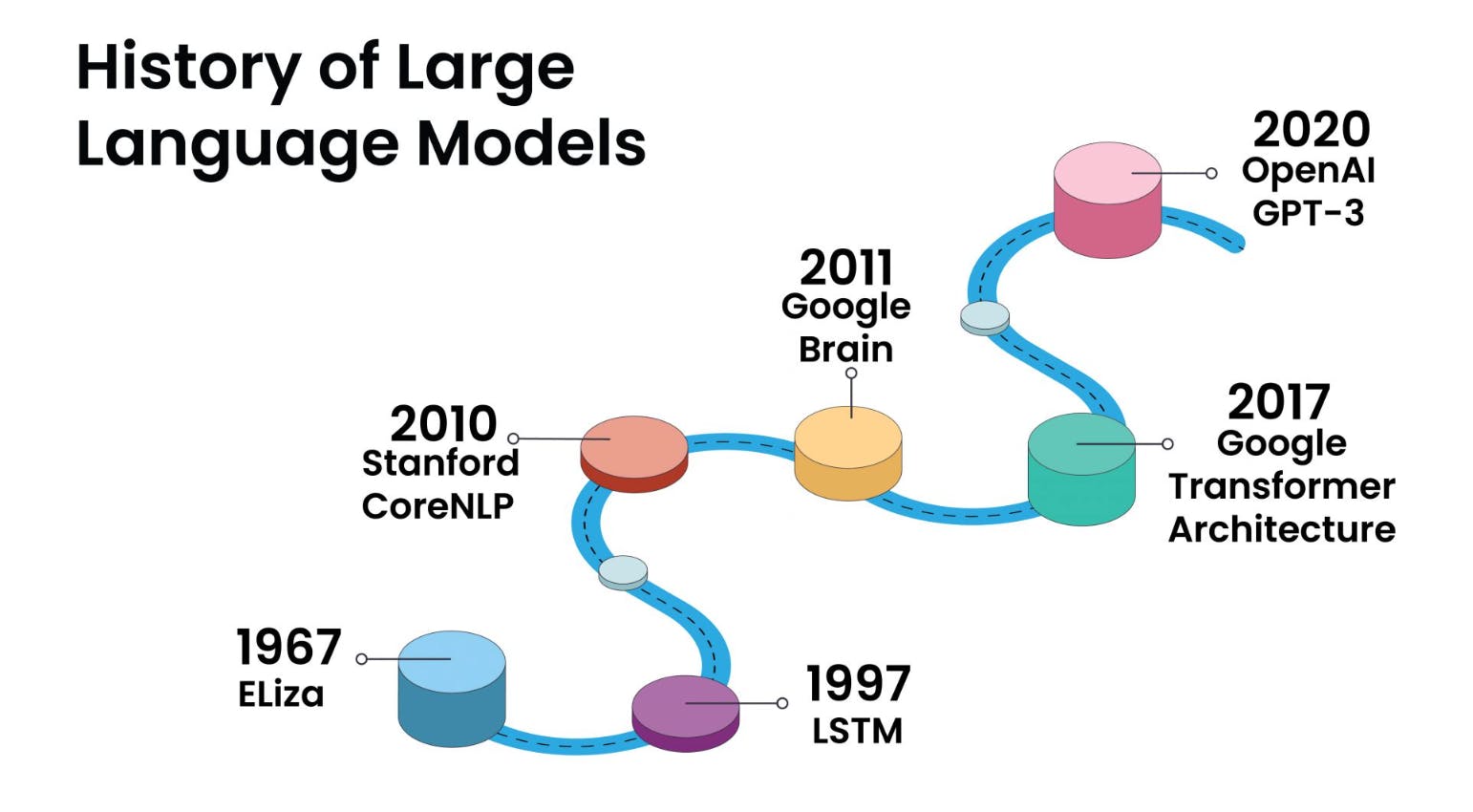
Ein Transformatormodell ist ein entscheidender Fortschritt in der Welt der künstlichen Intelligenz und der Verarbeitung natürlicher Sprache. Es stellt eine Art Deep-Learning-Modell dar, das bei verschiedenen sprachbezogenen Aufgaben eine transformative Rolle gespielt hat. Transformatoren wurden entwickelt, um menschliche Sprache zu verstehen und zu erzeugen, indem sie sich auf die Beziehungen zwischen Wörtern innerhalb von Sätzen konzentrieren.
Eines der charakteristischen Merkmale von Transformationsmodellen ist die Verwendung einer Technik, die als „Self-Attention“ bezeichnet wird. Diese Technik ermöglicht es diesen Modellen, jedes Wort in einem Satz zu verarbeiten und dabei den Kontext zu berücksichtigen, der durch andere Wörter im selben Satz gegeben ist. Dieses kontextuelle Bewusstsein ist eine signifikante Abkehr von früheren Sprachmodellen und ein wesentlicher Grund für den Erfolg von Transformatoren.
Transformatormodelle sind das Rückgrat vieler moderner KI-Sprachmodelle geworden. Durch den Einsatz von Transformationsmodellen konnten Entwickler und Forscher anspruchsvollere und kontextbewusste KI-Systeme entwickeln, die mit natürlicher Sprache auf zunehmend menschenähnliche Weise interagieren, was letztlich zu erheblichen Verbesserungen der Benutzererfahrungen und KI-Anwendungen führt.
Wie funktionieren KI-Sprachmodelle?
KI-Sprachmodelle funktionieren, indem sie Deep-Learning-Techniken nutzen, um menschliche Sprache zu verarbeiten und zu generieren.
- Datenerfassung: Der erste Schritt beim Training von LLMs besteht darin, einen umfangreichen Datensatz von Text und Code aus dem Internet zu sammeln. Dieser Datensatz umfasst ein breites Spektrum an von Menschen geschriebenen Inhalten, sodass die LLMs über eine vielfältige Sprachgrundlage verfügen.
- Pre-Training-Daten: Während der Pre-Training-Phase werden die LLMs mit diesem umfangreichen Datensatz konfrontiert. Sie lernen, das nächste Wort in einem Satz vorherzusagen, was ihnen hilft, die statistischen Beziehungen zwischen Wörtern und Sätzen zu verstehen. Dieser Prozess ermöglicht es ihnen, Grammatik, Syntax und sogar ein gewisses kontextuelles Verständnis zu erlangen.
- Feinabstimmung der Daten: Nach dem Pre-Training werden die LLMs für bestimmte Aufgaben fein abgestimmt. Dabei werden sie einem engeren Datensatz ausgesetzt, der sich auf die gewünschte Anwendung bezieht, z. B. Übersetzung, Sentimentanalyse oder Texterstellung. Die Feinabstimmung verfeinert ihre Fähigkeit, diese Aufgaben effektiv auszuführen.
- Kontextuelles Verständnis: LLMs berücksichtigen die Wörter vor und nach einem bestimmten Wort in einem Satz und ermöglichen so die Generierung kohärenter und kontextrelevanter Texte. Dieses Kontextbewusstsein unterscheidet LLMs von früheren Sprachmodellen.
- Aufgabenanpassung: Dank der Feinabstimmung können sich LLMs an ein breites Aufgabenspektrum anpassen. Sie können Fragen beantworten, menschenähnlichen Text generieren, Sprachen übersetzen, Dokumente zusammenfassen und vieles mehr. Diese Anpassungsfähigkeit ist eine der Hauptstärken von LLMs.
- Bereitstellung: Nach dem Training können LLMs in verschiedenen Anwendungen und Systemen eingesetzt werden. Sie unterstützen Chatbots, Content-Generierungs-Engines, Suchmaschinen und andere KI-Anwendungen und verbessern so das Benutzererlebnis.
Zusammenfassend lässt sich sagen, dass LLMs zunächst die Feinheiten der menschlichen Sprache durch Vortraining an umfangreichen Datensätzen erlernen. Anschließend optimieren sie ihre Fähigkeiten für bestimmte Aufgaben und nutzen dabei das Kontextverständnis. Diese Anpassungsfähigkeit macht sie zu vielseitigen Werkzeugen für eine Vielzahl von Anwendungen zur Verarbeitung natürlicher Sprache.
Darüber hinaus ist es wichtig zu wissen, dass die Auswahl eines bestimmten LLM für Ihren Anwendungsfall – ebenso wie die Prozesse des Pre-Trainings des Modells, der Feinabstimmung und anderer Anpassungen – unabhängig von Atlas (und damit außerhalb von Atlas Vector Search) erfolgt.
Was ist der Unterschied zwischen einem KI-Sprachmodell (LLM) und Natural Language Processing (NLP)?
Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) ist ein Bereich der Informatik, der sich mit der Erleichterung der Interaktion zwischen Computern und menschlicher Sprache befasst und sowohl die gesprochene als auch die geschriebene Kommunikation umfasst. Es geht darum, Computern die Fähigkeit zu verleihen, menschliche Sprache zu verstehen, zu interpretieren und zu manipulieren. Dazu gehören Anwendungen wie maschinelle Übersetzung, Spracherkennung, Textzusammenfassung und Beantwortung von Fragen.
Auf der anderen Seite entstehen KI-Sprachmodelle (LLMs) als eine spezielle Kategorie von NLP-Modellen. Diese Modelle werden anhand umfangreicher Text- und Codesammlungen rigoros trainiert, so dass sie in der Lage sind, komplizierte statistische Beziehungen zwischen Wörtern und Phrasen zu erkennen. Folglich sind LLMs in der Lage, Texte zu erstellen, die sowohl kohärent als auch kontextuell relevant sind. LLMs können für eine Vielzahl von Aufgaben verwendet werden, einschließlich der Erstellung von Texten, der Übersetzung und der Beantwortung von Fragen.
KI-Sprachmodell-Beispiele in realen Anwendungen
Verbesserter Kundenservice
Stellen Sie sich ein Unternehmen vor, das seinen Kundenservice verbessern möchte. Sie nutzen die Fähigkeiten eines umfangreichen Sprachmodells, um einen Chatbot zu erstellen, der Kundenanfragen zu ihren Produkten und Dienstleistungen beantworten kann. Dieser Chatbot durchläuft einen Trainingsprozess anhand umfangreicher Datensätze, die aus Kundenfragen, entsprechenden Antworten und detaillierten Produktdokumentationen bestehen. Was diesen Chatbot von anderen abhebt, ist sein tiefes Verständnis für die Absichten des Kunden, das es ihm ermöglicht, präzise und informative Antworten zu geben.
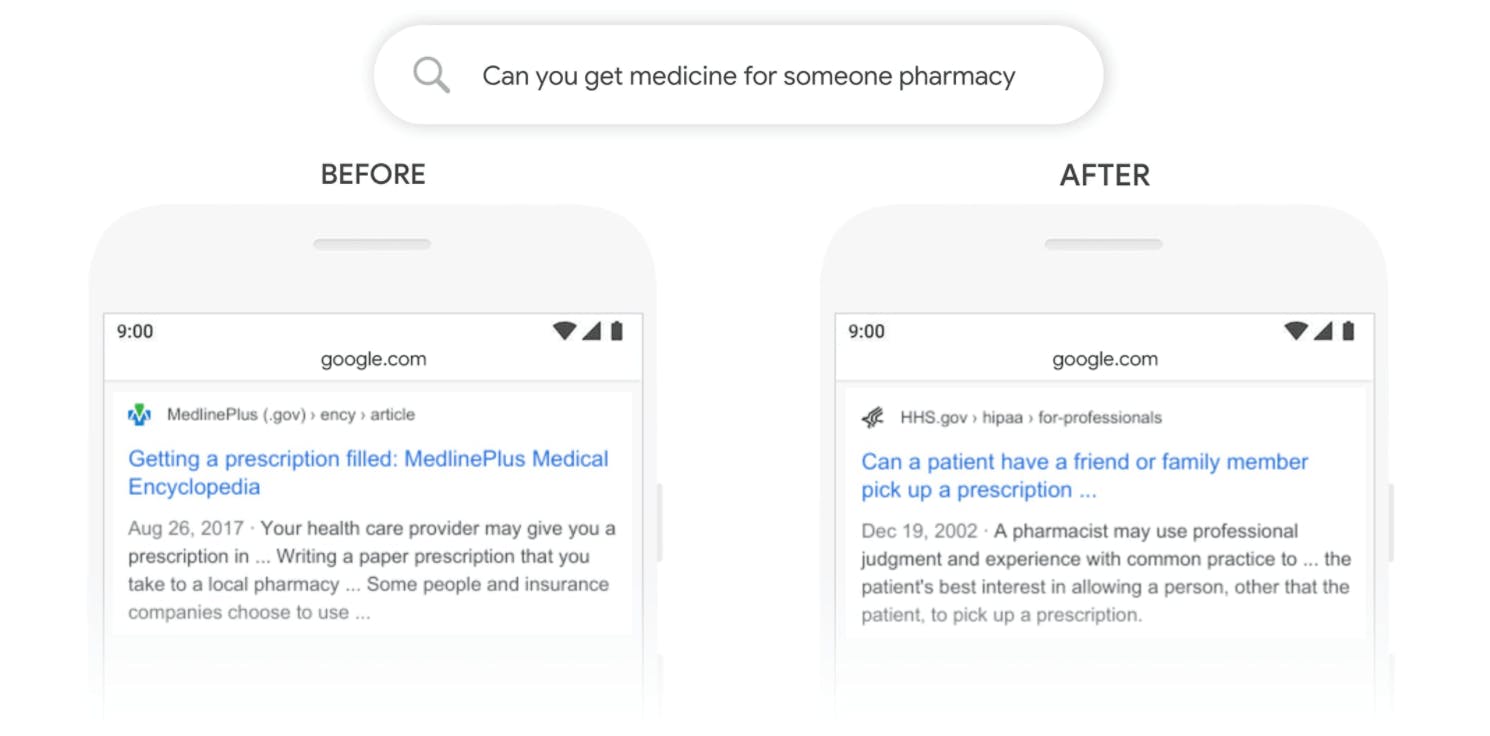
Intelligentere Suchmaschinen
Suchmaschinen sind ein Teil unseres täglichen Lebens, und LLMs treiben diese Suchmaschinen an und machen sie intuitiver. Diese Modelle können verstehen, wonach Sie suchen, auch wenn Sie es nicht perfekt formulieren, und die relevantesten Ergebnisse aus riesigen Datenbanken abrufen, um Ihr Online-Sucherlebnis zu verbessern.
Personalisierte Empfehlungen
Wenn Sie online einkaufen oder Videos auf Streaming-Plattformen ansehen, sehen Sie oft Empfehlungen für Produkte oder Inhalte, die Ihnen gefallen könnten. LLMs steuern diese intelligenten Empfehlungen, indem sie Ihr bisheriges Verhalten analysieren, um Ihnen Dinge vorzuschlagen, die Ihrem Geschmack entsprechen, und so Ihre Online-Erfahrungen maßgeschneiderter und persönlicher zu gestalten.
Erstellung kreativer Inhalte
LLMs sind nicht nur Datenverarbeiter, sie sind auch kreative Köpfe. Sie verfügen über Deep-Learning-Algorithmen, die Inhalte von Blogbeiträgen über Produktbeschreibungen bis hin zu Gedichten generieren können. Das spart nicht nur Zeit, sondern hilft Unternehmen auch dabei, ansprechende Inhalte für ihre Zielgruppen zu erstellen.
Durch die Einbeziehung von LLMs verbessern Unternehmen ihre Kundeninteraktionen, Suchfunktionen, Produktempfehlungen und die Erstellung von Inhalten und verändern damit letztlich die Tech-Landschaft.
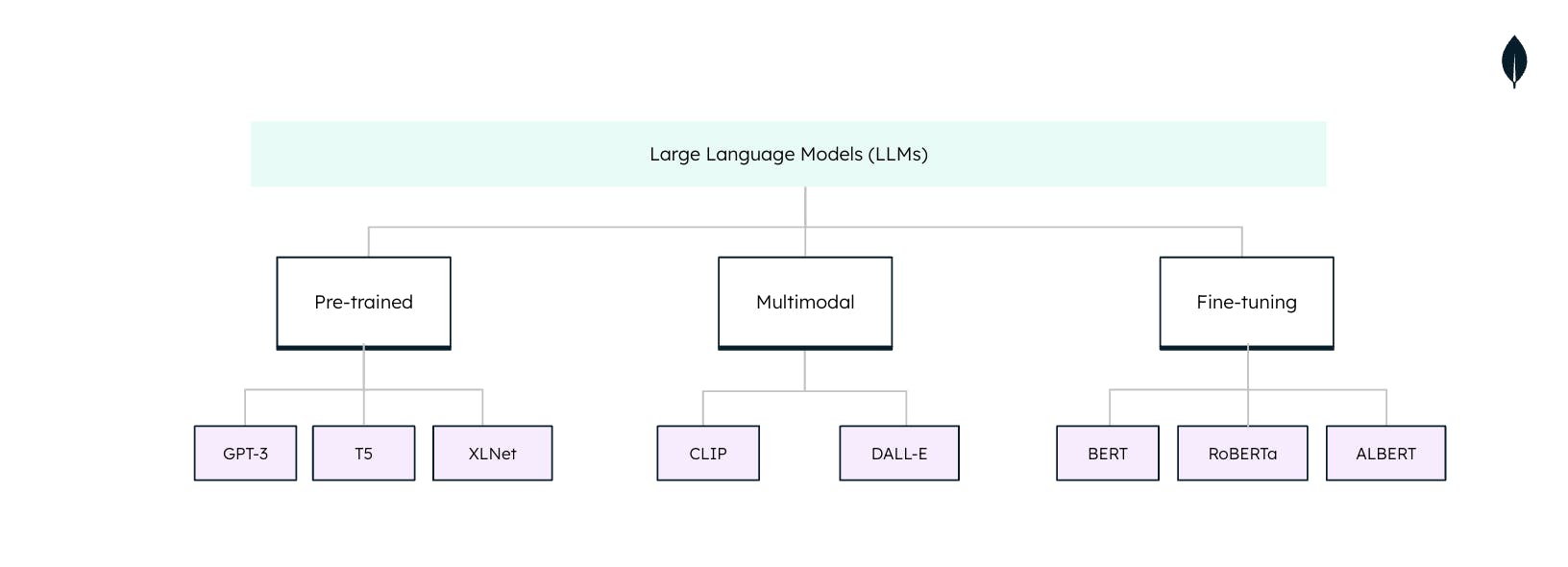
Arten von KI-Sprachmodellen
KI-Sprachmodelle (LLMs) sind keine Einheitsgröße, wenn sie in der natürlichen Sprachverarbeitung (NLP) eingesetzt werden. Jedes LLM ist auf spezifische Aufgaben und Anwendungen zugeschnitten. Diese Arten zu verstehen ist wichtig, um das volle Potenzial von LLMs auszuschöpfen: