
MongoDB and Databricks have succeeded in two complementary worlds: For MongoDB, the focus is making the world of data easy for developers building applications. For Databricks, the focus is helping enterprises to unify their data, analytics, and AI by combining a data lake's flexibility with the openness, performance, and governance of a data warehouse.
Traditionally, these operational and analytical functions have existed in separate domains built by different teams and serving different audiences. Though some will pretend a data warehouse can unify such disparate data and systems, the reality is this approach leaves you making false trade-offs where your developers, your data scientists, and, ultimately, your applications and customers suffer. Data warehouses are not designed to serve consumer-facing applications at scale and process machine learning in real time. It takes the unique application-serving layer of a MongoDB database, combined with the scale and real-time capabilities of a lakehouse, such as Databricks, to automate and operationalize complex and AI-enhanced applications at scale.
We observed that a large and growing population of joint customers has for years enabled the flow of data between our two platforms to run real-time businesses and enable a world of application-driven analytics, using MongoDB Connector for Apache Spark. So we asked ourselves: How could we make that a more seamless and elegant experience for these customers?
Today we're announcing that Databricks now features MongoDB as a data source within a Databricks notebook, thereby enabling data practitioners with an easier, more curated experience for connecting Databricks with MongoDB Atlas data. This notebook experience makes it simpler for enterprises to deliver real-time analytics, handle complex data warehouse/BI workloads, and to operationalize AI/ML pipelines using the MongoDB Spark Connector. In turn, developer and data teams can collaborate more closely on building a new generation of app-driven intelligence. MongoDB and Databricks are committed to further improve our integration in the coming months.
In this post, we'll explain how Databricks can be used as a real-time processing layer for data on MongoDB Atlas using the Spark Connector, extending MongoDB's built-in data processing capabilities like our aggregation framework. We'll also cover how to use Databricks' MongoDB notebook to make this even easier. In future posts we'll outline how to use MongoDB Atlas and Databricks Delta Lake to build sophisticated AI/ML pipelines.
Live application data plus the data lakehouse
MongoDB Atlas is a fully-managed modern database that powers a wide variety of workloads - supporting everything from simple CRUD operations to sophisticated data processing pipelines for analytics and transformation - all with a common query interface. With MongoDB Atlas you can isolate operational and analytical workloads using dedicated analytical nodes. Analytics nodes are read-only nodes that can be exclusively targeted by your queries
Let's look at an example. Assume you have long-running analytical queries that you want to run against your cluster and your operations team does not want these queries competing for resources with your regular operational workload. To address this, you add an analytics node to your cluster and then target it in your connection string using an Atlas replica set tag. You can connect to the analytical nodes to run sophisticated aggregation queries, BI and reporting workloads using the Atlas SQL interface, visualize your data using MongoDB Charts, or run Spark jobs using MongoDB’s Spark Connector.
For more complex data science and warehousing analytical queries, many enterprises choose the Databricks Lakehouse Platform. Enterprises can also benefit from enriching MongoDB data with data from other internal or external sources in the Databricks Lakehouse.
The Databricks Lakehouse Platform combines the best elements of data lakes and data warehouses to deliver the reliability, strong governance, and performance of data warehouses with the openness, flexibility, and machine learning support of data lakes. This unified approach simplifies your modern data stack by eliminating the data silos that traditionally separate and complicate data engineering, analytics, BI, data science, and machine learning. With Databricks notebooks, developers and analytics teams can collaboratively write code in Python, R, Scala, and SQL, plus explore data with interactive visualizations and discover new insights. You can confidently and securely share code with co-authoring, commenting, automatic versioning, Git integrations, and role-based access controls.
As good as MongoDB and Databricks are on their own, together we offer enterprises the unmatched ability to work with live application data across traditionally separate domains. This ability allows your teams to deliver what we call application-driven analytics. How does this work?
Using MongoDB and Databricks together
MongoDB and Databricks offer several ways to integrate the two systems, but the primary means is MongoDB’s Spark Connector. The Spark connector can be used within Databricks notebooks to directly query live application data managed in MongoDB collections and then loaded into data frames for further processing. You can also transform and/or enrich this data with data ingested from other sources using SparkSQL.
Queries issued by the Spark Connector can be pushed down to MongoDB's aggregation framework and indexes for pre-processing, significantly improving query efficiency (measured in milliseconds not seconds or minutes). Result sets generated from the Databricks notebooks can then be inserted back into MongoDB collections or can be pushed into Delta Lake for long-running analytics and machine learning.
Easier integration using Databricks' MongoDB Notebook
A Databricks notebook is a web-based interface that contains runnable code, visualizations, and explanatory text in the form of paragraphs. It lets personas, such as data scientists and data engineers, build linked sets of code in different languages and visualize results in a format in which they are used to working. Notebooks are great for collaboration and can be easily iterated on and improved.
MongoDB and Databricks created an example notebook that has sample code for:
Reading the data from MongoDB Atlas collections as is into Spark dataframes.
Pre-processing and filtering the data from Atlas collections using the aggregation framework, before passing into Spark dataframes.
Enriching/transforming the data using SparkSQL
Writing the enriched data back to the MongoDB Atlas collection.
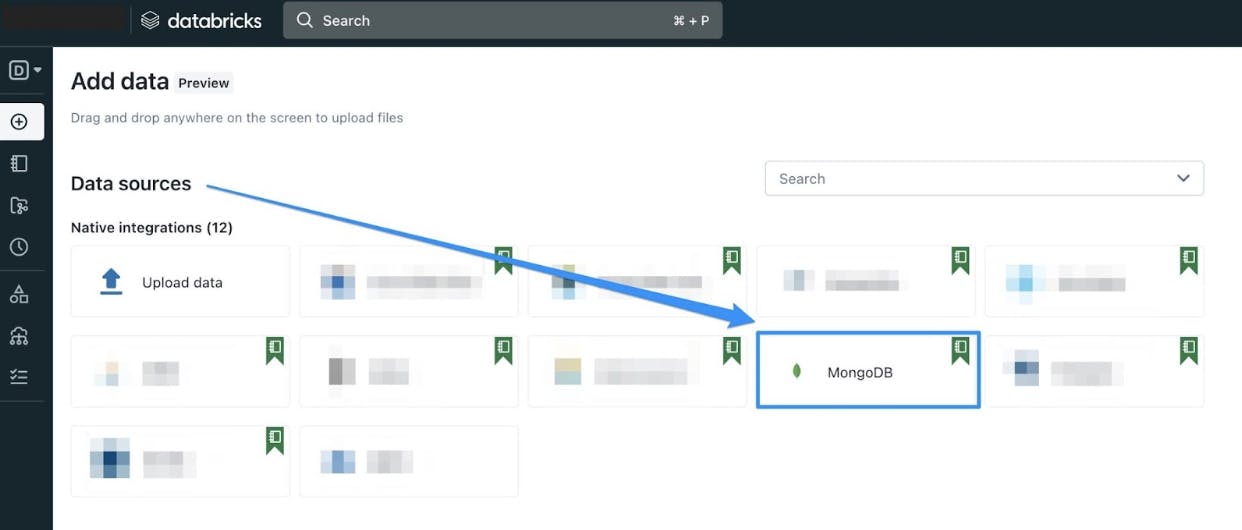
This notebook can help as an initial template for developers to start building complex transformation jobs on MongoDB data with Databricks platform.
Interested in a practical example of how this works? Let's demonstrate how you can run analytics on a sample sales dataset using MongoDB's aggregation framework and visualize it with Charts. The example also explains how you can enrich this data using our Databricks notebook and load that back to MongoDB. Refer to the GitHub repo for the same.
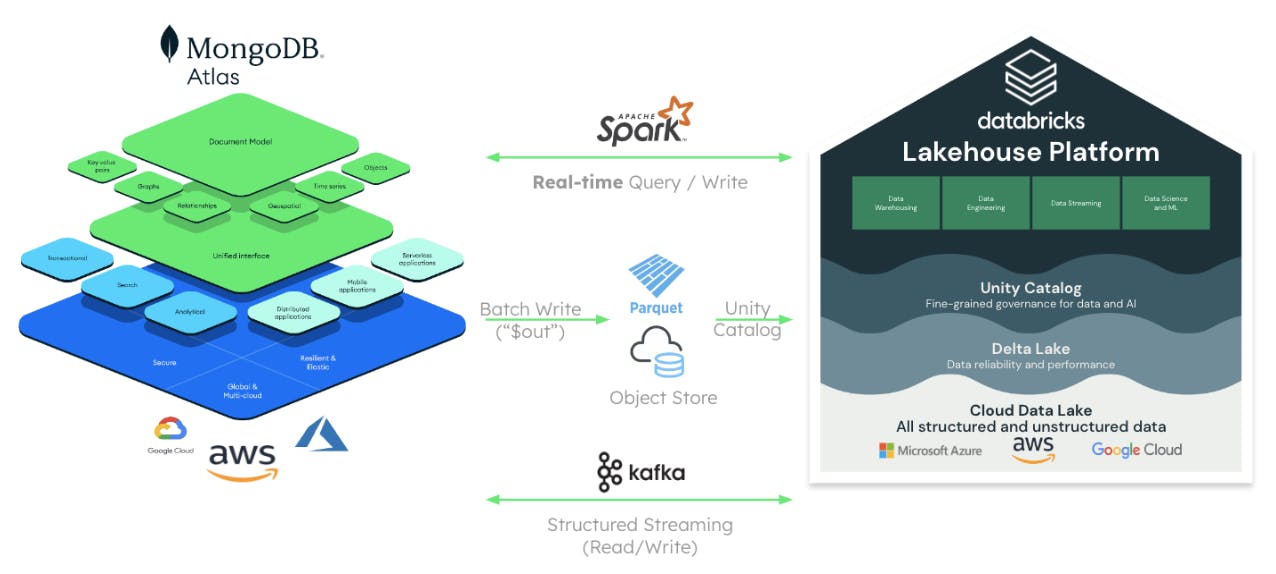
In addition to Spark, MongoDB and Databricks provide seamless integration through shared Cloud Object stores to enable a more traditional data exchange using analytics-optimized formats such as Parquet, as well as event streaming integration using Apache Kafka.
Together, MongoDB and Databricks offer unparalleled abilities to unify and process data from disparate systems in real-time. And now with the newly announced Databricks notebooks integration, data engineers and data scientists have an even easier and more intuitive interface to harness MongoDB data for their most sophisticated analytics and AI processing, making real-time applications more intelligent.
Conclusion
MongoDB Atlas along with Databricks Platform together will help organizations handle the increasing convergence between operational and analytical workloads. This convergence enables application-driven analytics and will help you build smarter applications and derive the right insights in real-time. Reach out to our partners team to learn more.