über Speicherzellen verfügen, um Abhängigkeiten der sequentiellen Daten zu speichern. LSTMs sind recht gut in der Spracherkennung, Stimmungsanalyse und Übersetzung.
Autoencoder
Autoencoder besteht aus einem Encoder und Decoder. Encoder komprimieren die Dimensionen der Daten in einen weniger dimensionalen Raum (latenter Raum). Decoder rekonstruieren die Eingabedaten mit Hilfe des latenten Raums. Autoencoder können zum Entrauschen, zur Dimensionsreduzierung und zum Lernen von Merkmalen verwendet werden.
Self-Attention-Netzwerke (SANs)
Die Encoder-Decoder-Architektur kann sich kürzere Sequenzen merken. Es kann jedoch sein, dass einige Informationen (insbesondere Informationen, die zuerst empfangen werden) in einer langen Sequenz vergessen werden. Mit einem Aufmerksamkeitsmechanismus kann der Decoder die gesamte Sequenz beachten und den Kontext der gesamten Sequenz verwenden, um die Ausgabe zu erzeugen. Die Selbstaufmerksamkeit ermöglicht es, den gesamten Eingabetext auf einmal zu verarbeiten und stellt Beziehungen zwischen allen Wörtern in der gesamten Sequenz her. Aufgrund dieser Eigenschaft arbeitet die Selbstaufmerksamkeit bei weitreichenden Abhängigkeiten schneller als ein RNN oder CNN.
Geschichte der künstlichen Intelligenz
Obwohl die ersten Vorstellungen bereits 750 v. Chr. durch Bücher und Ideen auf der Grundlage von Science Fiction und denkenden Maschinen entstanden, wurde der erste Grundstein für neuronale Netze 1947 von Walter Pitts und Warren McCulloch gelegt, die ein Rechenmodell für die Architektur neuronaler Netze entwickelten.
1950 führte Alan Turing den Turing-Test ein, um die Intelligenz von Maschinen zu definieren.
Der Begriff Künstliche Intelligenz wurde 1956 geprägt, als John McCarthy einen KI-Workshop organisierte und den Begriff als die Wissenschaft und Technik definierte, die Maschinen intelligent macht. In den frühen 1960er Jahren entwickelte Frank Rosenblatt den ersten Computer – Perceptron –, der aus Versuch und Irrtum lernen sollte. Später, 1963, gründete John McCarthy das KI-Labor.
Der nächste große Durchbruch in der KI kam durch die Expertensysteme, wissensbasierte Computersysteme, die die Entscheidungsfähigkeit eines menschlichen Experten nachahmen konnten. Diese Systeme waren recht erfolgreiche Formen der KI und wurden im Gesundheitswesen, in Kampf- und Trainingssimulatoren und als Hilfsmittel für das Missionsmanagement eingesetzt.
In den 1980er Jahren wurde die künstliche Intelligenz zu einer Industrie, und es wurden Milliarden von Dollar in Expertensysteme, Bildverarbeitungssysteme und Robotik investiert.
Im Jahr 1997 weckte die Entwicklung von Deep Blue, dem Schachcomputer von IBM, der den damaligen Schachweltmeister besiegte, weiteres Interesse an künstlicher Intelligenz, und es kam zu rasanten Entwicklungen auf diesem Gebiet.
Um 2010 stellten Forscher, die sich mit der Übersetzung natürlicher Sprache befassten, fest, dass Modelle, die mit großen Mengen unterschiedlicher Textdaten gefüttert wurden, im Vergleich zu Modellen mit regelbasierten Systemen weitaus bessere Ergebnisse erzielten.
2011 kamen persönliche Assistenten wie Cortana, Siri und Alexa auf den Markt, die durch natürliche Sprachverarbeitung Fragen beantworten und Aufgaben ausführen können.
Im Jahr 2014 begannen Sprachmodelle, den Kontext zu verstehen, in dem ein Wort erschien. Weitere Arbeiten führten zu allgemeinen Sprachmodellen, die Basismodelle oder Foundation Models darstellten, die für einen bestimmten Anwendungsfall oder eine bestimmte Domäne weiter entwickelt werden konnten.
Diese Foundation Models haben uns zu generativer KI und großen Sprachmodellen (LLMs) wie ChatGPT geführt.
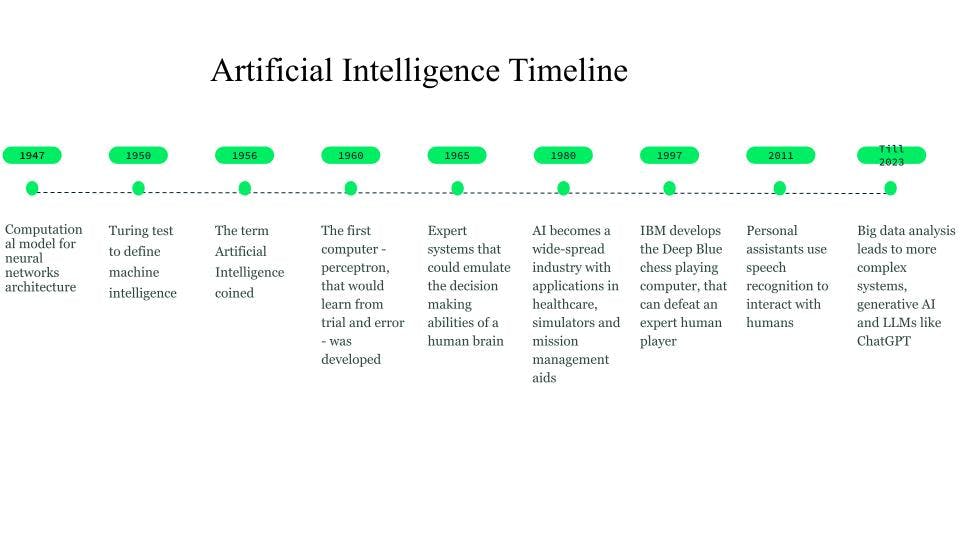 Geschichte und Zeitleiste der KI
Geschichte und Zeitleiste der KI
Arten von KI
Eine grobe Klassifizierung der künstlichen Intelligenz auf der Grundlage ihrer Fähigkeiten ist Narrow (oder schwache) AI und Strong AI. Durch Forschung und Fortschritte im Bereich des maschinellen Lernens, des Deep Learning und der KI bewegen wir uns von schwacher KI zu starker KI.
Schwache KI
Schwache KI/Narrow AI, oder Artificial Narrow Intelligence (ANI), sind Systeme, die für bestimmte Aufgaben trainiert wurden und aufgrund der Daten, auf denen sie trainiert wurden, nur begrenzte Fähigkeiten haben. Sie werden auch als herkömmliche KI-Systeme bezeichnet, bei denen das System auf der Grundlage einer Reihe von Eingaben und Regeln intelligent reagieren kann. Sie kann jedoch nichts Neues erschaffen.
Traditionelle oder schwache KIs werden in zwei weitere Kategorien eingeteilt: reaktive Maschinen und begrenzter Speicher.
Reaktive Maschinen
Die älteste Form der künstlichen Intelligenz waren die reaktiven Maschinen, die über keinen Speicher verfügten. Sie können jedoch die Fähigkeit eines Menschen nachahmen, auf verschiedene Reize zu reagieren. Sie können nicht aus ihren Erfahrungen lernen (kein Speicher) und basieren ihre Reaktion auf einer begrenzten Kombination von Eingaben. Die Maschine Deep Blue von IBM ist eine reaktive Maschine.
KI mit begrenztem Speicher
Systeme mit begrenztem Speicher verfügen über ein Gedächtnis und können auf der Grundlage der bereitgestellten Eingabedaten lernen und Entscheidungen treffen. Die meisten KIs, die wir sehen – selbstfahrende Autos, Chatbots, persönliche Assistenten wie Alexa und Empfehlungssysteme wie das von Netflix – sind alles Beispiele für KIs mit begrenztem Speicher.
Starke KI
Mit der Innovation von ChatGPT und anderen ähnlichen generativen KI-Modellen treten wir langsam in die Phase der starken KI ein. Generative KI ist eine Art KI der nächsten Generation, die auf der Grundlage von Benutzereingaben etwas Neues schaffen kann. ChatGPT ist ein Beispiel für generative KI basierend auf dem Large Language Model (LLM). Im Bereich der starken KI ist noch viel Arbeit zu leisten, die wie folgt kategorisiert werden kann:
Theory of Mind (ToM)
ToM ist eine kognitive Fähigkeit, die verschiedenen mentalen Zustände – wie Überzeugungen, Gedanken und Gefühle anderer – zu verstehen, um deren Verhalten und Handlungen zu erklären. Forscher arbeiten an der Anwendung von ToM auf KI mit dem Ziel, KI-Systeme in die Lage zu versetzen, menschliche Emotionen und Geisteszustände zu verstehen. ChatGPT, das neue KI-System, das mit Menschen in natürlicher Sprache interagieren und neue Inhalte produzieren kann, hat während der Tests eine Form von Theory of Mind gezeigt. Allerdings verfügt es immer noch nicht über die Fähigkeit, Wünsche, Überzeugungen oder Emotionen zu verstehen. Die Antworten von ChatGPT basieren auf Daten und gemeinsamen Mustern.
Artificial General Intelligence (AGI)
AGI ist die nächste Stufe der KI-Entwicklung, bei der sich ein KI-System oder -Agent genau wie ein Mensch verhält, einschließlich des eigenständigen Aufbaus mehrerer Kompetenzen und Funktionen, der Bildung von Verbindungen und Verallgemeinerungen, mit wenig oder gar keinem Training.
Selbstbewusstsein
Die nächste Stufe ist der Punkt der KI-Singularität, an dem sich die Maschinen ihrer selbst bewusst werden. Sie haben ihre eigenen Wünsche, Überzeugungen und Emotionen und verstehen auch die Emotionen, Wünsche und Überzeugungen von Menschen. Selbstlernende Agenten können im Gesundheitswesen und in der Robotik eingesetzt werden und erweisen sich im Vergleich zu Menschen als leistungsfähiger und genauer in der Ausführung von Aufgaben.
Künstliche Superintelligenz (Artificial Super Intelligence, ASI)
Selbstbewusste KI kann zu ASI führen, bei der KI-Agenten superintelligent werden und den Menschen in Bezug auf Werte und Motive übertreffen können. Selbstlernende KI und ASIs könnten Probleme mit der Beschäftigung und der Ethik aufwerfen, für die Forscher und Regierungen wachsam sein und Regeln und Richtlinien aufstellen müssen. Dies sind jedoch weit hergeholte Ziele, deren Erreichung Jahrzehnte dauern kann.
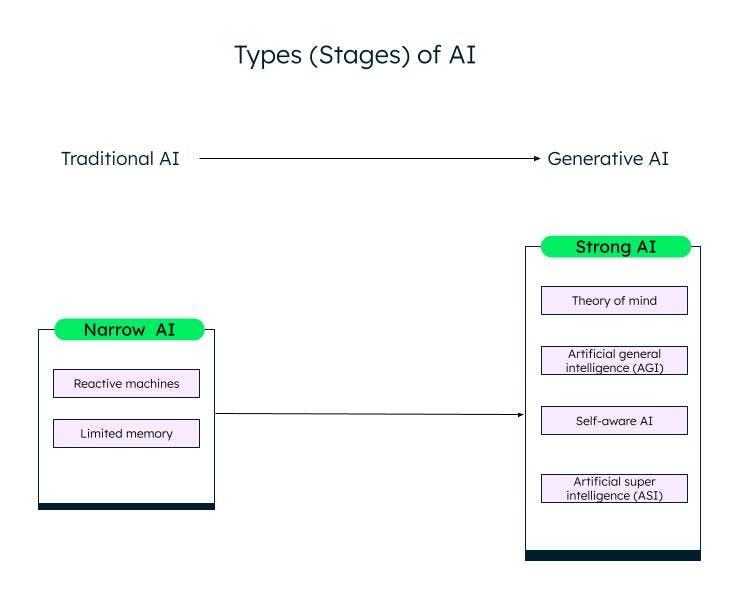 Verschiedene Stufen (Typen) von KI
Verschiedene Stufen (Typen) von KI
Foundation Models
Foundation Models sind verallgemeinerte künstliche tiefe neuronale Netzwerke, die auf riesigen Mengen unstrukturierter Daten trainiert wurden. Sie sind als Allzweckmodelle konzipiert. Wir können spezifischere Modelle für KI- und maschinelle Lernaufgaben erstellen, indem wir diese vortrainierten Foundation Models anpassen.
Ein Foundation Model wie das Large Language Model (LLM), das auf Textdaten trainiert wurde, kann beispielsweise für eine Vielzahl von Aufgaben wie Information Retrieval und Frage-Antwort verwendet werden. Generativer vorab geschulter Transformator oder GPT (bei dem der berühmte ChatGPT basiert) und BERT (bidirektionale Encoder-Repräsentationen von Transformatoren) sind Beispiele für LLM-Grundlagenmodelle. ResNet (Residual Network) ist ein beliebtes Computer-Vision-Grundlagenmodell für die Bildklassifizierung und Computer-Vision-Aufgaben. Foundation Models sind sehr anpassungsfähig und können sich selbst überwachen und durch Aufforderungen und Feinabstimmung improvisieren.
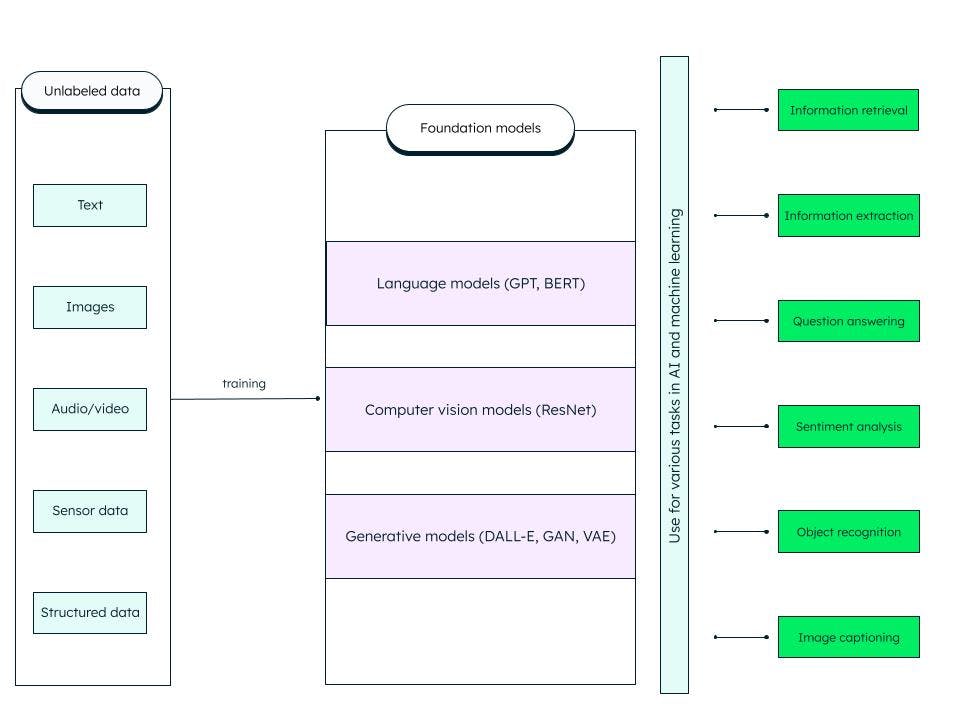
Was beinhaltet das Foundation Model?
Generative KI
KI-Technologien können neue Inhalte wie Bilder, Videos, Audios, Texte und so ziemlich alles andere produzieren – eine solche KI, die in der Lage ist, Inhalte zu generieren, wird generative KI genannt!
Generative KI basiert auf Foundation Models, die Aufgaben wie Klassifizierung, Satzvervollständigung, Generierung von Bildern oder Sprache und synthetische (künstlich erzeugte) Daten durchführen können. Foundation Models werden genau auf die konkrete generative Aufgabe abgestimmt.
Der Erfolg eines generativen KI-Modells hängt von der Qualität und Vielfalt der Daten sowie von der Geschwindigkeit der Generierung ab.
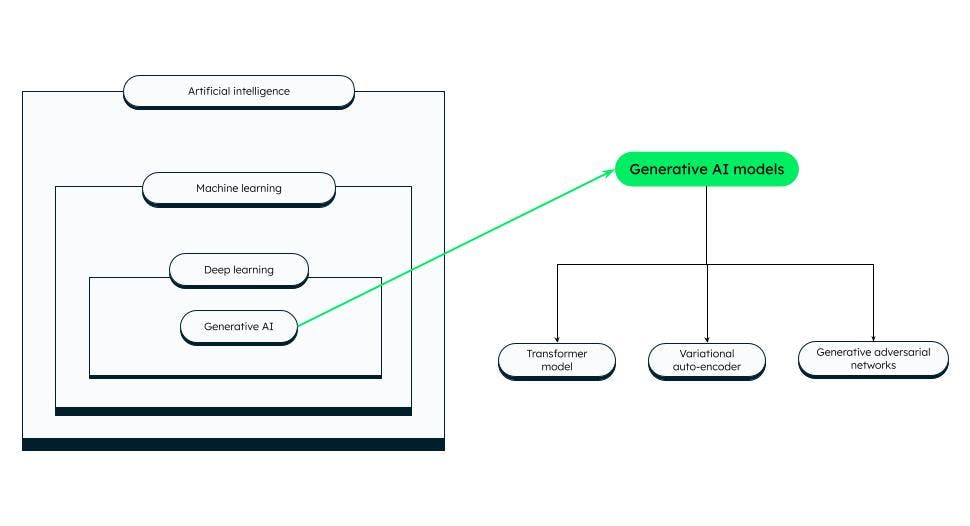 Generative KI-Modelle
Generative KI-Modelle
Es gibt verschiedene Kategorien von generativen KI-Modellen, von denen einige besonders bekannt sind:
Transformations-Modell
Transformations-basierte Architekturen haben sich bei der Identifizierung von kontextuellen Beziehungen zwischen Wörtern (Daten) als recht genau erwiesen. Sie werden für die Texterstellung, die maschinelle Übersetzung und die Sprachmodellierung verwendet. LLMs, wie GPT (verwendet in ChatGPT), sind ein Beispiel für die Transformations-Architektur.
Aufmerksamkeit ist alles, was Sie benötigen!
Das Transformations-Modell arbeitet mit einem Selbstbeobachtungsmechanismus, bei dem die Wichtigkeit jedes Elements in einer Eingabesequenz während der Verarbeitung des Textes gewichtet wird, wodurch die Kontextinformationen effektiv erfasst werden.
Wenn Sie beispielsweise den englischen Text „I love to write about artificial intelligence“ (Ich schreibe gerne über künstliche Intelligenz) ins Spanische übersetzen möchten, würde das Transformations-Modell diese Wortfolge (Token) an den Encoder (neuronales Netzwerk) weitergeben. Die Eingabewörter werden alle parallel in eine numerische Vektordarstellung (Worteinbettungen) umgewandelt, die aus der Abfrage (der benötigten Transformation), den Schlüssel- (Eingabe) und den Wertvektoren (Ausgabe) besteht.
Für das Wort “Liebe“ in unserem Satz hätten wir zum Beispiel die Vektoren q_love, k_love und v_love.
Es wird eine Matrix mit dem Ähnlichkeitswert jedes Wortes zu einem anderen erstellt. Zum Beispiel würde die Ähnlichkeit des Wortes „love“ mit allen anderen Wörtern des Satzes erzeugt werden – eine höhere Punktzahl bedeutet mehr Ähnlichkeit.
Der nächste Schritt ist die Berechnung der Aufmerksamkeitsgewichte, die bestimmen, wie viel Bedeutung jedem Wort im Satz im Verhältnis zum Hauptschlüsselwort („love“ in unserem Fall) beigemessen werden soll.
Fügen Sie dann die Positionskodierungen zu den Vektordarstellungen hinzu. Positionsbezogene Einbettungen (Ähnlichkeit + Positionskodierung) helfen dem Decoder (einem anderen neuronalen Netz) bei der Entscheidung, in welcher Reihenfolge die Ausgabetoken (Wörter) platziert werden sollen.
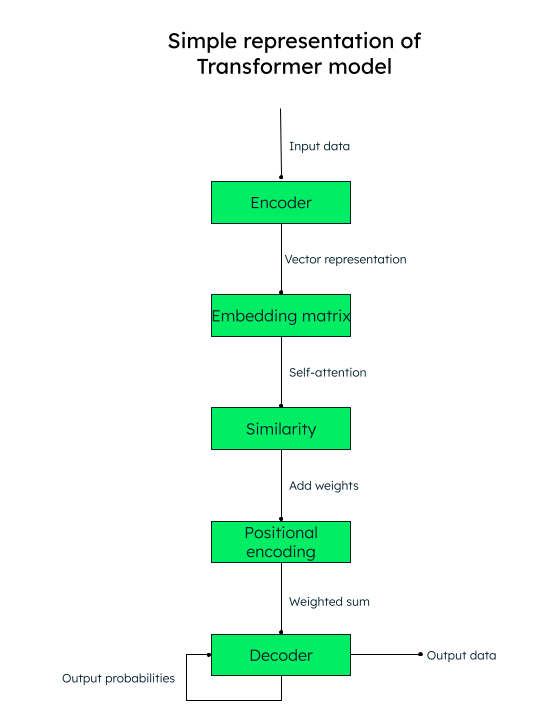
Darstellung des Transformations-Modells
Variational Auto-Encoder (VAEs)
VAEs sind sehr beliebt für die Bilderzeugung, Datenkomprimierung und Bildrauschunterdrückung. In einem VAE nimmt das neuronale Netz des Encoders die Eingabedatenpunkte und ordnet sie einer latenten Raumdarstellung zu. Ein latenter Raum ist die Darstellung von Daten in einer niedrigeren Dimension, indem die wichtigsten Merkmale der Daten extrahiert und andere Funktionen verworfen werden. Das neuronale Decoder-Netzwerk rekonstruiert die Ausgabedaten auf der Grundlage der latenten Darstellung.
Generative Adversarial Networks (GANs)
GANs werden häufig verwendet, um realistische Bilder, Kunst, Deepfake-Videos, Bild-zu-Bild-Übersetzungen und hochauflösende Bilder zu erstellen. Ein GAN besteht aus einem Generator (neuronales Netzwerk), der zufälliges Rauschen oder Saatgut als Eingabe nimmt und synthetische Datenmuster (wie ein Bild) erzeugt. Die synthetischen Datenproben werden dann an ein anderes neuronales Netzwerk, Discriminator, weitergeleitet, das mithilfe einer binären Klassifizierung feststellt, ob die Proben gefälscht oder echt sind. Durch das kontradiktorische Training werden der Generator und der Diskriminator gleichzeitig trainiert, bis ein Nash-Gleichgewicht erreicht ist, bei dem der Generator in der Lage ist, qualitativ hochwertige realistische Daten (wie Bilder) zu produzieren und der Diskriminator diese genau als echt oder gefälscht kategorisiert.
Large Language Model (LLM)
LLMs sind ein Foundation Model, das auf riesigen Datensätzen trainiert und eine nahezu genaue und ansprechende Erfahrung für die Benutzer bietet. Um solche Modelle erstellen zu können, müssen Sie riesige Datenmengen aus verschiedenen Quellen erfassen, sie korrekt speichern und bei Bedarf auf der Grundlage ihrer Relevanz verarbeiten und abrufen.
LLMs können zur allgemeinen Problemlösung eingesetzt werden, z. B. zur Beantwortung von Fragen, zur Texterstellung, zur Textklassifizierung und -zusammenfassung sowie zur Feinabstimmung mit Hilfe von Tuning und Prompting, um auf einem minimalen Datensatz für die Lösung bestimmter Probleme zu trainieren.
Wie funktioniert ein LLM?
Foundation Models lernen aus Datenmustern und produzieren eine flexible, verallgemeinerbare Ausgabe, die dann auf verschiedene spezifische Fälle angewendet werden kann. Eine solche Instanz ist das LLM, das für textbasierte Eingaben angewendet wird.
LLMs bestehen aus Daten, Architektur und Schulungen. Bei den Daten handelt es sich in der Regel um Petabytes an dicken Büchern, Gesprächen und Textinhalten. Die Architektur ist ein tiefes neuronales Netzwerk und im Fall von GPT ist es der Transformator. Während des Trainings lernt das Modell, das nächste Wort eines bestimmten Satzes vorherzusagen.
Es gibt jedoch drei Probleme mit dem LLM:
Wenn Informationen entwickelt oder geändert wurden, nachdem das Modell vollständig trainiert wurde, weiß das Modell nichts davon und könnte veraltete Ergebnisse liefern. Wenn Sie das Modell zum Beispiel fragen: „Nennen Sie mir eine Liste guter Comedy-Filme der letzten 6 Monate“, wäre das Modell dazu nicht in der Lage, wenn es nicht vor 6 Monaten trainiert wurde!
Das Modell könnte falsche Informationen in seiner internen Darstellung haben.
Das Modell hat keinen Zugriff auf Ihre privaten Daten und könnte auf der Grundlage begrenzter Kenntnisse verzerrte oder unvollständige Informationen liefern.
Retrieval Augmentation Generation (RAG)
Das RAG-KI-Framework zielt darauf ab, die oben genannten Probleme zu lösen und die Qualität der LLM-Antworten zu verbessern, indem es das Modell mit grundlegender Wahrheit auf einer externen Wissensbasis versorgt, die die intern im LLM dargestellten Informationen ergänzt. Dies verringert die Wahrscheinlichkeit, dass das Modell ein nicht vorhandenes Muster oder Objekt falsch identifiziert (Halluzinationen) sowie falsche, irreführende und veraltete Informationen.
Die Retrieval-Architektur nutzt einen Vektorspeicher und erweitert die Leistungsfähigkeit von LLM durch die Vektorsuche.
MongoDB Atlas, die einheitliche Plattform für Entwicklerdaten, bietet innerhalb der Plattform eine Vektorsuche, die Sie in wenigen einfachen Schritten einrichten können, um die Ausgabe Ihrer LLM zu verbessern und genauere Ergebnisse zu erzielen.
Vektorsuche
Im vorigen Abschnitt haben wir das Transformations-Modell kennengelernt und erfahren, dass Vektoren numerische Darstellungen von Textdaten sind. Die Vektordarstellung unseres vorherigen Satzes „I love to write about artificial intelligence“ könnte zum Beispiel so aussehen: „I love to...“ = [0.33, 0.45, 0.72, -0.23.....]
Die obige Vektordarstellung enthält die Beziehung zwischen den einzelnen Wörtern, z. B. wie das Wort „artificial“ mit dem Wort „intelligence“ oder dem Wort „write“ zusammenhängt oder in welchem Kontext das Wort „love“ in diesem Satz steht.
Diese Vektoren werden (wie wir beim Transformatormodell gesehen haben) erzeugt, indem die Eingabedaten durch ein tiefes neuronales Netzwerk (Encoder) geschickt werden.
In Wirklichkeit können die Vektordarstellungen eine beliebige Anzahl von Dimensionen haben. Je mehr Parameter die Daten haben, desto mehr Dimensionen gibt es. Um diese Zahlen zu verstehen und zu begreifen, was passiert, nachdem diese Vektoren erzeugt wurden, lassen Sie uns zum besseren Verständnis ein zweidimensionales Diagramm erstellen.
Alle Vektoren werden entsprechend ihrer numerischen Darstellung gezeichnet. Beachten Sie, dass die Worteinbettungen (Vektoren) mit ähnlicher Bedeutung nahe beieinander dargestellt werden und so einen Cluster bilden.
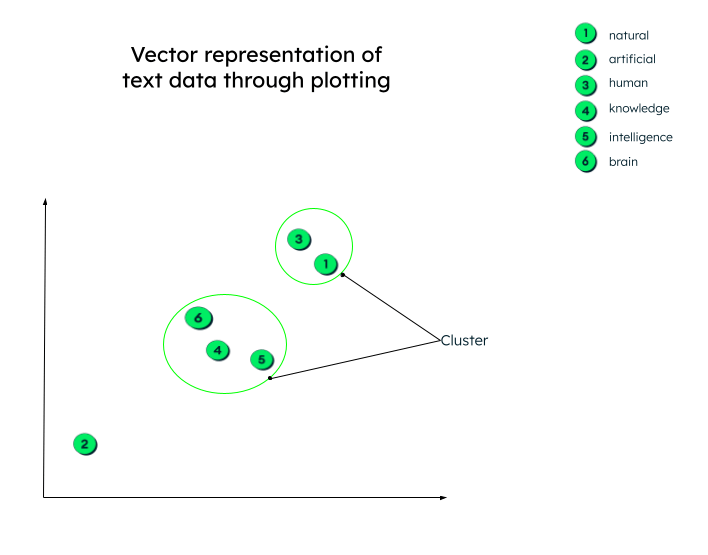 Grafische Darstellung von Vektoren
Grafische Darstellung von Vektoren
Es kann viele Kontexte geben, in denen die Daten gruppiert werden können. Die Beziehung hängt davon ab, wie der Encoder die Quelldaten einbettet und wie die Entfernung zwischen den Vektoren berechnet wird. Im folgenden Beispiel können zwei Arten von Beziehungen aufgebaut werden:- Both cat and dog are domestic animals, while tiger and wolf are wild animals. - Cat und tiger gehören zur gleichen Familie, während dog und wolf derselben Tierfamilie angehören.
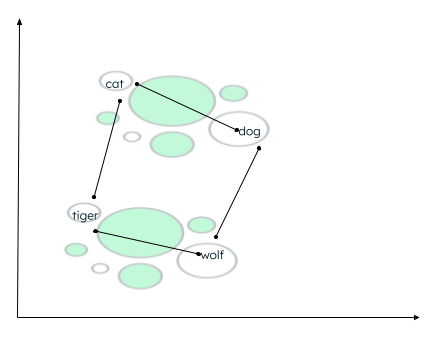 Berechnung der Entfernung ähnlicher Wörter
Berechnung der Entfernung ähnlicher Wörter
Eine Ähnlichkeitsfunktion bestimmt, welche Wörter näher beieinander liegen, und kennzeichnet eng beieinander liegende Wörter als Nachbarn. Diese Gruppierung/Clusterbildung erfolgt mit dem k-nearest neighbor Algorithmus, wobei der Wert von k die Anzahl der zu identifizierenden Nachbarn angibt. Um die Ähnlichkeit zu finden, unterstützt die Vektorsuche viele Methoden, wie z. B. das Finden des:
- Euklidischen Abstands zwischen den Enden der beiden Vektoren.
- Cosinus (Winkel) zwischen den beiden Vektoren.
- Punkt-(Skalar-) Produkt der Vektoren.
MongoDB Atlas bietet die Vektorsuchfunktionen innerhalb der Atlas-Plattform selbst, durch KI-Frameworks, und unterstützt alle oben genannten Ähnlichkeitsfunktionen.
MongoDB Atlas Vector Search
MongoDB hat die Vektorsuche immer in zwei Dimensionen unterstützt. Allerdings ermöglicht die neue Vektorsuche durch die Einbettung leistungsstarke Möglichkeiten und ermöglicht höhere Dimensionen. Anwendungen können sowohl die Daten als auch die Vektoreinbettungen in die Datenbank schreiben. Die Datenvektoren werden unter Verwendung eines Encoder-Modells generiert. Bei der Atlas Suche wird der Algorithmus „Approximate Nearest Neighbor“ (ANN) über den Graphen „Hierarchical Navigable Small World“ (HNSW) verwendet. ANN ist eine Variante des k-nearest neighbor, aber mit einer höheren Abrufgeschwindigkeit.
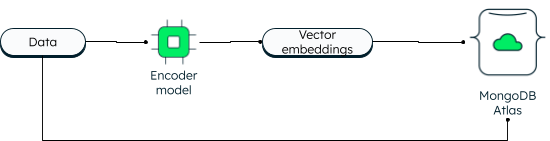
Wie Vektoren in MongoDB Atlas gespeichert werden
Beim Lesen wird die Abfrage kodiert und zusammen mit dem Zielvektor an die Aggregationsstufe „$search“ übergeben. Wenn Sie die Schritte lernen möchten, folgen Sie dem Tutorial zum Erstellen generativer KI-Anwendungen mit MongoDB.
Der Vorteil von Vektoren neben den operativen Daten ist, dass Sie auf alle Informationen innerhalb einer einzigen Plattform zugreifen können, sogar auf Ihre privaten Daten, die sonst nicht zugänglich wären.
Die Atlas-Vektorsuche vereinfacht Ihre Anwendungsarchitektur. Da Atlas vollständig verwaltet wird, kümmert sich die MongoDB Atlas-Plattform um alles, von der Datensynchronisation über die Sicherheit bis hin zum Datenschutz. Entwickler können mit der Datenbank und der Vektorsuche arbeiten, indem sie die vereinheitlichte MongoDB Query API verwenden. Sie können Atlas in über 125 Regionen bei drei großen Cloud-Anbietern bereitstellen. Atlas bietet Ihnen eine kontinuierliche Betriebszeit mit fortschrittlicher Automatisierung, die unabhängig vom Umfang der Anwendung eine hohe Leistung gewährleistet.
Einige prominente Anwendungsfälle der Atlas-Vektorsuche sind:
- Semantische Suche.
- Frage-Antwort-Systeme.
- Funktionsextraktion.
- Empfehlungs- und Relevanzbewertung.
- Synonymgenerierung.
- Bildersuche.
Wie funktioniert die Atlas-Vektorsuche?
Die Client-Anwendung sendet die Rohdaten. Das Vektoreinbettungsmodell erstellt Vektoren für jeden Text in der ursprünglichen Abfrage (Rohdaten). Frameworks wie Llamaindex und LangChain lassen sich gut mit MongoDB Atlas integrieren, um Einbettungen zu erstellen und Daten an MongoDB zu senden, um kontextbezogene Informationen hinzuzufügen. Die kontextbezogene Abfrage, die als Eingabeaufforderung bezeichnet wird, wird dann an ein LLM gesendet, das eine codierte Antwort generiert, das Vektoreinbettungsmodell (Decoder) verarbeitet und nach der Dekodierung an den Kunden gesendet wird.
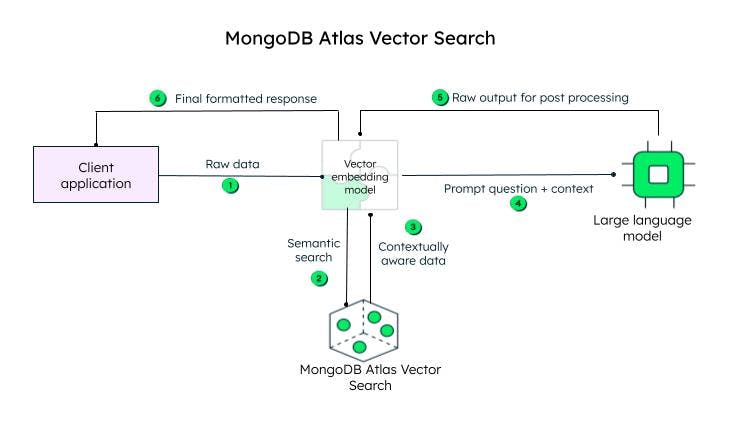 Schritte zum Erreichen der Vektorsuche in MongoDB Atlas
Schritte zum Erreichen der Vektorsuche in MongoDB Atlas
Vektoreinbettungen können im MongoDB-Datenbankdokument als Array von Floats zusammen mit dem Inhalt im Feld content_embeddings gespeichert werden.
_id: ObjectId('5091233df3f4925bd2f00371'),
Name: „sample_data“,
... andere Felder... ,
Inhalt: <unstructured data>,
content_embeddings: [0.9854344343432, 0.45255689075, -0.569745879343,...]Wenn die Anzahl der Dimensionen in den Eingabedaten höher ist, ist die Anzahl der Gleitkommazahlen höher.
Als Nächstes definieren Sie die Indexdefinition, indem Sie sie dem Definitionsgenerator hinzufügen:
{
"mappings": {
"fields": {
"content_embedding": {
{
"type": "knnVector",
"dimensions": 1536,
"similarity": "<euclidean | dotProduct | cosine>"
}
}
}
}
}Die Indexdefinition beinhaltet das Modell, das die Ähnlichkeitscluster, die Dimensionen und die Ähnlichkeitsfunktion (von den drei von MongoDB unterstützten Methoden) finden würde, die vom Modell verwendet würden.
Das war's auch schon! Nur zwei Schritte und du bist fertig.
Um suchen zu können, können Sie den Aggregationsoperator $search verwenden, indem Sie den knnBeta-Operator angeben und die Vektoreinbettungen der Abfrage im Feld vector angeben. Sie sollten auch den path der Inhaltseinbettungen angeben, nach denen bei der Vektorsuche gesucht werden soll. MongoDB bietet auch zusätzliche filters, um die Suche einzugrenzen und die Anzahl der nächsten Nachbarn, die der k-next Neighbor-Algorithmus zurückgeben soll, einzugrenzen.
[{
"$search": {
"knnBeta": {
//encoded query vectors
"vector": [0.983428349, -0,4234982300, 0.23023840922...............],
"path": "content_embedding",
"filters": {},
"k": <integer_value_of_num_of_nearest_neighbors>
}
}
}]Da sich sowohl die Vektoreinbettungen als auch die Daten auf derselben Plattform befinden, können Sie mit einer einzigen einheitlichen MongoDB-Abfrage-API auf Ihre betrieblichen Workloads und Vektoren zugreifen. Um Schritt für Schritt zu lernen, wie Sie die Funktionen nutzen, lesen Sie unser Tutorial zum Erstellen generativer KI-Apps mithilfe der Vektorsuche.
Wichtige KI-Anwendungsfälle
KI wird in verschiedenen Bereichen erfolgreich eingesetzt, darunter im Einzelhandel, im Gesundheitswesen und in der Fertigung. Einige beliebte Anwendungsfälle von KI sind:
Natural Language Processing (NLP): KI wird aktiv in der Stimmungsanalyse, bei virtuellen Assistenten, Chatbots, der Spracherkennung und der Textübersetzung eingesetzt. Wie wir oben gesehen haben, können KI-Systeme mit Hilfe von LLM und Vektorsuche Ausgaben in menschlicher Sprache produzieren.
Computer Vision: Mit modernen neuronalen Netzen sind KI-Systeme in der Lage, eine genaue Bildklassifizierung, Gesichts- und Objekterkennung sowie Bilderzeugung durchzuführen.
Empfehlungssysteme und Inhaltsfilterung: KI-Systeme sind in der Lage, Nutzern mithilfe von Deep Learning und maschinellen Lernmodellen Inhalte zu empfehlen, ohne dass ein Mensch eingreifen muss.
Gesundheitswesen: Die Technologie der künstlichen Intelligenz hat das Gesundheitswesen auf ein neues Niveau gehoben, indem sie Ärzte bei der Frühdiagnose von Krankheiten, der medizinischen Forschung und der Entdeckung von Medikamenten unterstützt und die elektronischen Gesundheitsdaten von Patienten sicher speichert.
Selbstfahrende Autos: Selbstfahrende Autos werden durch KI-Algorithmen, Sensordaten und Computer Vision angetrieben.
Robotik: Industrieroboter steigern die Produktivität, indem sie komplexe Aufgaben mit Genauigkeit ausführen. In ähnlicher Weise sind Serviceroboter in der Lage, ihre Aufgaben im Gesundheitswesen und im Gastgewerbe effizient zu erfüllen.
Ethischer Einsatz von AI, KI-Governance und Vorschriften
Angesichts der rasanten Entwicklungen auf dem Gebiet der KI ist es wichtig, Regeln und Vorschriften aufzustellen und ethische Überlegungen anzustellen, damit KI-Systeme fair, transparent und für den richtigen Zweck eingesetzt werden. Die KI-Ethik befasst sich mit den moralischen und ethischen Auswirkungen von KI-Tools und -Technologien, d. h. Fairness, Datenschutz, Transparenz und Verantwortlichkeit.
Das Framework, die Struktur und die Compliance-Regeln werden von der Regierung festgelegt, um einen verantwortungsvollen Einsatz von KI zu gewährleisten.
Die Regierung schafft auch KI-Vorschriften – d. h. rechtliche Rahmenbedingungen – um sicherzustellen, dass Datensicherheit, Verbraucherschutz und Sicherheitsstandards eingehalten werden.
KI-Tools und -Dienste
Daten sind der Kern aller KI-Operationen, und MongoDB ist eine Plattform, auf die Sie sich verlassen können, um leistungsstarke KI-Apps zu entwickeln. Als Datenbank mit einem flexiblen Schema bietet MongoDB eine zentralisierte Speicherlösung mit eingebauten Datenverwaltungsfunktionen, fortschrittlicher Datenverarbeitung, Echtzeitanalysen, Skalierbarkeit und vielem mehr. Einige andere beliebte Tools und Dienste sind:
ChatGPT: ChatGPT ist fast zum Alltag geworden, um einfache Fragen zu stellen, Urlaube zu planen, zu programmieren, Gedichte zu schreiben, Texte zusammenzufassen und vieles mehr.
Dall-E 2: Dall-E 2 ist ein OpenAI-Projekt, genau wie ChatGPT, und generiert Computergrafiken wie Bilder, Bilder und Zeichnungen aus Texteingaben.
Stable Diffusion 2: Dies ist ein Text-zu-Bild-KI-Tool für generative KI-Anwendungen. Im Gegensatz zu OpenAI-Tools, auf die über Browserportale zugegriffen wird, steht Stable Diffusion 2 zum Download und zur Installation zur Verfügung, und die Benutzer können öffentlich auf den Quellcode und die Algorithmen zugreifen.
FAQs
Was ist künstliche Intelligenz (KI)?
Die Fähigkeit von Maschinen, wie ein Mensch zu denken, zu lernen und Entscheidungen zu treffen, wenn sie mit verschiedenen Szenarien konfrontiert werden, wird als künstliche Intelligenz bezeichnet.
Wie funktioniert KI?
Künstliche Intelligenz (KI) umfasst maschinelles Lernen und Deep Learning, die beide aus mehreren Algorithmen bestehen, um den verschiedenen Anwendungsfällen gerecht zu werden. Diese Algorithmen arbeiten mit riesigen Datenmengen, die aus verschiedenen Quellen gesammelt, sortiert, umgewandelt und für die Einspeisung in die Algorithmen vorverarbeitet werden. Die Algorithmen verwenden Daten, um zu trainieren, Feedback zu erhalten und sich selbst zu verbessern, bis ein gewünschtes Ergebnis erzielt wird.
Warum ist künstliche Intelligenz wichtig?
AI ist wichtig, denn sie kann die Automatisierung alltäglicher und sich wiederholender Aufgaben ermöglichen, die Effizienz verbessern, menschliche Fehler reduzieren, prädiktive Analysen für eine schnellere und präzisere Entscheidungsfindung liefern, personalisierte Empfehlungen für Benutzer bereitstellen, bei der Diagnose von Krankheiten helfen, die Forschung in Medizin und Wissenschaft beschleunigen und Innovationen fördern.
Wann wurde KI erfunden?
Welche Arten von KI gibt es?
Was ist ein Beispiel für künstliche Intelligenz?
Das jüngste und beliebteste Beispiel für KI ist ChatGPT, das auf Fragen, die von Menschen durch Tippen gestellt werden, mit einer menschenähnlichen Antwort antworten kann. Es kann sich auch an den Kontext des Gesprächs erinnern. ChatGPT wird auf einem Large Language Model trainiert und durch Augmentierung weiter angereichert. MongoDB Atlas bietet eine großartige Plattform, um leistungsstarke generative KI-Apps mit jedem großen Cloud-Anbieter zu erstellen.